 夜雨聆风
夜雨聆风不少公司给 AI 工具定预算,沿用软件采购的老办法。先看部门人数,再看账号数量,再看订阅价格,最后给一个年度额度。这个办法适合管理邮箱、项目管理工具、CRM,却很难管理 AI。
原因很简单:AI 不只是一个软件入口,它正在变成可调度的工作能力。
一、从 Seat-Based 到 Usage-Based:成本模型的根本转变
过去组织分配人力,会问谁做什么工作,优先级多高,产出如何验收,是否需要加人或减人。到了 AI 时代,token 配额也应该回答类似问题:谁获得 token,多少额度,用于什么工作,最后产出什么结果。
微软 WorkLab 把 tokenomics 称为新的 headcount 问题。这个说法值得认真对待。传统开发者软件是 seat-based:按人头付固定月费。AI coding agent 是 usage-based、token-based、model-dependent 的——一个开发者动作可以触发多次模型调用,一个 agent 可以跨多个步骤持续工作。
Datawiza 的研究也指出,AI 成本管理现在需要 token management、quota management、model governance、usage attribution 和 runtime enforcement。这不是简单的账单管理,而是运行时治理。
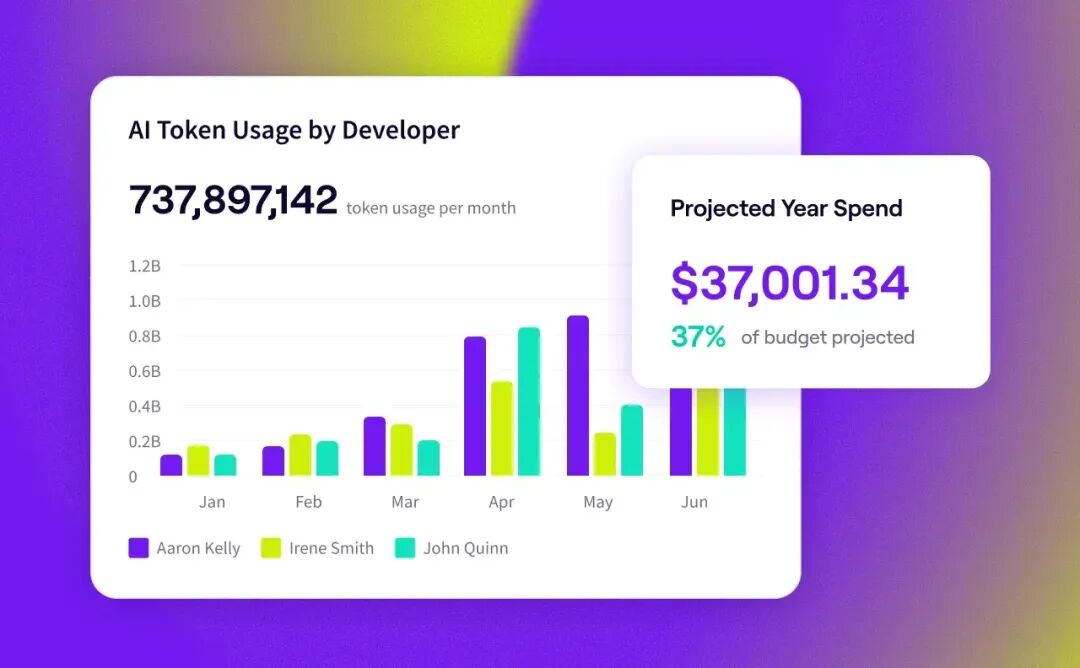
AI 成本管理需要从 seat-based 转向 token-based、usage-based 的精细化治理
如果仍按软件预算管理 token,组织只会看到"哪个部门花得多"。这会诱导大家做两种错误动作。
❌ 平均主义:每个部门都给一点,最后没有一个流程形成规模。
❌ 砍成本主义:看到某个团队调用多,就要求它少用,结果把正在产生价值的流程也压掉。
二、更好的隐喻:排班表
排班表关心的不是谁占用了最多小时,关心的是哪个岗位在什么时段必须有人,哪类工作需要经验,哪类工作可以自动化,哪里需要备用人手。
