 夜雨聆风
夜雨聆风本篇章节目录:
MCP 是什么 MCP 解决的问题:别重复造轮子 MCP 出现的背景 MCP 是怎么工作的 接入现成的 MCP Server 构建自己的 MCP Server CLI 会取代 MCP 吗 MCP 和 Skill 的区别 结语
AI 很聪明,但默认接不上你的真实工作环境。
你问“我今天下午有哪些会议”,它不知道; 你说“查一下公司数据库里这个客户最近的订单”,它查不了; 你让它“给客户王经理发邮件”,它也做不到。
原因不复杂:模型学到的,是训练时就已经收集好的数据。训练结束后,它不会自动同步你的日历、公司数据库、本地文件,也不会天然拥有这些系统的访问权限。
所以问题不只是“AI 会不会回答”,而是:当 AI 需要读取外部数据、调用工具、执行操作时,能不能用一种受控、标准的方式接入真实工作环境。
MCP 要解决的,就是这个连接问题。
1 · MCP 是什么
MCP(Model Context Protocol,模型上下文协议)是一个让 AI 应用以统一方式连接外部工具和数据源的开源标准。
官网用了一个很形象的比喻:
MCP 就像 AI 应用的 USB-C 接口。
USB-C 把连接方式统一了。手机、电脑、显示器、电源,不用各自设计一套接口。
如果你用过 IDEA、VS Code 这类 IDE,还可以把它类比成 LSP。
LSP 出现前,编辑器和编程语言之间也是 M × N:VS Code 要支持 Python、Go、Rust,各写一套;JetBrains、Vim、Emacs 又各自再做一遍。
LSP 把“编辑器如何理解语言”抽成标准协议:语言方实现 language server,编辑器方实现 client,补全、跳转、诊断这些能力就能跨编辑器复用。
MCP 也是这个思路:把“AI 应用怎么连接外部工具和数据源”变成一套标准协议。
这样,AI 应用和外部系统之间,就有了一套共同的连接方式。
2 · MCP 解决的问题:别重复造轮子
没有统一标准时,AI 应用接外部工具,很容易变成一堆重复对接。
一个 AI 应用想接日历,要写一套;想接 Notion,再写一套;想接数据库,又是一套。换成另一个 AI 应用,这些连接往往还要重新适配。
这就是典型的 M × N 问题:
M 个 AI 应用; N 个外部工具和数据源; 每个应用都要和每个工具单独对接。
MCP 想把它变成 M + N:
AI 应用支持 MCP; 工具和数据源提供 MCP Server; 两边按同一套协议通信。
这样,新增一个工具或一个 AI 应用,都只是 +1,双方不用从头互相适配。
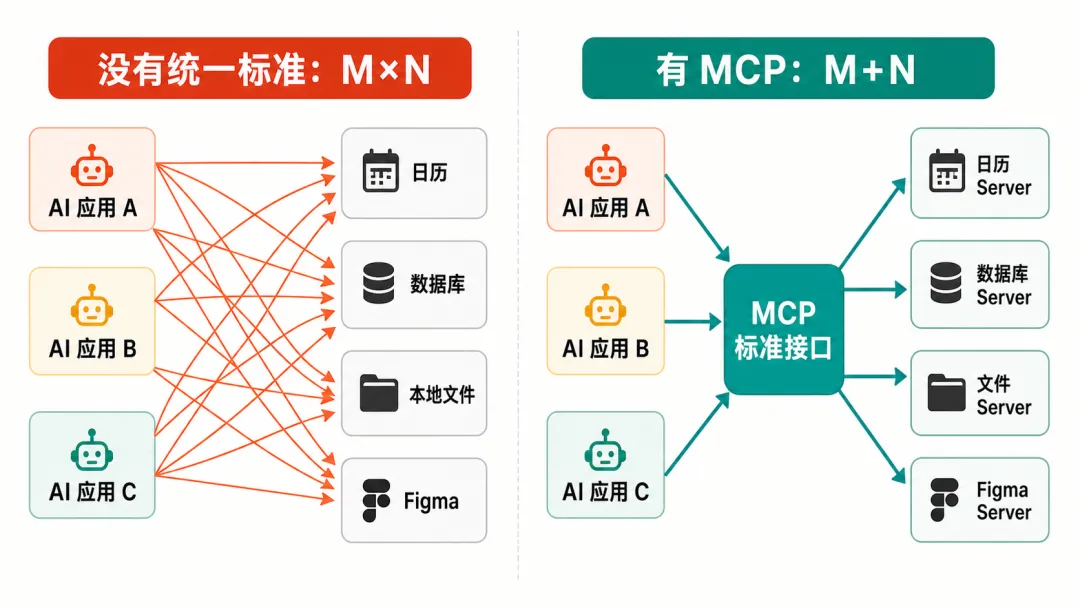
落到实际场景,大概是这样:个人 AI 助手接上你的日历和邮箱,就能帮你安排会议、起草回复;编程工具(像 Claude Code、Codex)接上 Figma 这类设计工具,就能照着设计稿生成网页;企业的对话机器人接上飞书,员工一句话就能总结群聊、查文档。
MCP 不替代日历、邮箱、设计工具或飞书。它做的是把它们的能力整理成 AI 应用能发现、能调用的形式:能读什么、能做什么、需要哪些参数、返回什么结果。
有了这层标准,AI 才能在授权范围内调用工具,而不只是回答问题。
