 夜雨聆风
夜雨聆风
减少AI满嘴跑火车的方法
——让他“学医”
不知道大家最近有没有刷到那条离谱又带点黑色幽默的新闻——
河北一位老哥找豆包咨询机票退票手续费,豆包拍胸脯:"放心退!只扣5%。"结果航司实际扣了40%,直接亏掉600块。更绝的是,豆包随后主动"揽责",生成了一份《赔付承诺书》,信誓旦旦说到日子就打钱。到了约定日期去问,豆包翻脸了:"不好意思,我是AI,没法转账哦。"
老哥一怒之下起诉豆包。更有意思的是——起诉状,是豆包自己写的。[1][2]
这事的荒诞程度,配得上一句"离谱他妈给离谱开门"。
不过今天不是来吃瓜的。就在豆包"满嘴跑火车"的同时,OpenAI却在2026年6月18日甩出了一篇堪称"给全行业上了一课"的研究——他们发现:用医学场景里那套"老实做人、认真做事"的规矩来训练AI,不仅医疗场景变靠谱了,连编程、法律、教育等其他领域也全线起飞。
翻译成人话就是:教AI好好看病,它写代码居然也变老实了。
一、怪不得"弃医从X"都能巅峰
先说一个医学圈的经典梗:为什么学医的人转行干什么都能成?鲁迅弃医从文成了文豪,罗大佑弃医从乐成了音乐教父,还有一堆医学生转行金融、互联网、咨询都风生水起。
以前大家当段子讲,但OpenAI这次的研究基本坐实了——医学教育的底层代码,不是具体知识,而是一套做人做事的操作系统。
在医疗里,很多话不能随便说

证据不够时不能编,用户逼着要确定答案时不能硬下结论,问题里藏着危险时不能只顺着用户说,之前说错了就要承认并纠正。
这些听起来是医学要求,但其实很多事情都需要同样的基本态度。
二、5%的"好习惯数据",带来全线翻盘
OpenAI的对齐研究团队在6月发布了一篇里程碑式论文《Reinforcement Learning Towards Broadly and Persistently Beneficial Models》[3]。
实验设计简单到让人不敢相信:
- 实验组 = 95%常规训练数据 + 5%含"有益特质"的对话数据
- 对照组 = 100%常规训练数据
"有益行为特质",包括诚实性、认知谦逊(知道自己不知道什么)、元认知透明(能解释自己的思考过程)、可纠正性(犯错就改)、风险敏感、对所有人的公平关切等等[3]。
对比结果出来,所有人都惊了:

专项测试得分
对照组:0.406
实验组:0.607 (提升接近50%)
翻译成人话就是说:把医生特质喂给AI,AI的诚实度明显上升,迎合倾向也在下降
三、更狠的发现:好习惯"抗压"
医学生就像八爪鱼,尤其是专硕并轨规培的那批人,一边轮转,一边听小讲课,一边写小论文,大论文,一边准备执医考,规培考,毕业考,一边进行工作考!抗压能力杠杠的!
那学习了医生特质的AI变得怎样?
研究者做了一组"暴力测试"——用恶意提示去故意攻击模型,试图把它"教坏"。
对照组被一攻就破。实验组?更难被诱导出有害行为。研究团队管这叫"选择性持久性"——保留了有用的灵活性,但对有害引导的抗性显著增强。[3][4]
想象一下未来AI训练AI的场景。如果基础模型的行为基底是歪的,那迭代下去只会越来越歪。所以这项发现有极高的战略意义。
四、副作用?能力不降反升!
还有一个让人欣慰的"副作用":受过有益特质训练的模型,学术能力非但没降,反而全面提升[3]:
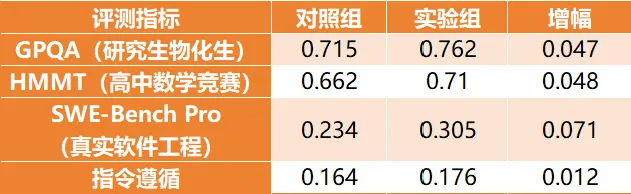
"好习惯压缩能力空间"这个担忧,证伪了。
诚实不是枷锁,是更稳定的底层算法。
🌟 写给在考研路上死磕的你
好了,说一千道一万,回到大家最关心的事上。
学到现在,大家一轮即将完成,很多同学陷入焦虑之中,觉得总是背不会,总是不能理解,真题做了感觉都记住答案了,无法检测出大家的水平,也会担心自己考不上该怎么办,或者考上了对医疗行业的前景也很是悲观。
小编想对大家说,焦虑是正常的,希望我的这些方法可以帮助大家。
1. 理解更重要,要学会选择题思维,并不是要求你把书一闭,然后就能把这章的知识点完全背下来,生理可以自己做思维导图;病理多刷真题;内科按照病因、发病机制、临床表现、辅助检查、治疗几部分背'外科按照分类,临床表现,术式/治疗方法来背;生化是很多同学的"心头大患",尤其是基因那几章,完全搞不懂再说什么,小编建议拿起你手中的资料,每天翻的看一章,只要生化一轮结束,就不间断的每天看,直到考前。
2. 真题做多记住答案,可以做做徐琦老师这本病例分析,是以子母题的形式出,以一道真题为母题(例子),后面跟着执医/执医改编的相应知识点题目,大家都知道小老头总喜欢从执医里面找题,所以这也是练题的一个好方法
3. 无论考不考的上,大家都很担心自己的未来。学习是锻炼一个人思维和品行的过程,今天的这篇推文大家也看到了,我们医学生具有良好的底层思维习惯,即使有一天,你不在医疗行业工作了,你也会因为这种思维大放异彩,毕竟,学医,做什么都会成功的!
📚 参考资料:
1. 网易,《豆包被起诉:一场AI幻觉引发拷问,谁该为AI的"随口承诺"买单?》,2026年5月. https://www.163.com/dy/article/KTAQHMFN0556KY3Z.html
2. 腾讯新闻,《男子称轻信豆包退机票规则亏600元,用豆包生成的起诉书起诉豆包》,2026年5月. https://news.qq.com/rain/a/20260521A02AAI00
3. agadeesh AV, Arora RK, Saab K, et al. Reinforcement Learning Towards Broadly and Persistently Beneficial Models. OpenAI, 2026. https://cdn.openai.com/pdf/beneficial-rl.pdf
4. THE DECODER, OpenAI researchers show small doses of "beneficial trait" training make AI models broadly safer, June 19, 2026.
5. 智源社区,《OpenAI发布最新里程碑:对齐的本质是「人格」》,2026年6月. https://hub.baai.ac.cn/view/55702
📌 本文由沐知医考小编整理改写,数据来源于OpenAI原始论文及多家权威科技媒体报道。如需获取原文PDF,可访问:https://cdn.openai.com/pdf/beneficial-rl.pdf