Token 配额也该这样看:哪些任务值得强模型,哪些任务适合便宜模型,哪些任务只需要搜索和摘要,哪些任务必须保留人工判断。
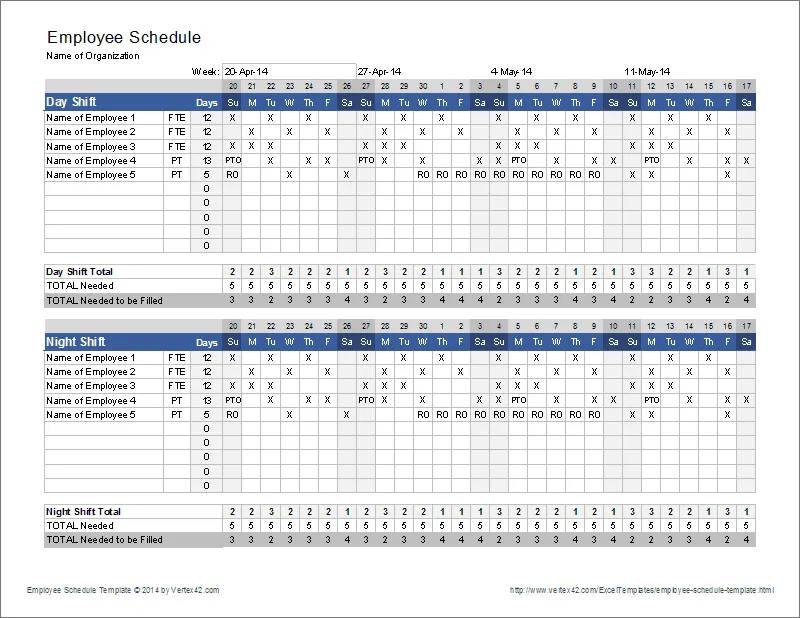
排班表思维:关心的是"哪类工作在什么时段需要多少能力",而不是"谁花了最多小时"
三、五类工作类型:一张 token 排班表
一张 token 排班表至少要有五个工作类型。
🎯 第一类:决策支持
市场分析、竞品拆解、方案比较、投资判断、重大客户判断。这类任务不一定调用频次最高,但出错成本很高。配额不能只看 token 数,要看它是否缩短决策周期,是否让拍板更有依据。
💻 第二类:代码交付
补测试、修 bug、写脚本、生成迁移方案、解释旧模块。这里的结果不是生成多少行代码,而是能否通过测试、能否合并、能否减少 review 往返。强模型不该被无差别用于所有补全,应该优先给高风险或高杠杆任务。
🤝 第三类:销售和客户动作
整理客户背景、生成跟进建议、提炼异议、写邮件、准备会议纪要。这里的结果很具体:客户是否回复,商机是否推进,下一步动作是否更清楚。没有进入客户动作的漂亮话术,不应继续吃高配额。
🔬 第四类:研究
研究类任务天然容易消耗大量 token,因为它要搜索、阅读、比对、归纳。研究配额需要停损线:没有证据链就停止追加,没有明确问题就不启动深搜,没有下一步动作就只算资料堆积。
⚙️ 第五类:自动化
批量分类、流程流转、表格处理、客服分流、数据清洗。自动化的价值不在单次回答质量,而在稳定性、错误率、人工接手率和维护成本。这里适合用量化指标管理,不适合只听 demo 汇报。
第一个好处,是让配额分配从"谁会争取预算"变成"哪类工作能产出结果"。
一个部门会写很好的 AI 方案,不代表它应该拿最多 token。一个不起眼的客服流程,如果每周能减少几百次人工重复,就应该获得稳定配额。
第二个好处,是让调整变得具体。
软件预算常常一年定一次,定完就很难动。Token 配额应该按周或按月复盘。某个研究任务连续两周没有形成可验证结论,就降低额度;某个销售跟进流程稳定带来回复,就提高额度;某个代码任务返工率高,就先补上下文和测试条件,而不是继续加调用。
