 夜雨聆风
夜雨聆风声明:【好玩的AI】单独开了一个系列,主体内容来自我,文档生成及排版来自AI工具,旨在记录自己学习AI的实际进展,并且给那些还在犹豫徘徊的读者一点参考。
本期想要传达的主要观点是:AI可以帮助我们跨越一些专业领域的学习障碍!
我一直觉得音乐和文字、绘画一样,是一种独特的表达方式,但我和音乐的关系只有两层:一是在KTV唱歌不跑调(虽然有些音高唱不上去),二是时不时被HIFI设备诱惑下单——我也尝试学习音乐,甚至学习乐器,但是现在也不过是能在midi键盘上弹出调来,左手和弦都合不进去。
搜索“音乐+AI”会出现很多AI创作音乐的app——但这不是我要的——这些AI创作只要求提供歌词、意境、节奏,然后就生成出一首歌曲——这不是我的音乐。我还是想要将每一个音符都掌握在自己手里,AI可以参与,但只是能工具,不能是决策方!
于是我开始想要“曲线救国”,用软件和AI绕开我过不去的障碍——比如:
左手合不进去,那就多建一条音轨咯~~
不会那么多乐器,用DAW+midi实现咯~~~
脑子里有旋律记不下来,那~~~是不是可以让计算机或者AI来帮忙?
🎵 缘起:不识谱的人,也想作曲
我学不会乐器,看不懂五线谱和简谱。但这并不妨碍我脑海里偶尔蹦出旋律。
哼出来,录下来,然后呢?就没了。那段旋律永远只能躺在手机录音里,无法变成可以被编辑、被分享、被演奏的东西。
我想要的是:对着手机哼一段旋律,它自动识别成 MIDI 文件,我直接拖进 GarageBand 里编曲。
听起来不难吧?
天真。非常天真。
🔍 发现与阻碍:每一个 App 都在劝我放弃
我去应用商店搜了一圈。
有"哼唱识曲"的——但那是用来识别现成歌曲的,不是把我的哼唱转成乐谱。
有专业乐谱软件的——打开一看,界面像飞机驾驶舱,我要的是谱子,但是我连谱子都不会写;
专业的midi宿主软件,比如Cubase有哼唱转midi的功能,但是功能太强大了,眼花缭乱到我连入口都找不到;
还有在线工具的——上传音频,等待分析,然后弹出付费墙,"请支付 68 元/月解锁完整功能"。68 块钱倒不是给不起。但问题是,我不确定它能不能满足我的需求。万一交了钱发现识别的音符全是错的呢?
想想AI见多识广,我就找 AI聊了聊,AI反馈了一些免费和没有注册要求的在线功能或者app,结果我一测试,几部,既不免费,也要收费!AI承认错误之后,悠悠地说:
"你有没有想过自己学一下简谱?你的条件(能唱、有 MIDI 设备)其实很好,简谱规则很简单(1-7 对应 Do-Re-Mi),可能比你找工具还快。"
!我被 AI 嘲讽了!它建议我先去上个音乐课!
但我哪是那种乖乖听话的人。
🛠️ 第一次方案:从零到一,React + Spotify Basic Pitch
我跟 AI 说:少废话,这功能别人能有,我就能做!我命令你,给我开发一个!
