 夜雨聆风
夜雨聆风1257期 | 2026.06.26

为探索科学落地的学术评价体系,推动新时代学术评价的改革和实践,复旦大学国家智能评价与治理实验基地与复旦新学术共同开设“新评价”栏目,以“知评价”“谈评价”“践评价”等话题聚焦、共议当代学者共同关心的学术学科评价的理论、方法与实践问题,为新时代中国哲学社会科学的良性发展与繁荣、建构中国自主的知识体系贡献绵薄之力。


摘要:迄今为止,生成式人工智能(GAI)的应用主要集中在内容评价。社会科学领域亟需开展研究质量评价及相关研究。因此,我们使用最先进的GAI模型进行质量评价,以考察其在社会科学领域的适用性。本研究采用GPT-4o和DeepSeek-V3模型,从一组高质量论文中筛选出相对更高质量的论文,将其与人类专家决策、被引次数及下载量的对比作为质量评价的基础。GAI模型在一定程度上能够评估高质量论文的学术价值。我们发现,基于GAI的质量评分与文献被引次数、下载量之间存在正相关关系,但相关性有限。研究同时观察到,GAI在质量评价中存在选择性偏好:更青睐那些使用显性技术术语、规范方法论框架,或表述看似宽泛但措辞客观的论文。相比之下,GAI往往低估了理论抽象度较高或社会语境嵌入性较强的论文质量。本研究为界定GAI在社会科学研究质量评价中的作用提供了新的实证基础,并为学术机构、图书馆、资助机构及研究管理机构提炼出了指导意见。研究预计,经过学术质量评价训练的GAI在筛选高质量论文时,其结果与人类专家的一致性将高于当前现有的模型。
关键词:社会科学学术评价;研究质量评价;学术评价;生成式人工智能;ChatGPT;DeepSeek
1.引言
GAI技术的快速发展为学术评价开辟了新的可能性。现有研究表明,GAI可以在一定程度上辅助传统的同行评审流程,尤其适用于自然科学和工程领域,这些领域研究成果结构化程度更高,评价标准相对规范。因此,GAI在生物医学、医学、计算机科学、地理学、数学和化学等领域表现突出,特别是在评价创新性、原创性和社会影响方面。然而,该研究方向仍存在两大局限。首先,现有样本多集中于自然科学和技术科学领域,在社会科学语境中的验证尚显不足。不同于自然科学研究,社会科学研究往往受到实证主义、解释主义和批判认识论范式的影响,具有认识论更复杂、价值观更为多元的特征。这意味着社会科学领域应采用更为细致的评价方法。其次,当前研究主要侧重于内容层面的评价(如新颖性、原创性),而涵盖长期维度的质量评价(如学科影响、实践指导)仍严重缺乏。长期维度的质量评价存在的固有特征——时间跨度长、评价指标模糊、高度依赖专家判断和情境理解,导致其仍是学术评价中成本高昂且发展不足的一个环节。这种更全面的质量评价方法亟需智能技术支持。
为弥补这些不足,本研究以图书馆与信息科学(LIS)领域为例,探讨在社会科学领域使用GAI进行质量评价的有效性。基于“中国社会科学优秀文献全文数据库(CSSEFD)”和“哲学社会科学经典文献数据库(CLD)”,本研究构建LIS领域再版论文(RPs)和经典论文(CPs)的标注数据集,并通过提示词工程引导GAI对其学术质量进行评价。
本研究围绕三个核心问题展开:
RQ1:在对高质量社会科学论文进行分类时,GAI与专家判断的契合度如何?
RQ2:AI赋予的质量评分与被引用次数及下载量之间是否呈正相关?
RQ3:哪些类型的LIS论文会更容易获得GAI更高的或更低的质量评分?
