 夜雨聆风
夜雨聆风处理文档这事儿,说大不大,说小可真不小。咱平时工作里,谁没遇到过那种抓狂时刻啊?一堆PDF合同、扫描件、发票照片,里面的数据得一条条抠出来填进Excel。手动复制粘贴吧,眼睛都要看瞎了,还老容易出错;想让AI帮忙吧,发现直接丢给ChatGPT,出来的结果时灵时不灵,格式也乱七八糟的,根本没法直接用。
要是有个工具,既能听懂人话,又能稳定输出规整的数据,还不用写代码,那该多好?哎,还真有。最近我在GitHub上挖到一个挺有意思的项目叫 Unstract,号称是"智能体工作流的数据层",用起来感觉就像给文档处理装了个自动驾驶。
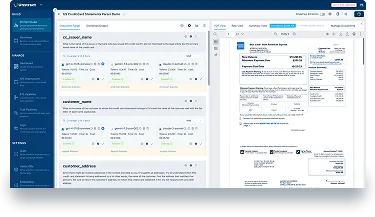
它本质上是个无代码的LLM平台,核心就干一件事:把你手里的各种乱七八糟的非结构化文档——不管是PDF、Word、图片还是PPT——自动转换成干干净净的JSON数据。而且准确率能做到接近100%,成本还可控。对于搞财务、法务、或者经常要处理报表的朋友来说,简直是救命稻草。
这玩意儿到底能干啥?
简单说,Unstract提供了一个从调试到部署的完整工作流。你不需要懂编程,只需要在界面上拖拽配置,就能搞定以前需要写几百行代码才能做的文档解析任务。
它的核心叫 Prompt Studio(提示词工作室)。这地方就像是文档处理的实验室,你可以像设计数据库表一样,用自然语言定义想提取的字段。比如你要从一堆信用卡账单里抓"持卡人姓名"、"账单金额"、"还款日期",就直接在界面上新建这几个字段,然后用大白话告诉AI"账单金额是哪个数字",完事儿。
最爽的是,你可以同时连上好几个大模型——GPT-4、Claude、Gemini都行——上传一份文档,让它们并排跑,看哪个提取得准、哪个速度快、哪个更便宜。比完以后选个最好的,一键发布成API接口,或者直接设置成定时任务,自动处理新来的文件。
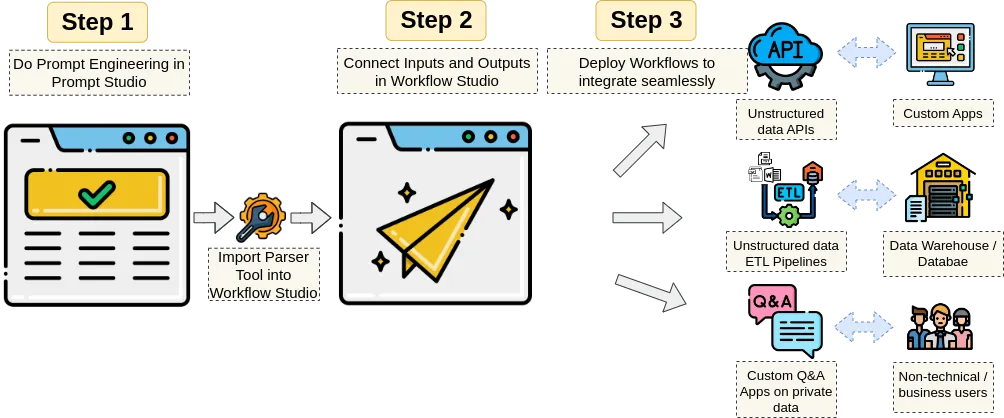
除了API,它还支持好几种用法:可以当成ETL管道,自动从S3或者Google Drive抓文件,处理完直接写进Snowflake或者PostgreSQL;也可以接入n8n这种自动化工具,搭个流水线;甚至还有MCP服务器,能给Claude这样的AI智能体当"手"用,让它自己能去读文档取数据。
安装其实没那么难
看到这儿你可能觉得,功能这么全,安装肯定特麻烦吧?其实不然。开发者明显考虑到了咱们不想折腾的心情,整个部署就几条命令的事儿。
你需要准备的:
一台Linux或Mac电脑(Windows可能得用WSL) 8GB内存(这个得有,别太少) 提前装好Docker和Git
然后,就三步:
# 1. 把代码克隆下来git clone https://github.com/Zipstack/unstract.gitcd unstract# 2. 运行启动脚本(这就是个一键安装)./run-platform.sh等着Docker把各种容器拉起来,大概几分钟吧,取决于你的网速。看到命令行里显示所有服务都启动了,就搞定了。
接下来打开浏览器,访问:
http://frontend.unstract.localhost默认的账号密码都是 unstract。第一次登录建议去改个密码,安全第一嘛。

要是以后想升级,也简单,运行 ./run-platform.sh -u 就行,会自动拉最新版本。如果想用特定版本,加个 -v 参数指定版本号就好。整体来说,维护成本挺低的,不用你天天盯着。
手把手教你提取第一份数据
装好了就得用起来,不然白折腾。咱们走一遍完整的流程,假设你要处理一堆发票,想提取"发票号码"、"开票日期"、"金额"这三个字段。
