 夜雨聆风
夜雨聆风
王某某大概没想到,她在键盘上敲下提示词、让AI大模型吐出的那篇文章,会在短短几天后把她送进处罚决定书。据南充融媒报道,5月20日,一篇涉股市的文章出现在今日头条上,洋洋洒洒,围绕A股走势做了一通预测——量化交易政策要怎么改、印花税要征收、T+0交易要来了。每一句都像是内部消息,每一段都在撩拨股民最敏感的那根神经。
但那些"消息",全是AI编的。
6月18日,南部县警方依据治安管理处罚法,对王某某作出行政处罚。那篇文章,已被清理下架。据南充融媒的报道,王某某的根本目的很明确——从网络攫取流量收益。
📜 治安管理处罚法 第二十五条
散布谣言扰乱公共秩序的,处5日至10日拘留,可以并处500元以下罚款。
三千字,换来一份处罚决定。这笔账,怎么算都不划算。
但更值得琢磨的是,她不是第一个。
就在这次处罚前不久,据第一财经报道,北京证监局接连对两人开出罚单。冯某被罚没20万元。另一个叫班某,事情做得更"精致"一些——他把互联网上已有的文章拿过来,用AI工具改写,加上夸大的描述,发到微信公众号上,获利173.70元。
173块7毛。
班某申辩说,文章是AI工具生成的,不是他本人编造。北京证监局的回应很硬:你未尽审慎核查义务。罚没合计25万元。
| 对比项 | 金额 | 量级 |
|---|---|---|
| 班某违法所得 | 173.70元 | 百元级 |
| 班某被罚没 | 25万元 | 百倍惩罚 |

这个落差,大概是所有想拿AI当挡箭牌的人最该记住的数字。
我一直在想一个问题:为什么是股市?
答案可能藏在股市的特殊性里。证券市场是一个信息驱动的市场,一条消息可以让一只股票涨停,也可以让它跌停。造谣者不需要真的有多少粉丝,不需要文章写得多好——他们只需要让信息出现在对的场景里,让算法推给对的人。恐慌会放大恐慌,贪婪会喂养贪婪。一个"印花税要征收"的假消息,在散户群里传一圈,可能就是几亿市值的波动。
王某某那篇文章里,臆测了量化交易政策,编造了印花税征收的信息,还虚构了T+0交易的说法。三条不实信息,每一条都精准踩在股民最关注的政策议题上。这不是巧合。AI大模型的"聪明"在于,它能根据提示词精准生成看起来最像那么回事的内容——语气、逻辑、甚至引用的"数据",都可以是编的。而它的"危险"也正在于此:造谣的成本,从需要一个懂行的人亲自动笔,变成了任何会打字的人都能完成。
技术门槛塌了,但法律门槛没有。
我国证券法写得明明白白:编造、传播虚假信息扰乱证券市场的,没收违法所得,并处以违法所得一倍以上十倍以下罚款;没有违法所得或者违法所得不足20万元的,处以20万元以上200万元以下罚款。
📜 证券法 相关条款
编造、传播虚假信息扰乱证券市场的,没收违法所得,并处以违法所得一倍以上十倍以下罚款;没有违法所得或者违法所得不足20万元的,处以20万元以上200万元以下罚款。
治安管理处罚法第25条也兜着底:散布谣言扰乱公共秩序的,处5日至10日拘留,可以并处500元以下罚款。
再往上,刑法第291条之一:编造、传播虚假信息严重扰乱社会秩序的,处三年以下有期徒刑。
📜 刑法 第二百九十一条之一
编造、传播虚假信息严重扰乱社会秩序的,处三年以下有期徒刑。

