 夜雨聆风
夜雨聆风
6月16日,Anthropic在官网正式发布了最新一期智能体AI应用研究报告——《Agentic coding and persistent returns to expertise》(智能体编程与专业知识的持久回报)。
这份报告堪称AI应用落地的一面镜子,它基于2025年10月至2026年4月期间约23.5万名用户、近40万场Claude Code交互式会话的隐私保护数据,深度剖析了三个核心命题:用户究竟在让AI做什么?人机协作的边界在哪?哪些人能在AI时代脱颖而出?
报告给出了一个极其清醒的结论:AI确实在大幅降低编程的门槛,但从未降低“专业”的门槛。Agentic Coding(智能体编程)的本质不是用机器替代人类,而是重新划定知识工作的价值边界。在当下,会不会写代码正在退居二线;取而代之的是,你是否具备深刻的业务洞察力,能否精准拆解问题,以及能否清晰界定技术约束与验收标准。
Part 01
跨越单点任务:AI已全面接管端到端工作流
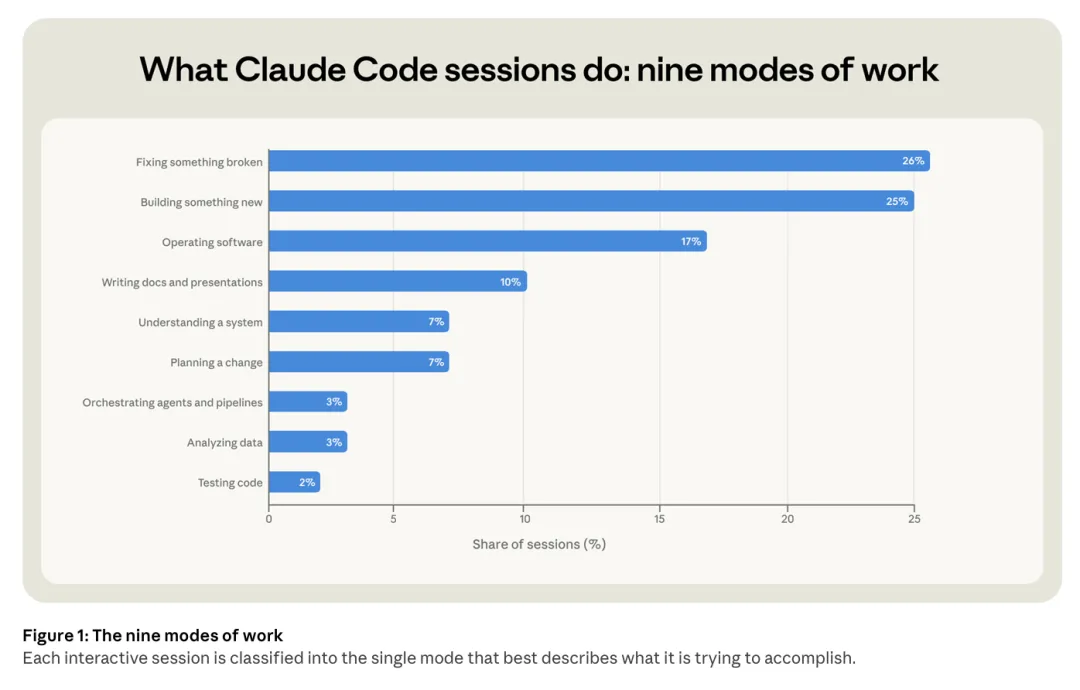
过去我们总把AI编程工具当成“高级代码补全插件”,但报告中的工作模式分布图(Figure 1)彻底打破了这一刻板印象。在真实的会话场景中,修复问题(26%)和构建新功能(25%)固然占据主导,但运行软件(17%)、撰写文档与演示文稿(10%)、理解系统与规划变更(各占7%)等非纯代码任务同样庞大。此外,编排Agent流水线、数据分析与测试代码也占据了近8%的份额。