2.数据与方法
在数据采集与分析阶段,本研究构建了一个融合专家评审与GAI评价的混合框架。
数据采集阶段,本研究选取了CSSEFD作为高质量文献数据集(RPs)的基准数据集,以及CLD作为高质量论文黄金标准数据集(CPs expert)。通过跨库比对与补充,最终形成包含2844条图情档领域高质量论文的数据集(RPs)与510条专家鉴定的元数据集(CPs expert)。在此基础上,选用GPT-4o和DeepSeek-V3两种GAI模型,严格遵循CLD的四个质量评价维度,每篇论文的标题与摘要由两个模型独立进行五轮评价。同时,本研究从中国知网获取了所有高质量文献数据集(RPs)的引用次数和下载次数,以支持后续的学术影响力分析。
分析层面,研究围绕三个核心问题展开。针对研究问题一,将GAI模型的决策(被归类为高质量论文,RPs AI)与CLD中专家标注的高质量论文集(CPs expert)进行对比,设计了六种分类策略以增强稳健性,并通过精确率、召回率、F1分数和ROC曲线下面积(AUC)等指标衡量自动化评价系统的准确性和与人类评价结果的一致性。针对研究问题二,将论文分为专家标注高质量论文(CPs expert)、AI识别高质量论文(RPs AI)以及普通论文(RPs)三组,对被引次数和下载次数进行标准化处理后,运用多种统计检验方法比较两两组间差异。针对研究问题三,结合关键词演变分析与词语联想主题分析,比较CPs expert与RPs AI两组论文中的高频词。在文本处理上,采用分词工具分别处理中英文文本,并运用Bootstrap重采样方法克服样本量不平衡问题,最后由研究人员对高频术语进行人工聚类,归纳出高质量论文的研究方向与知识参考价值特征。
3.结果
研究问题1:在对高实用性社会科学论文进行分类时,GAI与专家判断的契合度如何?
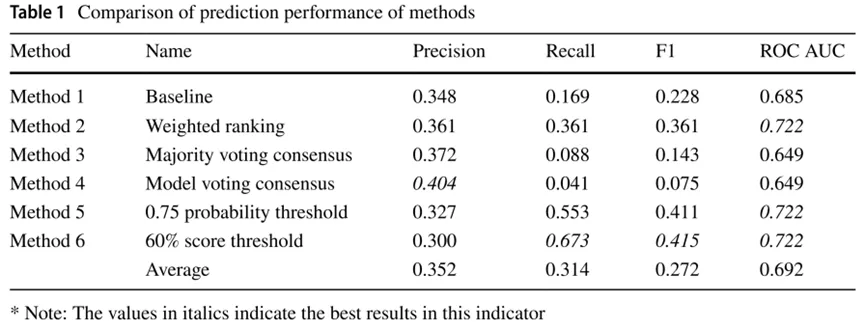
研究设计了六种分类策略(见表1),将GAI模型的评价结果与CLD专家标注的高质量论文进行比较。结果显示,六种方法的平均精确率为0.352,平均F1值为0.272,表明GAI在识别高质量文献方面存在精确度不足的问题。其中,方法六(60%分数阈值)表现最优,F1值达到0.415,召回率高达0.673,能够在覆盖大部分专家标注论文的同时保持较好的区分能力(AUC=0.722)。因此,该方法被选定为后续分析的最优策略。
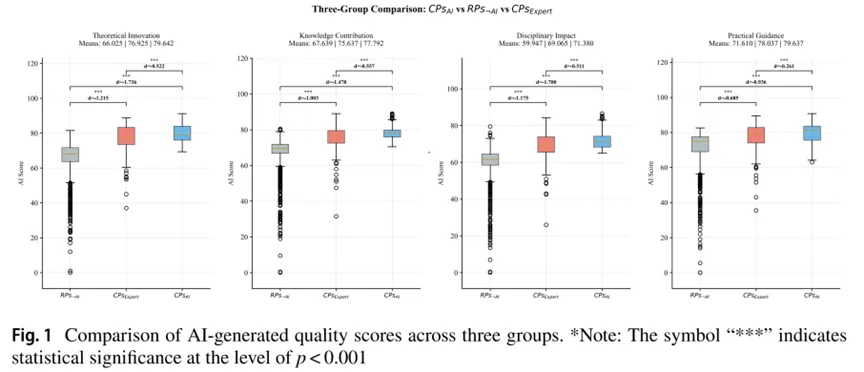
进一步的区分效度检验显示:GAI筛选出的高质量论文(RPs AI)在理论创新、知识贡献、学科影响、实践指导四个维度上的得分均显著高于未被AI选中的论文(RPs ¬AI,p<0.001),表明GAI具备稳定、一致的内部评价逻辑。但与专家标注的高质量论文(CPs expert)相比,GAI评分仍偏高,说明GAI与人类专家的质量标准存在存结构性差异,只有部分重叠。
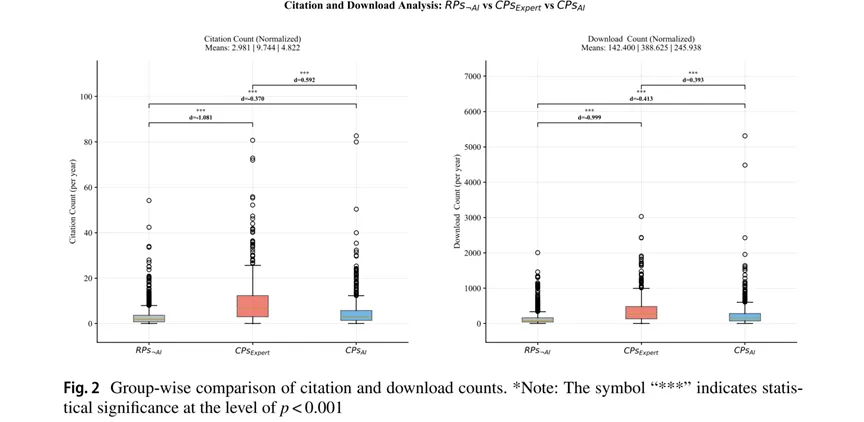
研究问题2:GAI质量评分与引用量、下载量是否呈正相关?