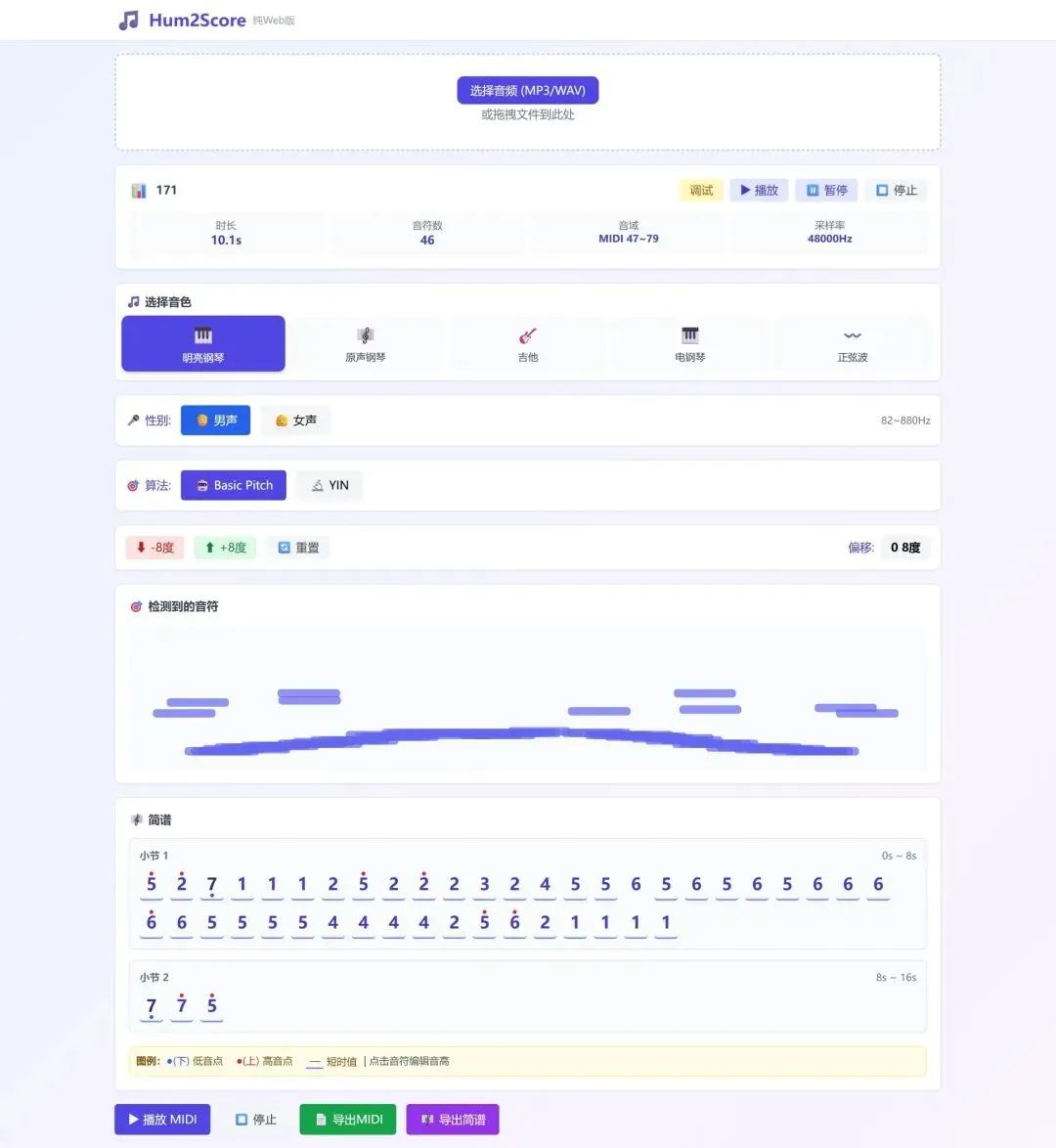
于是开始厘清需求:纯 Web 应用,不需要安装任何东西,打开浏览器就能用。上传或录制一段哼唱,自动检测音高,生成 MIDI 文件和简谱。
技术选型我是交给AI做的决定,它说:
- React 18 + TypeScript:组件化 UI,类型安全
- Vite 5:构建工具,开发体验极快
- Web Audio API:浏览器原生解码 MP3/WAV
- Tone.js:MIDI 合成播放
- Spotify Basic Pitch:音高检测引擎
技术方案中的Basic Pitch音高检测引擎,是 Spotify 开源的深度神经网络模型,专门针对音高检测训练过,应该比传统信号处理算法准得多。我在 https://basicpitch.spotify.com/ 测试过,我唱的1234567他能识别得不错,直接下载midi到Garageband听了,虽然有杂音符,但是基本可行。
于是在 AI 的帮助下,我们搭起了脚手架:一个文件上传区域、一个音色选择器、一个音符可视化网格、一个简谱展示区,外加 MIDI 导出和简谱导出按钮。
一切看起来都像模像样。
😫 效果不理想:AI 说"我们换个算法吧"
第一次测试,我满怀期待地上传了一段哼唱。结果出来——识别出一堆音符,但没有一个是对的。音高几乎全错,旋律也完全对不上。
我不服气,又试了一次。十几次之后,我开始怀疑自己是不是天生五音不全。
AI 开始分析和修改代码:调整滤波器参数、修改帧大小、优化自相关阈值……改了一轮又一轮,效果时好时坏,但始终达不到官网 demo 的水平。
然后 AI 提出了一个方案——"要不我们换一个算法?"