更关键的数据在于,绝大多数会话并非“平地起高楼”:48%的会话围绕修改已有代码展开,17%用于探索现有代码逻辑,仅有14%是从零创建。这标志着Claude Code已经深度嵌入完整的工作流中,将技术工作从孤立的“写代码”动作,延展为涵盖部署、配置、分析、规划的全链路闭环。
Part 02
决策权大洗牌:人类定战略,AI抓落地
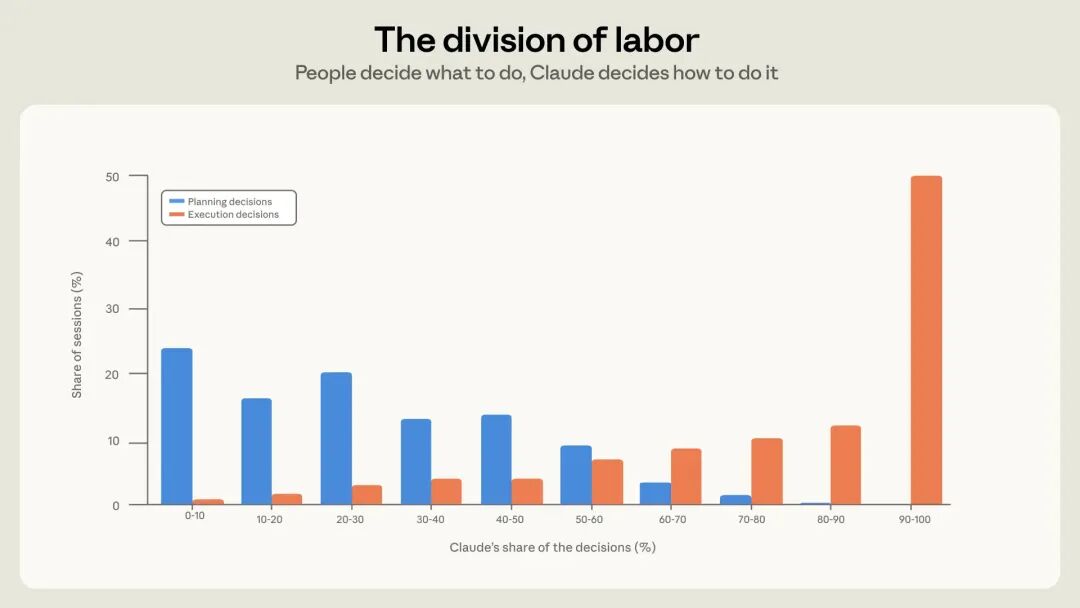
Anthropic在报告中将工作决策精准划分为两类:规划决策(做什么、怎么算完成)与执行决策(改哪个文件、用什么命令)。数据显示,在典型的会话中,人类承担了约70%的规划决策,而Claude则包揽了约80%的执行决策。
用一句话概括这种新型协作模式就是:“人类决定造什么,智能体决定怎么造。”当AI越来越擅长战术执行时,人类的价值便不可逆转地向战略层集中。定义问题、设定目标、把控边界、验收结果——这些曾经被代码语法掩盖的核心能力,如今成了决定AI产出质量的关键。
Part 03
撕掉“职级”标签:AI时代的专家只看“任务理解力”
在评估用户专业度时,Anthropic抛弃了传统的“职位头衔”体系,转而采用“任务特定”的动态评估模型。系统通过三个维度来判断用户是否为专家:能否精准表达任务需求、是否知道该让AI验证什么、能否敏锐发现并纠正AI的错误。
报告举了一个极具启发性的例子:一位资深工程师如果初次接触Rust语言,在这个特定任务中他依然是“新手”;相反,一位毫无Python基础的会计,只要能清晰阐述月末对账的复杂规则,并准确指出结账的边界条件,他在这个任务中就是当之无愧的“专家”。在AI时代,“专家”不再是一个静态的身份,而是你对当前问题理解深度的动态体现。
