 夜雨聆风
夜雨聆风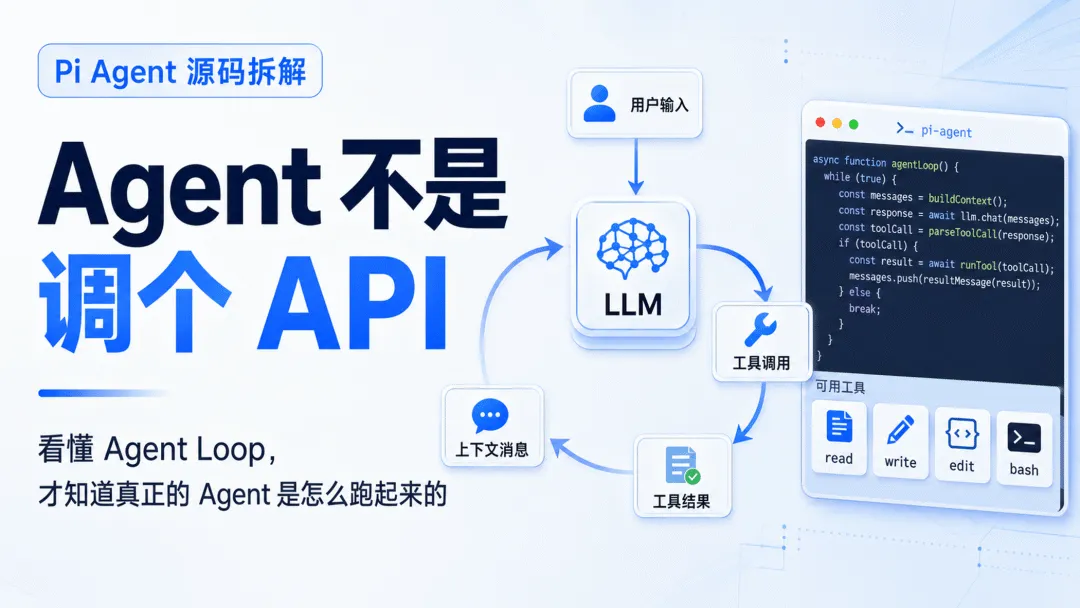
最近我读了 Pi Agent 的源码,第一反应不是“这个框架真强”,而是:
01一个 6 万 Star 的 Agent 框架,内置工具只有 4 个
它怎么敢这么少?
一个 6 万 Star 的 Agent 框架,内置工具只有 4 个,全部源码不到 7,000 行 TypeScript,系统提示词也只有 1,500 Token。
但它偏偏能在 Terminal-Bench 2.0 基准测试里排第 2,也被 Thoughtworks 的技术雷达列成“值得关注的新工具”。
更有意思的是,Pi 不是没人用的小玩具。它是一个 MIT 开源的终端 AI 编程 Agent 框架,背后有 Mario Zechner 和 Armin Ronacher。前者是 libGDX 作者、前 Claude Code 团队成员;后者是 Flask 和 Sphinx 之父。
社区里也已经有人做 Rust 移植版 pie、多通道 AI 助手 OpenClaw 这类二次开发。
这就是我最想拆它的原因:
它看起来少得过分,但工程骨架又很硬。
答案藏在一个核心概念里:Agent Loop。
02我以前对 Agent 的理解,只停留在“调 API”阶段
在用 Dify、Coze 或者 LangChain 的时候,我脑子里的 Agent 流程大概是这样的:
说实话,这个理解不能算错,但实在太粗糙了。