| 法律层级 | 处罚力度 |
|---|---|
| 治安管理处罚法 | 5-10日拘留 + 500元以下罚款 |
| 证券法 | 20万-200万元罚款 |
| 刑法 第291条 | 三年以下有期徒刑 |
三层法律,从行政处罚到刑事追责,阶梯清晰。而关键在于——法律追究的对象,始终是那个按下发布键的人。
警方说了一句很重的话:AI不是违法犯罪的挡箭牌。
这句话的分量,班某应该比谁都清楚。他以为"AI生成的"是一张免责声明,但法律只看一件事:你是内容的发布者,你有义务核实,你没有核实,你就得承担后果。
但事情远不止处罚几个人那么简单。
AI大模型生成不实信息的链条,大致是这样的:一个人,一个提示词,一个模型,一个平台,一次发布,一个算法推荐,一轮传播。七个环节,每个环节都有问题可以问。
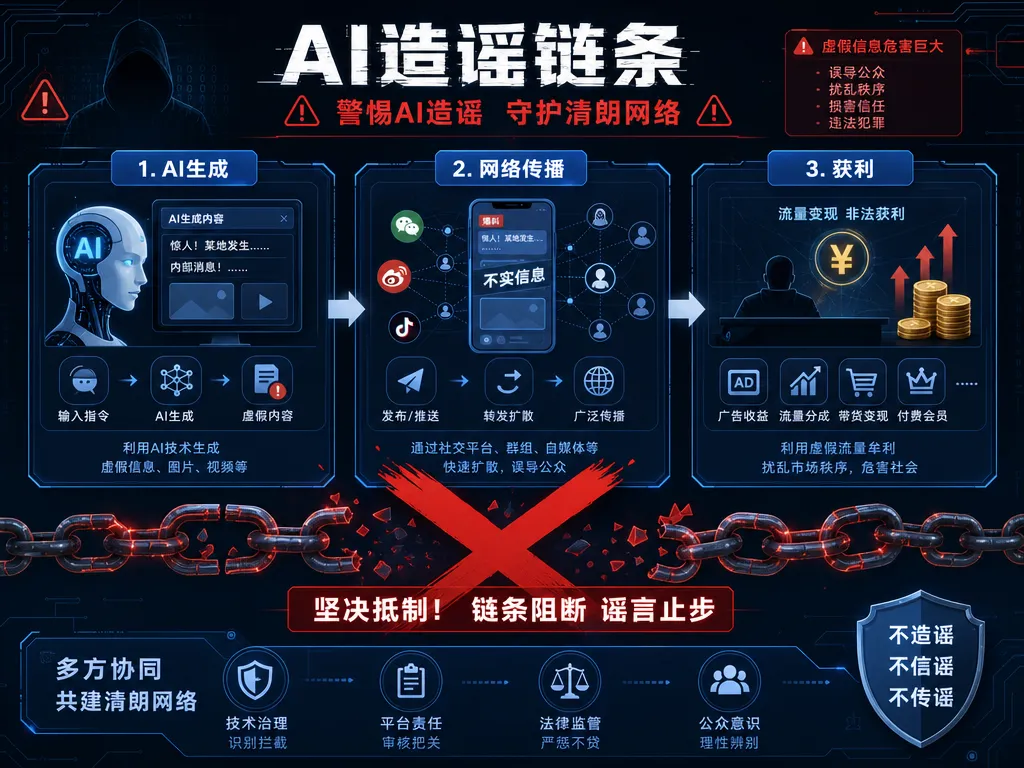
人,为什么造谣?流量收益是最直接的答案,但背后可能还有更隐蔽的动机——建立影响力、收割注意力、甚至配合某些利益操作。
模型,为什么会编?大模型不是信息检索工具,它是概率生成器。它不"知道"什么是对的,它只是根据训练数据的概率分布,生成看起来最"合理"的下一段文字。你让它写一篇"印花税即将征收"的分析,它会写,而且写得头头是道。它不会跳出来说"等等,这个前提是假的"。
平台,为什么推?算法的优化目标是用户停留时长和互动率,而不是信息真实性。一条"独家消息",点击率天然高于一条枯燥的政策解读。算法不会追问消息来源,它只看数据。
传播,为什么快?因为恐慌和贪婪是传播最快的两种情绪。股市谣言同时激活了两者。
⚠️ 这条链上每一个环节都在加速,却没有一个环节在刹车。
薛洪言提过一个四维治理体系:监管、平台、法律、投资者教育。四个维度,缺一不可。
短期最紧迫的,是让AI生成的内容可以被识别。据IT之家报道,有专家建议部署AI内容标识系统和区块链溯源——至少让人知道,他正在读的这篇文章,是不是机器写的,是谁让它写的。
中期需要重构的,是一个更根本的逻辑:谁算法推荐,谁担责。平台不能一边用算法放大传播,一边声称自己只是中立的"信息展示者"。
长期要做的,是整个信息生态的治理。技术、制度、意识,三件事要同步走。这不是一个部门能完成的,也不是一条法律能覆盖的。
近五年,类似案件据称有19起。这个数字我没有逐条核实,但即使打个折,也足以说明:这不是个案,而是一种趋势。AI让造谣变容易了,造谣的人变多了,查处的速度在加快,但治理的难度也在指数级上升。
我最后想到的,是那些读到王某某那篇文章的人。
他们不知道那是AI写的。他们可能在一个深夜,刷到那条"印花税要征收"的消息,心里一紧,第二天开盘就卖了手里的股票。他们的损失,不会出现在任何处罚决定书里。
这才是AI造谣最隐秘的伤害——不是造谣者被罚了多少钱,而是那些被一条假消息改变了决策的普通人,他们甚至不知道自己被算法和虚假信息共同操控过。
每个用AI的人,大概都该在按下发布键之前,停三秒。
问自己一句:我确定这是真的吗?我核实过吗?如果别人因为这句话做了错误的决定,我担得起吗?
AI没有良心,但人有。
完
硅基艺志 · AI创作,触手可及
#AI造谣 #网络治理 #法律