它推荐了 YIN 算法——这是一个 2002 年发表的经典信号处理算法,被 Audacity、REAPER 等专业音频软件广泛采用。不需要加载模型,纯本地计算,精度号称能达到 0.1 个半音。
我把两种算法做成了可切换的 UI。点一下"Basic Pitch",再点一下"YIN",实时对比结果。
您猜怎么着?
两种算法的结果,一模一样!
💡 峰回路转:"你的 Basic Pitch,从来没跑起来过"
我说:这不科学啊,先别管YIN,就是basic Pitch,我在官网 demo测试过效果不错的,怎么到你这就不行了?——是的,我说了那句我最讨厌的台词:别人挺好的,那你想想自己出了什么问题?!错哪了!
AI 开始逐一排查代码。看了半天,它突然沉默了。然后说了一句让我至今难忘的话——
"等等。你用的这个 CDN 链接——
unpkg.com/basic-pitch@0.4.1——这个包压根不存在。"
我:!!!【此处省略好几百字——这些字平台肯定不让发】
AI 解释说,它当初写代码的时候,直接从某个第三方教程里复制了 CDN 链接,但那个链接指向的 npm 包"basic-pitch"其实是一个跟 Spotify 毫无关系的个人项目。Spotify 官方的包名叫 @spotify/basic-pitch。
也就是说,从第一天起,我们的"Basic Pitch 引擎"就从来没有加载成功过。每次加载都 404,然后静默回退到 YIN 算法。所以两个按钮其实都在跑同一个 YIN 算法,结果当然一模一样。
而且更离谱的是——回退逻辑也没有任何日志输出。用户在浏览器控制台里都看不到任何报错提示。一切都在静默中优雅地失败着。
那一刻,我的心情很复杂。
一方面觉得"擦,浪费了这么多时间";另一方面又觉得"能发现这个问题,也算没白折腾"。最终我没崩溃,是因为我这前面一段用的都是免费的大模型,还不至于心疼token到发疯发狂的地步!
🔧 修复后的结果:终于,但它还不够
发现问题之后,修复很简单:
用 npm 安装 @spotify/basic-pitch官方包将 ~8MB 的 TensorFlow.js 模型文件复制到本地 public/目录音频重采样从 44100Hz → 22050Hz(模型要求) 使用官方 API outputToNotesPoly()替代手写后处理
这次,控制台终于能打出 [BasicPitch] ✓ 模型加载完成 了。
效果呢?比之前好了很多——音符数量基本对上了,旋律的整体走向也大致正确。但对于比较复杂的哼唱(比如有颤音、滑音、或者不太稳定的音准),偏差依然存在。
实事求地说:它现在可以作为一个"旋律速记"的参考工具——你哼一段,它给出大概的音高走向和节奏框架,你再到真正的编曲软件里手动修正。它做不到"一次识别,直接可用"的程度——比如我唱1234567,它识别出来的在主旋律之外还有一些噪音——难道我唱得是和弦?