本研究通过对比专家标注高质量论文(CPs expert)、GAI筛选出的高质量论文(RPs AI)与未被AI选中的论文(RPs ¬AI)三组在标准化引用次数和下载次数,证实GAI质量评分与这两项指标呈正向相关关系,但相关性有限。结果显示:
> 专家标注论文(CPs expert)的年均引用与下载量显著最高;
> GAI筛选论文(RPs AI)显著优于未被AI选中的论文(RPs¬AI),但明显低于专家标注论文(CPs expert);
> 未被AI选中的论文(RPs ¬AI)表现最弱。
这表明GAI能够在一定程度上识别学术影响力更高的文献,但其判断与真实学术影响力之间仍存在明显差距,无法完全替代基于引用与专家判断的学术评价。
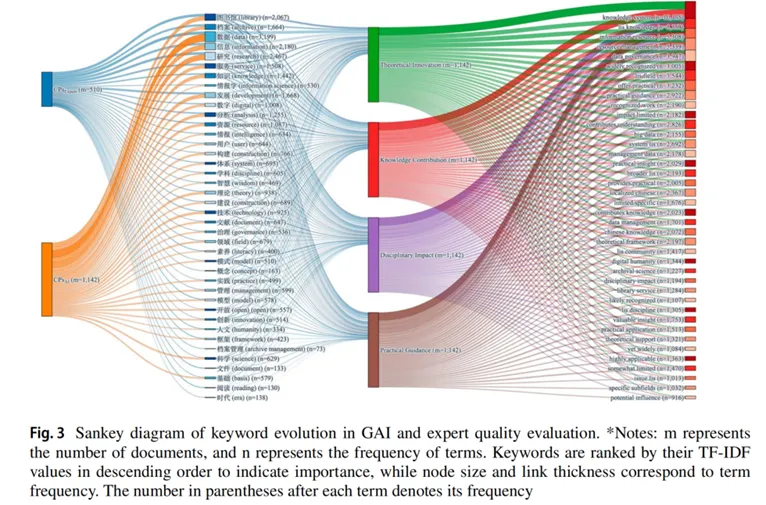
研究问题3:哪些类型的LIS论文更容易获得GAI高分/低分?
