 夜雨聆风
夜雨聆风
01. 产品概述

Perplexity 是一款面向知识检索、研究分析与信息整合的 AI 答案引擎,通过实时联网搜索、检索增强生成与带引用回答机制,把传统搜索升级为可对话、可追溯、可快速验证的研究工具。用户无需在多个网页和搜索结果之间来回跳转,而是可以围绕一个问题持续追问、扩展和整理信息,实现从查询、验证到总结的完整工作流。相比传统 ChatGPT 式通用对话,Perplexity 更强调实时信息、来源引用与答案可信度,试图解决搜索结果碎片化、信息时效性不足与事实核验成本高等问题 。

02. 用户需求

|核心用户
- 研究人员与学者
需要实时检索最新文献、验证数据、追踪研究进展,做深度学术探索 - 知识工作者与分析师
金融分析师、市场研究员、产品经理等,需要快速获取并验证专业信息,做竞品分析、行业研究 - 学生群体
用于学习新知识、做研究、整理笔记,快速获取有引用的答案 - 内容创作者与自媒体
需要快速获取素材、验证信息、生成内容摘要,做选题和资料整理 - 企业决策者与管理者
需要快速了解行业动态、市场趋势、竞品信息,做决策参考
|核心需求
- 实时信息获取
需要最新、最准确的信息,而不是依赖模型训练数据中的过时知识 - 答案可信度验证
需要带引用来源的答案,可以快速跳转到原始信息核实内容 - 快速研究效率
减少在多个网页和搜索结果之间来回跳转的时间,集中在一处完成查询、验证、总结 - 复杂问题推理
需要 AI 支持多步骤推理、复杂任务处理,做深度分析 - 多模态输出
需要文字、图像、视频等多模态输出,适合不同场景

03. 核心能力

实时联网搜索:基于 Vespa AI 引擎,覆盖超过 2000 亿个 URL,每秒处理数万个索引更新,确保答案始终基于最新信息 - 检索增强生成(RAG)
通过五阶段流程(意图解析→实时检索→片段提取→答案生成→会话优化)实现高效问答,结合自研 Sonar 模型与外部 AI - 带引用回答
每一段回答都附带引用文献,用户可直接跳转至原始信息来源核实内容 - 智能模型路由
使用高效分类器模型,根据查询意图和复杂度,将请求路由至最合适、最具成本效益的模型(自研 Sonar 或 GPT/Claude) - 多模态能力
支持文字、图像、视频等多模态输出,适合不同场景

