 夜雨聆风
夜雨聆风常见现象包括:
OpenAI、Anthropic、Google、Ollama 各写一套封装 同一个测试助手在不同模型间切换成本很高 工具调用散落在脚本里,权限和日志不好管 Agent 任务失败后,很难复现中间步骤
AIsuite 更适合放在 Agent 工具调用与工作流 这个问题域里。它的价值不是替你选最强模型,而是把多 provider 调用、工具执行和 Agent 工作流放进更统一的接口层。
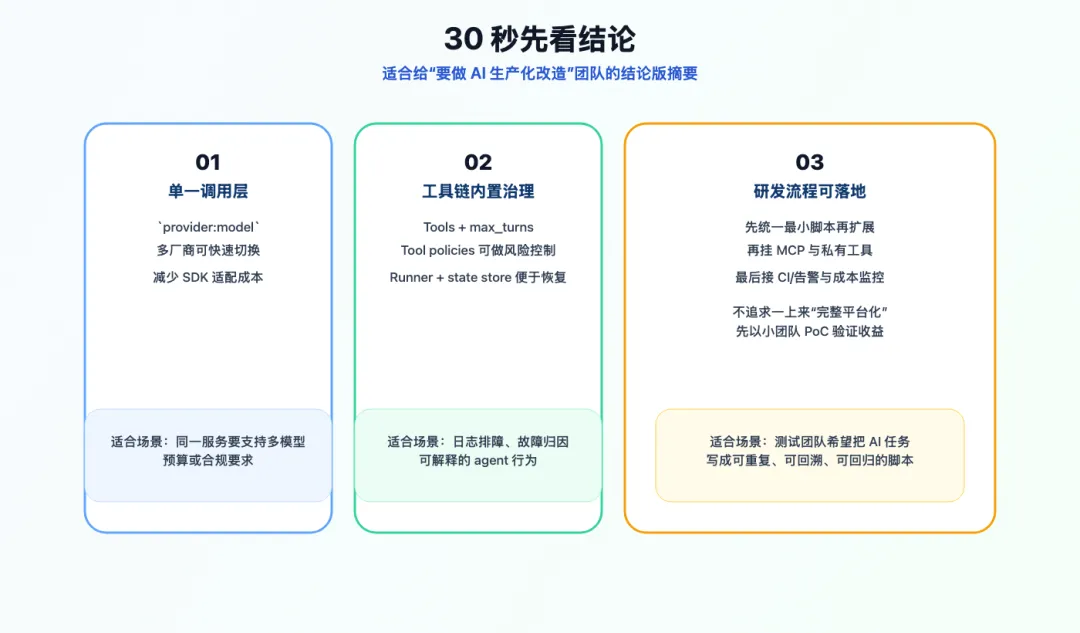
30 秒先看结论
如果你的团队已经开始写 AI 脚本、测试助手、仓库分析助手,AIsuite 最值得看这三点:
- 统一模型入口
:用 provider:model这类方式降低多模型切换成本 - 统一工具调用
:把 Python 函数、内置工具、MCP 工具接到同一类任务流程里 - 统一执行链路
:Agent/Runner/state/tool policy 这类能力让长任务更容易治理
收益判断这里必须说清楚:上面是基于 AIsuite 官方 README 和文档能力的工程推导,不是官方承诺的提效数据,也不是社区普遍评价。
这篇文章里的图片分两类:
本地结构化 SVG:用于解释调用层、工具执行、落地节奏 GitHub 仓库截图:用于证明项目主页和官方入口真实存在,不作为社区评价或效果数据使用
一、它为什么适合测开团队?
