 夜雨聆风
夜雨聆风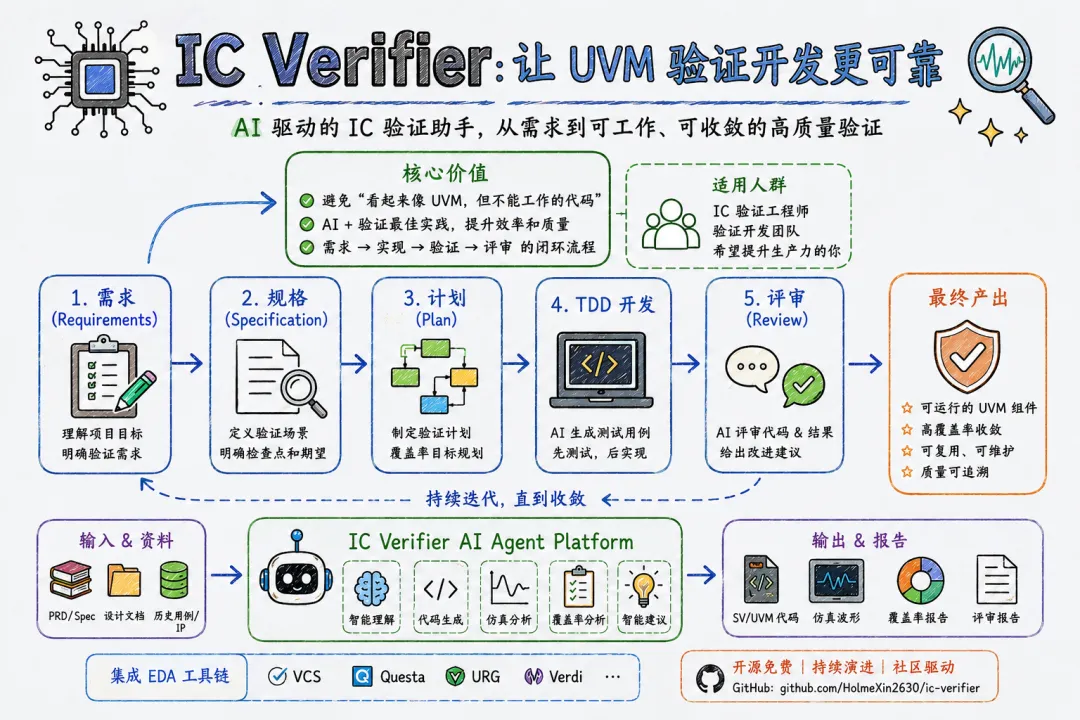
一周没更新,后台炸了
上周休假出去浪了一圈,整整一个星期没更新公众号。本来以为大家会把我忘了,结果后台私信和互动反而更多了。
看来大家对 UVM/UVC 的开发确实很感兴趣,这个话题的热度远超我的预期。
本来我在想,怎么能把 UVC 的开发介绍做得更浅显易懂一些。但是转念一想——现在都是 AI 时代了,未来的 UVC 开发,完全可以交给 AI 来做啊!
于是旅游回来以后,我就迫不及待地尝试了一下。
结果……一言难尽。
第一次尝试:AI 的 UVM,语法都写不对
我先用 mimo-v2.5-pro,让它按照我之前介绍的 UVC 开发思路,去开发一个 APB UVC。
信心满满地等它输出,然后一看代码,我人傻了:
// AI 生成的"精彩"代码class apb_driver extends uvm_driver; def run_phase(self, phase): // 这是 Python 吧?!while True: item = self.seq_item_port.get_next_item() self.drive(item)function drive(item): // SV 里混 Python?if item.direction == "READ": self.vif.paddr = item.addr// ...我:???这是 UVM?
UVM 里混杂了 Python 的 def、self、while True,还有一堆不伦不类的语法。这要是能仿真通过,我把键盘吃了。
不死心,我又切到了 DeepSeek v4,结果也没好到哪里去。虽然语法错误少了,但生成的代码风格诡异,各种反模式层出不穷。
原因分析: 用于 AI 训练的 SystemVerilog/UVM 代码量,相比 Python、Java 这些主流语言,实在是太少了。AI 对 UVM 的理解,基本停留在"看起来像 UVM"的程度。
第一轮突破:给 AI 加上"红绿灯"——TDD
既然 AI 写的代码质量不行,那怎么才能让它知道自己写错了?
答案是:测试!
我让 AI 先写了一套 APB 的基本测试用例:
// 基础测试用例class apb_basic_test extends uvm_test;// 1. 单次读操作// 2. 单次写操作// 3. 随机读写操作// 4. 连续读(back-to-back read)// 5. 连续写(back-to-back write)// 6. 读写交替操作endclass然后告诉 AI:"你按照 TDD 的方式开发 UVC,写完以后必须用仿真工具跑通这些测试,才算完成。"
这一步效果立竿见影!
