 夜雨聆风
夜雨聆风
摘要:今天这几条 AI 新闻,核心不是模型更会说话,而是开始进入安全、芯片和企业工作流。
标签:人工智能、 AI Agent 、 OpenAI 、 Codex 、企业 AI
今天的 AI 新闻有点密。真正值得看的不是“谁又发布了什么”,而是 AI Agent 正在从聊天框里走出来,开始接那些脏活、慢活、需要被验收的活。
安全漏洞要修,开源项目要维护,推理芯片要重新设计,大公司内部的文档、代码和自动化流程也要有人一点点接起来。
1. OpenAI 把重点从“发现漏洞”推到“真正修掉”
OpenAI 在 6 月 22 日发布了 Daybreak 更新,最扎眼的不是“模型又强了”,而是它把网络安全讲得更像工程现场。
以前大家谈 AI 安全工具,很容易停在“发现问题”这一步:扫出漏洞,生成报告,给你一堆风险列表。听起来很厉害,但维护者看到几十上百条报告时,心里大概率只有一句话:谁来修?
OpenAI 这次说得比较直接:瓶颈正在从“找漏洞”变成“补漏洞”。它更新了 Codex Security 插件,用来做扫描、验证、攻击路径追踪、严重性判断、修复建议,甚至生成面向具体代码库的补丁。官方披露的数字也不小:研究预览以来, Codex Security 已扫描超过 3000 万次 commit ,覆盖 3 万多个代码库;人工审核标记为已修复的 findings 超过 7 万,自动判定已修复的超过 50 万。
GPT-5.5-Cyber 也进入更完整的受限发布。 OpenAI 说它在 CyberGym 单模型评测里达到 85.6%,高于 GPT-5.5 的 81.8%;在 ExploitGym 和 SEC-bench Pro 上也有提升。换句话说,模型不只是会“解释漏洞”,而是更能沿着代码、环境和验证步骤往下走。
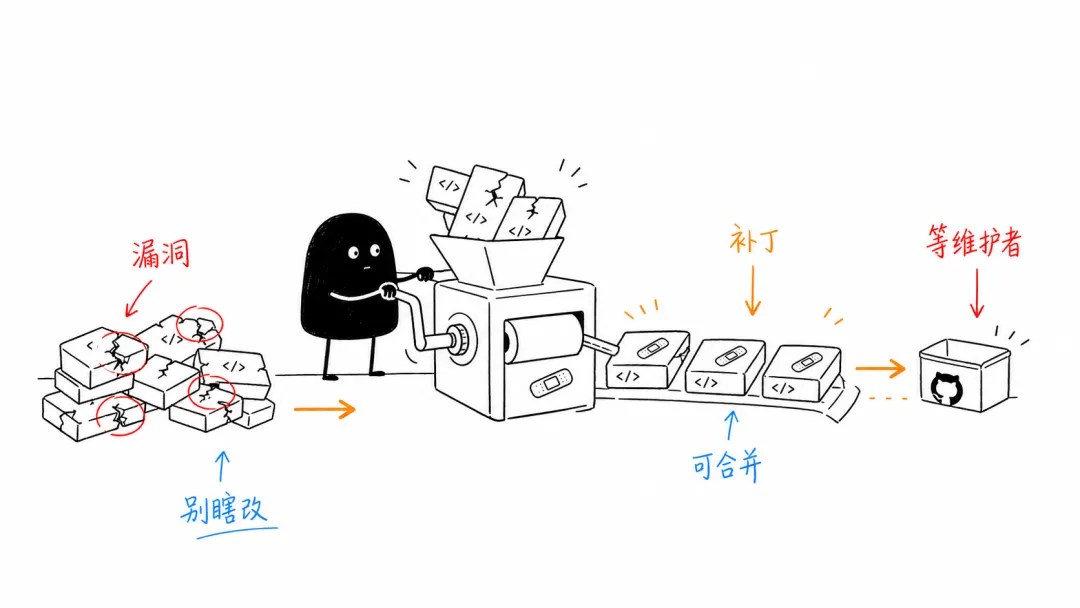
AI Agent 如果只会指出问题,只会制造更多待办事项。真正有价值的是把问题推到下一步:复现、验证、修补、测试、给人审。 OpenAI 这次没有把 AI 写成替代安全工程师的按钮,反而反复强调 human oversight 、 trusted defenders 、 review 。说白了,它也知道这类能力一旦放开,既能帮防守方,也可能帮攻击方。
今天可以试的小动作:如果你自己有代码项目,别急着幻想 AI 自动替你修安全漏洞。更现实的用法是让 Codex 或类似工具先读你的依赖、权限边界和入口文件,让它列出“哪里最值得人工检查”。先让它做分拣员,别直接让它当发布负责人。
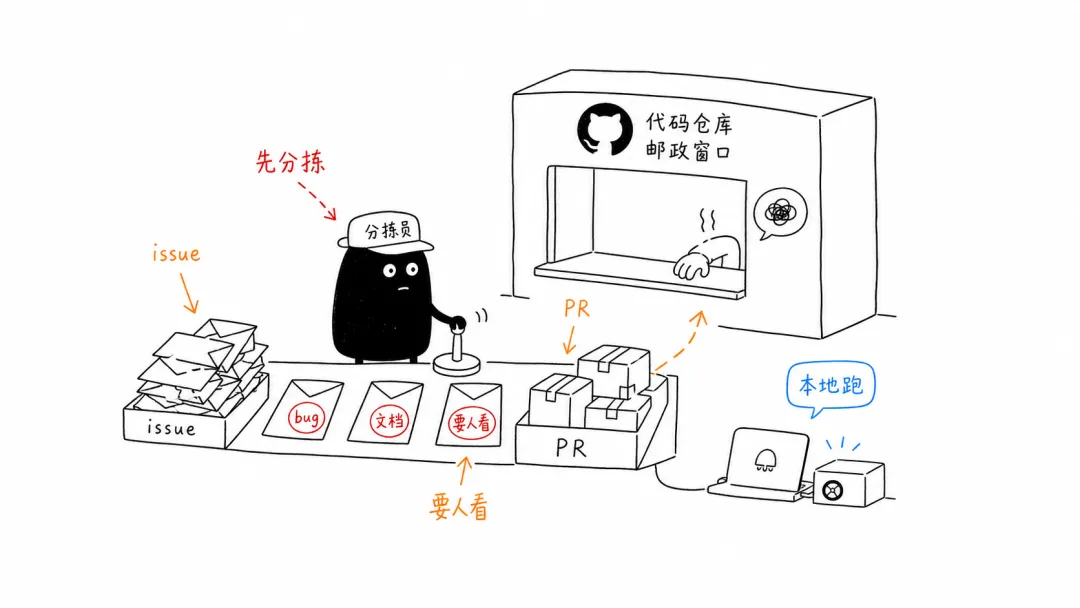
2. Patch the Planet :开源维护者最怕的不是漏洞,是低质量报告
