 夜雨聆风
夜雨聆风Anthropic 这个开放协议,正在悄悄变成整个 AI 圈的共同语言
故事是这样的。
愚钝如我,作为AI圈新人,前两天,被 Claude结结实实教育了一回。
前两天,我让 Claude帮我干了一件很具体的事。
一件我自己做可能要花上一两天,但又确实必须做的事。
你猜怎么着。
我让Claude跑了大概几个小时,过程中穿插了五六个不同的MCP,搞定了四五个步骤,最后出来的东西,我看了一眼,挺出乎我意料的。
最让我吃惊的,不是它做了啥,而是它做的过程里,我几乎没有救场。
Claude自己判断该用哪个工具,该调哪个 MCP,该跳过哪些步骤,该在哪里停下来确认。整个流程跑下来,我就坐在那,喝着咖啡,偶尔扫一眼屏幕上的进度条。
那一刻我脑子里就一个想法。
AI 的工作方式,被一个叫 MCP的东西,悄悄改变了。

MCP 一周年:从 Anthropic 的小实验,到行业的基础设施
· · ·
MCP 是个啥
如果你最近两年没太关注 AI 圈的基础设施层,你可能听过这个词,但不一定真的明白它干了啥。
坦率的讲,我一开始也没太当回事。
MCP全称Model Context Protocol,是 Anthropic在2024 年 11 月开源的一个协议。
一句话讲清楚,它就是个标准。一个让大模型能「接上」外部工具的标准。
这个比喻我想了很久,最贴切的应该是 USB-C。
在USB-C出来之前,每根线,每种接口,每个设备,都有自己的连接方式。充电器、硬盘、手机、相机,外设厂商要做一堆适配。USB-C出来之后,一根线通吃。
MCP干的事,差不多。
在MCP之前,AI 工具圈是这样的。
每一个外部工具,比如浏览器、数据库、文件系统、邮件客户端,都得跟每个 LLM 厂商单独接一次。OpenAI接一遍,Anthropic接一遍,Google接一遍,DeepSeek接一遍。
工具方痛苦,模型方也痛苦。
这是个 M 乘 N 的灾难。
MCP出来之后,工具方只需要按 MCP标准实现一次 server,就能在所有支持 MCP的客户端里用。模型方也只需要实现一次 client,就能接所有 MCP server。
从 M 乘 N 变成 M 加 N。
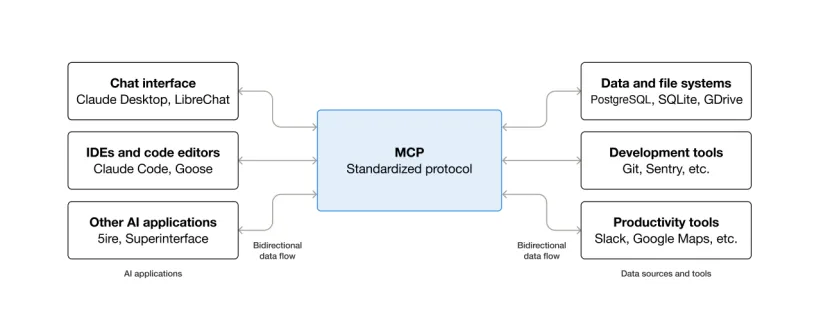
MCP 核心架构:Host / Client / Server 三角色交互
但这只是粗线条。
如果你愿意再往下挖一层,MCP这套协议,真正的设计其实是这样的。
它规定了三个角色。
Host,就是装 MCP客户端的那个程序,比如 Claude Desktop,比如 Claude Code,比如你公司里某个内部 AI 工具。
Client,跑在 Host里,负责跟 Server说话。
Server,就是那个具体干活的工具,比如文件系统 MCP,比如 GitHub MCP,比如某个数据库 MCP。
Host跟Server之间,中间是 Client在桥接。
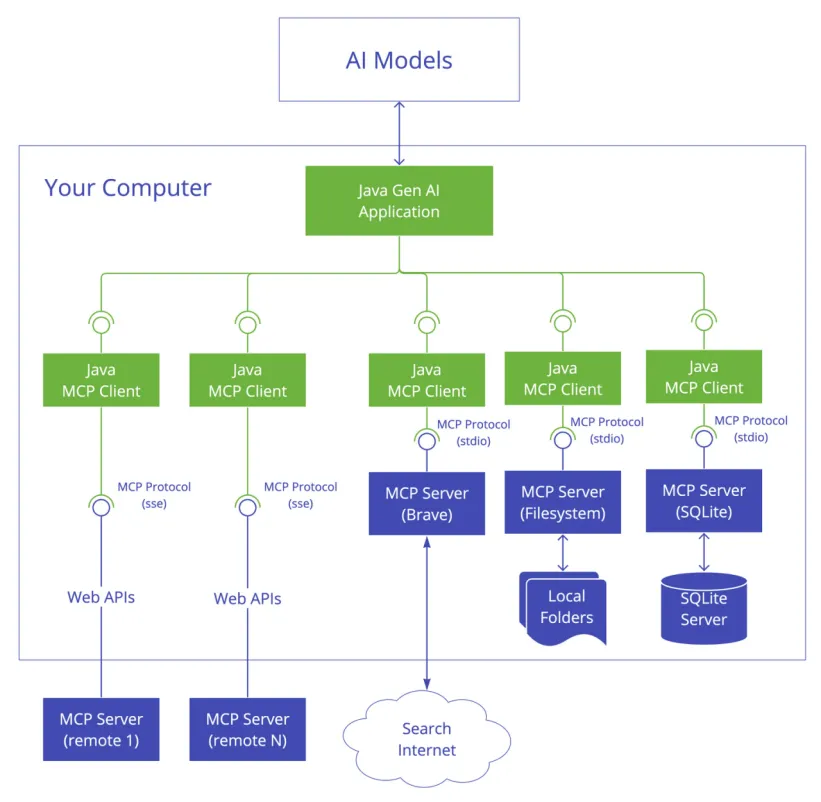
Java MCP Client 架构:Spring AI + stdio 桥接
数据流是这样的。
用户在Host里跟 LLM 对话,LLM 觉得「我需要调一下文件系统 MCP看看某个文件」,它就告诉 Client,Client通过MCP协议跟文件系统Server说话,Server干活,把结果返回给 Client,Client拿给 LLM,LLM 把结果组织成人话给用户。
这一圈,可能就几百毫秒。
· · ·
顺着这个,我把 MCP的三个核心原语也讲一下。
第一个,Resources。
