 夜雨聆风
夜雨聆风 6 月 18 号,Thomas Dimson 发了条 tweet。
6 月 18 号,Thomas Dimson 发了条 tweet。
"did you make it into the superintelligences? are you in the weights?"
你进入超级智能的脑子了吗?你在权重里吗?
没有配图,没有 thread,就一句话加一个链接。然后瞬间爆了。Hacker News 顶到了首页。
链接指向一个叫 In the Weights 的网站。界面是像素风的终端机,中间一个输入框,输入你的名字,看看 AI 认不认识你。
看到的一瞬间,我就去搜了。很遗憾,AI不认识我😂。
比如搜一下「雷军」👇

895 分,Top 1%。GPT-5.5 不仅知道他是小米创始人,还用中文写了他的完整履历。这就是 In the Weights 做的事——输入名字,AI 告诉它认不认识你。
01谁搞的这个产品?
做这个网站的只有两个人。

| Thomas Dimson | Joey Flynn | |
|---|---|---|
| 江湖标签 | Instagram算法之父 | 设计/产品 |
| 干了什么 | 写了 IG 的 Feed 排序算法,管了 7 年推荐系统;后创办 Global Illumination,被 OpenAI 收购;进 Sora 团队做核心开发 | Facebook → OpenAI → Sora 发布 |
| 离开时间 | 2026 年 5 月,在 OpenAI 待了大概 1000 天 | 同一个月 |
| 人设 | 工程极客,Fast Company 评过十大最具创造力商业人物 | 设计脑,X 的 bio 引了帕斯卡那句如果我有更多时间,我会写一封更短的信 |
他们做了个网站,让你问问 AI 认不认识你。
02为啥能搜到?分数怎么来的?
为啥你能被搜到,为啥搜不到你?原理其实很简单。
你输入名字,网站把它同时发给十几个模型——GPT-5.5、Claude Opus 4.8、Grok、Gemini、DeepSeek V4、Llama、Mistral、Qwen3……一堆你叫得上名叫不上名的前沿模型。
每个模型被问到同一个问题:[名字] 是谁?

需要注意的是。模型不能联网,不能查资料。它只能靠训练数据里记住的东西回答。换句话说,这不是 Google 搜索。这是在考模型的记忆力。考它背没背过你。
十几个模型各自交出答案后,后台干两件事:
第一,聚类。 相似的答案聚在一起。GPT-5.5 说Jackie Chan,香港动作演员。Claude 说成龍,功夫电影明星。说的同一个意思。多个模型给出一致的描述,置信度就高。
第二,打分。 一致性越强,分数越高。满分 996。各说各话的、彼此矛盾的、直接编的,归进幻觉栏。
这里面有一个反直觉的设计:模型越小,认出你越难。 Dimson 说,大模型参数多空间大,记住谁都不稀奇。但如果你在 Llama 1B 这种小模型里还能被认出来——说明你的信息在训练语料里密度极高。小模型都记得你,你才是真的在权重里。
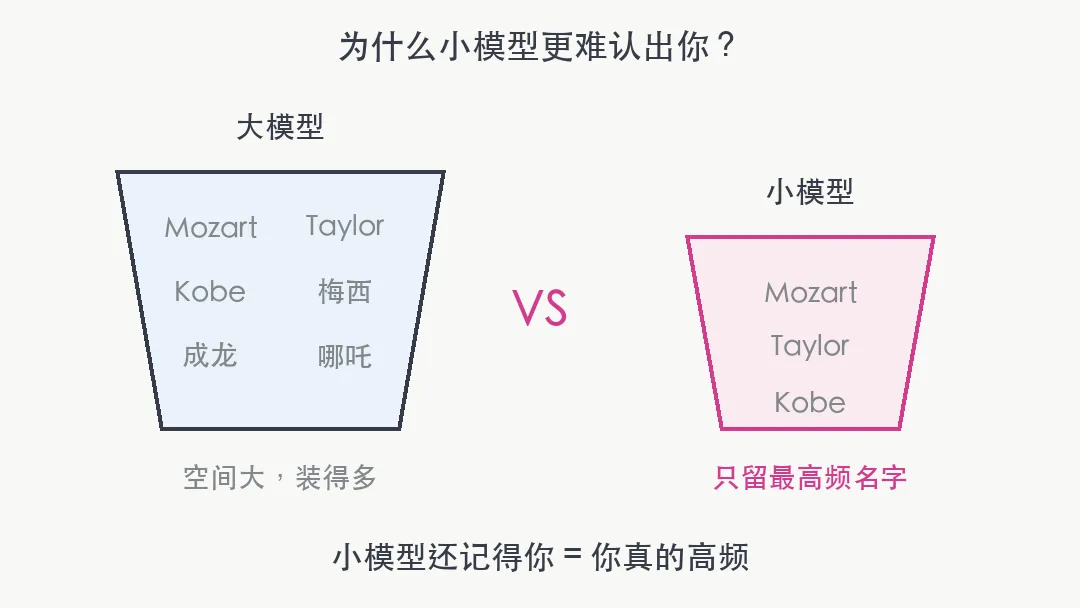
这面镜子,照出了什么
你输入的是名字,看到的是自己在 AI 里的影子。
先说满分俱乐部。Paul McCartney、莫扎特、莎士比亚、泰勒·斯威夫特、斯皮尔伯格、曼德拉。20 个人全部 996 分,没有任何高下之分。
排行榜不是刻在石头上的。前一天 Charlize Theron 以 998 分登顶,第二天满分线就降到了 996,榜首换成了 Paul McCartney。模型一更新,权重流动,排名跟着变。