同一天, OpenAI 还单独发了一篇 Patch the Planet 。这个项目和 Trail of Bits 一起做, HackerOne 、 Calif 也参与,目标是帮开源项目从“发现问题”走到“合并补丁”。
官方列出的初始参与项目包括 cURL 、 NATS Server 、 pyca/cryptography 、 Sigstore 、 aiohttp 、 Go 、 freenginx 、 Python 和 python.org 。这些名字不是边角料,很多都是网络、加密、软件供应链和语言基础设施里的底座。
麻烦在于,开源项目不是大厂安全部门。很多维护者本来就人少、时间少、预算少。 AI 如果突然发现更多漏洞,却不给维护者过滤、复现、排优先级,那等于往他们桌上倒垃圾袋。
Patch the Planet 的设计比较关键:研究人员先和维护者沟通项目偏好、披露流程、最需要帮助的地方,再做漏洞验证、补丁开发、测试和协调披露。 Trail of Bits 的安全工程师会在提交给维护者之前人工审核,去重、过滤误报、重新判断严重性,然后再把确认过的内容推进修复。
OpenAI 披露, Trail of Bits 已经安排工程师全职使用 Codex 和 GPT-5.5-Cyber ,覆盖 19 个开源项目,识别出数百个安全问题,合并了几十个补丁。初始冲刺还产出了 fuzzing harness 、历史 CVE 分析管线、差分测试系统、威胁模型和补丁生成工作流。
这里最值得看的不是“AI 发现了多少漏洞”,而是工作流变了: AI 做搜索和候选生成,人类专家做确认和交付,维护者保留最终控制权。这比“全自动修复世界”靠谱多了。
今天可以试的小动作:如果你维护一个小项目,可以先从 issue 模板和测试入口开始整理。 AI Agent 最怕的不是任务难,而是上下文乱。你把复现步骤、期望行为、测试命令写清楚,它才有可能从“胡乱建议”变成“能帮你递补丁的人”。
3. Jalapeño 芯片: AI 的成本战开始往底层打
6 月 24 日, OpenAI 和 Broadcom 发布了 Jalapeño ,也就是 OpenAI 第一款面向 LLM 推理优化的 Intelligence Processor 。
它说明 OpenAI 不满足于只做模型和应用,开始更深地碰底层基础设施。官方说, Jalapeño 从设计到生产 tape-out 只用了 9 个月, OpenAI 自己的模型也参与加速了部分设计和优化过程。工程样片已经在实验室以目标频率和功耗跑 ML 工作负载,包括 GPT-5.3-Codex-Spark 。
OpenAI 还说,早期测试显示,这颗芯片的 performance per watt 会明显好于当前最先进水平。不过详细技术报告还没出来,最终性能要等后续报告。
推理才是 AI 真正接触用户的地方。你每问 ChatGPT 一次,每让 Codex 多跑几步,背后都是推理成本、延迟、功耗和网络调度在扛。模型越会干活,账单越不客气。