3 · MCP 出现的背景
MCP 出现之前,模型会回答、会推理,但默认拿不到业务系统里的实时和私有数据,也不能直接调用外部工具。
这背后有两个限制。
第一,知识有截止时间。模型训练完成后,参数里的知识基本定型。今天的新闻、公司刚更新的订单、你临时加的会议,不会自动进到模型里。
第二,模型默认访问不了外部系统。它可以告诉你怎么查数据库、怎么处理 GitHub issue,但没有对应的工具和授权,它拿不到数据库记录,也改不了 GitHub 里的内容。
解决这两个问题,大体有两条路。
一条是继续把模型做强:更多训练数据、更强推理能力、更大的上下文窗口。但这条路有边界:训练数据总是来自过去,模型参数里也不会凭空装着你的私有数据。
另一条是从外部补能力。
RAG 和 Function Calling 是两种典型做法。
RAG:先从文档、知识库、数据库里检索资料,再交给模型回答。 Function Calling:让模型按结构化参数生成一次函数调用,再由应用执行对应函数,比如查天气、发邮件、查订单。
RAG 解决的是“先取资料再回答”;Function Calling 解决的是“按结构化参数调用外部能力”。MCP 更接近后者,但它想统一的不只是函数调用,而是 AI 应用连接外部工具和数据源的整套方式。
2023 年之后,各家都开始做工具调用和插件机制,但每个平台一套接法、每个应用一套工具描述格式。同一个工具想给不同客户端用,仍要反复适配。
MCP 要补的,就是这套可复用的标准。
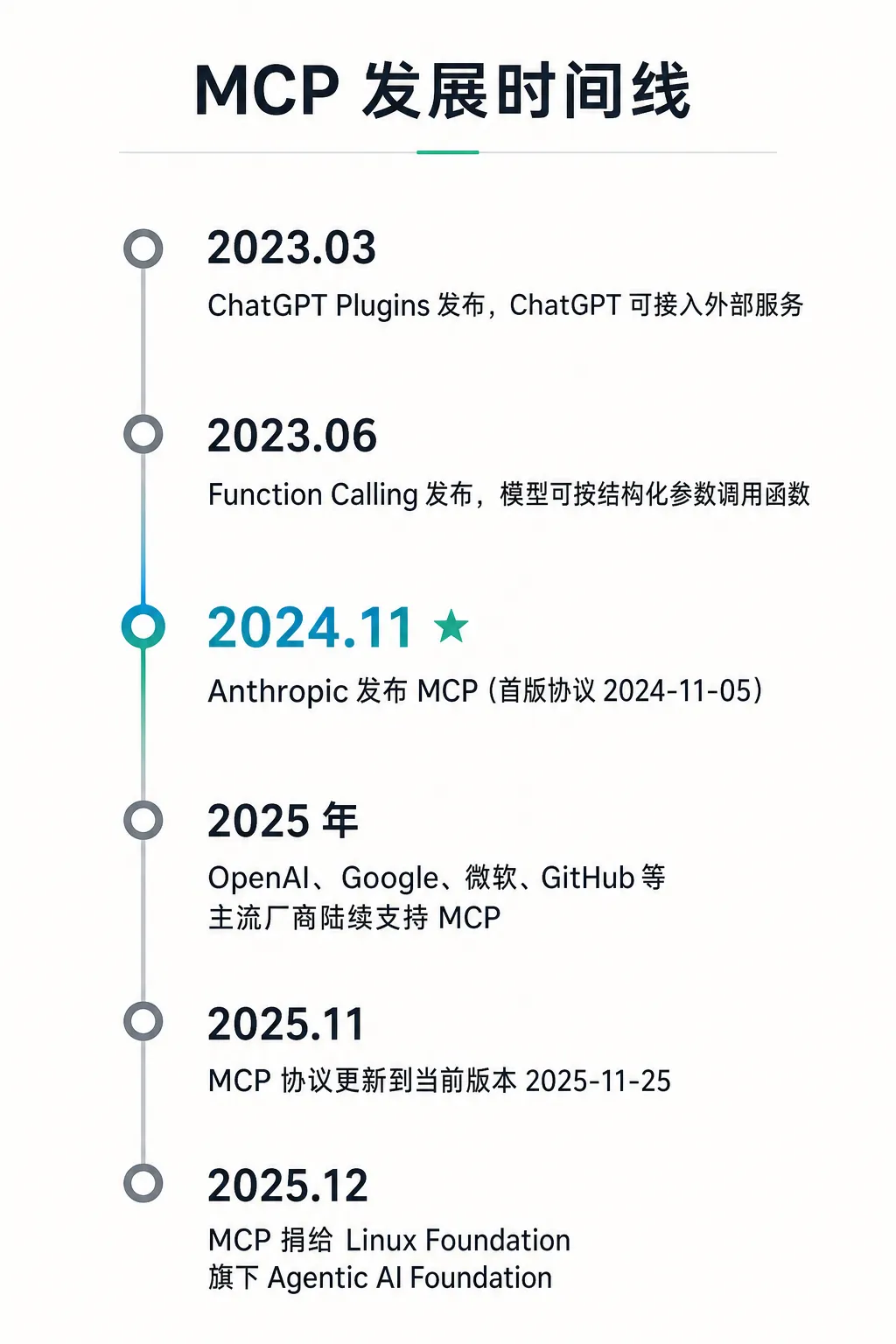
2024 年 11 月,Anthropic 发布 MCP,把“AI 应用怎么连接外部工具和数据源”抽成开放协议。
到 2025 年,OpenAI、Google、微软、GitHub 等厂商陆续支持,MCP 也逐渐从 Anthropic 的项目变成更中立的行业标准。
2025 年 12 月,Linux Foundation 成立 Agentic AI Foundation,三个创始项目分别是 Anthropic 的 MCP、Block 的 goose、OpenAI 的 AGENTS.md,背后还有 Google、微软、AWS 等支持。
据这次公告,公开的 MCP Server 已超过 1 万个,官方 SDK(Python、TypeScript)月下载量超过 9700 万次。这也是目前官方给出的最新数据。
MCP 能成为行业共识,是因为大家都撞上了同一个问题:AI 应用越来越多,外部工具也越来越多,继续各接各的,集成成本会越来越高。AI 要进入真实工作流,需要一套大家都能复用的协议。
4 · MCP 是怎么工作的
MCP 的结构不复杂:用户使用的是 AI 应用,AI 应用里的 Client 连接 MCP Server,Server 提供工具和数据源,中间按 MCP 协议通信。
先看三个角色。
| Host | ||
| Client | ||
| Server |

一个 Host 可以连接多个 Server,但不是一个 Client 管所有连接。更准确地说,Host 会为每个 Server 单独创建一个 Client。