第三个好处,是让管理者看见 AI 工作的真实容量。
过去一个团队说"我们用了很多 AI",很难判断含金量。排班表会把问题变成:这些 token 被安排到哪些岗位,完成了哪些班次,哪些班次空转,哪些班次需要人类接管。
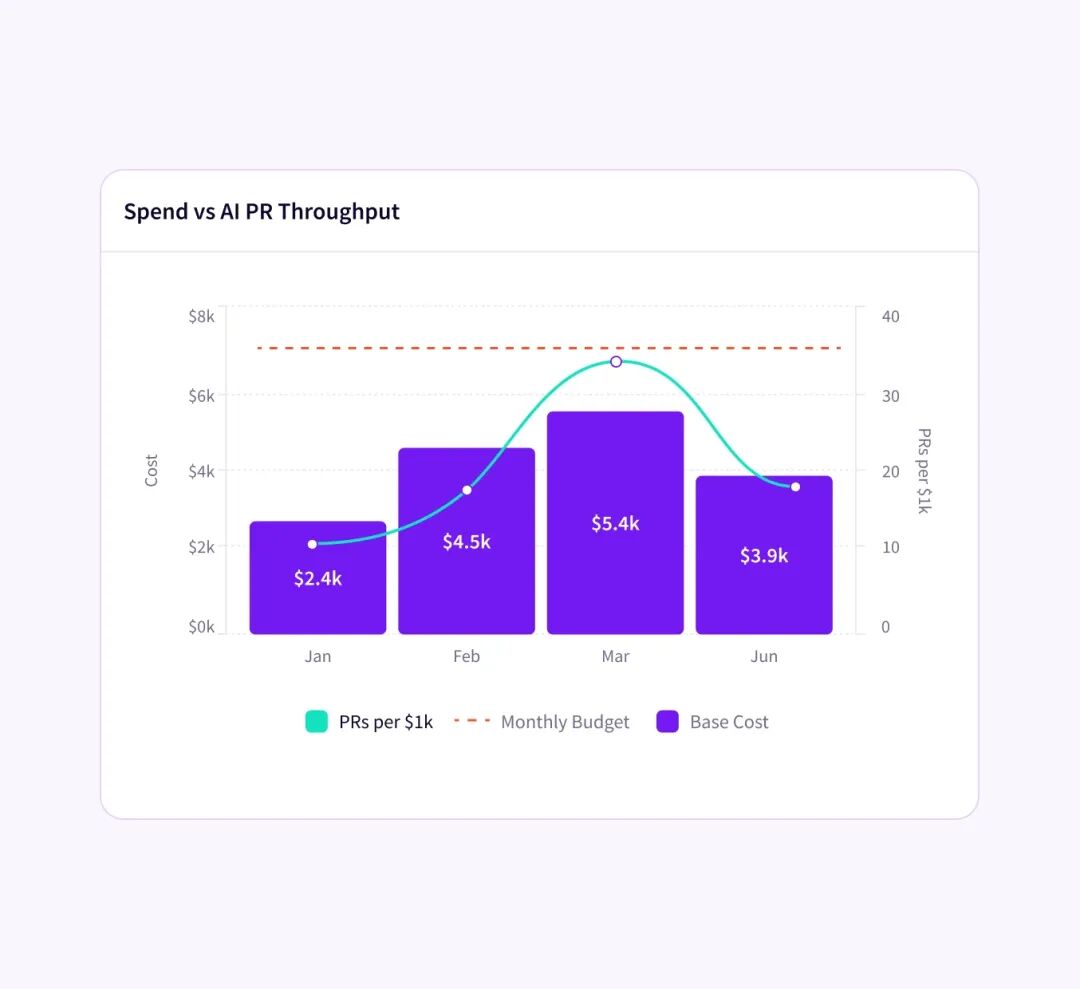
排班表思维让管理者看见:成本花在哪里,产出是什么,哪班"空转"、哪班"高产"
四、一张周度排班表
这套方法不需要一开始就接入复杂监控。可以先在多维表格里建一张周度排班表。字段很简单:
| 工作类型 | |
| 业务负责人 | |
| 模型/工具 | |
| 周配额 | |
| 预期结果 | |
| 验收方式 | |
| 实际结果 | |
| 下周调整 |
每周只开十五分钟会,看三件事:
哪些配额产生结果 哪些配额没有证据 哪些配额应该迁移到其他工作
五、两个容易踩的坑
⚠️ 坑一:不要把 token 配额做成新的审批负担
每次调用都审批,会让 AI 使用变慢,也会把人推回私下使用工具。配额管理应该管工作类型和结果边界,不该管每一次点击。像排班一样,先定岗位和班次,具体执行交给负责人。
⚠️ 坑二:不要把"节省人工时间"当唯一指标
某些 AI 工作并不节省时间,却能提高判断质量。比如竞品分析可能花费同样时间,但让团队少犯一次方向性错误。某些研究任务短期没有收入,却能形成产品路线判断。排班表要允许不同结果类型存在:时间、质量、收入、风险、学习。
对 AI 创业者来说,token 排班表还能反过来指导产品设计。
客户不缺一个"更聪明的 AI 助手",客户缺的是能把 AI 工作分配、记录、复盘起来的系统。谁能帮客户回答"这周 token 用在了哪些工作,换来了哪些结果,下周该怎么调度",谁就更接近预算入口。
企业需要的不是"更聪明的 AI",而是能把 AI 工作分配、记录、复盘起来的系统
你们团队现在更缺哪种管理工具:一个能按人头控制预算的限额系统,还是一个能按工作类型调度资源的排班系统?