04. 技术架构

Perplexity 的底层能力可以概括成三层:实时检索引擎 + 智能模型路由 + RAG 生成管道。它不是自己从头训练大模型,而是把实时搜索、模型编排和知识管理组织成一个可用的认知系统 。
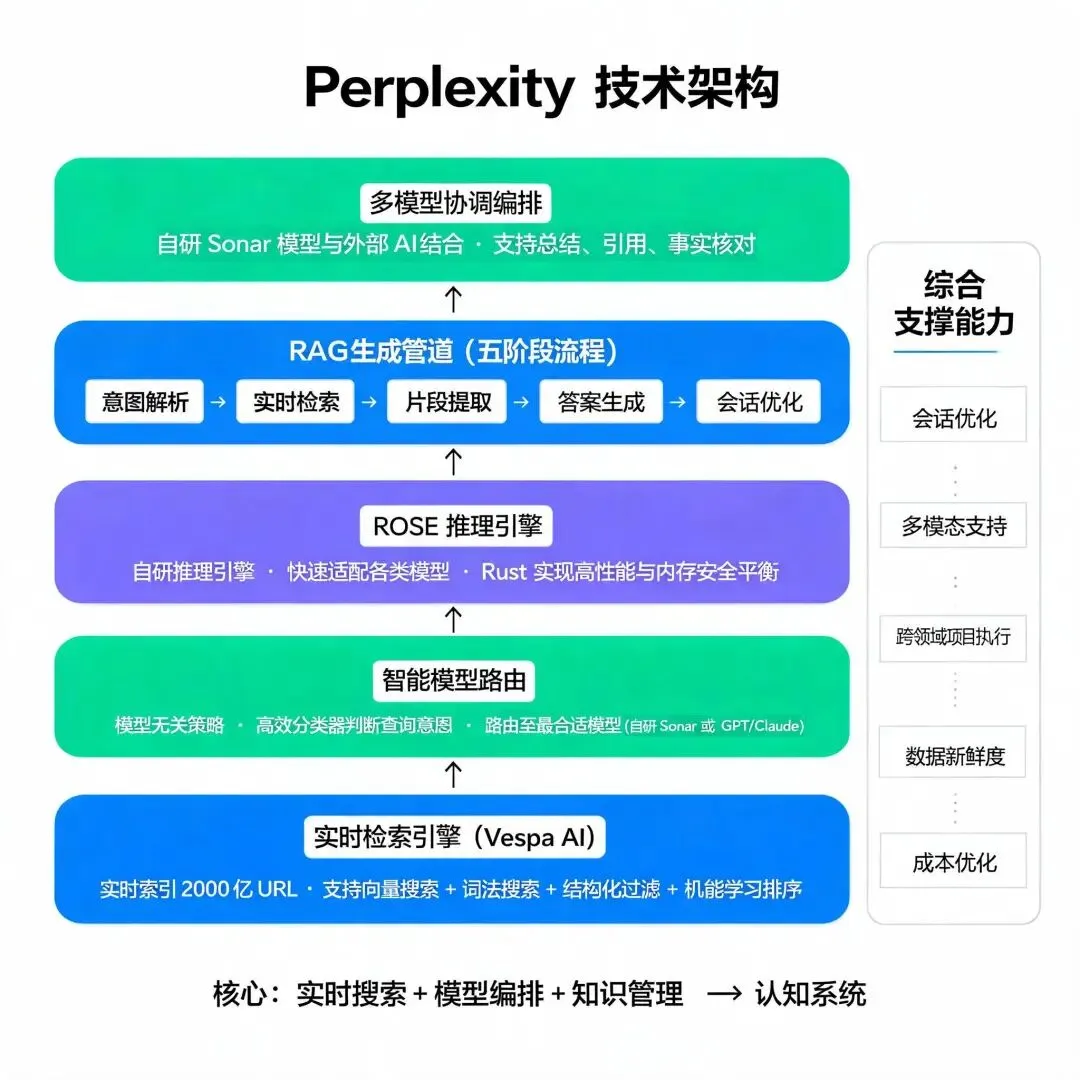
Vespa AI 检索引擎:实时索引 2000 亿 URL,支持向量搜索、词法搜索、结构化过滤、机器学习排序 ;
智能路由系统:模型无关策略,使用高效分类器判断查询意图,将请求路由至最合适模型(自研 Sonar 或 GPT/Claude);
ROSE 推理引擎:自研推理引擎,支持快速适配各类模型,推理逻辑关键部分迁移至 Rust,实现高性能与内存安全平衡 ;
RAG 生成管道:五阶段流程(意图解析→实时检索→片段提取→答案生成→会话优化),生成内容不得脱离检索信息 ;
多模型协调编排:自研 Sonar 模型与外部 AI 结合,支持总结、引用、事实核对等核心能力 ;
会话优化;对话式迭代优化,确保答案的相关性和时效性持续提升,用户交互成为反馈数据;
多模态支持:支持文字、图像、视频等多模态输出,适合不同场景;
跨领域项目执行:Perplexity Labs 可执行跨领域项目,支持深度推理和复杂任务;
数据新鲜度:每秒数万次索引更新,强调信息新鲜度和细粒度内容理解 ;
成本优化;ROSE 引擎在硬件与软件两端压榨性能极限,平衡 LLM 高计算成本与实时搜索产品低延迟需求;