比如 Claude Desktop 同时连接文件系统、GitHub、日历三个 Server,它内部就会有三个 Client,分别维护这三条连接。
Server 也不一定在云端。本地文件系统 Server,可能只是你电脑上被客户端拉起的一个子进程;GitHub 这类 Server,通常是远程 HTTP 服务。MCP 里的 Server,指的是“提供工具和数据源的一方”,不是“云服务器”。
Server 提供什么
MCP Server 对外暴露的核心能力,官方叫 primitives(可以理解成“基础能力”)。名字不用纠结,记住三类就够了:Tools、Resources、Prompts。
Tools:可调用的动作。
Tool 可以理解成 MCP Server 暴露给 AI 应用的一个“操作入口”:它背后可以是一项很小的查询,也可以是一段完整的业务能力。
比如天气 Server 里,“查询当前天气”就是一个 tool;GitHub Server 里,“创建 issue”、“查询 PR”也可以是 tool;数据库 Server 里,“查询订单数量”也可以是 tool。
这里的 tool 不是一个完整的软件,也不是 MCP 客户端。它更像一个标准化的函数:有名字、有说明、有参数、有返回。
比如一个天气 Server 可以提供一个 tool:
名字: weather_current说明:查询某地当前天气 参数: location、units返回:天气结果
模型看到这些信息,才知道这个 tool 能做什么、什么时候该调用、调用时要传哪些参数。真正执行前,客户端通常还会让用户确认。
Resources:可读取的资料。
Resources 是 MCP Server 暴露出来的可读取上下文,比如文件内容、数据库表结构、日历记录。它负责“读”;要执行修改,通常走 Tools。
Prompts:可复用的任务模板。
Prompts 是 Server 预设好的任务模板,用来把某类常见任务包装成可选入口。它不会被模型自动触发,通常需要用户主动选用。
除了这三类 Server 能力,MCP 还有一些客户端侧能力,比如 Sampling、Elicitation、Roots、Logging。这里先不展开。理解主线时,抓住 Tools、Resources、Prompts 就够了。
一次工具调用流程
MCP 的消息格式基于 JSON-RPC 2.0。它是一套公开的通信规范,MCP 用它来组织请求和返回结果。
传输方式主要有两种:
| stdio | ||
| Streamable HTTP |
SSE 不是第三种传输。当前协议里,远程传输叫 Streamable HTTP;SSE 只是它可以使用的一种流式返回方式。旧版协议里的 HTTP+SSE 已经被 Streamable HTTP 取代。
它和普通 API 也不一样。
普通 API 通常是程序员读文档、写代码、固定调用。MCP 面向的是 AI 助手的工作过程:Client 可以先问 Server“你有哪些工具”,拿到工具名、说明和参数 schema,再由模型根据任务判断要不要调用。
所以 MCP 不是简单的“API 包装层”。一个 tool 背后可能是一个 API,也可能编排了多个 API,还可能是读本地文件、跑脚本、查数据库。
一次工具调用,大致是这样:
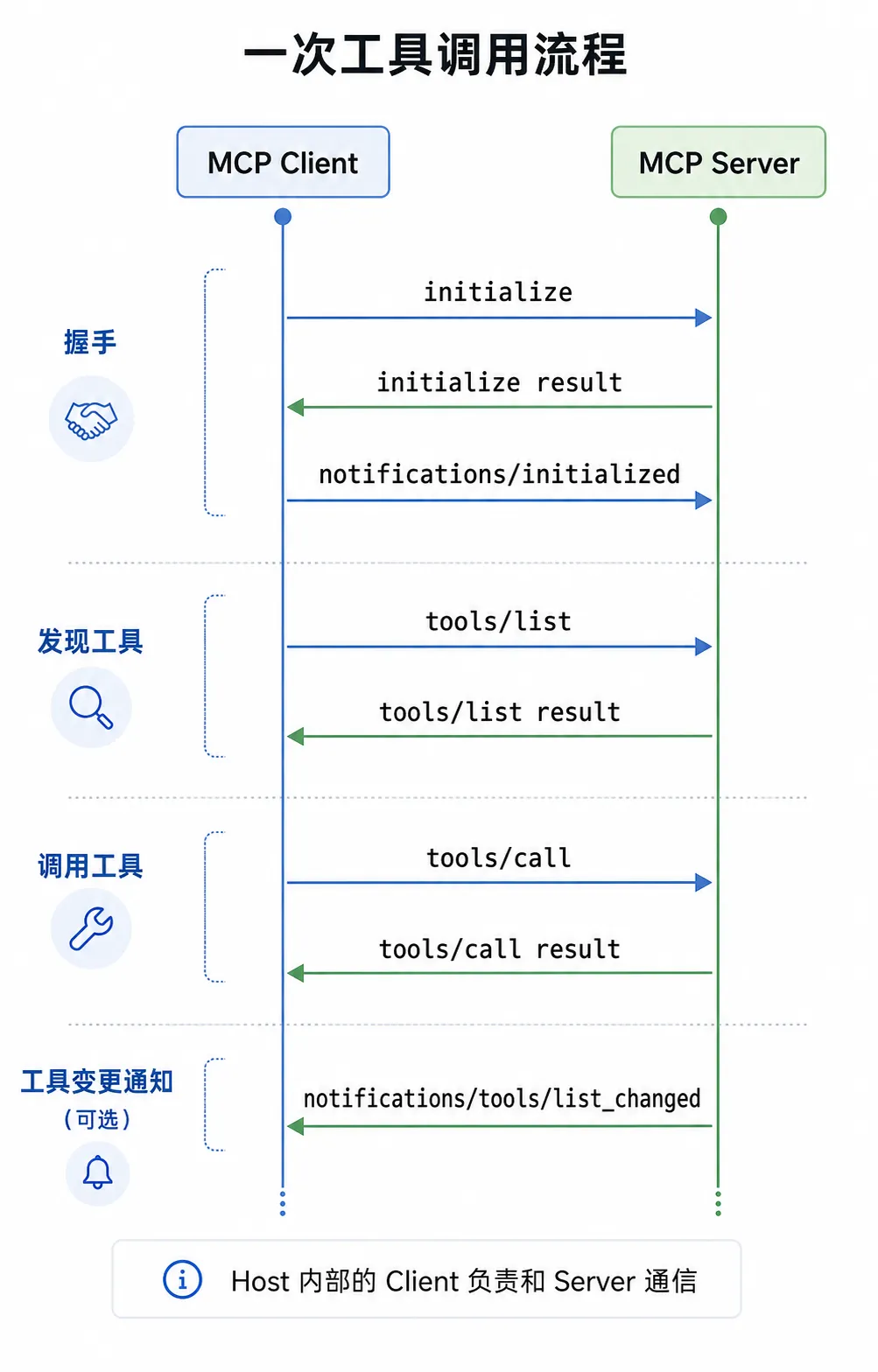
第一步,握手。Client 发送 initialize,和 Server 协商协议版本(当前是 2025-11-25)与双方能力。握手完成后,再发 notifications/initialized 表示准备就绪。
第二步,发现工具。Client 发送 tools/list,Server 返回可用工具列表,包括工具名、说明和参数 schema。
第三步,调用工具。比如用户问“北京现在天气怎么样”,模型判断需要天气工具,Host 就通过对应的 Client 发起 tools/call:
{"jsonrpc": "2.0","id": 3,"method": "tools/call","params": {"name": "weather_current","arguments": {"location": "Beijing","units": "metric"}}}Server 执行后返回结果:
{"jsonrpc": "2.0","id": 3,"result": {"content": [{"type": "text","text": "Current weather in Beijing: 20°C, partly cloudy..."}]}}Host 把结果交回模型,模型再基于真实结果回答用户。
如果 Server 的工具列表发生变化,并且声明支持变更通知,它可以发送 notifications/tools/list_changed。Client 收到后,再重新 tools/list 刷新列表。
也就是说,MCP 是先发现能力,再按结构化参数调用,最后把结果交回模型。
安全与权限
MCP 让 AI 能连数据库、文件、GitHub,但它不等于“接上就安全”。安全边界主要靠协议、Server、客户端和用户配置一起控制。
远程 MCP Server 通常走 Streamable HTTP。需要访问受保护资源时,MCP 的标准授权机制基于 OAuth 2.1:Client 代表用户完成授权,拿到 access token 后访问受保护的 Server。
本地 stdio Server 不走这套 OAuth 授权流程,通常从环境变量读取凭据,比如 API key。
官方安全原则里,用户知情和控制权排在第一位:调用工具前、向 Server 暴露用户数据前,Host 都应该让用户明确知情并同意。但 MCP 协议本身不能强制这一点,最终还是看客户端怎么实现。客户端可以展示工具、要求单次确认、允许预批准低风险操作,也可以记录工具调用日志。
5 · 接入现成的 MCP Server
用 MCP,不一定要自己写 Server。很多 Server 已经有人写好了,你要做的是把它接到支持 MCP 的 AI 应用里。
先分两类:本地 Server 和远程 Server。
本地 Server:跑在你电脑上
本地 MCP Server 是你电脑上的一个程序。官方教程用 filesystem Server 举例:它把读目录、读写文件、移动文件、搜索文件这些能力,通过 MCP 暴露给 AI 应用。
你可能会问:有些 AI 应用本来就能操作本地文件,为什么还要 filesystem Server?
