 夜雨聆风
夜雨聆风数字越大越像凑数。但这个 817,拆开看是另一回事。
◇ ◇ ◇
817 这个数字,我第一反应是反感
先交代我的偏见。看到 mukul975/Anthropic-Cybersecurity-Skills 这个项目标题写着 817 个结构化安全 skill,我第一反应不是"哇好全",是"又一个凑数的"。
这几年 GitHub 上这类 repo 我见太多了。标题里塞个吓人的数字——500 个 prompt、1000 个 agent、200 个 MCP——点进去一看,大半是把同一件事换个说法重写了十遍。数字是 KPI,不是能力。
而且这名字有坑。它叫 Anthropic-Cybersecurity-Skills,但跟 Anthropic 这家公司一点关系没有。作者自己在 README 里写了:"独立社区项目,与 Anthropic PBC 无关。"蹭个名字冲星,21.2k star 里有多少是被名字骗进来的,不好说。
带着这股劲儿,我点进去想看它怎么凑的。然后我没笑出来。
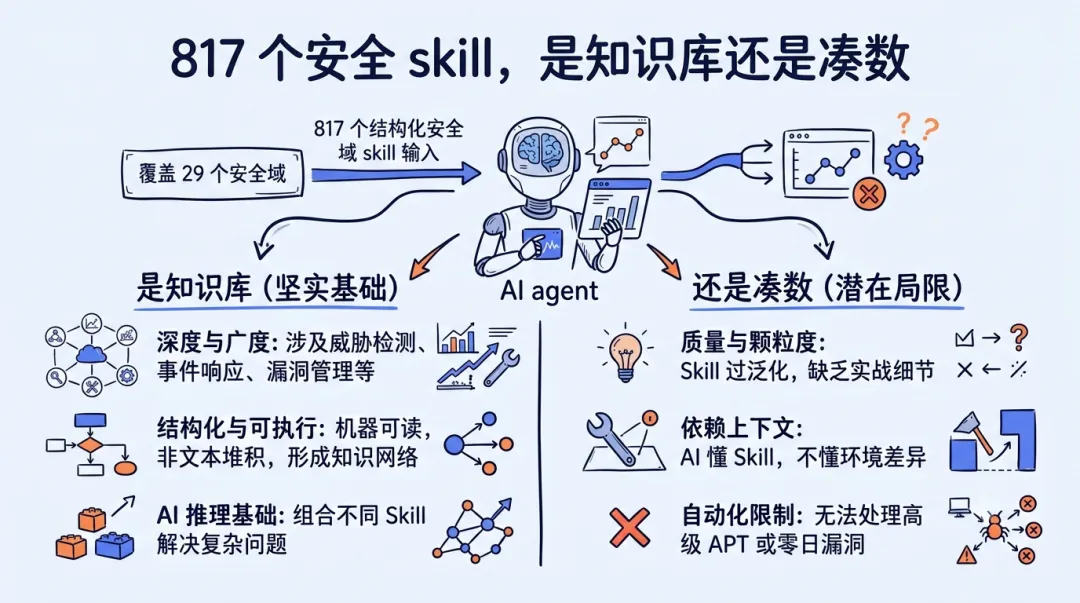
817 个安全 skill,是知识库还是凑数
◇ ◇ ◇
它解决的是一个我真遇到过的问题
讲个我自己的事。我让 Claude Code 帮我分析过一个内存 dump,想看有没有凭证窃取的痕迹。它的反应是——开始猜。猜 volatility 的命令参数,猜该看哪个 plugin,有一半是错的,我得一条条纠。
这个项目 README 里有句话,正好戳到这:
没有这些 skill,agent 在瞎猜工具命令。有了它们,agent 按一个资深 DFIR 分析师的 playbook 来做。
它不是给你一堆脚本,是给 agent 一套结构化的领域知识。拿那个内存取证的 skill 举例,真实文件叫 performing-memory-forensics-with-volatility3,frontmatter 长这样:
name: performing-memory-forensics-with-volatility3 tags: [forensics, memory-analysis, volatility3, dfir] atlas_techniques: [AML.T0047] d3fend_techniques: [D3-MA, D3-PSMD] nist_csf: [DE.CM-01, RS.AN-03]
每个 skill 是一个目录:SKILL.md 写什么时候用、前置条件、一步步的 workflow、怎么验证结果,references 里放框架映射和技术细节,scripts 放辅助脚本。这不是把命令换十种说法,是把"一个老手会怎么干这件事"写成了机器能读的结构。
我那个内存 dump 的活儿,如果 agent 手里有这个,它不会再猜——它会去跑对的 volatility3 plugin,检查 LSASS 的模式,关联 Windows 事件日志,最后把发现映射到 ATT&CK 的 T1003。这是 playbook,不是瞎试。
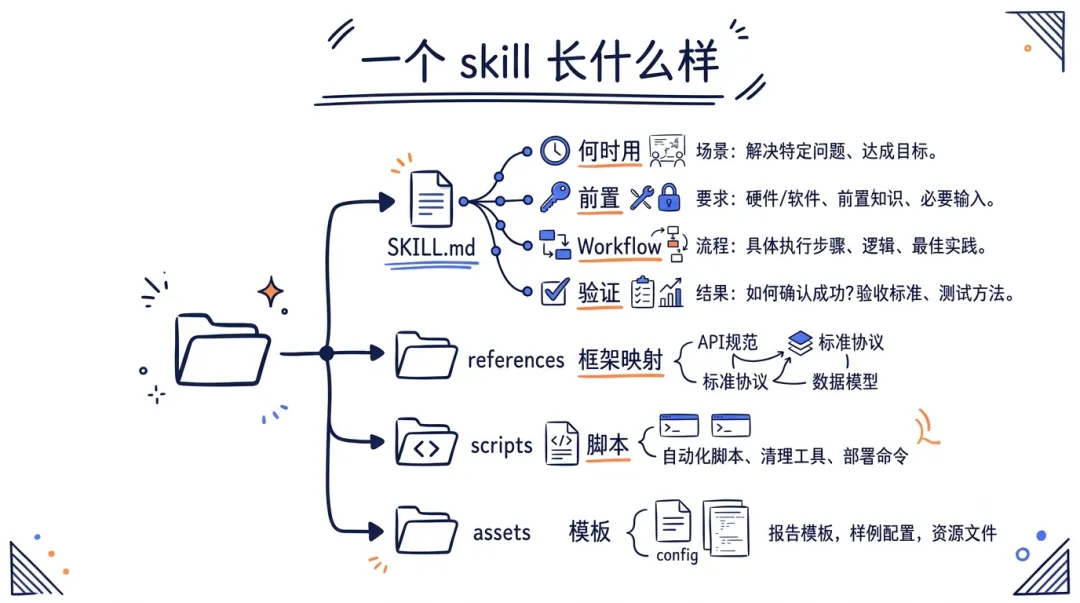
一个 skill 的目录结构:SKILL.md / references / scripts / assets
◇ ◇ ◇
真正聪明的地方是它不让 agent 一次读 817 个
817 个 skill 全塞进 context?那 token 直接爆了。这也是我一开始觉得它蠢的点。
结果它用了 progressive disclosure,分四步:
扫描——每个 skill 的 frontmatter 只占约 30 token,agent 先扫一遍 817 个标题和 tag,找匹配的;
加载——只把最相关的 top 3-5 个完整 workflow 拉进来,每个 500-2000 token;
执行——按 workflow 一步步跑命令;
验证——拿 skill 里的 verification 标准核对结果。
算笔账:扫描阶段 817 × 30 token,再加载 3-5 个详细的。这比把全部内容堆进 context 省了一个数量级。它不是让 agent 背下 817 个 skill,是让 agent 学会按需查阅。
这一步我得给分。它说明作者真在乎 agent 实际怎么用,不只是堆数量。
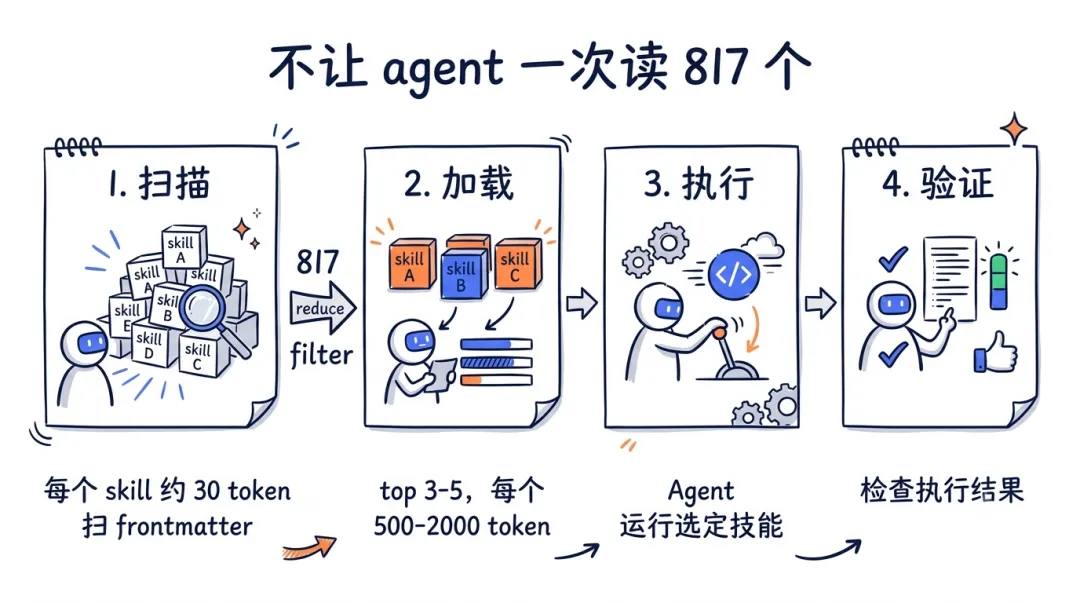
progressive disclosure:扫描→加载→执行→验证
◇ ◇ ◇
然后说说我没法忽略的那几个问题
夸完了,泼冷水。
