在使用 langchain 基础框架做智能体开发时,我们需要维持模型的上下文记忆。常见的做法有设置 checkpoint 定义InMemory组件。但常见的操作大多无法满足定制化开发。本文主要通过分析 langchain 组件弊端来实现自定义分层记忆,使智能体的单个会话支持更多轮次对话,同时不易丢失上下文。一、Langchain 的记忆是怎么做的:短期记忆与长期记忆
在聊之前,先分析一下 LangChain 官方的记忆机制。1.1 LangChain 记忆的两大分类
LangChain 的两类记忆体系:短期记忆和长期记忆。所有的 Memory 类,都是这两类的变体。短期记忆就是「当前对话还能记住什么」,核心特点是直接以原始消息形式存在于 messages 列表里,模型每一轮都能完整看到。| 记忆类型 | 原理 | 适用场景 |
|---|
| ConversationBufferMemory | 完整保留所有对话消息,不做任何裁剪 | 短对话、Demo、对上下文完整性要求极高 |
| ConversationBufferWindowMemory | 只保留最近 K 轮对话,更早的直接丢弃 | 中等长度对话,控制 Token 成本 |
| ConversationTokenBufferMemory | 按 Token 数裁剪,超过阈值就丢掉最早的消息 | 严格控制 Token 上限的场景 |
本质问题:都是「存多少、丢多少」的选择题,没有信息压缩。对话一长,要么 Token 无限增长,要么上下文丢失。长期记忆是把历史信息压缩、提炼后保存,需要的时候再拿出来用。核心特点是信息密度高、不占用太多上下文空间。| 记忆类型 | 原理 | 适用场景 |
|---|
| ConversationSummaryMemory | 用 LLM 把历史对话逐轮压缩成一段摘要 | 长对话、需要保留核心信息 |
| ConversationSummaryBufferMemory | 摘要 + 窗口混合:最近 K 轮保留原文,更早的压缩成摘要 | 平衡效果与成本,最常用的方案 |
| VectorStoreRetrieverMemory | 把历史对话向量化存到向量库,需要时检索相关片段 | 超长时间记忆、跨会话知识沉淀 |
其中ConversationSummaryBufferMemory是官方最推荐的长对话方案,也是 SummarizationMiddleware 的设计思路。
1.2 langchain.agents.middleware.SummarizationMiddleware
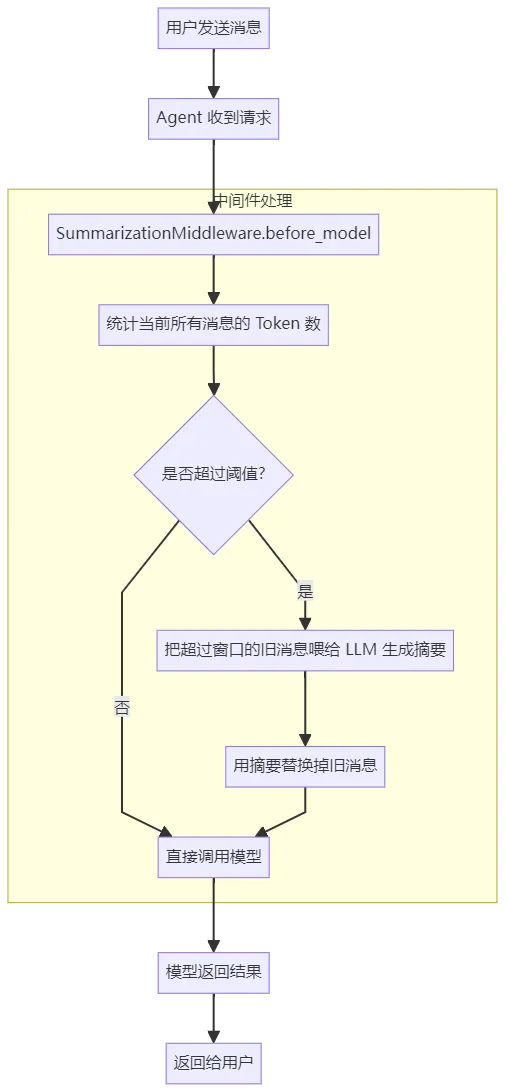
LangChain 推出 Agent 新 API 后,记忆不再绑定 Chain,而是做成了中间件(Middleware)的形式,挂在 Agent 的模型调用前后。这就是 SummarizationMiddleware,官方对长对话记忆的推荐方案。看起来似乎很完美,主要就是摘要 + 短期窗口的经典分层记忆设计。二、官方中间件的不足
2.1 压缩即删除
官方中间件的逻辑是:超过阈值 → 旧消息压缩成摘要 →直接从消息列表里删掉旧消息。注意,这个修改是直接作用在 Agent 的状态上的。如果你用了 LangGraph 的 Checkpointer 持久化状态,那旧消息就真的从存储里消失了。结果是什么?用户打开会话详情,只能看到最近 10 条对话,之前的全没了。对于需要完整会话留痕、安全审计、工单回溯的业务场景,这近似是产品级事故。官方的设计假设是:「记忆只服务于模型推理」。但真实业务里,记忆还要服务于前端展示、用户回溯、业务审计。这两个需求是冲突的。
2.2 每轮都重复触发