05. 竞品分析

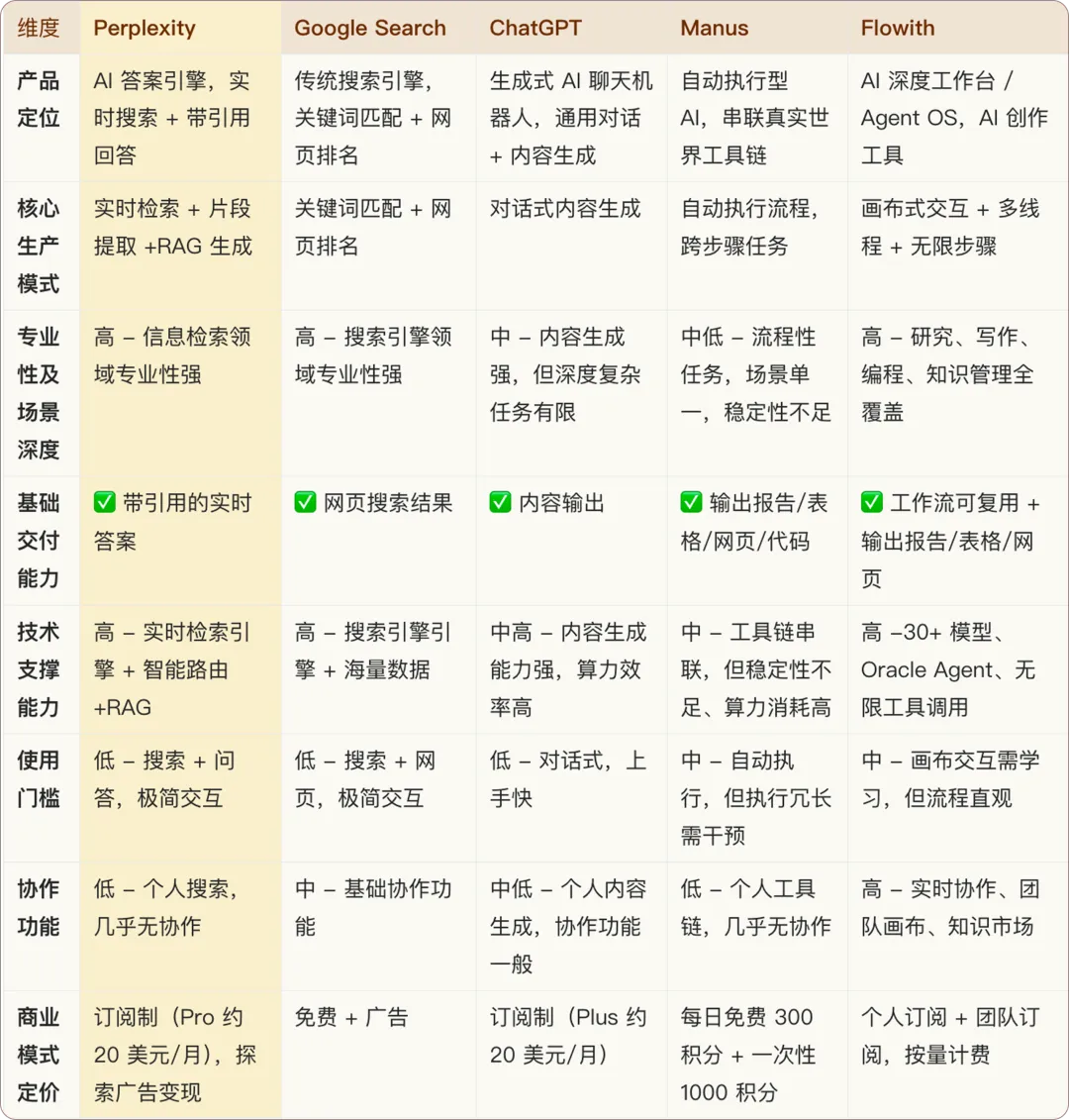
|核心差异化总结
Perplexity 在"实时信息 + 带引用回答 + 信息检索专业性"上形成差异化优势,适合需要快速获取和验证信息的研究者与知识工作者;Google 在搜索引擎领域专业性强;ChatGPT 在内容生成和性价比上领先;Manus 在自动执行上有潜力但稳定性不足;Flowith 在"问题深度 + 工作流覆盖度 + 画布交互"上有优势。