测试团队做 AI 提效,往往不是只写一个聊天机器人,而是会把模型接到真实工具上:
读日志 查仓库 分析 PR 总结失败用例 生成报告 调用内部接口
这时问题就变成了工程治理:模型怎么切换、工具怎么授权、状态怎么保存、失败怎么复现。
AIsuite 的切入点是把“模型调用 + 工具执行 + Agent 运行”放到更统一的 Python 接口里。对测开来说,它更像一层轻量调用框架,而不是完整平台。
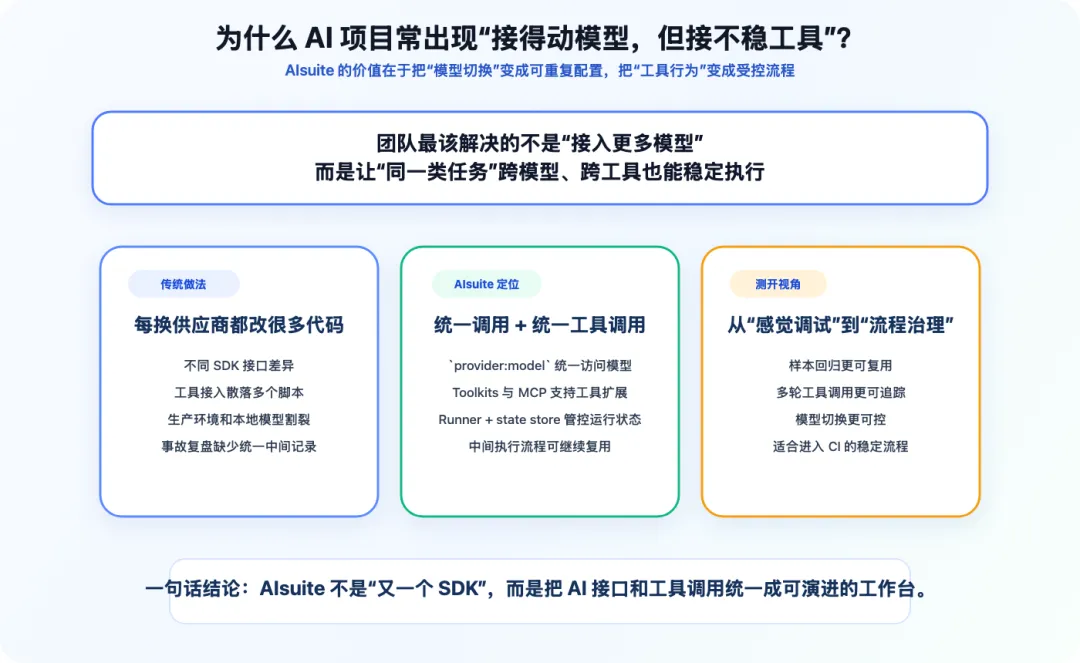
二、先看官方入口:仓库主页和安装
下面这张是 GitHub 仓库首页截图,用来证明项目主页、仓库归属和官方入口真实存在。它只作为仓库事实截图,不作为“社区认可”或“效果数据”使用。
官方 README 给出的基础安装方式是:
pip install aisuite
按 provider 安装可选依赖,例如:
pip install 'aisuite[anthropic]'
pip install 'aisuite[all]'
如果使用 MCP,官方文档也提供了相关 extra。具体接入前,应以仓库 README 和 docs 里的当前说明为准。
三、最小闭环怎么跑?
第一阶段不要直接上复杂 Agent。先验证统一模型入口是否能降低迁移成本。
import aisuite as ai
client = ai.Client()
response = client.chat.completions.create(
model="openai:gpt-4o",
messages=[{"role": "user", "content": "总结这段测试日志的风险点。"}],
)
print(response.choices[0].message.content)
这一步要验证三件事:
同一套 messages 能否换 provider/model 结果结构是否方便统一解析 错误、超时、密钥配置是否能被纳入统一处理
然后再加工具调用,例如日志分析、文件读取、仓库检查。
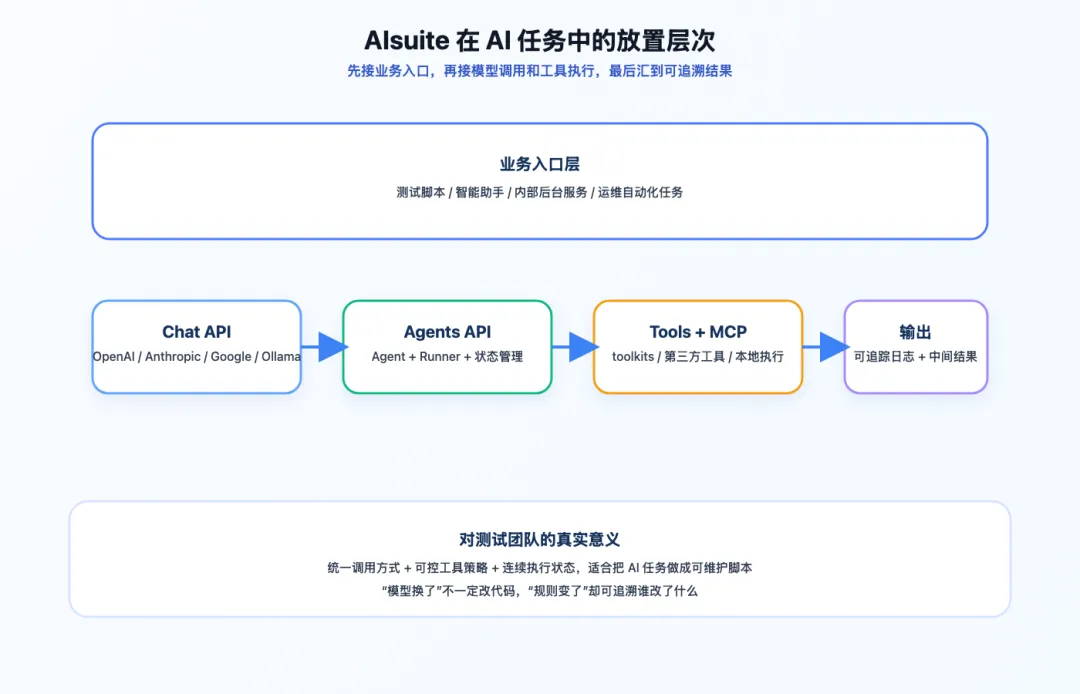
四、测试团队怎么接进工作流?