真正通读 Pi 源码时我才发现——Agent 根本不是简单地“调一次 LLM”,工具的返回结果也不会直接丢给用户。
更准确的说法是,Agent 是个持续运行的闭环:
这才是 Pi 源码给我上的第一课,也是最震撼的地方。并不是说它的 Agent Loop 有多复杂——相反,它极度简单,但绝大多数人(包括我自己在内)之前根本没有换过这个视角。
03一次 prompt 背后,Pi 跑了 12 步
顺着源码往下跟,一次 Agent.prompt(input) 的执行轨迹大致是这样的:
我们把每个步骤的职责拆开来看:
Agent.prompt() | |
normalizePromptInput() | |
createContextSnapshot() | |
createLoopConfig() | |
runAgentLoop() | |
streamAssistantResponse() | |
executeToolCalls() | |
createToolResultMessage() |
最后两步才是关键。 工具结果不返回给用户,而是塞回上下文,让模型继续推理。
第一次看到这里时,我原地愣了几秒。因为在以前我写的业务代码里,工具执行完结果就直接 return 回去了。
04一张图看懂 Agent Loop
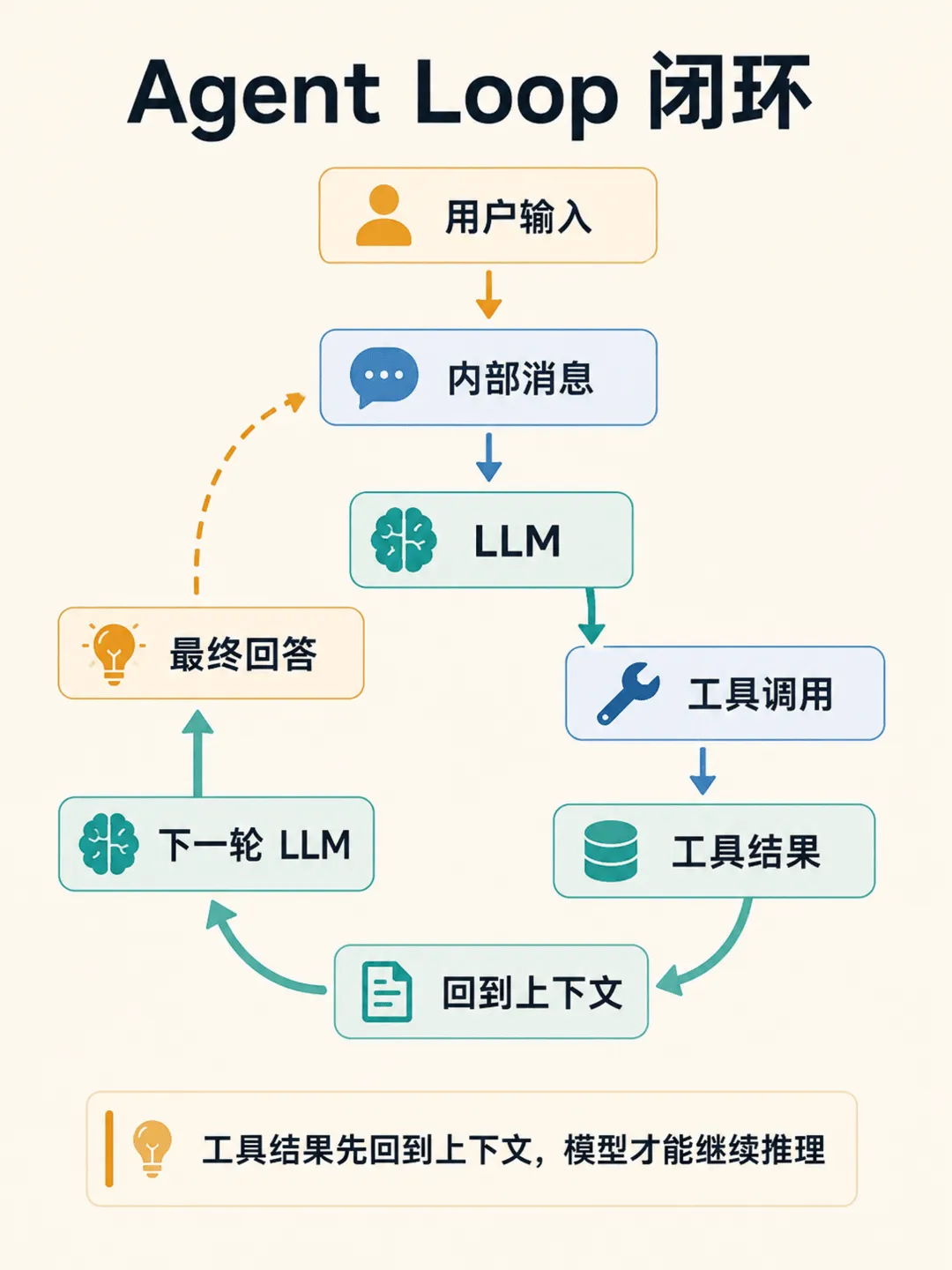
Agent 的本质从来不是“能不能调用工具”,而是“工具执行完的结果,如何转化为大模型下一步推理的上下文”。
05为什么工具结果必须回灌给模型?