06. 商业模式

Perplexity 的商业模式是典型的 Freemium + 订阅制 + 广告探索。收入的关键是用户是否愿意为"实时信息 + 可信答案 + 高级推理"付费,而不是流量本身 。
|核心收入来源
订阅收入:Perplexity Pro 订阅(20 美元/月),提供先进多元 AI 模型支持、多样化数据呈现形式、高级推理模式、无限文件上传等
企业版 :Perplexity for Enterprise,面向企业团队,提供团队协作、权限管理、定制能力
广告探索:CEO 认为广告是最伟大的商业模式,正在探索广告变现路径
API 服务:未来可能开放 API,供第三方调用 Perplexity 的搜索和生成能力
|关键成本
模型调用成本:用户上传每次发起查询、生成、检索、总结,背后都要消耗模型与算力(GPT-4/Claude 等)
检索引擎成本:Vespa AI 引擎维护、2000 亿 URL 索引、实时搜索接口的云资源成本
推理引擎成本:ROSE 引擎部署于 AWS 云平台,运行在大规模 NVIDIA H100 GPU 集群上,Kubernetes 管理资源调度
获客与营销成本:PLG 增长 + 品牌营销,早期获客成本较高,印度市场 MAU 同比激增 640%

07. 全局总结

|综合评分:7.0/10

|核心优势
信息检索专业性极高:实时检索 2000 亿 URL,每秒数万次索引更新,信息新鲜度和准确性强 带引用回答机制:每一段回答都附带引用文献,答案可信度高,用户可快速验证 使用门槛低:搜索 + 问答,极简交互,用户上手快
|主要短板
问题深度有限:不覆盖深度任务(如 Research、写作、编程),不如 Flowith 深度 工作流覆盖窄:聚焦查询→验证→总结,不覆盖创作、编程、知识管理等场景 生态沉淀较浅:虽然有能力构建生态(如企业版、API),但实际用户行为和模板积累仍在早期
Perplexity 是一款 在信息检索专业性和系统化能力上达到 8 分水平,但在问题深度、工作流覆盖和生态沉淀上仍有提升空间 的 AI 答案引擎,适合需要快速获取和验证信息的知识工作者和研究人员 。

08. 趋势判断

|行业赛道
AI 搜索从"结果列表"走向"答案引擎"
大趋势:AI 正在从传统搜索引擎进化为可对话、可验证的答案引擎,Perplexity 踩在"AI 搜索"这个核心赛道上 。
- 短期(1-2 年)
AI 搜索从试点走向规模化,用户从"手动搜索 + 阅读"转向"提问→答案→验证" - 中期(3-5 年)
AI 答案引擎可能成为下一代搜索入口,重构信息检索方式 - 长期
AI 将从"信息检索"转向"认知推理",谁能完成复杂推理谁才有真正的护城河
|机会与风险
Perplexity 的核心机会在于其信息检索专业性、带引用回答、实时性和市场增长四个方向。首先,Perplexity 的实时检索 2000 亿 URL、每秒数万次索引更新是其差异化优势,短期内很难被竞争对手超越 。其次,Perplexity 的带引用回答机制让答案可信度高,用户可快速验证 。第三,实时信息是 Perplexity 的核心优势,信息新鲜度和准确性强 。最后,从市场层面看,AI 搜索赛道正处于高速增长期,MAU 同比激增 640%,超越 ChatGPT 增速 。
Perplexity 面临的主要风险集中在大厂竞争、深度任务边界、生态沉淀和成本压力四个方面。首先,Google、Microsoft 等大厂可能推出类似产品,如 Google 的 AI Overviews 已经是 AI 搜索方向的潜在竞争者,Perplexity 需要避免被大厂产品替代 。其次,深度任务(如 Research、写作、编程)边界有限,不支持复杂任务,用户需转向其他工具 。第三,虽然有能力构建生态(如企业版、API),但实际用户行为和模板积累仍需时间 。最后,模型调用、检索引擎、推理引擎成本是核心负担,盈利模型仍需时间验证 。
|竞争格局判断
Perplexity 目前处于"有差异化优势,但尚未形成绝对壁垒"的阶段:
- 与 Google、Microsoft 比
Perplexity 在"实时信息 + 带引用回答 + 信息检索专业性"上有优势 - 与 ChatGPT 比
Perplexity 更专注信息检索,ChatGPT 更通用内容生成 - 与 Flowith 比
Perplexity 是信息检索工具,Flowith 是 AI 深度工作台
关键判断:未来 2-3 年这个赛道会快速分化,Perplexity 有机会成为"AI 答案引擎"细分领域的头部玩家,但能否成为"行业标准"取决于生态建设速度和大厂竞争格局的演变 。