Part 04
认知杠杆效应:你越懂行,AI的产能越惊人
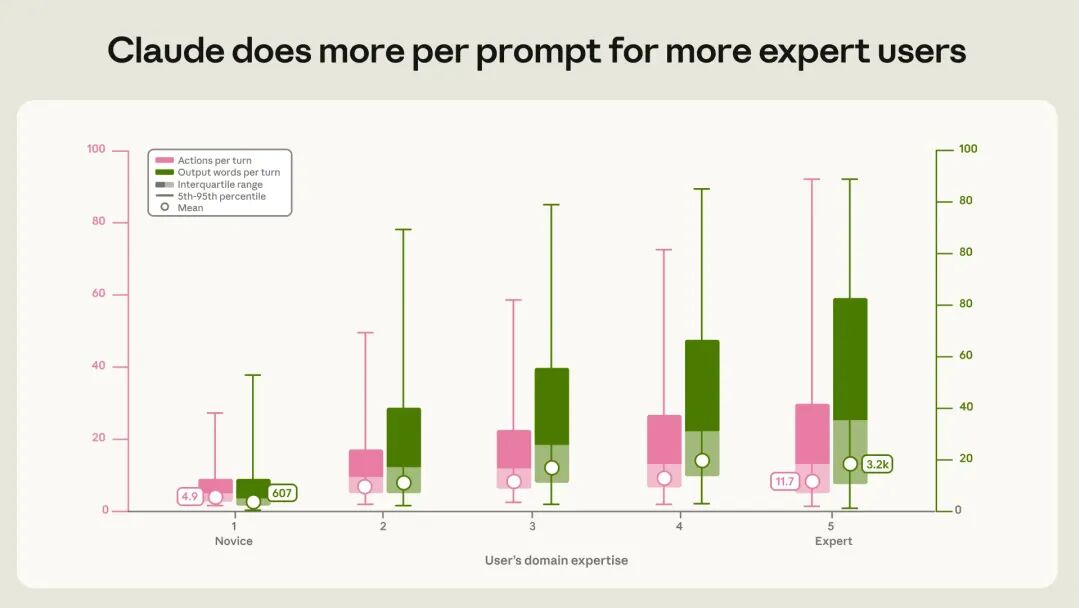
专业度究竟能带来多大的效能差异?数据给出了震撼的答案。在新手用户的会话中,每次提示平均仅触发5个AI动作,输出约600词;而在专家用户的会话中,单次提示可触发12个连贯动作,输出量飙升至3200词。
专家之所以强大,并非因为他们亲自敲了更多键盘,而是因为他们懂得如何“压榨”AI的产能。他们清楚该问什么、哪里容易出错、什么才算真正的交付。AI并没有让专业知识贬值,反而为那些真正懂业务的人提供了一个超级杠杆,让他们能以极低的边际成本撬动巨大的生产力。
Part 05
价值链条上移:从“修Bug救火”到“高价值构建”
对比2025年10月至2026年4月的数据,智能体应用的结构发生了显著进化。修Bug类的“救火”会话占比从33%骤降至19%;与此同时,运行软件、写作与数据分析等高阶任务占比大幅攀升。
伴随任务结构的升级,任务的经济价值也水涨船高。基于自由职业平台定价的粗略估算显示,这7个月内平均任务价值上涨了27%,其中构建类任务涨幅高达43%。这说明AI正在从低效的“补洞”工具,蜕变为承担复杂、高价值任务的端到端引擎。对于组织而言,真正的转型不是教员工写Prompt,而是重新设计人与Agent协同完成高价值任务的新流程。
Part 06
拒绝主观体感:用“硬核证据”定义AI协作成功
