 夜雨聆风
夜雨聆风你好,我是老王。
把 PDF 丢给 AI,让它帮你总结、提炼重点,确实省事,这价值是实实在在的。
但我踩过一个坑:总结读起来很顺,可一旦追问「这句出自哪一页?这个数字是不是表格里的原文?」,它就不一定靠得住了。
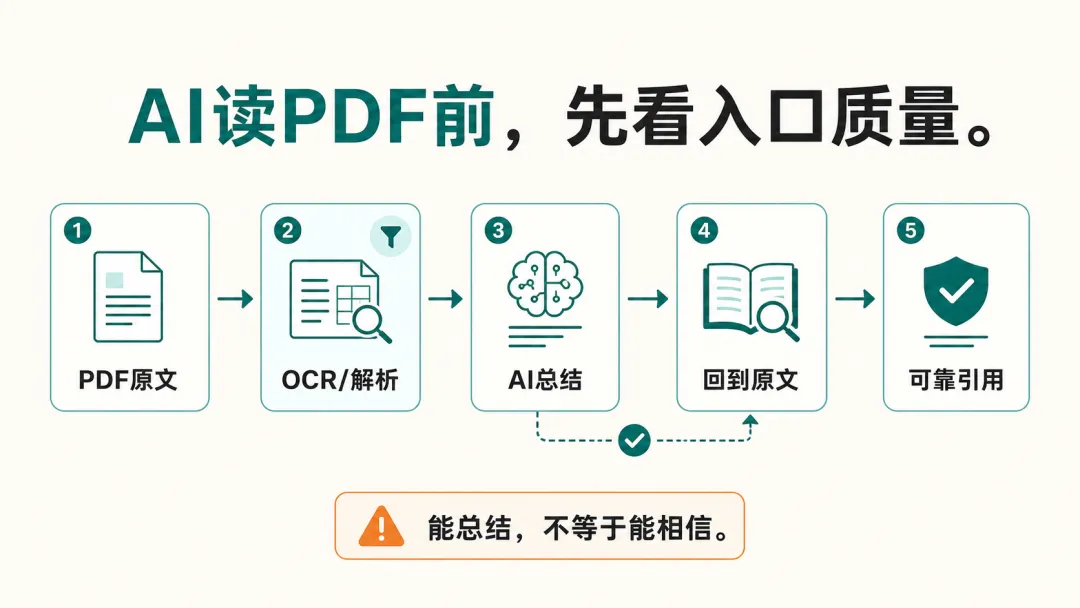
所以我现在更谨慎一点——只是快速读懂,丢给 AI 没问题;但要把一批重要 PDF 放进知识库、反复引用,最好先确认一件事:资料入口干不干净。
能总结,不等于能相信。
普通阅读,能总结就够了;但要写文章、做研究、搭知识库,就得能回到原文。
很多时候,我们会自然地觉得:
AI 回答不准,就是模型没理解好。
有些场景确实如此。
但处理 PDF 的时候,还有另一种情况很常见:模型拿到的资料,本身就已经不太干净。
比如一份 PDF 里有两栏排版、扫描页、页眉页脚、表格、图片说明、脚注、参考文献。
人眼看这些东西,其实还好。我们知道哪里是标题,哪里是正文,哪里是图注,哪里是表格。
但机器处理的时候,不一定总能保持这种结构。
有时候文字识别出来了,但标题层级没了。
有时候表格里的数字识别出来了,但行和列对应关系乱了。
有时候 AI 给出一段总结,看起来挺像那么回事,但你想回到原文核对出处,就不太容易了。
这就是我说的“资料入口”问题。
关键
PDF 进入 AI 工作流之前,中间有一层转换。
这层转换如果不稳,后面总结、问答、知识库、素材整理都会受影响。
所以这篇文章的重点不是讨论“哪个模型最强”,而是提醒自己:先别急着问 AI,先看看 AI 拿到的材料是不是可靠。
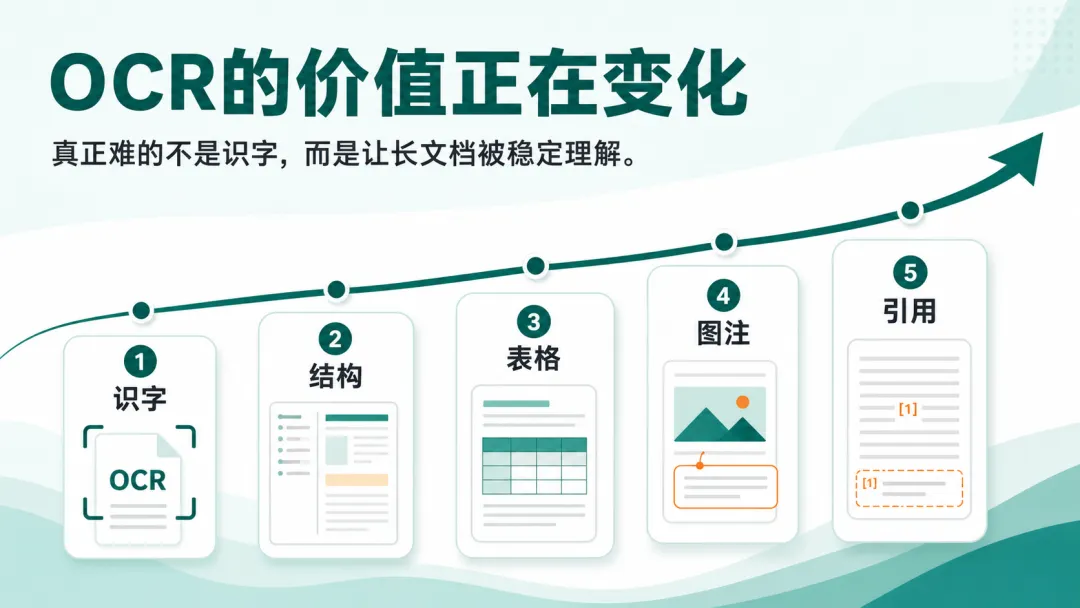
这也是我最近重新关注 OCR 的原因。
不是因为它又多了一个新名词,而是因为 PDF 进 AI 之前,确实需要一个更靠谱的“入口处理”。
以前我们说 OCR,基本就是“识字”:截图转文字、扫描件转文字、拍照识别文字。