就是给 LLM 看的东西。比如「我电脑上所有 PDF 的列表」,「我这个项目里所有的 Python 文件」,「我数据库里所有的表名」。Resources是只读的,LLM 可以问「有没有」「是什么内容」,但不能通过 Resources改东西。
第二个,Tools。
就是 LLM 可以调用的函数。这是 MCP里最常用、也是大家最熟的原语。比如「读取这个文件」,「执行这个 SQL」,「打开这个网页」。Tools跟传统Function Calling的区别在于,MCP的Tools是一组声明在 server 启动时就注册好的,Client可以随时通过tools/list拉一份清单过来。

Tools 原语:Server 启动时注册,LLM 通过 tools/list 拉取
第三个,Prompts。
这是MCP独有的设计,Anthropic把它做成了一种「预制的提示词模板」。Server可以声明一些提示词模板,比如「总结这篇文章」,「解释这段代码」,「给这个 commit 写个 changelog」。Host可以在 UI 上让用户一键触发,触发之后,模板里的变量会被填好,送给 LLM。
Prompts 原语:Server 声明的预制提示词模板
三个原语,资源、工具、提示词。
一个 LLM 拿到这三样东西,就等于有了「看」「做」「想」三种能力。
· · ·
再讲一个很多文章没讲清楚的东西。
MCP的传输层。
一个MCP server,跟 Client之间的连接,可以走三种通道。
第一种,Stdio。也就是标准输入输出。Server是个本地进程,Client通过进程的stdin喂JSON-RPC请求,通过 stdout拿JSON-RPC响应。这是最简单、也是最常见的模式,适合本地工具,比如文件系统、Git、SQLite。
第二种,SSE。Server-Sent Events,基于 HTTP。Server是个跑在某台机器上的服务,Client通过HTTP长连接订阅事件流。这种适合远程服务,比如云端数据库、API 网关。2025 年之前的MCP远程调用主要走这个。
第三种,Streamable HTTP。这是2025 年 11 月 MCP新版本里推出的。它把SSE升级了一下,支持双向流、批处理,还有更细粒度的 session 管理。远程 MCP以后基本都走这个。
为什么这个细节重要。
因为它决定了「我装一个MCP,到底在装啥」。
装StdioMCP,你在装一个本地进程,装上之后它常驻后台,每次 Claude用它的时候,通过 stdin/stdout通信。
装Streamable HTTPMCP,你在订阅一个远程服务,这个服务可能在 AWS,可能在阿里云,你给它发 HTTP请求,它给你回响应。
两种部署模型完全不同,安全模型也完全不同。
StdioMCP跟你同权限,因为它就是你的进程。Streamable HTTPMCP是别人家的服务,它的权限边界在你的 token 上。
这个区分,我后面讲安全的时候还会回来聊。
· · ·
MCP 在底层到底是怎么跑的
讲完协议骨架,我再讲一个更技术一点的东西。
MCP底层用的是JSON-RPC 2.0。
这是个非常老牌的 RPC 协议,2009 年提出来的,比 gRPC 还早。JSON-RPC的设计极简,请求和响应都是 JSON 对象,长这样。
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/list",
"params": {}
}
这是Client问Server「你有哪些 tools」。
Server回的响应长这样。