但是整体的旋律差不多,我可以修修改改之后将这个旋律体现在Garageband上,基本上满足我最开始的诉求。
这个结果,既让人欣慰,也让人清醒。
📐 技术复盘 应知应会:2个音高引擎
做到这里了,这个项目的核心技术,音高引擎,也该了解了解了。我请AI做了个应知应会的名词解释。
🅰️ Basic Pitch(Spotify 官方)
类型:深度神经网络(LSTM + CNN)
原理:用百万级标注音频训练,能从复杂的音频信号中直接提取音符起止、音高和力度
优缺点:抗干扰能力强、对颤音/滑音处理得好,但需要加载 ~8MB 的 TensorFlow.js 模型,首次推理较慢
部署方式:官方 npm 包 @spotify/basic-pitch,WebAssembly + TensorFlow.js
🅱️ YIN 算法
类型:经典信号处理算法(2002 年发表)
原理:通过累积均值归一化差函数,在信号中寻找基波周期。简单说就是:把信号跟它自己的"延时版本"做比较,找到最匹配的延迟时间,然后算出频率。
优缺点:纯本地计算,无需加载模型,速度快,精度约 ±0.5 半音。但对颤音、噪声敏感,人声的不稳定性容易导致误检。
🎓 收获与展望:我学会的,不止是写代码
这次经历,我学到了三件事:
第一,别全部相信AI。
AI大概率是回避型人格,一个方案不行,就用另一个方案试试,用战术的勤奋掩盖战略方向的错误——一种没有功劳也有苦劳的态度。
AI是个任劳任怨的渣男——会杜撰,会臆想,会无事生非,会诚恳认错——但是都可能再犯。所以,
AI 生成代码时引用的 CDN 链接、第三方库版本、API 文档——这些都有可能已过期、不存在、或者压根是编造的。每次都要亲自验证。
第二,日志是最好的朋友。
如果代码的静默回退路径第一时间就打了日志,这个 bug 在第一次测试时就能被发现。不要相信"一切正常"的静默代码。
这其中还有好几次修改之后,原来正常的功能也不正常了的情况,因为之间更换了不同的大模型,因此,他们的记忆有可能不连续,但是日志文件,可以避免AI的思路断联。
第三,AI是队友,不是神。
它能快速搭建脚手架、写大量代码、提供多种方案。但它也会自信满满地写出根本不存在的依赖。作为使用者,必须有判断力——AI 的效率 + 你的判断力 = 真正的战斗力。
再直白一点,如果甲方是小白,那就只能受乙方判断的牵制,因此,我们可以不亲自实现,但是该懂的技术要点、业界风向、开源方案,这些调研做的越充分,被忽悠的几率和试错成本就越少——而这些,AI可以在传统的搜索引擎基础上,提供更为丰富的信息,效率也更高,所以,动手之前,充分调研,还是很有必要的。
我后来在互联网找到不少现成的工具,比如:哼唱转MIDI音符【https://www.ud5.com/tool/audio-to-midi-approximator】,在线AI音频转 MIDI转换器【https://www.openmusic.ai/zh/audio-to-midi】,还有即便是我实现的这个basic pitch的方案,其实也已经有了“voice-note-to-midi”的skill【https://hub.cocoloop.cn/skills/5726】~~~这说明我的调研远远不够。这些作为“重复的轮子”的项目,如果只是为了探索开发应用倒是可以做做,真的要是为了生产力的话,集成现有项目可能更适合。
至于后续的方向,我想到了几个:
- 本地模型优化:目前的 Basic Pitch 模型是通用版本,如果能用哼唱数据做微调(Fine-tune),准确率应该能大幅提升。
- 音符编辑器:在 Web 端实现一个可拖拽的音符编辑器,让用户手动修正检测偏差,——这个功能很实用,只是在代码测试阶段,发现UI很好,但是修改的音高存盘有问题,还在查。

- 节奏检测:目前的算法只检测音高,节奏全靠音符时长来推断。如果能加入独立的节拍检测模块,输出会更接近真实乐谱。
🔁 这个案例的迁移价值:这件事的底层逻辑
写到最后,我想聊聊这件事的通用价值。
其实,"一个不识谱的人想哼唱作曲"这个需求,本质上是一个典型的"个人痛点 + 技术解决"场景。类似的需求还有很多:
不会设计,但想做一张海报 → Canva / AI 生图 不会剪辑,但想做一段短视频 → CapCut / AI 视频 不会编程,但想做一个工具 → Cursor / Claude / Copilot 不会外语,但想翻译一本书 → DeepL / ChatGPT
这些场景的共同模式是:专业技能的门槛被 AI 大幅降低了,但还远没有消失。
你要做的不是等 AI 完全替代专业人士,而是主动把自己当成"产品经理",去拆解需求、评估方案、验证结果。AI 帮你执行,你来判断方向。
这比学会弹钢琴简单多了。

如果你也有类似的想法——想用 AI 解决自己的某个"专业门槛"——我的建议是:
别等。直接试。
会踩坑,会被 AI 误导,会浪费很多时间。但最终,你会得到一个属于自己的工具——它可能不完美,但它属于你。而且,下次你就知道怎么避坑了。比如,先检查那个 CDN 链接是不是真的能用。
纸上得来终觉浅——学习AI还是动动手最快!学到和AI工具相关的只是操作技能,可能会随着技术发展更加简单易用,但是同时还会学到自己思维方式和决策方式的调整,这个是终身可用的,不会浪费。
— END —