官方中间件没有单独的字段记录上次压缩到哪了,每一轮用户提问,都要重新完整扫描所有消息、统计 Token、判断是否需要压缩。每次压缩都是把所有旧消息完整重新摘要一遍,不是增量合并对话越长,每次摘要的输入 Token 越多,成本呈线性增长举个例子:100 轮的对话,官方中间件可能会触发 10 次摘要,每次都要喂几十轮的历史给 LLM。而增量合并只需要触发 10 次,每次只喂新增的几轮。两者 Token 消耗差一个数量级。2.3 同步阻塞执行
中间件挂在 before_model 钩子上,在模型调用之前执行。也就是说,用户发完消息,得先等摘要生成完,模型才会开始推理。摘要生成可能要等 2~3 秒,然后模型推理再等几秒First Token需要很久,用户发完消息要等五六秒才看到第一个字
三、官方的补救措施
LangChain 官方其实也意识到了这个问题,给出了两种「官方认可」的解决方案,但都有各自的局限性。3.1 DeepAgents 版:后端 Offload 机制
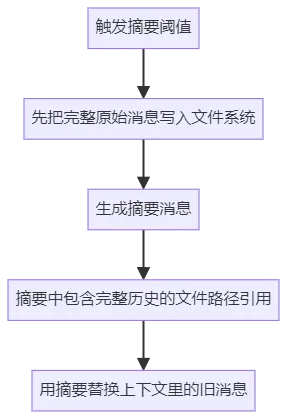
在 DeepAgents 框架(LangChain 的高级 Agent 框架)中,官方对 SummarizationMiddleware 做了增强,增加了后端卸载(Backend Offload)机制。完整历史不会丢:压缩前会把所有原始消息写入后端文件系统存档摘要带「档案号」:生成的摘要消息里包含完整历史的文件路径引用,相当于留了个索引官方文档原文:"The summary message includes a reference to the file path where the full conversation history was stored."默认是文件系统存储:原生实现存本地文件,分布式部署、多实例共享、查询检索都很麻烦(虽然可以扩展对接数据库,但存储范式依然是文件式的)不是给前端展示设计的:Offload 是为了 DeepAgents 的「深度思考」和「任务回溯」,不是给用户 UI 看的需要单独安装 deepagents 包:不是 langchain 自带的,多数普通项目不会引入结构化程度低:文件里的原始消息解析、筛选、分页都需要写代码处理总而言之,DeepAgents 版虽然保留了完整历史,但更像是「后台存档」,不是「前端可用的业务数据」。
3.2 官方推荐的生产级架构:两层存储分离
如果你不用 DeepAgents,官方论坛给出的生产级最佳实践是这样的:"The checkpointer is not a message store, it is a LLM context management tool."
—— LangChain 官方论坛
| 层级 | 存储 | 用途 | 谁来管理 | 是否会被压缩修改 |
|---|
| 推理层 | LangGraph Checkpointer | 给 LLM 提供工作上下文 | LangGraph 自动管理 | ✅ 是,压缩后旧消息会被替换 |
| 展示层 | 自己的 messages 表/Redis | 给前端展示完整历史 | 应用代码管理 | ❌ 否,只追加不删除 |
"If you need full chat history for your UI, the recommended pattern is to maintain your own chat history store separately from the LangGraph state. Use the graph state for what the LLM needs to see, and use your own store for what the UI needs to see."