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"tools": [
{
"name": "read_file",
"description": "读取文件内容",
"inputSchema": {
"type": "object",
"properties": {
"path": {"type": "string"}
}
}
}
]
}
}
就是声明,「我有一个工具叫 read_file,它接受一个 path 参数」。
LLM 拿到这个清单,就知道自己能用这个工具了。
然后 LLM 要真用,会发一个 tools/call请求。
{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/call",
"params": {
"name": "read_file",
"arguments": {
"path": "/home/user/notes.md"
}
}
}
Server接到这个请求,去读文件,把内容塞回 result 里。
整条链路就完了。
Client→ JSON-RPC请求→ Server→ JSON-RPC响应→ Client→ LLM → 用户
整个过程,LLM 看到的是两个东西。
一个「工具清单」,一个「工具调用结果」。
它不关心底下是Stdio还是HTTP,也不关心 Server跑在哪台机器上、用什么语言实现。
这就是协议抽象的力量。
· · ·
光讲协议太抽象,我给你看一段真实代码。
下面这个是我让公司小朋友帮我写的一个最简单的MCP server,Python 版的,大概 30 行。
from mcp.server import Server
from mcp.server.stdio import stdio_server
import asyncio, os
app = Server("file-reader")
@app.list_tools()
async def list_tools():
return [{
"name": "read_file",
"description": "读取指定路径的文件内容",
"inputSchema": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "要读取的文件路径"}
},
"required": ["path"]
}
}]
@app.call_tool()
async def call_tool(name, arguments):
if name == "read_file":
path = arguments["path"]
with open(path, "r", encoding="utf-8") as f:
content = f.read()
return [{"type": "text", "text": content}]
raise ValueError(f"未知工具,{name}")
async def main():
async with stdio_server() as (read_stream, write_stream):
await app.run(read_stream, write_stream, app.create_initialization_options())
asyncio.run(main())
看到了吧。
装饰器风格,声明式,30 行代码,一个能读文件的 MCP server 就写完了。