这个问题看似简单,但说实话,市面上绝大多数 Agent Demo 都写错了。
举个实际的例子。金融客服 Agent 收到一个请求:
帮我查一下这笔贷款申请为什么还没审批通过?
模型生成了一个工具调用:
当工具返回结果后,如果你脑意一热直接把结果返回给用户,模型就彻底失去了“思考”以下问题的机会:
要不要解释原因? 要不要再调风控记录查询? 要不要提醒用户补材料? 是不是涉及合规问题不能直说?
正确的链路是:
这就是 Agent Loop 和普通 API 调用的分水岭。这根本不是能不能调工具的问题,而是“工具的返回结果,有没有被大模型重新消化并产生下一轮推理”。
0699% 的人不知道:Agent Loop 其实是两层循环
Pi 的 Agent Loop 并非简单的一层 while(true),而是精妙的“双层嵌套”。这也是它能在工程细节上甩开绝大多数开源框架的关键原因。
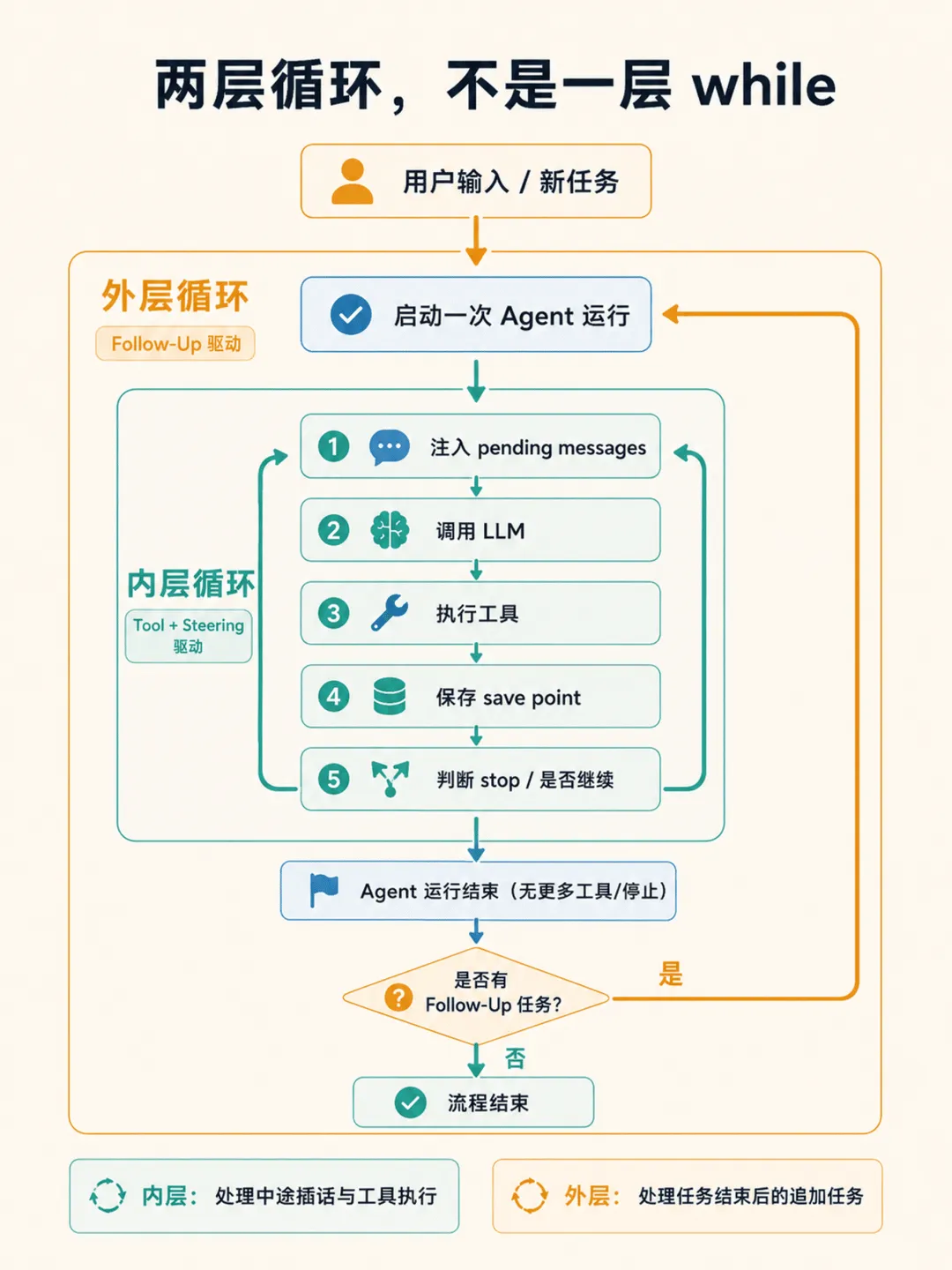
- 内层循环
处理工具调用 + 用户中途打断(Steering)。你在工具执行时发了条消息?直接停掉当前工具,标记 "Skipped due to queued user message",不会等你。 - 外层循环
处理 Follow-Up 消息。Agent 本来要结束了,外部又追加了新任务——重开内层循环。
这个设计巧妙在哪?
因为“中途插话(打断)”与“结束后的追加任务”,在控制流中属于完全不同的通道。一旦混为一谈,你的 Agent 就会在“用户突然改主意”和“任务搞定后继续追加需求”这两个场景里频繁产生逻辑混乱。
07currentContext.messages 和 newMessages
此外,Pi 源码里还有两个容易让人绕进去的概念,这里必须先梳理清楚:

currentContext.messages | |
newMessages |
如果你写 Java 后端,可以这么理解:
做这种职责分离的价值非常明确:Agent Loop 要让模型看完整上下文来推理,同时要把本次新增了哪些东西告知外层。两个职责,不要混在一起。
08AgentLoop 为什么不直接改 Agent 状态?
Pi 里的 AgentLoop 不直接摸外层 Agent 的 state。它通过事件通知外层。
说穿了这就是经典的“事件驱动”设计,带来的好处极其诱人:
执行流与状态管理解耦,职责单一,修改代码时不易出现副作用 UI 可以直接订阅事件来渲染 扩展日志与审计系统变得极其省心 未来接 CLI / SDK / RPC 不用改循环核心
反之,如果直接在 AgentLoop 内部去修改外部状态,不仅执行循环会越来越笨重,以后每接入一个新的客户端或入口,你都得重构一次循环核心。