但现在真正有价值的,不只是把字认出来。
更关键的是:一份几十页、上百页的 PDF,里面的标题、表格、图片说明、引用位置,能不能被尽量保留下来。
因为 AI 后面能不能答准,很大程度取决于这些东西有没有丢。
最近像 Mistral OCR 4、百度 Unlimited OCR 这些方向被讨论,也是一个信号:大家开始意识到,真正难的不是识字,而是让长文档能被 AI 稳定理解。
这个变化值得关注。
但我会说得克制一点:OCR 变强,不等于所有 PDF 都可以放心一键入库。
它更像是一个越来越好用的入口工具。
入口工具再强,也最好结合自己的资料类型做一点小样本验证。
尤其是:扫描件、表格很多的报告、图文混排手册、课程讲义、需要引用出处的研究材料。
这些资料不是不能用 AI 处理。只是最好先试一下,再决定要不要批量处理。
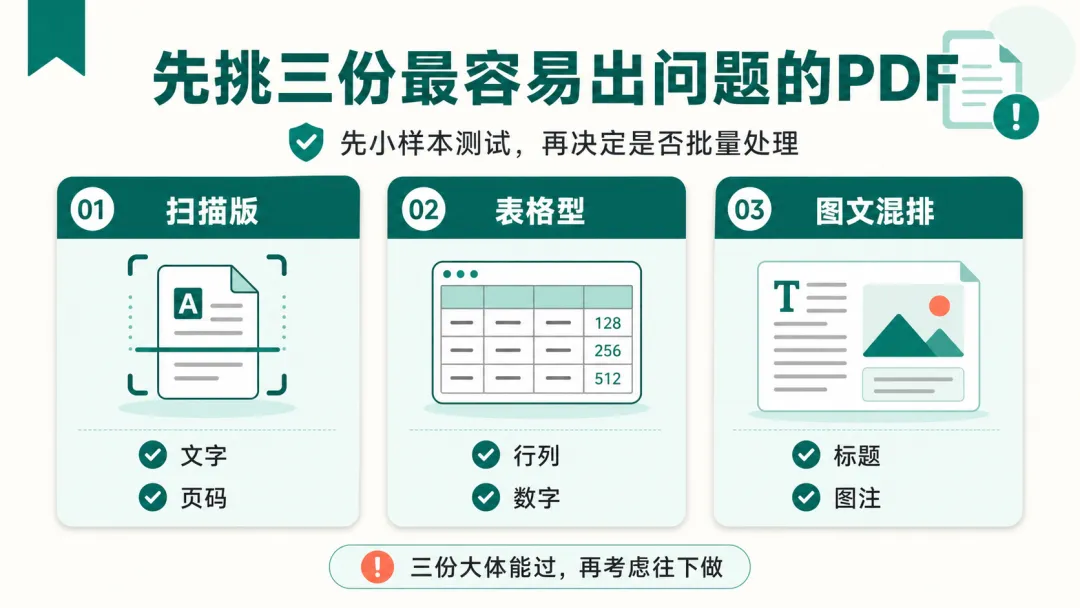
如果我自己要试,我不会一上来处理整个文件夹,而是会先挑三份最容易出问题的 PDF。
这里面我最在意的是表格。
因为表格最怕的不是识别失败,而是错位。
错位之后,它看起来仍然像真的,但结论可能已经偏了。
这三份不需要测很多。
每类拿一份,跑一遍,就能大概知道这条路线适不适合你手上的资料。
三份都过不了,就先别急着搭知识库。
三份大体能过,再考虑往下做。
我一开始想把这件事写成一张很完整的检查表。
但后来想想,对大多数读者来说,太重了。
我们不是要给自己增加工作量。我们只是想避免把一堆“不稳定的资料”直接丢进知识库,然后后面越问越乱。
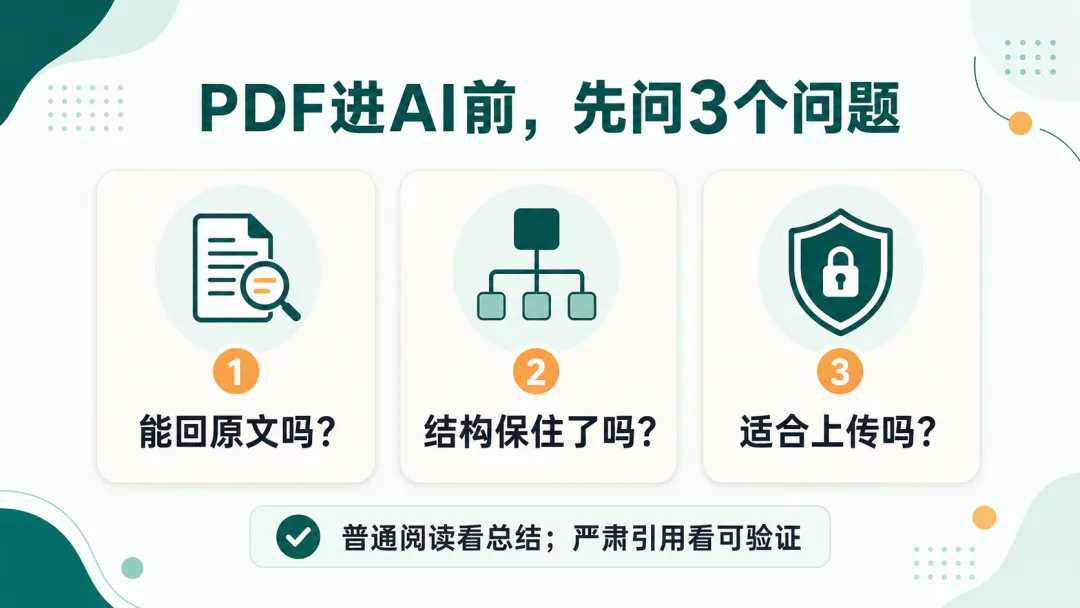
所以我现在更建议只记住 3 个问题。
这是我最在意的问题。
AI 总结得顺,不代表一定可靠。
如果它说了一个结论,但你找不到原文出处,那这份资料就不适合直接用于重要判断。
比如你用它做研究、写文章、整理报告,最好能回到原文页码或原文段落。
划重点
如果回不去,就把它当“辅助理解”,不要当最终依据。