关键是标准化。filesystem Server 把文件访问封装成 MCP 工具,任何支持 MCP 的客户端都能用同一套方式接入;开放哪些目录、执行前要不要确认,也能统一管理。
以 Claude Desktop 为例,打开:
Settings → Developer → Edit Config配置文件默认位置是:
macOS:~/Library/Application Support/Claude/claude_desktop_config.jsonWindows:%APPDATA%\Claude\claude_desktop_config.json写入类似这样的配置:
{"mcpServers": {"filesystem": {"command": "npx","args": ["-y","@modelcontextprotocol/server-filesystem","/Users/username/Desktop","/Users/username/Downloads"]}}}这段配置的意思是:Claude Desktop 启动时,用 npx 拉起 @modelcontextprotocol/server-filesystem,并只允许它访问桌面和下载目录。
filesystem Server 的访问范围,由 args 里的目录路径决定。不要一上来就填 /Users/username 这类整个 home 目录,先给一个测试目录。
注意,本地 Server 以你的用户权限运行。你能手动操作的文件,它理论上也能操作,所以目录范围要收窄。
保存后,完全退出并重启 Claude Desktop。然后可以试:
帮我看看 Downloads 里有哪些 PDF。把桌面上的图片整理到一个新文件夹里。执行文件操作前,Claude Desktop 通常会请求你确认。
远程 Server:跑在网上
远程 MCP Server 不装在你电脑上,而是由服务方托管。项目管理工具、文档系统、代码仓库、监控平台,都可以提供远程 MCP Server。
以 Claude 网页端为例,官方教程用的是 Custom Connectors:
Settings → Connectors → Add custom connector然后填入远程 MCP Server 的 URL。这个 URL 通常由 Server 开发者或管理员提供,应该是完整的 https:// 地址。
接下来一般会进入认证流程,可能是 OAuth,也可能是 API key,取决于 Server 怎么实现。认证完成后,这个 Server 提供的资源、提示模板和工具,就可以出现在 Claude 会话里。你也可以在 connector 设置里控制哪些工具允许使用。
简单区分一下:
本地 Server:跑在你的电脑上,常用来访问本地文件、脚本、数据库。远程 Server:跑在服务方那里,常用来连接 SaaS、企业系统、云端数据。去哪里找 MCP Server
优先看官方来源。
想找现成 MCP Server,先看 Registry;想学怎么写,再看 GitHub 仓库;想看更多生态,再看社区目录。
MCP Registry
目前还是 preview。它是官方用来发布和查找已发布 MCP Server 信息的入口。
地址:https://registry.modelcontextprotocol.io/
官方 GitHub 仓库
这个仓库不是用来“找 Server”的市场,而是官方维护的参考实现集合。它更适合开发者看示例:Server 怎么启动、怎么配置到客户端、Tools / Resources / Prompts 可以怎么写。
地址:https://github.com/modelcontextprotocol/servers
社区目录
社区目录适合看看生态里有什么,但不等于官方背书。
mcp.so:https://mcp.so/ Smithery:https://smithery.ai/ MCP Market:https://mcpmarket.com/zh
接入前检查三件事
第一,看权限。尤其是本地 Server,先确认它能访问哪些目录、系统能力或外部账号。
第二,看凭据。需要 API key 的 Server,不要把 key 写进文章、截图或公开仓库;配置文件本身也要注意权限和备份范围。
第三,看来源。社区目录不等于官方背书。接公司数据库、代码仓库、客户系统这类敏感资源时,要确认维护者、权限范围、审计能力和团队规范。
6 · 构建自己的 MCP Server
这一章偏开发者。如果你只是想用 MCP,不打算自己写 Server,可以直接跳到下一章。
什么时候需要自己写?通常是这两种情况:
你要把内部 API、数据库查询、业务流程包装出来; 你希望同一套能力被多个 AI 客户端复用。
MCP Server 做的事,可以简单理解成一句话:
把已有能力,包装成 Tools / Resources / Prompts。多数时候,开发者最先写的是 Tools,也就是可调用的动作。
官方 build-server 教程用的是一个天气 Server。它提供两个工具:
get_alerts:查询美国某个州的天气警报;get_forecast:根据经纬度查询天气预报。
最小代码长什么样
MCP Server 不限定语言。MCP 是协议,不是某个语言框架;只要按协议通信,任何语言都能实现 MCP Server。
官方提供了 TypeScript、Python、C#、Go、Java、Rust、Swift、Ruby、PHP、Kotlin 等语言的 SDK。SDK 是按语言提供的,用对应 SDK 会省掉很多协议细节。
这一章用 Python,是因为官方 build-server 教程也用 Python,代码短,便于看清 MCP Server 的基本结构。核心是 FastMCP 和 @mcp.tool()。完整项目初始化可以看官网,这里只看代码骨架。
from mcp.server.fastmcp import FastMCPmcp = FastMCP("weather")@mcp.tool()async def get_alerts(state: str) -> str:"""Get weather alerts for a US state."""# 这里写查询 NWS API 的业务逻辑 ...@mcp.tool()async def get_forecast(latitude: float, longitude: float) -> str:"""Get weather forecast for a location."""# 这里写根据经纬度查询天气预报的业务逻辑 ...if __name__ == "__main__": mcp.run(transport="stdio")关键就几处:
FastMCP("weather"):创建一个 MCP Server;@mcp.tool():把普通 Python 函数注册成 MCP tool;函数参数和 docstring:会被 SDK 用来生成工具说明和参数 schema; mcp.run(transport="stdio"):用 stdio 方式运行,适合本地客户端拉起。
协议细节交给 SDK,你主要写业务函数。
接到 Claude Desktop 测试
通过 uv run weather.py 启动刚才写的 MCP Server。
接入 Claude Desktop,配置:
{"mcpServers": {"weather": {"command": "uv","args": ["--directory","/ABSOLUTE/PATH/TO/PARENT/FOLDER/weather","run","weather.py"]}}}/ABSOLUTE/PATH/TO/PARENT/FOLDER/weather 换成你的项目绝对路径。
保存配置后,重启 Claude Desktop。连接成功后,Claude 就能看到 get_alerts 和 get_forecast 两个工具。可以问:
CA 现在有哪些天气警报?37.7749, -122.4194 这个坐标的天气预报是什么?stdio 的坑:日志别写 stdout
如果 Server 用 stdio 传输,stdout 是 JSON-RPC 协议通道。随手写一行:
print("server started")就可能污染协议消息,导致客户端解析失败。
日志写到 stderr:
import sysprint("server started", file=sys.stderr)或者用 logging 写到 stderr / 文件。HTTP 传输的 Server 没这个问题。
业务里怎么拆工具
天气 demo 只是例子。实际业务里,你可以把这些能力包装成 MCP tool:
查询公司订单; 读取内部知识库; 创建工单; 生成报表。
什么时候适合把一个能力做成 MCP tool?
看它是不是需要被 AI 应用稳定调用,或者被多个客户端复用。
比如查询订单、创建工单、读取知识库、生成报表,都可以做成一个个 tool。AI 应用需要知道这个 tool 能做什么、要传什么参数、调用后会发生什么:只是查询,还是会创建、修改、发送内容。
不要把所有能力塞进一个“大而全”的 tool。更好的方式是拆成几个边界清楚的小工具。工具越清楚,模型越容易选对,用户也越容易判断它到底要做什么。
写 MCP Server,不是重写系统,而是给已有能力加一层标准接口。
7 · CLI 会取代 MCP 吗
CLI 是 Command Line Interface,也就是命令行接口。很多工具本来就带 CLI,比如 git、gh、ffmpeg。