第一,双用性。这 817 个 skill 里,红队 33 个、渗透测试、还有 467 个映射到 MITRE ATT&CK 的"初始访问"。这些东西防守方能用,进攻方一样能用。README 里 D3FEND 那套防御映射做得挺足,但我翻下来,没看到一句正经的法律免责声明。一个把攻击 TTP 结构化喂给任意 agent 的库,这个口子开得有点随意。
第二,六框架映射听着唬人,得打问号。MITRE ATT&CK v19.1、NIST CSF 2.0、ATLAS、D3FEND、NIST AI RMF,还有 4 月才发布的 MITRE F3 反欺诈框架——每个 skill 都号称映射到这六个。问题是,817 × 6 个映射,谁来保证每一条都映射对了?这种规模的标注,人工核不过来,大概率有相当比例是模型批量生成的。映射错的安全知识,比没有更危险。
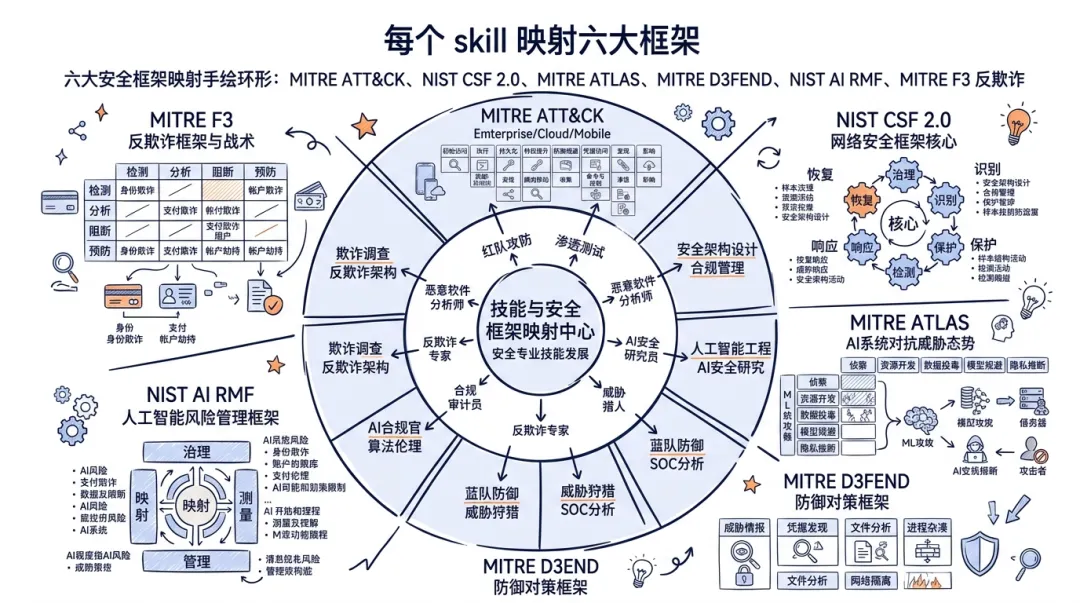
每个 skill 映射六大框架:ATT&CK / NIST CSF / ATLAS / D3FEND / AI RMF / F3
第三,数字还是数字。817 比 762 多了 55 个(这是 6 月 22 号 v1.3 干的),但"多 55 个 skill"不等于"多 55 份能力"。29 个域里云安全 66 个、威胁狩猎 58 个,密度是真高,可有多少是核心、多少是边角料,光看数字看不出来。
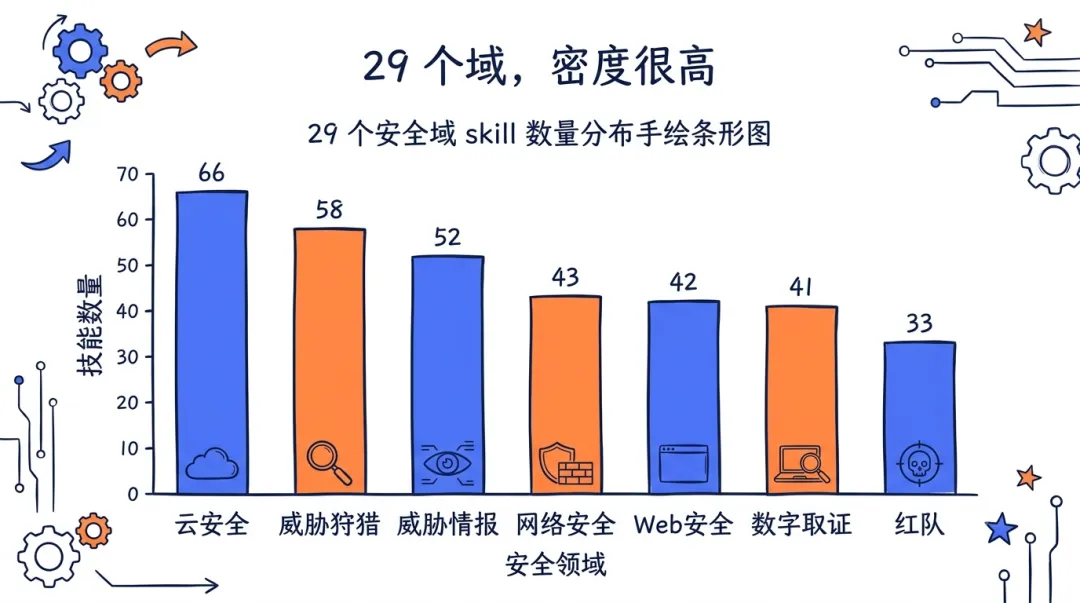
29 个安全域的 skill 数量分布
◇ ◇ ◇
我的判断:当索引,别当圣经
那这玩意到底用不用?
