 夜雨聆风
夜雨聆风这两年做 RAG、知识库问答、论文助手的人越来越多,但很多项目其实不是死在模型上,而是死在PDF 解析这一步。
多栏论文一解析就串行了,表格直接散架,页眉页脚和水印混进正文,最后连“答案到底来自 PDF 的哪一段”都没法高亮回链。你以为是模型幻觉,很多时候其实是上游数据一开始就喂歪了。
最近我在 GitHub Trending 上看到一个很适合分享给大家的项目:OpenDataLoader PDF。如果只看一句话,它就是一个面向 AI-ready data 的 PDF parser:可以把 PDF 转成适合 LLM 和 RAG 使用的 Markdown、JSON(含 bounding boxes)和 HTML;默认本地 CPU 就能跑,复杂页面再切到 hybrid 模式;同时还把 OCR、复杂表格、公式、图片描述、提示词注入过滤、甚至 PDF 无障碍结构化这条线一起做了。
它之所以值得看,不只是因为star数,而是因为它解决的,是一条非常实在的工程链路:别再只关心模型,先把 PDF 这层脏活干对。
为什么这个项目现在值得看?
先说结论:OpenDataLoader PDF 不是“又一个 PDF 转文本工具”,而是一个明显按 RAG / LLM 场景反推出来的解析器。
项目首页直接把问题点得很透:PDF 对人类阅读友好,但对 AI 并不友好。常见坑包括:
多栏布局导致阅读顺序错乱
表格被打成一坨文本
没有源坐标,回答没法精准引用
无障碍标签缺失,后续 accessibility 成本高
也就是说,它瞄准的不是“能不能读出文本”,而是:
能不能把结构、顺序、表格关系和来源位置一起保下来。
这也是它能冲上 GitHub Trending 的原因之一。按照我查看 Trending 时的数据(2026年4月10日),这个项目当天拿到了 1,124 stars today,总星标大约 1.39 万,说明它不只是小圈子工具,而是正在进入更多 RAG / 文档 AI / PDF 工程开发者的视野。

它最有价值的地方,不是“提取文本”,而是“保留结构”
很多 PDF 工具的默认思路是:
先把文本抽出来,再说。
但你真把它接进知识库、问答系统、论文助手之后就会发现,纯文本远远不够。
1)它给的不只是 Markdown,还有带坐标的 JSON
OpenDataLoader 的输出不是单一文本,而是多种格式:
Markdown:适合直接做 chunking,喂给 LLM
JSON:保留 semantic type、page number、bounding box 等结构信息
HTML:适合前端展示
其中最关键的是 JSON 里的 bounding box。
这件事对做 RAG 的人非常重要,因为它意味着你不只是“知道答案来自第几页”,而是可以进一步做到:
高亮原 PDF 的精确位置
做 page + position 级别的引用回链
校验抽取结果到底对不对
很多文章在聊 RAG 的时候,会把注意力都放在 embedding、reranker、agent 上,但如果你的 PDF source 根本没法精准对位,最后的用户体验就很难像样。
有坐标框,才有真正可验证的引用。
2)它把“阅读顺序”这件事当成核心能力来做
OpenDataLoader 不是简单从左到右扫文本,而是强调它的 XY-Cut++ reading order。
这点听起来很简单,但非常关键。
因为多栏论文、侧边栏、图文混排这类文档,最怕的就是抽取顺序乱掉。
一旦顺序错了,哪怕文本一个字没丢,LLM 看到的上下文也已经是错的了。
如果你做过论文问答、政策文档分析、招股书解析,应该很容易理解这一点:
顺序一乱,整个 chunk 的语义边界就会跟着塌。
3)它不是靠“上来就上模型”硬解所有问题
这也是我比较喜欢它的地方。
OpenDataLoader 的思路并不是“所有页面都扔给大模型”,而是分成两层:
默认 deterministic local mode:本地 CPU 处理,适合普通数字 PDF
Hybrid mode:遇到复杂表格、扫描件、公式、图表,再路由到 AI backend
这个策略很工程化。
因为现实里大多数 PDF 页面其实并不值得你一页页上重型处理。
简单页面用本地规则和布局分析先吃掉,复杂页面再交给 hybrid,既节约资源,也更容易把吞吐量做起来。
它为什么会让开发者有“收藏感”?