AI 开发的 UVC 终于能编译通过、仿真成功了。但是……实际操作的时序还是有些问题。比如 APB 的 setup phase 和 access phase 时序不对,信号的驱动时机有偏差。
于是又继续来回迭代,让 AI 通过查看仿真波形(VCD)来识别自己的时序错误,然后修复。
折腾了好几轮,UVC 终于能跑起来了。
第二轮突破:Wavedrom——让 AI 正确"看懂"时序
时序问题一直困扰着我。
做芯片设计或验证的同学都知道,描述时序是一件非常麻烦的事情。尽管我们可以用自然语言描述,但要把一个时序描述清楚,自然语言的篇幅可能比 Verilog 代码还长。
比如你想告诉 AI:"在时钟上升沿,如果 PSEL 为高且 PENABLE 为低,则进入 setup phase,此时 PADDR 和 PWRITE 必须稳定;下一个周期 PENABLE 拉高,进入 access phase……"
光描述一个 APB 的基本读写时序,就要写一大段。而且 AI 还不一定能完全理解。
有没有一种好的交互格式,能让 AI 准确地知道各信号之间的时序关系?
这时候我发现了一个叫 WaveDrom 的东西。
“WaveDrom 是一个基于 JSON 格式描述数字时序图的开源工具。它使用一种叫做 WaveJSON 的语法,可以用简洁的 JSON 结构精确描述信号的波形时序。
官网:https://wavedrom.com/
举个例子,用 WaveDrom 描述一个简单的 APB 读操作:
{"signal": [ {"name": "PCLK", "wave": "p....."}, {"name": "PSEL", "wave": "01.0.."}, {"name": "PENABLE", "wave": "0.10.."}, {"name": "PWRITE", "wave": "0....."}, {"name": "PADDR", "wave": "x=x...", "data": ["addr"]}, {"name": "PRDATA", "wave": "x.=x..", "data": ["data"]}, {"name": "PREADY", "wave": "x.10.."} ],"config": {"hscale": 2}}用这种格式,我可以把时序精确地、结构化地告诉 AI,而不是用一大段自然语言去描述。
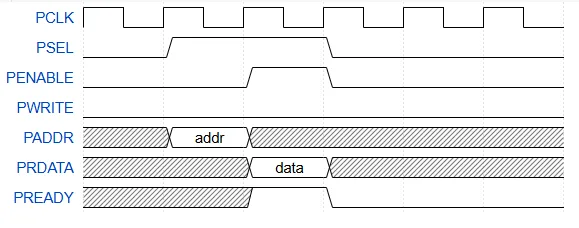
时序图效果
AI 拿到这个 JSON 以后,就能清楚地知道:
什么时候 PSEL 拉高 什么时候 PENABLE 拉高 什么时候地址和数据必须稳定 什么时候从设备可以返回数据
继续迭代 UVC,此时生成的代码时序已经比较准确了。
第三轮挑战:Guidelines——让 AI 写出"好"的 UVC
UVC 能跑、时序也对了,但这还不够。
UVC 毕竟是给别人用的,需要满足一些工程规范:
高内聚、低耦合:组件之间职责清晰 依赖注入原则:配置通过顶层注入,而不是底层自己去 config_db 里 get 避免递归式 config_db:不要到处乱 set/get,导致配置链路混乱 遵循 UVM Cookbook 的最佳实践
于是我把 UVM Cookbook 里的 guideline 做成 skill,用来指导 AI 生成 UVC。
然后……我就被拖进泥潭了。
问题一:Guideline 写得太抽象,AI 不理解
一开始我写的 guideline 比较简短:
“"代码要符合 OOP 思想,遵循高内聚低耦合原则。"
结果 AI 根本不买账。它"理解"的 OOP 跟我想要的完全不一样。
后来我发现,必须写成"正确示范"和"错误示范"的形式,AI 才能理解:
// ✅ DO: Use config to control active/passiveif (cfg.is_active == UVM_ACTIVE) begin drv = my_driver::type_id::create("drv", this);end// ❌ DON'T: Use config_db for config within UVM hierarchyuvm_config_db#(int)::get(this, "", "is_active", is_active); // WRONG但是这样一来,skill 的内容就变得非常大,很快就把上下文窗口占满了。UVC 迭代两轮,上下文就没了。
问题二:模型差异巨大
不同模型对代码的理解能力天差地别:
切换模型以后,之前好不容易调通的流程又开始出问题。
这一刻我深刻体会到:光靠 prompt 和 guideline,是不够的。
最终方案:代码模板化,脚本 + Prompt 两步走
折腾了好几天以后,我终于想通了一个道理:
“不要让 AI 做它不擅长的事情。
AI 擅长什么?填充逻辑、实现细节、处理变化的部分。
AI 不擅长什么?保证代码结构的一致性、遵循复杂的规范。
那怎么办?