推荐从低风险工具开始,不要一上来让 Agent 执行 shell 或改代码。
第一批可以选:
只读日志分析 只读仓库目录扫描 测试报告摘要 PR diff 风险归类 CI 失败原因聚合
落地顺序可以这样做:
固定一个模型和一个只读工具 准备 20 条真实任务样本 记录模型输入、工具调用、中间结果、最终输出 设置 tool policy,限制工具范围和参数 再逐步引入 state store、MCP、更多 provider
这条链路里,AIsuite 负责统一调用和执行框架;权限、安全、审计和业务标准仍然要由团队自己定义。
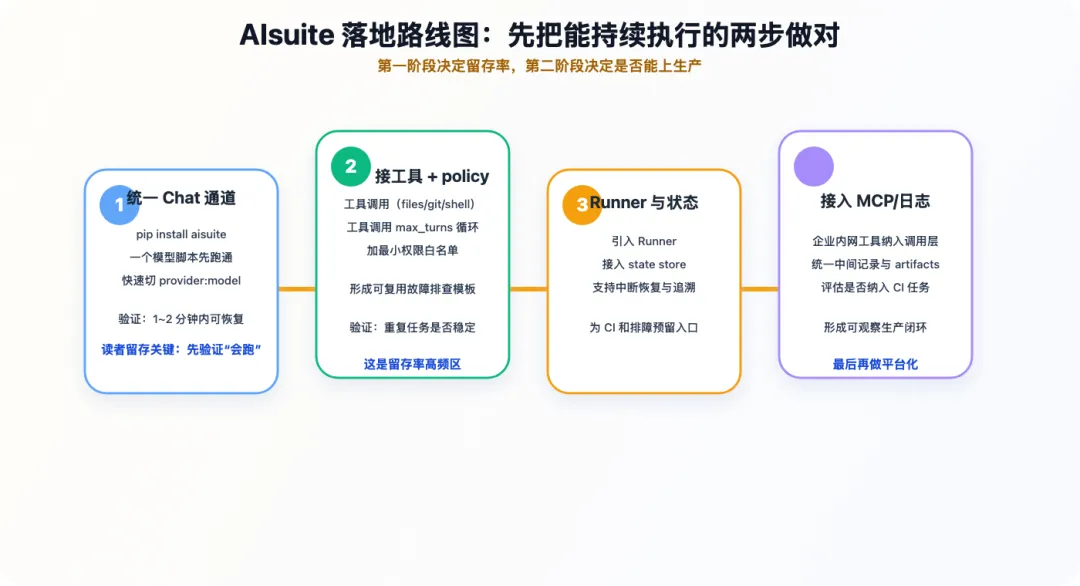
五、和 LiteLLM、LangChain、多 Agent 框架怎么区分?
如果你的痛点是“多模型和工具调用分散在脚本里”,AIsuite 更直接;如果你要做企业级模型网关,LiteLLM 更贴近;如果你要完整应用生态或多角色任务编排,其他框架可能更重。
六、使用时的 6 个坑
- 把统一调用当成统一质量
模型入口统一了,不代表输出质量统一。仍然要有样本和评测。
- 工具权限给太大
测开场景经常涉及仓库、日志、环境变量。工具必须最小权限。
- 没有记录中间步骤
Agent 失败时,只看最终回答没用。要保存工具调用和中间消息。
- 过早接入高风险 MCP 工具
先从只读工具开始,再逐步放开写操作和外部系统调用。
- 状态持久化没有隔离
文件、内存、数据库 state store 都要按环境和权限隔离。
- 把仓库截图当口碑证据
本文的 GitHub 截图只证明项目真实存在,不证明效果。
七、一个 1 周试点方案
第 1 天:统一模型入口
跑通一个 provider/model,并保留输入输出日志。
第 2 天:切第二个模型
用同一批任务切另一个 provider,比较输出结构和错误处理。
第 3 天:接一个只读工具
例如日志摘要或文件读取,限制目录和参数。
第 4 天:准备任务样本
整理 20 条真实测开任务,例如 CI 失败归因、PR 风险总结。
第 5 天:加 tool policy
限制工具调用范围、次数和敏感路径。
第 6 天:记录中间链路
保存模型消息、工具调用、错误和最终输出。
第 7 天:评估是否扩展
根据失败样本决定是否接 MCP、state store 或更多工具。
八、总结
AIsuite 的价值不在“更强模型”,而在“减少多模型、多工具、多任务脚本的混乱”。
它适合这些场景:
测试日志分析助手 PR 风险检查助手 CI 失败总结助手 仓库只读问答工具 多模型对比实验脚本
如果你的团队只是单模型、单脚本 PoC,它可能不是第一优先级;但只要开始接多模型和工具,统一调用层就会变得很关键。
参考资料:
AIsuite GitHub:https://github.com/andrewyng/aisuite Chat Completions Quickstart:https://github.com/andrewyng/aisuite/blob/main/docs/chat-completions-quickstart.md Agents Quickstart:https://github.com/andrewyng/aisuite/blob/main/docs/agents-quickstart.md PyPI:https://pypi.org/project/aisuite/