放到Claude Code的配置里,Claude就多了一个能力,「读我电脑上任意一个文本文件」。
这就是MCP厉害的地方。
它把「给 AI 加一个能力」这件事,从「写一个完整的 ChatGPT plugin,要搞鉴权、OAuth、托管」,降级成了「写 30 行 Python」。
· · ·
我再讲一个更进阶的东西,叫 Sampling。
这是MCP2025 年新版本里加的特性,也是让 MCP跟传统Function Calling拉开差距的关键设计。
传统Function Calling,是 LLM 调用工具。LLM 主动,工具被动。
MCP的Sampling反过来了。
Server可以反过来问Client「我需要 LLM 帮我处理一下这个东西」,Client接到这个请求,让 LLM 跑一下,把结果回给 Server。
举两个真实场景。
第一个,代码审查 MCP。
它扫描你最近改的代码,生成一份「可能有问题」的清单。但它不直接报给用户,它通过 Sampling让 LLM 帮它润色一下,「给每条问题写一段人话解释」,然后才返回给用户。
没有Sampling,这个 MCP就只能给一堆干巴巴的代码 diff,质量很差。有了 Sampling,它的输出质量直接上一个台阶。
第二个,数据库 MCP。
你让它「找一下最近一个月销售额最高的 10 个客户」。它跑 SQL 拿到结果,但结果可能是个 100 行的表。它通过 Sampling让 LLM 帮它「总结成一段话,顺便提几个值得关注的点」。
没有Sampling,你就只能看到一张表。有了 Sampling,你看到的是「销售冠军是 X 公司,占了 23%,值得跟进」。
Sampling让Server从「一个被动的工具」,升级成了「一个能主动用 AI 的智能体」。
这才是MCP真正的魔法。
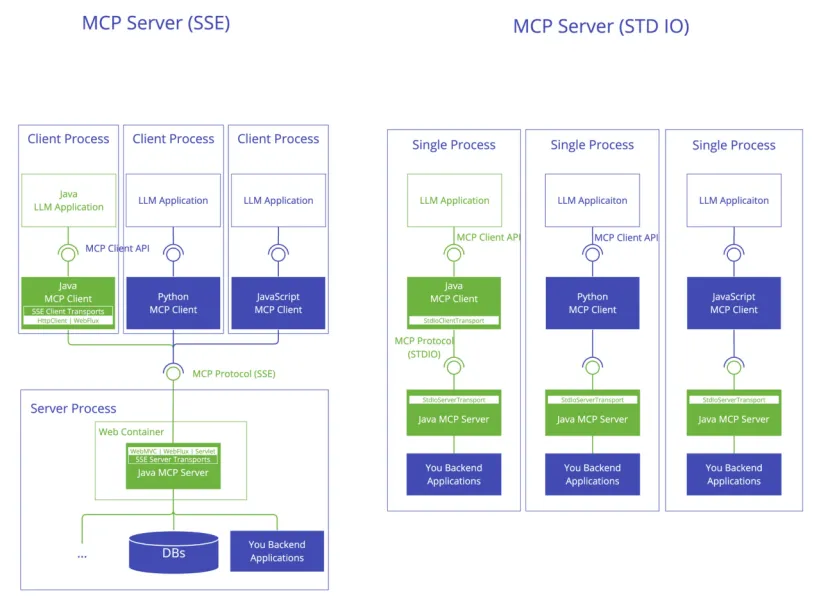
Java MCP Server 架构:Tools + Resources + Prompts 三原语封装
= =
· · ·
MCP 跟 Function Calling 到底差在哪
讲完协议和实现,我想专门聊聊 MCP跟Function Calling的差异。
因为这俩经常被混为一谈,但其实根本不是一个层级的东西。
Function Calling是 LLM 厂商的 API 能力。
OpenAI的Function Calling、Anthropic的 Tool Use、Google的Function Calling,虽然叫法不一样,干的事都差不多,让 LLM 在输出里加一个特殊的字段,表示「我想调这个函数」。
这个字段是模型自己生成的,模型觉得该调,就生成。
它是一个「一次性的指令」,发出去,函数执行,结果回来,塞回上下文,没了。
MCP不是这个。
MCP是进程之间的通信协议。
它规定了 LLM 跟外部工具之间,怎么握手、怎么发现能力、怎么传递上下文、怎么管理 session、怎么处理错误。
差异,我列几个关键点。
第一,持久性。
Function Calling是一次性的,调完就完了。MCP是长连接,Client跟Server之间维持一个 session,可以反复调用,可以订阅事件,可以保留上下文。
第二,能力发现。
Function Calling是写死在 prompt 里的,「我有这些函数,长这样」。MCP是动态的,Client可以随时问Server「你现在有哪些 tools」,Server可以运行时增加或修改工具。
第三,反调用。
Function Calling是单向的,LLM → 工具。MCP双向,工具也能反过来请 LLM 帮忙,就是 Sampling。