因为它不是只给你一个“效果不错”的结果,而是把很多 RAG 场景真正需要的东西都补齐了。
第一层:结构信息齐全
仓库里给出的能力矩阵里,比较实用的点包括:
正确阅读顺序
每个元素都有 bounding boxes
表格抽取
标题层级检测
列表检测
图片坐标
OCR(hybrid)
公式提取(hybrid)
图表 / 图片描述(hybrid)
Header / footer / watermark 过滤
Prompt injection 过滤
这里面我觉得最容易被低估的,是 prompt injection filtering。
很多人默认觉得 PDF 很“静态”,但 README 明确写了它会过滤:
隐藏文本(透明、零字号)
页面外内容
可疑的不可见层
如果你的 PDF 来源复杂,或者后面真的要把抽取文本直接接进 AI 系统,这种安全清洗其实很有现实价值。
第二层:它是本地优先的
项目文档明确强调:100% locally,不需要把文档传到云端;hybrid backend 也可以在本地机器运行。
这对法律、金融、医疗、政务之类文档场景很重要。
技术圈里很多“效果最好”的解析方案,问题不是准不准,而是:
要不要上 GPU
要不要传云
能不能进内网
能不能给合规团队解释
OpenDataLoader 这类 local-first 的设计,刚好会让它在企业和半企业场景里更容易被认真看待。
它到底强到什么程度?
1)整体成绩确实很能打
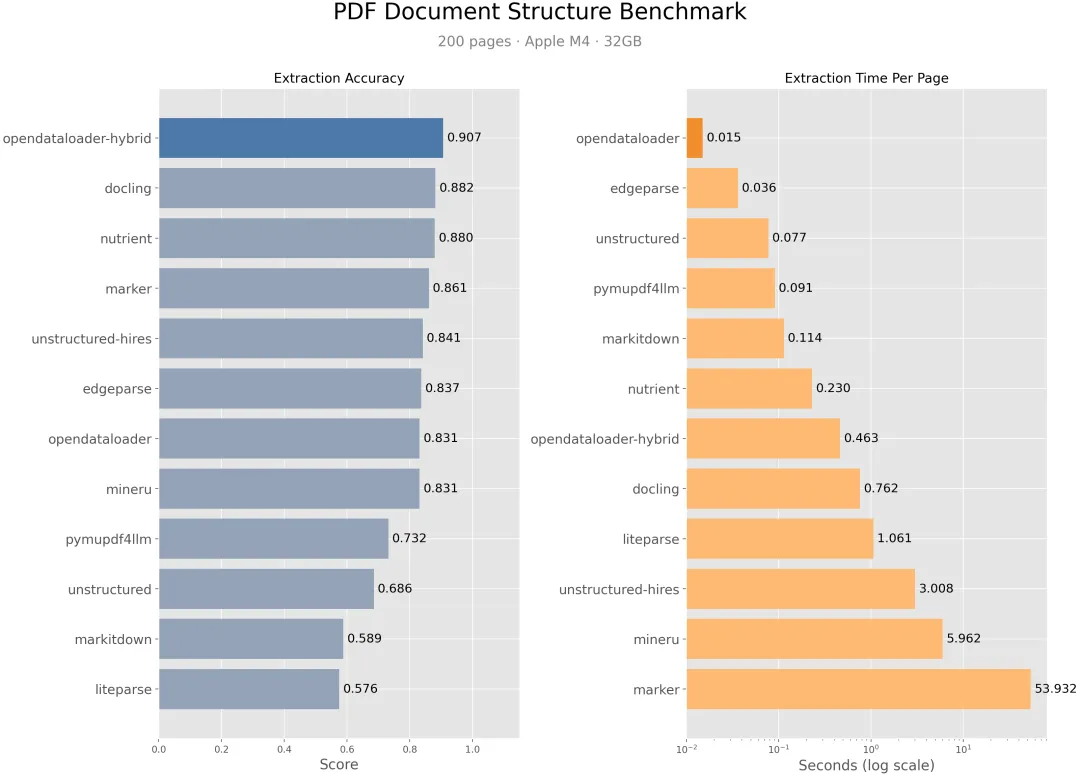
README 和官网给出的 benchmark 里,OpenDataLoader [hybrid] 的 overall score 是 0.907,高于:
docling:0.882