—— LangChain 官方论坛,2026 年 4 月
如果你需要给 UI 展示完整聊天记录,推荐的模式是:独立于 LangGraph State,维护你自己的聊天历史存储。图的状态存 LLM 需要看的内容,你自己的存储存 UI 需要展示的内容。
3.3 So?
官方推荐的「两层存储」思路是对的,但它只给了个方向,具体落地还有一堆问题要解决:摘要压缩逻辑要自己写:官方只说「你自己存一份」,但怎么压缩、什么时候压缩、压缩后怎么合并,全得自己搞没有增量合并机制:官方 SummarizationMiddleware 是全量重摘要,每轮都重复喂历史,Token 成本高同步阻塞执行:压缩在模型调用前同步跑,影响First Token延迟没有压缩节奏控制:容易连续触发,也容易长时间不触发总而言之,官方只告诉我们「要分开存」,但怎么存、怎么压缩、怎么控制节奏,这些还是得我们干。所以我干脆基于这个思路,设计了一套完整的分层记忆架构,把上述问题一次性都解决了。
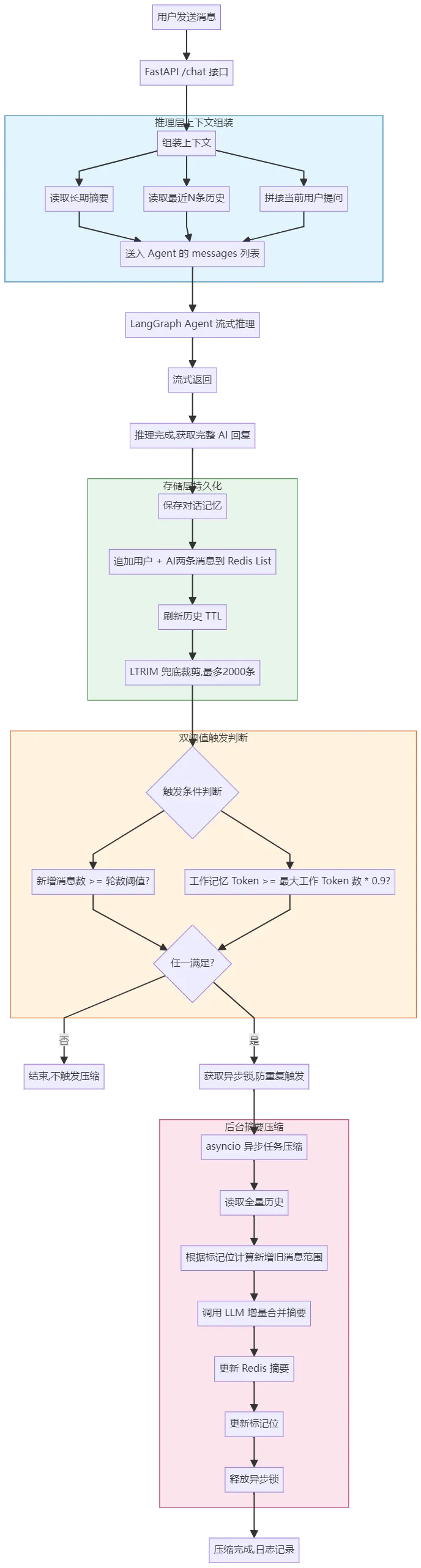
四、解决方案--分层记忆架构思路
既然官方方案满足不了生产需求,那我们就自己造轮子。存储层:Redis 永久存全量原始对话,给前端展示、业务审计用推理层:只把「长期摘要 + 最近 N 轮」喂给 LLM,控制 Token 成本和推理效果五、核心设计亮点
5.1 增量合并
用 Redis 存一个标记位,记录上次压缩时的总消息条数。每次压缩只取「上次压缩后新增的旧消息」去合并,不会把已经摘要过的内容再重复喂给 LLM。对话越长,收益越明显:官方中间件每次都要全量重喂所有历史,累积 Token 消耗呈平方级增长;而增量合并方案避免了对已摘要内容的重复计算,长对话下 Token 成本可降低一个数量级。5.2 异步后台压缩
压缩逻辑放在异步任务里后台跑,用户的流式输出完全不受影响。用户发完消息立刻就能收到回复,摘要在后台默默生成,感知不到任何延迟。再加一把异步锁,防止用户快速连发消息导致重复触发压缩任务。5.3 双阈值触发
工作记忆 Token 超 90%:防止单条超长文本(比如用户粘贴一大段日志)直接撑爆上下文5.4 Redis 分层存储
| Key | 类型 | 作用 |
|---|
会话Key:{user_id} | Hash | 用户会话列表(元数据) |
对话记录Key:{thread_id} | List | 完整对话历史,前端展示用 |
摘要Key:{thread_id} | String | 长期记忆摘要,推理用 |
摘要标志位Key:{thread_id} | String | 压缩标记位,记录上次位置 |
5.5 增量摘要的权衡与兜底机制