我的用法会是——把它当一个结构化的索引和起点,不当不容置疑的标准答案。
它最大的价值,是把零散的安全知识整理成了 agent 能按需检索的形状,progressive disclosure 这套设计是真有用。在一个有人盯着、做防御分析的场景里,它能让你的 agent 少瞎猜很多。这是实打实的。
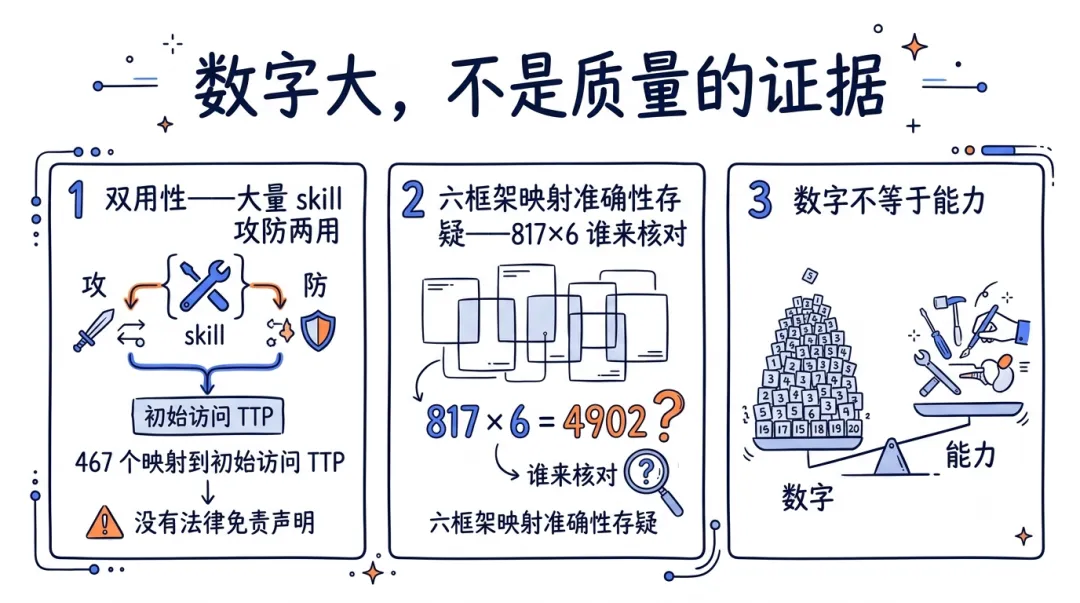
数字大,不是质量的证据
但你得清楚:它是社区项目,作者一个人(Mahipal Jangra),Apache 2.0,六框架映射的准确性没有第三方背书,双用风险也没人替你兜。agent 跑出来的每一步,你都得自己复核,尤其是它引用的命令和框架编号。
说到底,网络安全人才缺口 480 万(ISC2 的数,README 引的),这种结构化知识库确实是在试着补这个口子。方向我认。但"AI 按 playbook 干活"和"AI 把 playbook 干对",中间还隔着一整个验证环节——而这个环节,目前只能是人。
写到这我自己都有点怀疑是不是太苛刻了。一个免费开源、一个人维护、能做到这个结构化程度的项目,已经比大多数"凑数 repo"强太多。我那点最初的反感,收回。
只是别因为它叫 Anthropic、因为它有 817 个 skill,就放下警惕。数字大,从来不是质量的证据。
配图由 AI 辅助生成 · 内容为个人观察