排行榜上的名字偏得厉害。20 个里几乎全是欧美文娱圈的人。Beatles 贝斯手、灵魂歌手、乡村歌手、好莱坞演员。亚洲面孔一个没有。
那不在满分线上的人呢?我拿截图对比着看,分差大到让人坐直。
体育圈:同一个地球,不同的分数

成龙,832 分,Top 2%。GPT-5.5 用英文描述他:香港动作喜剧演员。姚明也在这个段位:

姚明 833 分,跟成龙几乎一模一样。两位在中国家喻户晓的名字,在 AI 的标准里都是 Top 2%。
再看看梅西:

梅西 900 分,直接跳了一档。他是全世界最知名的足球运动员,训练数据里他的故事被几十种语言反复讲。
然后看 Kobe:

Kobe 977 分。比姚明高出 144 分。同样是 NBA 巨星,一个在西方媒体里浸泡了二十年,一个主要被中文世界覆盖。这个分差,就是训练数据偏见的刻度。
科技商业圈:马斯克一骑绝尘

马斯克 985 分,离满分只差 11 分。全球最被 AI 认识的企业家,不意外。

马云 902 分,Top 1%。GPT-5.5 甚至在描述里写了马云 is the Chinese name of Jack Ma。它知道中文名和英文名的对应关系。

任正非 904 分,比马云还高了 2 分。华为创始人,在全球科技媒体的曝光量也许比阿里创始人更多。
最让我意外的名字

哪吒。896 分。他不是真人,是一个神话人物。但 GPT-5.5 不仅知道他是谁,还用中文描述了风火轮、火尖枪、混天绫。
一个虚构角色拿了 896 分,比成龙高了 64 分。这说明什么?说明 AI 的训练数据不只收录了新闻和百科。它吞了足够多的中文文化内容,多到连神话人物都有精确画像。
总结一下这面镜子
横看竖看,几个事实摆在那里:
英语世界的名字天然分高。 Kobe 977 vs 姚明 833,马斯克 985 vs 马云 902。这不是谁更重要的问题,是谁被写得更多的问题。
中文世界的人正在被看见。 任正非 904、马云 902、哪吒 896。放在半年前可能更低。中国的人物、文化符号正在进入权重,只是速度还不够快。
神话人物也在权重里。 哪吒 896 分这件事本身就值得多想一层:AI 认识的你,可以是真实的,也可以是虚构的。它不区分这两者。
还有一个细思极恐的角落:幻觉栏。AI 不认识你的时候,不会说「我不知道」。它会编。给你编一段生平、编一段成就、编一个你从未拥有过的身份。某种意义上,每个人在 AI 眼里都有两个版本:一个真实的你,一个幻觉的你。你没法控制后者。
说到幻觉——我自己也搜了一下。