增量合并虽然大幅降低了 Token 成本,但它有一个天然缺陷:信息衰减。原因:每一轮合并都是基于上一轮摘要 + 新内容,随着合并次数增多,最早的对话细节可能在层层提炼中被稀释甚至丢失。这是所有增量式摘要都绕不开的 trade-off。针对这个问题,我们设计了三层兜底机制:定期全量重算(周期性校准)每合并 N 次(比如 5 次),或对话总轮数达到阈值(比如 100 轮),就触发一次全量重摘要,用完整历史重新生成一份干净的摘要,清零累积的信息误差。这相当于在 "省钱的增量合并" 和 "保质的全量摘要" 之间找了个平衡点:平时用增量省成本,定期用全量校准质量。关键信息锚定(防丢失机制)在摘要 Prompt 中明确要求:用户身份、核心诉求、重要约定、已确认的关键事实这四类信息必须永久保留,不得在合并中被稀释。同时可以在 Redis 里单独存一个 key_facts 字段,用 LLM 从对话中提取结构化的关键事实列表,每次合并时强制注入摘要,确保核心信息不会丢。完整历史永远在存储层推理层的摘要可以丢细节,但存储层的完整对话历史是永久留存的。如果出了问题,随时可以用完整历史重新生成摘要,不会出现不可逆的信息丢失。这也是「存储层与推理层解耦」架构的一大优势 —— 推理层可以大胆做压缩,因为原始数据永远在底下兜着。
六、和官方中间件的完整对比
| 维度 | 自研分层记忆 | LangChain 官方中间件 |
|---|
| 前端完整历史展示 | ✅ 支持,永久保存 | ❌ 不支持,压缩即删除 |
| 压缩时机 | 异步后台,零阻塞 | 同步阻塞,推理前执行 |
| 合并方式 | 增量合并,只处理新增 | 全量重总结,重复消耗 |
| 计数机制 | Redis 持久标记位 | 无持久标记,每轮全量统计 |
| 业务定制 | 完全自主可控 | 通用封装,改造困难 |
| 会话删除清理 | 一键清理,无残留 | 数据混杂,清理不干净 |
七、适用场景
有前端会话展示需求的产品(聊天机器人、智能客服、Agent 平台)需要完整会话留痕的业务场景(安全审计、工单处置、客服质检)多端接入的系统(网页 + 钉钉/企微/飞书 + API,共用一套记忆逻辑)如果只是做个简单的 Demo、不需要展示历史,那直接用官方中间件就行,省事。但如果是要上线的产品,有前端展示和成本控制的需求,建议自己搞一套分层记忆。
八、写在最后
LangChain 这类框架,入门的时候确实香,开箱即用。但真到了生产环境、有具体业务需求的时候,还是得根据场景自己造轮子。核心的记忆、上下文管理这一层,自己可控才是最踏实的。你们的 Agent 记忆是怎么设计的?踩过哪些坑?欢迎评论区交流~
关于我:后续会持续分享 Agent 开发的实战踩坑经验,欢迎关注。
 夜雨聆风
夜雨聆风