nutrient:0.880
marker:0.861
pymupdf4llm:0.732
速度上,它的 local mode 是 0.015s/page,非常快;
hybrid mode 是 0.463s/page,比 docling 的 0.762s/page 更快,也远快于 marker 的 53.932s/page。
2)它最亮眼的是表格和阅读顺序
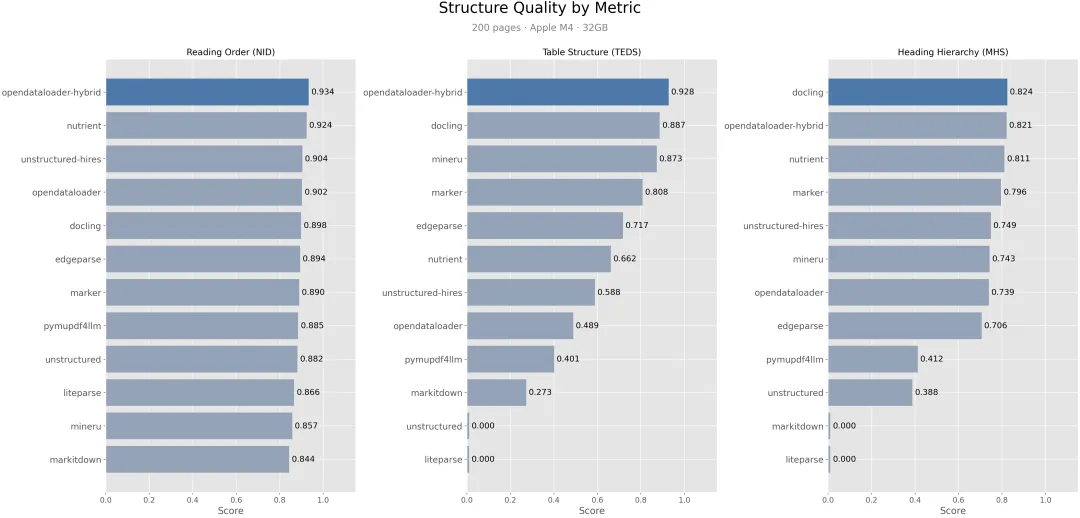
如果拆指标看,它的 hybrid 模式在:
Reading Order (NID):0.934
Table Structure (TEDS):0.928
Heading Hierarchy (MHS):0.821
这里最值得聊的是表格。
README 里直接给了一个很有传播力的数据:本地模式表格分数是 0.489,打开 hybrid 之后能到 0.928。
这意味着如果你的文档里有复杂表格、无边框表格,hybrid 带来的提升不是“小修小补”,而是会直接决定这个工具能不能进入生产链路。
3)但它也不是全项碾压
这个项目的一个优点,恰恰在于它的数据里也能看出边界。
比如在 Heading Hierarchy 这个指标上,docling 是 0.824,OpenDataLoader [hybrid] 是 0.821。
差距不大,但这说明它不是“每一项都绝对第一”。
我反而更愿意相信这种项目。
因为真实世界里的 parser,本来就不太可能在所有维度都无死角领先。
更重要的是你要知道它最适合解决什么问题:
PDF 结构保留
多栏阅读顺序
表格抽取
精准坐标引用
本地部署
扫描件 / OCR / 复杂页面增强
如果你现在就想上手,最推荐怎么用?