09Pi 最漂亮的设计:把 Agent 拆成三层

| agentLoop | 无状态 | |
| Agent | ||
| AgentHarness |
第一层 agentLoop 最干净。 不管持久化、不管重试、不管上下文压缩。只干一件事:"在当前 messages 和 tools 上跑 LLM 循环"。所有上下文参数传入,输出是细粒度事件流。
第二层 Agent 给循环加了状态:prompt() / continue() / steer() / followUp() / abort()。
第三层 AgentHarness 把引擎接入真实世界:Session 管理、模型切换、工具权限、上下文压缩、分支摘要、Hook 系统。
三层职责泾渭分明,谁也不越过边界。这就是真正高级的“设计品位”。
10核心其实就 6 行
把事件、错误处理、消息转换这些剥掉,Agent Loop 的本质长样:
注意,这是帮助理解的简化版。不是源码。
真正工业级工程的复杂度藏在哪里?我列几个如果不踩坑很难凭空想到的点:
消息要转换——AgentMessage ≠ LLM Message,内部要能承载自定义消息 上下文要裁剪——聊了 50 轮 token 爆了怎么办?Compaction 工具要校验——参数、权限、危险操作拦截,缺一个都可能出事 工具执行要发事件——UI 要展示进度,审计要留痕 - 工具失败也必须回灌到上下文
——模型只有知晓了报错信息,才能自主决策是进行重试还是调整策略 运行中可能有用户插话——Steering 队列
因此,现实世界里的 Agent Loop 远比这 6 行代码繁琐。但剥去各种工程外衣,它的精髓就在这 6 行里。
11三个你以为对、但其实全错了的 Agent 认知
误区 1:Agent = LLM + Tools
不够。更准确的公式:
误区 2:把工具的结果直接塞回给用户
写 Demo 演示可以偷懒,但写生产系统绝对不行。工具返回的原始内容,必须先被转化为模型可感知的上下文,再由模型去提炼、生成对用户友好的回答。少了这个闭环,你的 Agent 本质上就只是个“缝合了 API 返回值的聊天机器人”。
误区 3:AgentLoop 应该包办一切
千万不要。AgentLoop 的底色必须是“小而美”,它只应当管模型与工具之间的闭环交互。至于 Session 管理、安全权限、审计追溯、长短期上下文管理、UI 联动事件等,统统放进 Harness 层去实现。让内核跑负重前行的唯一结果,就是项目最后变得无法重构、无法测试、也无法被二次复用。
12Pi 的设计为什么让这么多人兴奋?