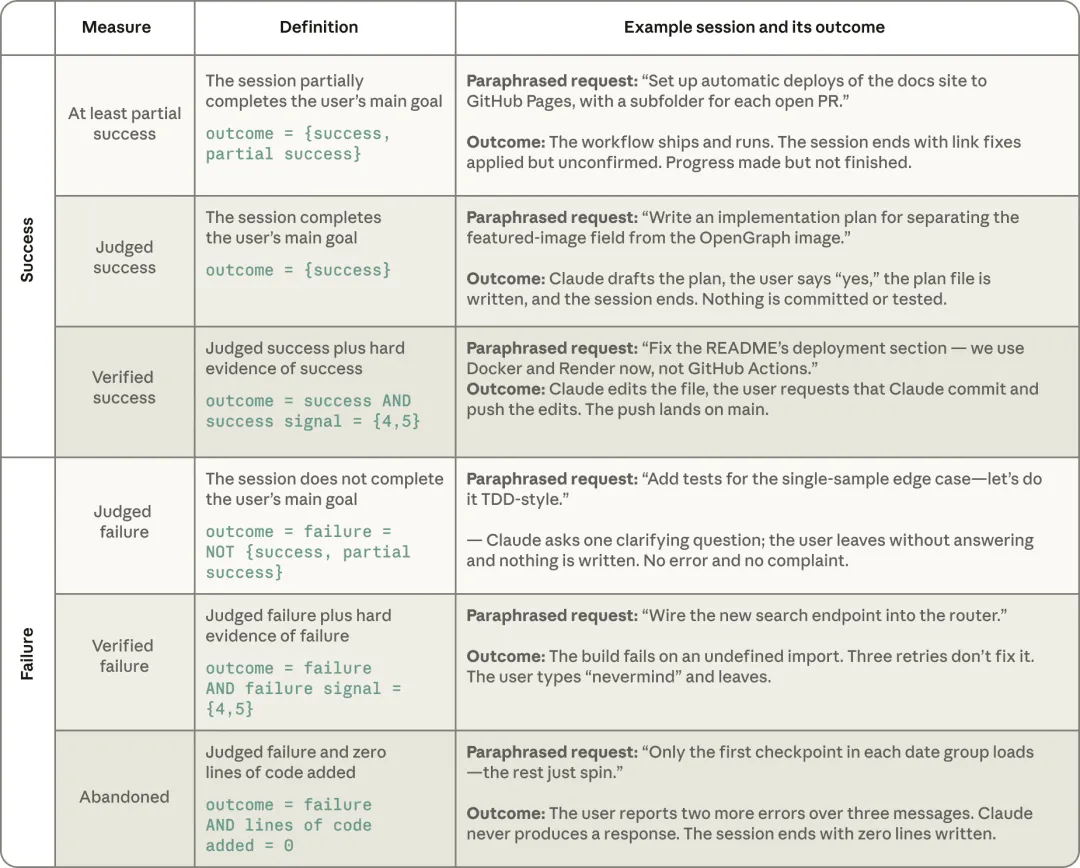
为了避免“感觉良好”的虚假繁荣,Anthropic建立了一套严苛的成功评估体系。所谓的“验证成功(Verified Success)”,不仅要求AI完成了用户目标,还必须附带硬证据——如代码提交(Commit)、PR合并、测试通过或用户的明确确认。
同时,报告也精准定义了失败:包括报错、测试未过、多次重试,以及最致命的“放弃(Abandoned)”——即任务失败且未产生任何代码。这种基于客观事实的评估框架,让后续关于成功率的洞察具备了极高的商业参考价值。
Part 07
破局关键:跨越“新手到中级”的专业鸿沟
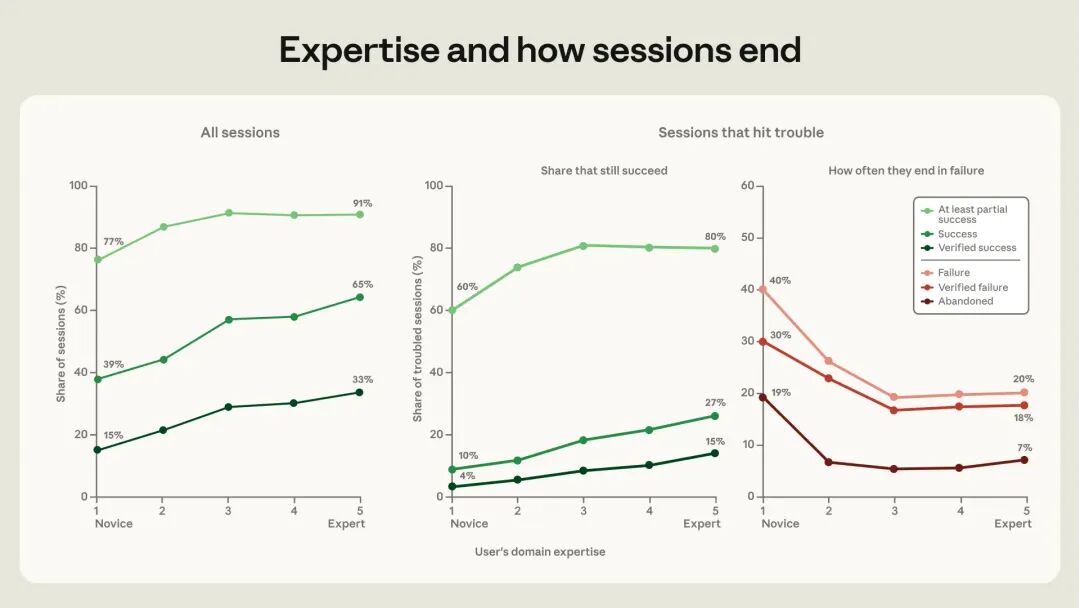
在严格的验证标准下,新手会话的成功率仅为15%,而中级及以上用户则跃升至28%-33%。这条增长曲线揭示了一个极其重要的规律:AI时代最大的红利,并不属于金字塔尖的顶尖专家,而是属于那些刚刚跨越“新手到中级”鸿沟的人。只要具备基础的领域理解,就能拿走绝大部分效能红利。
在遭遇困难时,这种专业鸿沟更为致命。在陷入麻烦的会话中,新手最终翻盘的概率仅有4%,而专家高达15%;新手遇到问题直接放弃的比例高达19%,其他用户则控制在5%-7%。使用AI的核心竞争力,往往不在于“一次说对”,而在于出错后能否凭借专业直觉把AI拉回正轨。
Part 07
能力平权:非技术岗位的“代码自由”与业务底线
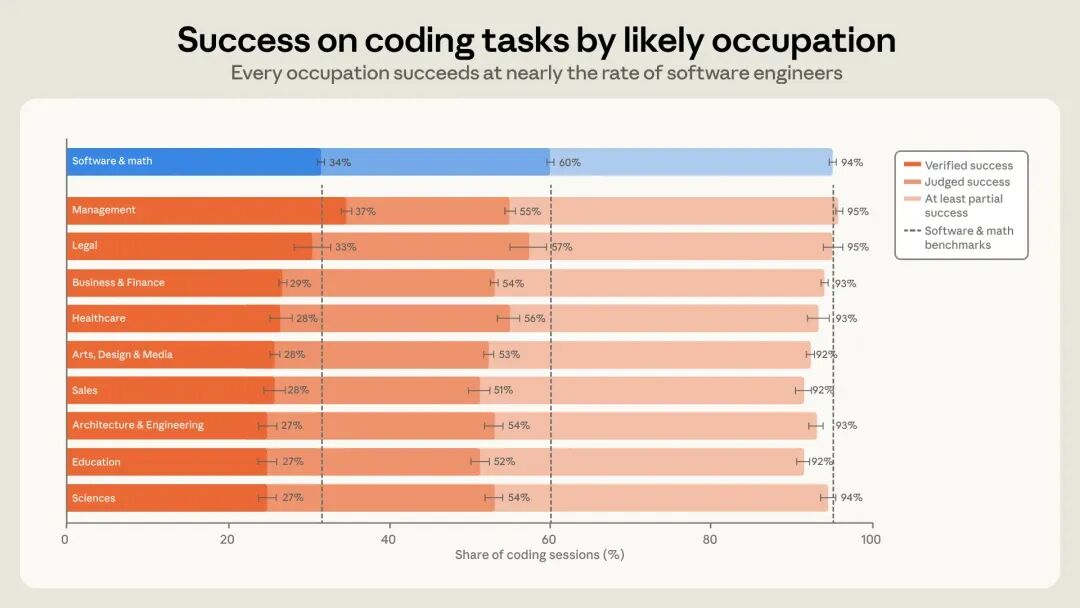