脚本生成框架,AI 填充逻辑。
以前我不是开发过一个生成 UVC 的脚本吗?(uvc_gen)先把 UVC 的框架用脚本生成出来,再让 AI 去填充时序和具体的协议逻辑。
说干就干!
效果立竿见影——AI 生产出来的 UVC 非常符合我的预期了:
# 第一步:脚本生成 UVC 框架python3 uvc_gen.py -n apb -m single -v v1.0 -o ./my_project# 第二步:AI 填充时序和逻辑# 此时 AI 只需要关注 drive_trans() 和 rcv_data_phase() 的实现脚本保证了代码结构、命名规范、TLM 连接等"骨架"部分的正确性,AI 只需要往里面填"肉"。
env-builder:一个完整的 UVC 开发 Skill
搞定了上面这些问题以后,我把整个流程整合成了一个 Claude Code Skill——env-builder。
这个 Skill 由两部分组成:
1. uvc_gen:UVC 框架生成脚本
uvc_gen 是一个 Python 脚本,支持生成常见的 UVM 组件框架:
支持的模式:
single 模式:单 agent 类型(如 APB、SPI、I2C) mstslv 模式:主从类型(如 AXI、AHB) 多通道 env 层:支持多个 agent 的环境封装
设计原则:
遵循依赖注入原则:UVC 开发后向使用者提供 sequence_lib作为 API控制 agent 只能通过顶层的 cfg 依赖注入 去掉了递归式的 config_db,避免底层配置被破坏最终使用体验:把 UVC 当作 Python 的库一样简洁,最大化方便使用者集成和复用
# 安装npx skills add HolmeXin2630/ic-verifier -g# 使用(自动调用 uvc_gen)> /env-builder> Create an APB UVC with driver, monitor, and sequencer2. 开发 UVC 的流程
参照 Brainstorm 的思路,开发 UVC 的过程中 AI 会层层询问你的需求:
┌─────────────────────────────────────────────────────────┐│ Step 1: 需求澄清 ││ - 这是什么协议? ││ - 需要哪些组件?(driver/monitor/scoreboard) ││ - 使用场景是什么? ││ - 时序要求是什么? │├─────────────────────────────────────────────────────────┤│ Step 2: 生成 UVC 框架 ││ - 调用 uvc_gen 生成代码骨架 ││ - 生成 config、transaction、agent 等组件 │├─────────────────────────────────────────────────────────┤│ Step 3: 编写开发文档 ││ - 输出 spec(架构、接口、时序) ││ - 用户确认后继续 │├─────────────────────────────────────────────────────────┤│ Step 4: TDD 开发 ││ - 先写测试用例(RED) ││ - 填充实现逻辑(GREEN) ││ - 仿真验证(需要告知 AI 你的 EDA 工具) │├─────────────────────────────────────────────────────────┤│ Step 5: Review ││ - 调用 review-agent 审查代码 ││ - 检查 UVM 规范、命名、时序等 ││ - 发现问题则回到 Step 4 │└─────────────────────────────────────────────────────────┘在 TDD 开发过程中,你需要告知 AI 你所使用的 EDA 工具是什么(VCS、Xcelium、Questa 等),它会自动配置编译和仿真命令。

ic-verifier:一个面向 DV 的 AI Skill 技能包
env-builder 只是开始。
我的规划是开发一个完整的 IC Verifier 技能包,覆盖验证工程师的日常工作场景:
/env-builder | |||
/testplan | |||
/coverage | |||
/formal |
最终目标: 让 AI 成为验证工程师的得力助手,而不是一个"看起来像在帮忙,实际上在添乱"的工具。
总结:AI 开发 UVC 的正确姿势
经过这一番折腾,我总结出了 AI 开发 UVC 的几个关键点:
1. TDD 是必须的
不要相信 AI 一次就能写对。先写测试,再写代码,让仿真工具来验证。
2. 时序描述要结构化
用 WaveDrom 或类似的格式精确描述时序,而不是用自然语言"大概说一下"。
3. 框架和逻辑分离
用脚本生成框架(保证结构正确),让 AI 只负责填充逻辑(发挥它的创造力)。
4. Guidelines 要具体
"符合 OOP 思想"这种抽象描述没用,必须写成"正确示范 vs 错误示范"的形式。
5. 不同模型要区别对待
GPT-5.5、MIMO、DeepSeek 的表现差异很大,要根据实际情况调整策略。
项目地址
ic-verifier: https://github.com/HolmeXin2630/ic-verifier
欢迎安装试用:
npx skills add HolmeXin2630/ic-verifier -g欢迎大家使用,有任何问题和建议,欢迎在 GitHub 上提 issue!