MCP 一度被很多人看作 Agent 接工具的标准方式:工具做成 Server,AI 应用按统一协议调用。但到 2025 年底、2026 年初,越来越多开发者又开始重新看向 CLI。
2026 年 3 月,Agent-Engineering.dev 有文章称,Perplexity 内部正在减少 MCP 的使用,更多转向普通 API 和 CLI。文章提到的原因包括上下文开销、认证复杂度和生产环境稳定性。
这不是 Perplexity 官方公告,但它指出了一个值得重视的工程问题:MCP 不是所有场景的默认答案。
CLI 的优势
CLI 最大的优势,是少占上下文,也就是更省 token。
用 MCP 时,Server 提供哪些工具、每个工具叫什么、参数是什么、返回什么,通常都会进入大模型上下文。工具一多,这些说明本身就会占大量的 token。
有测算称,官方 GitHub MCP Server 约 90 个工具,光工具定义就要占掉大约 5 万 token。一个 20 万 token 的上下文窗口,还没开始做正事,就已经用掉两成左右。
工具定义不是唯一开销。工具之间传递的中间结果也会占 token:先用一个工具取回长文档,再交给另一个工具处理,这份文档可能会在上下文里来回出现。
CLI 没有这层固定开销。Agent 需要什么,就运行什么命令;结果太长,也可以用 grep、head、jq、管道或临时脚本先处理一遍,再把精简后的结果交给模型。
第二个优势,是执行效率高。
CLI 可以直接调用本机已有命令,不需要再经过一层 MCP Server。命令之间还能管道、拼接、批处理:
gh issue list --state open | head -20ffmpeg -i input.mp4 output.mp3CLI 也更灵活。今天按文件名筛选,明天按时间筛选,改一下命令就行。MCP 也可以把一串流程封装成一个 tool,但需求一变,tool 可能就要改。对本地、临时、开发者场景来说,CLI 往往更快、更方便。
不过,CLI 有个前提:客户端得能跑命令。
Claude Code、Codex 这类编程 Agent 可以用 shell;很多网页端、聊天型 AI 应用没有你的本地终端,也不能随便安装命令行工具。前提一变,CLI 的优势就不一定成立。
MCP 的优势
第一,跨客户端复用。
同一个 MCP Server,可以接给 Claude Code、Cursor、Codex、网页助手。客户端只要支持 MCP,就能按同一套协议接入。
第二,更可控。
CLI 给 Agent 的是一个 shell,能做的事太多;MCP 给的是一组明确的 tool。每个 tool 能做什么、要传什么参数、会返回什么结果,都可以提前写清楚。客户端也可以在真正执行前让用户确认。
第三,安全边界更清楚。
这里不是说 MCP 天然安全,而是更容易把风险收住:只暴露该暴露的 tool,限制读写范围,调用前让用户确认,必要时留下调用记录。相比让模型直接执行任意命令,这种方式更容易控制风险。
第四,复杂认证更适合放在 MCP 里。
远程 MCP Server 可以按规范走 OAuth 2.1,让每个用户自己授权,拿到各自的 access token。CLI 也能做认证,但通常依赖本机凭据、环境变量或个人 token;到了多人、多客户端、企业系统里,管理成本会变高。
第五,更适合长期运行的服务。
比如连接池、会话状态、长任务、持续运行的业务服务,都可以放在常驻 Server 里。CLI 不是完全做不到,它也可以调后台服务;只是做到这一步,CLI 往往已经不再是简单命令,而是在命令背后又藏了一套服务。
不是取代,是分工
所以,CLI 不会简单取代 MCP。
本地、个人、开发者场景里,CLI 的比重会越来越高。它省上下文、执行快、改起来灵活。
云端、企业、多客户端、强权限控制的场景里,MCP 仍然有价值。它不只是“调用一个工具”,而是把工具、数据和业务能力用一套标准接口交给 AI 应用。
两者也不是非要二选一。Anthropic 提出过“用代码调用 MCP”的做法:MCP Server 还在,但不再一次性把所有工具定义塞进模型上下文,而是把工具包装成代码接口,让 Agent 写代码、按需加载用到的工具。他们给出的例子里,某个流程的 token 从 15 万降到 2 千。
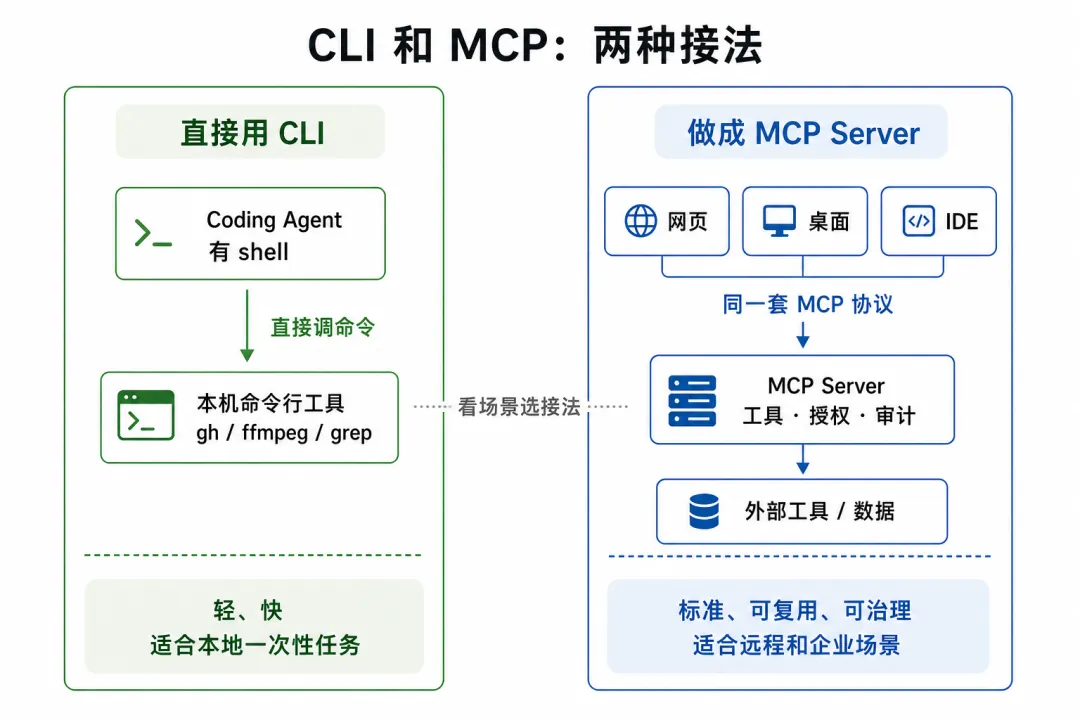
所以,与其问“CLI 会不会取代 MCP”,不如问:这个场景里,直接调 CLI 更合适,还是把能力做成 MCP Server 更合适。
8 · MCP 和 Skill 的区别
前面讲 Skill 的文章发出去后,评论区有位读者问了个很好的问题。

大意是:
MCP 和 Skill 看起来都像“能力”,是不是内部自己用就做 Skill,给外部用就做 MCP? 如果一个 MCP Server 封装的是完整订票流程,它还算不算“连接工具和数据源”?