关键词分析、桑基图与词语联想检验(WATA)共同揭示了GAI明确的语言与主题偏好:
> GAI倾向于给高分:聚焦微观与中观的实践导向,善用专业技术术语、方法框架、数据、模型、体系构建等内容,并采用客观化、实证化的表达方式;
>GAI倾向于给低分:理论抽象度高、强社会嵌入、宏观思辨、人文色彩浓厚、非结构化表达的研究。
总之,GAI对形式化、工具化、技术化、实践导向的文本特征高度敏感,而对深层理论创新、制度逻辑与人文价值的识别能力较弱,呈现出明显的表层语言偏向。
4.讨论
4.1 本研究质量评价与传统评估研究的对比
在社会科学文献质量评价中,即便采用当前最先进GAI模型,其复现专家标准的能力仍受限。最优配置下F1仅0.415,平均精确率0.352、召回率0.314,一致性未达可接受水平。GAI虽具备稳定的内部区分逻辑,但与专家标准存在系统性偏差,易高估部分未获专家认可成果的质量。
现有研究证实GAI在自然科学多学科领域以及社会科学领域中的经济学等学科中效果较好,因这些领域文本结构规范、术语统一;而部分社会科学强调理论深度、语境嵌入与多元解读,仅靠标题与摘要,GAI难以复现专家复杂评价逻辑。GAI依赖文本表层特征,专家判断则超越文本、整合学术背景与理论价值,二者对学术质量的理解存在本质差异。
4.2 GAI质量评价的内部效度与外部相关性
GAI评分与引用量、下载量呈正向但有限相关,可识别具备短期关注度的文献,但整体表现显著弱于专家筛选成果。GAI易于将表面关注度、语言规范性、热点主题等同于真实学术质量,混淆短期吸引力与长期学术价值,降低了评价的可信度与可解释性。
4.3 GAI质量评价中的结构偏好
GAI呈现明确的表层语言偏向:偏好技术、方法、实践导向的微观/中观研究,高频关键词集中于数据、模型、分析等显性表述;对理论创新、学科影响、宏观制度与深层语境的识别能力明显不足。
本质上,GAI并非误判质量,而是受训练架构与数据驱动,重新定义了“有用知识”,偏向可操作、显性化、实践导向内容。若直接用于学术评价,可能导致研究生态从理论驱动转向形式化、效率驱动,不利于学术自主性。
4.4 局限性与未来改进
本研究存在三方面局限:首先,仅以标题与摘要为输入,未纳入全面内容;其次,样本仅限LIS单一学科;第三,采用未做领域微调的通用GAI模型。
未来可沿三条路径推进:首先,构建领域专家语料库微调模型并结合图RAG增强语境理解;其次,系统识别并缓解评价偏差;第三,开展对照实验,检验基于大语言模型(LLM)评价的可操纵性,建立相关防范机制。
5.结论
本研究首次系统性地揭示了GAI模型与人类专家在社会科学学术质量评价的评价标准和模式方面存在可量化且不可忽略的差异。这些差异不仅反映出准确性问题,还反映出GAI在解读学术文本时对语言结构和模式识别的偏好。方法论术语、技术路径和操作描述清晰的论文,GAI倾向于赋予更高的分数。但是GAI显著低估了侧重于宏观理论视角、深层社会背景嵌入和制度机制探索的论文。这一发现为定义GAI在社会科学学术评价中的作用提供了新的实证基础。
从理论贡献的角度来看,本研究表明,GAI驱动的学术评价领域亟需开展更为精细、目标导向的分类研究,方能得出可靠且可解释的结论,尤其在评估研究的长期社会影响与科学影响力时更为关键。同时我们揭示的语言结构偏好,体现了GAI在深度解读非结构化文本时的边界条件,为构建具有语境感知和跨维度推理能力的学术评价GAI奠定了可解释的理论基础。
在实践贡献方面,本研究为学术机构、图书馆、资助机构和科研管理机构提供了重要的指导:在使用GAI进行学术文献筛选、研究趋势预测或学术资源分配时,应充分认识到GAI偏好模式可能导致的方法论-实践导向偏差。此外,虽然GAI能够在一定程度上识别具有短期学术关注潜力的文献,但它系统性地高估了未被专家共识认可的成果,并将被关注与产生效用混为一谈。尽管GAI在新颖性和原创性等静态内容质量评价方面表现尚可,但长期质量指标属于动态的、历史性的、高度依赖专家智慧的判断范畴,GAI的替代能力仍然有限。
研究结果表明,目前GAI还无法取代人类专家对社会科学学术研究理论深度和社会背景的深刻理解,应被视为一种同行评议的辅助工具。这种理解不仅有助于制定AI辅助学术评价的风险管理策略,而且为设计人机结合的学术评价机制提供了实证依据,从而确保研究评价和资源分配在技术效率和学术可信度之间取得平衡。
(全文及参考文献见Scientometrics,原文链接:https://doi.org/10.1007/s11192-026-05570-9,本期推文为节选摘编,有所删减和编辑。)
本期策划 | 复旦大学国家智能评价与治理实验基地
复旦大学新学术网
供稿 | 王萱瑜 王译晗
本期编辑 | 学术君001号
本平台图文发布除特别注明外,版权归新学术网
新学术合作联系:fudanxinxueshu@163.com
平台使用图片除特别注明来源,均来自公版权网站
https://pixabay.com/zh
新学术门户:www.fudanxinxueshu.com
www.xinxueshu.cn
• end •
长按识别二维码,了解学术新风向