报告最令人振奋的发现,是Coding Agent正在推动“技术能力”的民主化。在产生代码的会话中,管理类职业的严格验证成功率达到37%,甚至略高于软件相关职业的34%;法律、商业、金融、医疗等职业的成功率也基本保持在27%-33%的区间内,与程序员群体的差距不超过7个百分点。
这意味着,法务可以批量审查合同,财务可以搭建对账系统,HR可以生成人才盘点工具。非技术人员正在获得前所未有的“代码自由”。但这一切的前提是:他们必须足够懂自己的业务。AI放大的永远不是“写代码的能力”,而是“把问题结构化并验证结果的能力”。
Part 08
结语:AI越会执行,组织越需要真正懂问题的人
这份基于40万次真实会话的报告,为我们描绘了一幅清晰的知识工作演进图:未来,越来越多的岗位将拥有“技术执行力”,但“专业判断力”依然是极其稀缺的资产。
当AI包揽了执行,业务专家的价值将强势回归;初级岗位的训练模式将被迫重构,组织需要建立“AI时代的学徒制”;管理者的能力模型也必须升级,学会管理“人+Agent”的混合任务链。
软件生产不再只属于程序员,数据分析也不再是数据团队的专属。越来越多普通岗位将拥有调用技术的权力。但这绝不意味着专业不再重要,恰恰相反,专业正在以一种更高级的方式回归。在AI越来越会干活的今天,未来最值钱的人,永远是那些能把问题讲透彻、把结果看明白、并把Agent引向正确方向的人。
来源:本号所刊发文章仅为学习交流之用,无商业用途,向原作者致敬。因某些文章转载多次无法找到原作者在此致歉,若有侵权请告知,我们将及时删除,本文仅供学习交流、我们注重分享,勿作商用,版权归原作者。