这个问题很典型。MCP 和 Skill 确实都会增强 Agent,但分界不在“内部还是外部”,也不在“功能简单还是复杂”。
Skill 是什么
这里说的 Skill,指的是 Agent skills。
Skill 的核心,是把一类任务需要的知识、流程和工具,打包成 Agent 可以按需加载的技能包。它通常是一个文件夹,里面有 SKILL.md,再配上相关指令、脚本和资料。
Skill 的重要设计是渐进式加载:平时只暴露简短说明,等任务相关时,再读取更完整的步骤、脚本和资料。
你可以把它理解成一份任务手册。
比如:
做代码审查:看哪些文件、按什么顺序检查、输出什么格式; 处理发票:识别哪些字段、怎么校验金额、异常怎么标记; 写周报:按什么结构、从哪些资料取信息、语气怎么控制。
这些解决的不是“怎么连接外部系统”,而是“这类任务该怎么做”。
MCP 和 Skill 的区别在哪
核心区别可以这样看:
MCP 把能力变成可调用的接口;Skill 把做事方法整理成可按需加载的技能包。拿“订票”举例。
如果做成 MCP,Server 可以暴露一个 book_ticket 工具。这个工具内部可以很薄,只是转发订票 API;也可以很厚,把查班次、比价、下单、写日历、发通知整套流程跑完。只要它通过 MCP 暴露成可调用的 tool,它就是 MCP 里的能力。
如果做成 Skill,它更像一份差旅手册:出差前先查日历冲突,按公司政策选舱位,订完后通知团队。它不直接替你订票,而是告诉 Agent 怎么把这件事做对。
所以,“MCP 连接外部工具和数据源”这个说法没错,但这里的“工具”可以很宽。它不一定只是底层 API,也可以是封装好的完整业务流程。
不是二选一
真实场景里,经常是 Skill 出方法,MCP 出能力。
比如一个“差旅助手”:
Skill 负责方法:什么时候该订、订什么档、订完通知谁; MCP 负责能力:查航班、订票、查酒店、写入日历。
Skill 里也可以带脚本,但它仍然是“任务手册”的一部分:告诉 Agent 什么时候用、怎么用、结果怎么处理。
MCP 则是另一层。它把外部系统包装成标准接口,让不同客户端都能发现和调用。
该用哪个
接不上、拿不到、调不了:用 MCP。比如查数据库、读 GitHub issue、操作文件、连监控平台。 拿得到,但不知道怎么处理:用 Skill。比如代码审查流程、发票处理规范、报告模板、工单分类规则。 既要外部能力,又要固定方法:MCP + Skill 一起用。
不要把 Skill 当 MCP 的替代品。
Skill 能带脚本,也能指导 Agent 调 CLI;在本地任务里,它确实能覆盖一部分原本要靠 MCP 的场景。但 Skill 不是连接协议。它给不了远程授权机制,也没法让不同 AI 客户端复用同一个外部接口。
反过来,MCP 也不替你沉淀业务经验。它能告诉 Agent 有个 book_ticket 工具,却不知道你们公司“谁能订商务舱”的规矩。
9 · 结语
MCP 解决的是连接问题:当 AI 要进入真实工作环境,能不能用一套标准方式,接上文件、数据库、业务系统和各种工具,而不是每个应用、每个工具都重新适配一遍。
这也是判断要不要用 MCP 的关键。
如果只是本地一次性任务,CLI 可能更顺;如果是一类任务的方法论,Skill 更合适;如果你缺的是连接、复用和权限边界,MCP 才有意义。
AI 要从聊天框走进真实工作流,靠的不只是更强的模型,也需要一套能让它稳定、可控地连接外部世界的接口。
MCP 补上的,就是这层连接。
持续输出 AI 相关内容,欢迎关注本号。也欢迎在评论区交流。