OpenAI 自己下场做推理芯片,本质上是在争取两件事:一是让模型响应更快、更稳定,二是把单位智能的成本压下来。别看“芯片”离公众号读者很远,它最后会体现在很俗的地方:工具贵不贵、卡不卡、能不能让 Agent 多跑几步。
今天可以试的小动作:以后看 AI 产品价格,不要只盯模型名字。也看它是否支持长任务、异步执行、批量处理、失败重试和成本上限。真正影响你工作流体验的,很多时候不是“聪明一点”,而是“能不能稳定跑完”。
4. Samsung 把 ChatGPT 和 Codex 发给员工,企业 AI 进入大规模内测
6 月 21 日, OpenAI 还宣布 Samsung Electronics 将向韩国所有员工,以及全球 Device eXperience 部门员工开放 ChatGPT Enterprise 和 Codex 。
这条没有前面那么炫,但很重要。它代表企业采用 AI 的重心正在变化:不再只是给少数研发团队试试代码助手,而是把 ChatGPT 和 Codex 放到更广的工作面里。 OpenAI 的说法是, Samsung 会把它用在软件开发、市场、产品开发、制造、企业职能等场景。 Codex 也不只写代码,还可以把想法变成内部工具、网站和自动化流程。
官方还提到, Codex 每周活跃用户已经超过 500 万;韩国的 Codex 周活用户自 2026 年 2 月 1 日以来增长接近 800%。这个数字看着挺夸张,至少说明一件事:代码助手正在变成工作助手。
企业里最容易出问题的不是“没人用 AI”,而是大家开始偷偷用、乱用、绕过安全规则用。 Samsung 这种部署至少说明一个趋势:大公司会更倾向于把 AI 纳入统一账号、权限、数据保护和治理框架,而不是让员工各自找野路子。
今天可以试的小动作:如果你在公司里用 AI ,不妨给自己建一个小清单:哪些内容可以丢给 AI ,哪些绝对不能;哪些结果必须人工复核;哪些任务可以变成固定提示词或小脚本。别等公司制度来了才补。
今天的判断: AI Agent 正在进入“验收时代”
这四条新闻放在一起看,有一条线很清楚: AI 开始被安排进系统里干活了。
它不再只是回答问题,而是进入有验收标准的流程:安全漏洞有没有修掉,补丁能不能合并,芯片能不能把推理成本打下来,企业员工能不能把想法变成可用工具。聊天可以含糊,生产不行。漏洞有没有复现,测试有没有过,补丁有没有副作用,这些都不是“表达能力”能糊弄过去的。
我今天最想记住的是这句话:Agent 的下一步,不是更会说,而是更能被验收。
今天可以试一个小动作:拿一个真实任务,不要问 AI “帮我想想怎么做”,而是给它一个验收条件。
比如:
“读这个项目,找出 3 个最可能出问题的入口。每个都要给文件路径、原因、复现方式和我该怎么验证。”
或者:
“把这篇文章改成公众号稿,但不要改事实。改完后列出你改了哪些段落。”
你会很快发现,能不能交付,比会不会聊天重要多了。