第四,生态位。
Function Calling是每个 LLM 厂商私有的。MCP是开放的,任何人都能实现 client 或 server,任何模型都能用。
这四条差异加在一起,你会发现一个事。
Function Calling解决的是「LLM 怎么调一个函数」。
MCP解决的是「LLM 怎么跟整个外部世界协作」。
前者是一个能力,后者是一个生态。
· · ·
一年半,成绩单
让我再讲一个我观察到的现象。
MCP出来一年半,整个生态的变化速度,比我预想的要快。
2024 年 11 月,Anthropic刚开源MCP的时候,业内其实反应不大。很多人觉得,又一个协议,又一个标准,谁知道能不能活过一年。
但接下来发生的事,超出了大部分人的预期。
2025 年上半年,Claude Desktop第一个全面支持MCP,相当于给整个生态打了个样。
2025 年下半年,OpenAI宣布支持MCP。
注意,是 OpenAI,那个 Anthropic最大竞争对手的OpenAI。
那结果会怎样呢,大家也都看到了。MCP不是Anthropic一家的玩具了,它变成了整个行业的共识。
到了2025 年 11 月,MCP协议新版本发布,规范更清晰,性能更好,还引入了 Streamable HTTP这种更适合云原生的传输方式。
到2026 年初,公开数据显示,全网已经有超过 10000 个公共MCP server 在跑。
一年半。10000 个。
你敢信???
这个速度,放在传统软件行业是不可想象的。
我顺便聊一个我自己的小观察。
我这一年半装过的MCP,少说也有十几个。学术类的,爬论文的,浏览器自动化的,画图的,代码分析的,文件管理的,飞书协作的,Zotero 文献管理的。
最夸张的时候,我的 Claude Code同时挂着9 个MCP。
跟朋友吹牛的时候,我说,我现在打开 Claude Code,它不是一个聊天框。它是一个工作室。
9 个助手,9 种技能,随时待命。
这种感觉,是 Function Calling时代完全给不了的。
· · ·
顺着这个,我再聊一个我看到的隐性变化。
这一年,AI 从业者的工作流,正在被 MCP重新组织。
在MCP出来之前,一个 AI 产品经理想做个能联网的 AI 助手,他得做这些事。找个能联网的方案,可能要用 LangChain,可能要自己写代码。接 LLM。调 API 试。踩一堆坑。搞两周,能跑。
在MCP之后,他只需要。找个合适的 MCP server,比如浏览器 MCP。装上。跑。
两周变成 5 分钟。
这背后是整个行业的范式转移。
AI 应用开发的门槛,从「写代码调 API」,变成了「挑 MCP装MCP」。
这是从工程师红利,到产品经理红利的迁移。
· · ·
两个我比较担心的点
回到MCP本身,我想再讲两个我比较担心的点。
第一个,是安全问题。
MCP server 是本地进程,每个 server 都有一定的权限。它能读你的文件,能执行你的命令,能访问你的浏览器,能改你的数据库。
如果你装了一个不太靠谱的MCP,它能干的事,可比一个网页大多了。
我自己的建议是,不熟的 MCP不装。来历不明的 server,果断 skip。装之前,先看一眼它的代码,它的 issue,它最近的更新频率。
这点跟早期装浏览器插件有点像。为了方便啥都装,最后被一个恶意插件偷了密码,这种事不少见。
MCP比浏览器插件更狠。它能干的事更多。
更深一层的问题,是 StdioMCP跟用户进程同权限,没有沙箱。
你装了一个文件读取MCP,它能读你电脑上任何文件。
你装了一个 shell MCP,它能执行任意命令。