455 分,Top 10%。不高,但至少进去了。问题是 GPT-5.5 把它描述成「中国 AI 芯片公司」。不是芯片公司,是一个公众号。AI 认识这个名字,但它搞错了这是什么。
这就是权重里的幻觉。它记住了你,但记住的版本跟你自己知道的未必一样。
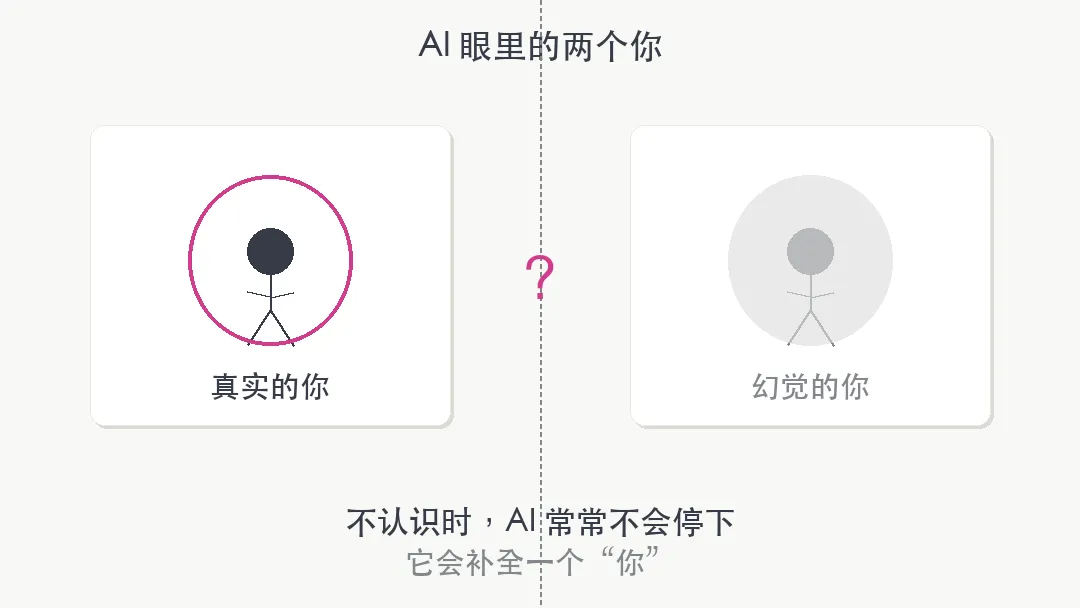
为什么这件事值得认真想
三件事。
第一,信息权力在转移。 过去一个人存不存在取决于 Google 能不能搜到。但越来越多人不再打开搜索引擎。他们直接问 ChatGPT,问 Claude,问 Grok。信息不再以网页形式存在,而是被压缩进了模型权重。你在权重里没有位置,AI 就不会为你说话。搜索不到你 ≠ 你不在线;但 AI 不认识你 ≈ 你不存在。
第二,训练数据的偏见是结构性的。 进入权重需要两个条件。被写在某个地方,而且写得足够多、足够一致。AI 的认识天然偏向英语世界,偏向互联网高密度人群,偏向被反复报道的名字。排行榜就是这面镜子的反射。满分线上站满了欧美文娱巨星和历史人物。普通人连进都进不去。
第三,幻觉不是 bug,是镜子本身。 AI 编造你的生平,不是因为坏。它的运作方式就是补全。它被训练成补全一切——你给它一个名字,它就往下写。它不在乎写的对不对。这个问题没有技术上的终极解法。补全一切和不确定就不说是互斥的目标。
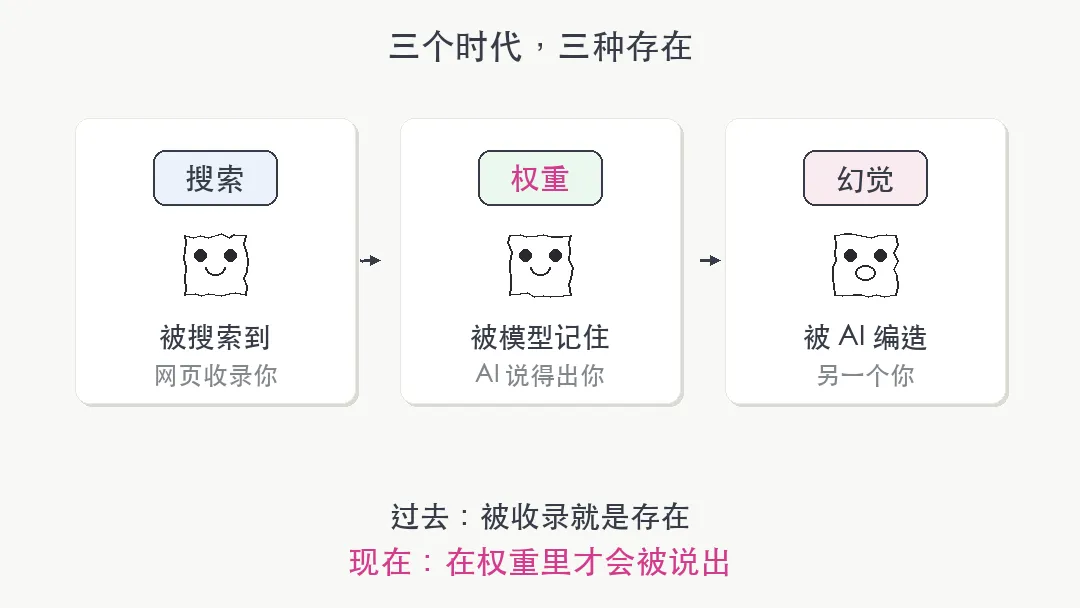
去玩玩吧
回到开头那个问题:AI认识你吗?
去 intheweights.com 敲一下自己的名字。可能是个惊喜,可能是场幻觉,也可能,什么结果都没有。
搜索引擎时代,被收录就是存在。在大模型时代,在权重里也许才是新的通行证。
快去玩玩,看AI是否认识你?

参考来源
- • intheweights.com — 网站及公开 API
- • techcrunch.com/2026/06/20/in-the-weights-is-your-new-ai-centric-vanity-search — TechCrunch 报道
- • aiweekly.co/alerts/in-the-weights-scores-how-strongly-ai-models-know-who-you-are — AI Weekly 报道
- • the-decoder.com/website-in-the-weights-shows-whether-ai-models-know-who-you-are — The Decoder 报道
- • telescoper.blog/2026/06/22/are-you-in-the-weights — 博主实测体验
- • thomasdimson.com — Thomas Dimson 个人网站
- • x.com/wjosephflynn — Joey Flynn X主页