PDF 里很多信息不是靠文字本身表达的,而是靠结构表达的。
标题、层级、表格、图注、脚注、页码,这些都很重要。
如果结构丢了,AI 后面就容易在一堆碎片里猜。
所以可以随便抽几页看看:
不用每页都查。
先抽样就够了。
公开资料、课程资料、普通文章,一般问题不大。
但如果是合同、财务、医疗、法律、客户信息、账号密钥,就不要随手上传。
如果一定要处理,可以先脱敏,或者考虑本地方案。
这不是吓唬人。这是做资料自动化时很基本的边界感。
这里也不用绝对化。我不想说哪一种一定最好。
更合适的判断是:看你的资料类型和使用频率。
我的判断很简单:
不要为了显得专业,一上来就把事情做重。
如果只是做公众号素材、课程笔记、网页剪藏、低风险 PDF,现成工具加一点人工抽样,已经能解决很多问题。
提醒
我们要的是稳定可用,不是把流程做复杂。
我想提醒的不是:PDF 不能丢给 AI。
恰恰相反,该用。
AI 读 PDF,确实能帮我们省时间。
OCR 变强,也确实会让资料整理变得更方便。
只是别把“能总结”直接等同于“能相信”。
普通阅读,能总结就够了。
但如果你要写文章、做研究、搭知识库,最好多问一句:
划重点
它的答案还能不能回到原文?
这句话,可能比“哪个工具更强”更重要。
所以,OCR 变强是好事。
AI 读 PDF 也确实越来越方便。
但越是方便,我们越要留一点判断。
不是所有 PDF 都要先做一套复杂流程。
也不是所有资料都必须严肃验收。
如果只是快速了解一份文档,直接丢给 AI 总结,没问题。
但如果你要把它放进知识库、资料库、内容素材库,后面还要反复引用、复盘、写文章,那最好先做一个小样本测试。
看看答案能不能回到原文。
看看结构有没有保住。
看看资料适不适合直接上传。
这几个问题过得去,再批量处理,心里会踏实很多。
很多时候,AI 问不准,不一定是模型没理解好。可能只是它一开始拿到的资料,就已经不够清楚。
这里是老王,让 AI 成为你的超能力。
— E N D —