我建议你别一上来就研究所有参数,先按场景分三步。
场景一:普通数字 PDF,先用默认 fast mode
```bash
pip install -U opendataloader-pdf
```
```python
import opendataloader_pdf
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)
```
这里有个很实用的细节:README 特别提醒,每次 `convert()` 都会拉起一个 JVM 进程,重复调用会慢。
所以更推荐一次性 batch 多个文件,而不是你在循环里一页一页调。
场景二:复杂表格 / 扫描件 / OCR,直接开 hybrid
```bash
pip install "opendataloader-pdf[hybrid]"
opendataloader-pdf-hybrid --port 5002 --force-ocr
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/
```
如果你处理的是中文扫描件,可以把 OCR 语言显式带上,比如:
```bash
opendataloader-pdf-hybrid --port 5002 --force-ocr --ocr-lang "ch_sim,en"
```
项目文档里给出的语言支持里包括 `ch_sim`、`ch_tra`、`ja`、`ko`、`ar` 等,这一点对中国开发者挺友好。
场景三:你已经在用 LangChain
那就直接走它的官方 loader:
```bash
pip install -U langchain-opendataloader-pdf
```
```python
from langchain_opendataloader_pdf import OpenDataLoaderPDFLoader
loader = OpenDataLoaderPDFLoader(
file_path=["file1.pdf", "file2.pdf", "folder/"],
format="text"
)
documents = loader.load()
```
如果你本来就在搭 LangChain RAG,这条路会比较顺。
除了 RAG,这个项目还有一个很容易被忽略的点:Accessibility
OpenDataLoader 不只是把 PDF 解析成 AI-ready data,它还在往 Tagged PDF / PDF/UA 这条线走。
README 和官网都提到,它的 auto-tagging 正在推进,目标是把无标签 PDF 自动转成 Tagged PDF,而且这条链路是和 PDF Association、Dual Lab(veraPDF 开发方)一起做的。
这件事其实非常“工程问题化”:
以前你把 PDF 当内容问题
现在它越来越变成 数据工程 + 合规 + 可访问性 的组合问题
这个项目适合谁,不适合谁?
适合的人
做 RAG / 知识库 / 文档问答
要处理论文、招股书、财报、政策文档、手册
很在意表格、阅读顺序、源定位
希望本地运行,不想把文档传到外部服务
需要扫描件 OCR,或者处理中英混合 PDF
不那么适合的人
你只是想把 PDF 粗暴转成纯文本
你现在处理的主要不是 PDF,而是 Word / Excel / PPT
你不想额外准备 Java 11+ 和 Python 3.10+
你不需要坐标、结构、表格、引用,只要“能看个大概”
README 也写得很清楚:它现在的限制之一,就是不处理 Word / Excel / PPT。
所以别把它当成“万能文档入口”,它目前还是一个非常明确的 PDF 专项工具。
我的真实判断:它最有价值的不是“解析得更准”,而是“更适合进入工程系统”
看完这个项目,我最大的感受不是“又一个 PDF parser 卷起来了”,而是:
文档 AI 这条链路,终于开始从 demo 走向工程细节了。
以前很多人做 PDF + LLM,思路都很粗:
抽文本
切块
向量化
检索
回答
现在大家会越来越意识到,真正决定体验上限的,其实是最前面那一层:
文本顺序对不对
表格还在不在
引用能不能精确回链
页面元素有没有坐标
不可信内容有没有被过滤
敏感文档能不能本地跑
OpenDataLoader PDF 代表了一种很明确的趋势:
RAG 上游不再只是“读文档”,而是在做结构化、可追踪、可验证、可部署的数据入口。
如果你最近正好在折腾 PDF 知识库、论文助手、企业文档问答,我觉得这个项目很值得放进你的工具清单里。
至少它会逼着你重新想一遍:
你现在的 RAG 问题,到底是模型问题,还是 PDF 解析根本没做对。
注:本文章项目来源于https://github.com/trending,项目地址为github.com/opendataloader-project/opendataloader-pdf,本文部分内容由人工智能辅助整理、润色与优化。