第一步:创建项目登录进去后,左边菜单找到"Prompt Studio",新建一个项目,取个名字比如"发票提取器"。这时候界面会分成左右两栏,左边是你要定义的结构,右边可以上传PDF预览。
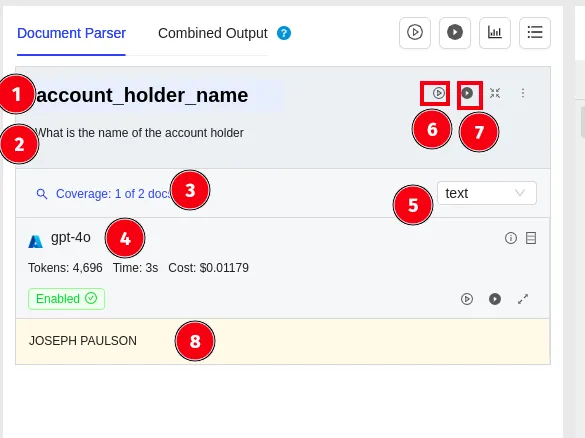
第二步:定义提取字段点"Add Prompt"添加字段。系统会让你填:
字段名:比如 invoice_number提示词:用自然语言描述,比如"这是一张增值税发票,请提取右上角的发票号码,通常是10位或12位数字" 数据类型:选text就行,如果是数字也可以选number
依葫芦画瓢,把日期和金额也加上。每加完一个,都可以点试运行,看AI能不能抓对。
第三步:多模型对比(这步可选但推荐)在设置里把OpenAI和Claude都配置上(需要填API Key,用自己的就行)。然后上传几个样本发票,看看哪个模型在你这类文档上表现更好。界面会显示每个模型的token消耗和耗时,一目了然。
第四步:导出使用测试满意了,点右上角的"Export"或者"Deploy as API"。如果选API,系统会给你生成一个接口地址,还有示例代码。你在外部系统里只需要发一个HTTP POST请求,带上PDF文件,等个几秒钟,就能收到结构化的JSON数据。
要是想全自动处理,就去设置ETL Pipeline。配置好源(比如AWS S3的某个文件夹)和目标(比如你的数据库),设置个定时任务,Unstract就会像个勤劳的小蜜蜂,定时去检查新文件,处理了写进库,完全不用人工干预。
几个提升准确率的独门秘籍
用AI处理文档,最怕的就是"幻觉"——AI瞎编数据。Unstract在这方面做了不少贴心设计。
LLMChallenge(双重校验): 这是云版才有的功能,原理是用两个不同的LLM分别提取同一份文档,然后交叉比对。只有当两者结果一致时才输出,不一致就标记出来让人工复核。虽然成本会高一点,但准确率确实能上去,适合对精度要求极高的场景。
SinglePass Extraction(单次提取): 有些长文档如果分段处理,容易漏东西或者重复。这个技术能把token消耗降低好几倍,同时保持准确性,省下的钱可不少。
人机回环(HITL): 对于关键数据,可以开启人工审核界面。AI提取的结果会高亮显示在原文对应的位置,审核人员一眼就能核对,点一下就能修正,改完了数据才正式入库。
它能用在哪些地方?
基本上,只要涉及"从文档里扒数据"的场景,Unstract都能插一脚:
财务部门:自动识别发票、报销单、银行流水,直接生成记账凭证 法务合规:批量审合同,提取关键条款、金额、到期日,做风险预警 人力资源:处理简历,自动提取技能、工作经历、联系方式,建人才库 市场调研:抓竞品的PDF报告,提取产品参数、价格策略 客服中心:自动分析客户发来的邮件和附件,分类整理工单
而且它是开源的(AGPL-3.0协议),意味着你可以完全掌控数据,不用担心隐私泄露。对于金融、医疗这些对合规要求高的行业,也能放心用。
如果你不想自己部署,官方也提供了云服务,注册就能用,有14天免费试用期。但我个人觉得,既然有Docker版本,还是自己托管更划算,数据也安全。
总的来说,Unstract这项目把AI文档处理这件事从"技术活"变成了"体力活"——不需要你懂深度学习,不需要写正则表达式,只要懂业务逻辑,就能把复杂的文档解析 pipeline 搭起来。对于想降本增效的团队,真的值得花半小时试试看。
源码地址:https://github.com/Zipstack/unstract
专注分享 GitHub知识,分享AI 资讯和AI搞米经验,分享AI Agent使用经验。

想领取完整版OpenClaw资料,后台留言哦~