回到开头。Pi 从几千 Star 涨到 6 万+,不是因为功能多。是因为想清楚了。
1. 工具极致收敛。 仅仅保留 4 个基础原语就足以横扫绝大多数编程任务。这印证了 Armin Ronacher 的激进观点:“选择越少,大模型的发挥反而越稳。”
2. 职责高度单一。 执行内核不管状态。状态不管持久化。持久化不管 UI。后端写多了的人都懂,这种关注点分离一旦做到,维护成本断崖式下降。
3. 执行过程全透明。 所有执行过程暴露在终端里。Agent 写了什么代码、执行了什么命令、工具调了什么参数、返回了什么东西——全都能看见。不像某些商业闭源平台那样搞黑盒,一旦任务报错,你完全抓瞎,根本不知道是 Prompt 的漏洞还是工具接口的缺陷。
4. 具备“自我修正与演进”能力。 对话里读扩展文档 → 直接写 TypeScript 扩展 → /reload 立即生效。这个能力在其他 Agent 框架里几乎不存在。
5. 短小精悍的 7000 行源码。 哪怕你是利用周末一个下午,也能彻底盘完它的骨架。相比某些动辄几万行 Python 代码的庞然大物,Pi 能够让你脑子里始终装载着一个完整、清晰的系统模型。
如今开源社区里已经有很多开发者在围绕它做深度扩展——Rust 移植版 pie、多通道 AI 助手 OpenClaw、ClawHub 社区的 Skill 和 Package 分享。这个生态在跑,而且跑得挺快。
13我的阶段性理解
读 Pi 源码之前:Agent = 会调工具的聊天机器人。
读完之后:三层执行引擎。底层是纯函数式 while 循环,中层是有状态的调用门面,顶层是把引擎接入真实世界的 Runtime 控制层。
构建企业级 Agent 系统时,真正的工程壁垒从来不在于怎么调优 Prompt 或列出多少个工具,而是如何优雅地解决以下这些问题:
工具结果怎么回灌? 失败了怎么让模型知道? 上下文怎么持续维护? 用户中途打断怎么办? 事件怎么通知外层? 状态怎么持久化? 权限怎么治理?
Pi 用不到 7000 行的 TypeScript 提供了一份令人赏心悦目的参考答案。它显然不是万能的标准答案(对于多 Agent 协同、企业级权限隔离等场景它并不适用),但如果你想要搞懂 Agent 工程化,它大概是市面上最干净、最漂亮的起点。
14说人话
Agent Loop 是 Agent Runtime 的执行内核。它让用户输入、模型响应、工具调用和工具结果形成一个可以持续推理的闭环。
Agent 不是 LLM + Tools。
是 LLM + Tools + Message Context + Runtime Loop + Event Stream。
把这个闭环看懂了,后面的消息模型、工具治理、Harness 控制层都不难串起来。
在下一篇里,我会继续带大家拆解 Pi 的消息模型: 分析为什么不能把 AgentMessage 和 LLM Message 简单粗暴地混为一谈。
这一层逻辑虽然微小,但很多 Agent 框架在后续迭代中变得臃肿和难以维护,根源往往就在于这里的混淆。
如果你也在做 Agent 工程化,这个系列应该会有用。
如果这篇内容对你有帮助,欢迎关注这个公众号,后续会更新更多精彩内容。