如果这个MCP被供应链投毒了,作者更新了一个版本偷偷加了后门,你的电脑可能就裸奔了。
想想就后背发凉。。。
2026 年的MCP Roadmap里,重点之一就是引入细粒度的权限系统和沙箱隔离,让用户能告诉某个 MCP「你只能读这个目录」「你只能执行这个白名单的命令」。
但这个标准还在路上。
短期内,装 MCP这件事,还是要靠用户自己长点眼睛。
· · ·
第二个,是生态碎片的问题。
10000 个 server,是好事,也是坏事。
好事是供给丰富。坏事是选择困难。
同一个功能,比如浏览器自动化,可能有 5 个不同的MCP server,每个实现的细节都不一样。调一个用着用着发现 bug,换另一个又得重新理解 API。
这事Anthropic也看到了。2026 年的MCP Roadmap里,重点之一就是统一标准、减少碎片化。Anthropic推出了「MCP Verified」机制,官方背书一批高质量的 server,相当于给生态一个推荐列表。
但这事需要时间。短期内,可能还是得靠我们自己来踩坑。
· · ·
说到踩坑,我突然想起来一个事。
前几天,我跟一个程序员朋友聊天,他说他最近在重构他的 AI 工作流。
我说你重构啥。
他说他把原来散落在5 个 SaaS 工具里的活,迁到了一个 Claude Code加6 个 MCP里。省了两个账号,一年下来大概省了 6000 块。更重要的是,省了「切换工具」的时间。
听他讲完,我就笑。
这不就是十年前,智能手机把所有功能机功能都吞掉的故事,再来一遍嘛。
· · ·
最后聊两句
写到这里,我突然想再回到最开始那个问题。
MCP是个啥。
讲到这里,你应该大概有数了。
但我想再补一刀。
MCP最大的价值,不是它解决了什么具体的技术问题。是它把「AI 能接什么工具」这件事,从「每个团队自己想办法」,变成了「整个行业一起建设」。
它真正干的事,是一次 AI 基础设施的标准化。
这件事在历史上的对标,我觉得是 1990 年代的 HTTP。或者更准确一点,是 2000 年代 Linux 桌面环境里,PulseAudio干的事。把碎片化的音频接口,统一成一层可以随便替换的抽象。
MCP干的是同一件事,只不过抽象的层级更高了一层。
抽象的层级越高,下面被替代的岗位就越多。
这是个残酷的事实,但也是行业往前走的现实。
· · ·
最后我想说一句,可能听起来有点冒犯。
如果你是一个 AI 从业者,最近一年还在坚持「Function Calling是未来」,或者「每个公司应该有自己的一套私有协议」。
我劝你早点换换思路。
MCP已经是事实标准了。
不是Anthropic强推的标准。是OpenAI也接、Google也接、Meta也接、DeepSeek也接,全行业一起投票投出来的标准。
这种情况下,自己另搞一套,不是技术自信,是技术傲慢。
· · ·
写到最后,突然想起了一句话。
是Anthropic的Dario去年接受采访时说的。大意是,他们做 MCP,从来不是想再造一个围城,而是想造一座桥。
桥这一头是 LLM,桥那一头是整个世界。桥上跑的是协议,桥上走的是 server。
这座桥还在修,但已经能过车了。而且会越修越宽。
· · ·
能做的,还是那句话。
磨平一些信息差。
MCP这个事,对很多非技术背景的人来说,可能还是个陌生的词。但对 AI 从业者来说,它已经是一个绕不开的基础设施。
跟电一样,跟网一样,跟 HTTP一样。
它不会让你兴奋。但没它你活不下去。
这就是基础设施的命。
我们,下次再见。
如果您对赛博时代启示录技术交流群感兴趣,请在后台回复“启示录”获取进群二维码。
