夜雨聆风
夜雨聆风阿拉丁的神灯?
关于AI漏洞挖掘的研究,一直是大家所关注的命题
之前写的系统与文章 陆续收到很多师傅的反馈
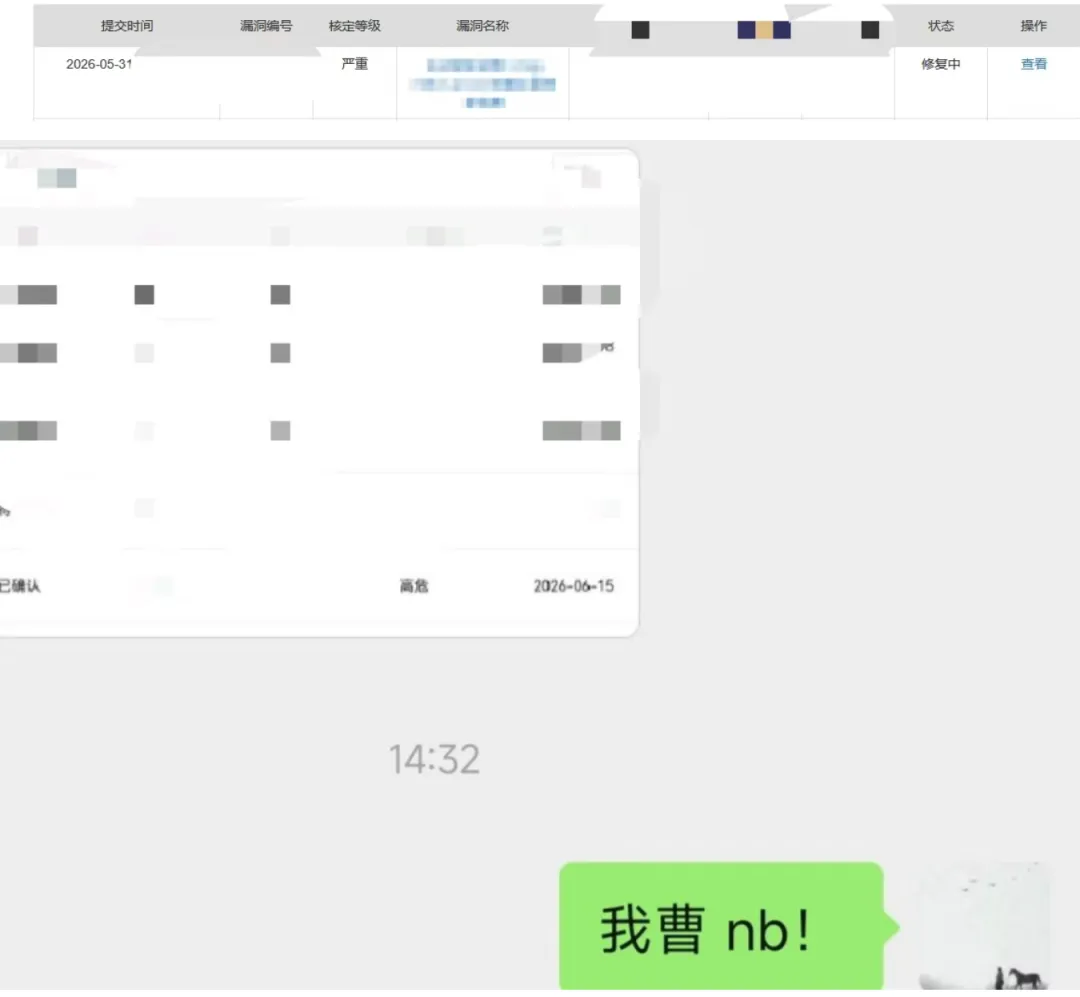
效果在我意料之外 诸如 某大厂SRC严重漏洞 单洞2.6w 以及n多个核心业务高危
也有师傅直接把开源项目源码丢进AI,让一次性找出项目里的所有漏洞
AI 说有17 个"高危",确认后发现 16 个误报,剩下 1 个是已公开的 CVE
同样是AI挖洞,而两者之间的差异,让我感叹不已
前者知道数据怎么流转、哪个接口容易出问题 后者把 AI 当成阿拉丁神灯 许愿式挖洞
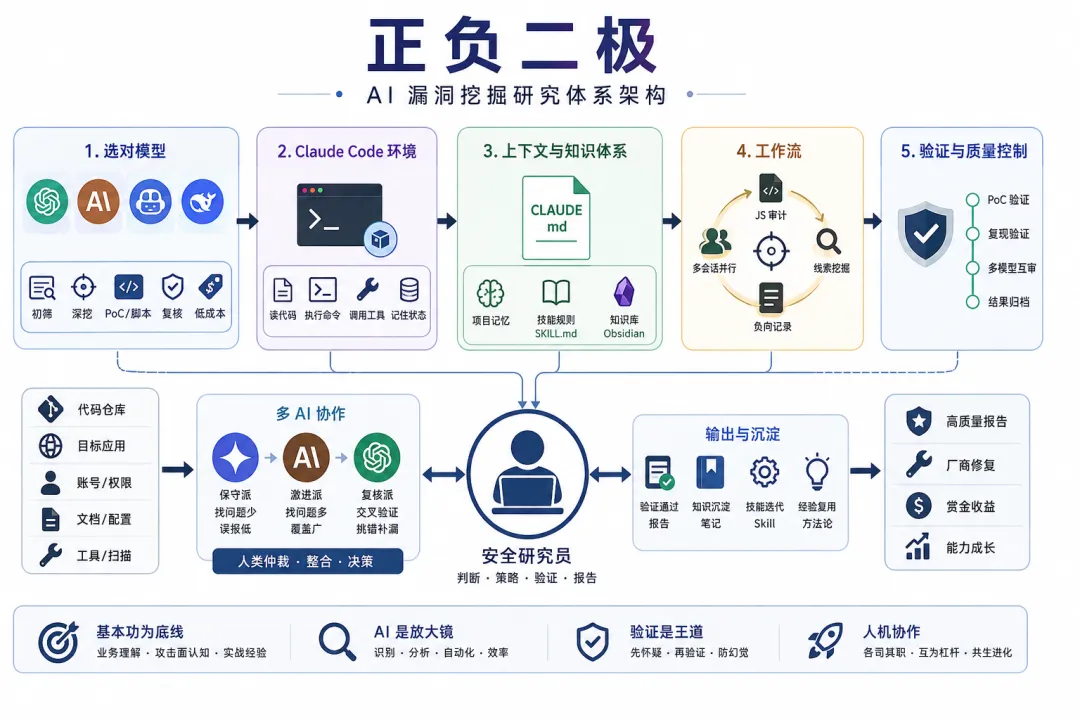
那么怎么更好的利用AI放大自身优势 ? 本文将进行系统性的讲解
基本功是底线,AI 是放大镜,基础越扎实,AI 能放大的价值就越大
1. 按任务选模型,别迷信最强
一谈到AI漏洞挖掘,很多第一反应 什么模型?最好用的是什么?
实则 没有最强模型,不同模型 适合的事情不一样,因地制宜,个人感觉如表
比如 Tom Fenech 在 ClickHouse 的做法,有参考价值:
https://clickhouse.com/blog/how-i-hunt-for-vulnerabilities-with-ai
Copilot Agent:干体力活,读代码、跑
git log、生成 PoC、在 Docker 里验证Claude Opus:做深度分析,理解漏洞为什么会发生
ChatGPT/GPT:做交叉验证,复核报告
2. 从网页端AI迁到 Claude Code
看到很多师傅还在用网页端AI挖洞,豆包黑客,其实没必要

2.1 网页端的问题
网页端 AI 适合聊天,不适合长期项目,原因如下:
大项目只能一段一段喂,全局关系被切断
无法很好调用你的本地工具
中间结果都要你手动复制粘贴
2.2 Claude Code 是什么
而Claude Code、Codex 这类Agent 能给模型一个调用工具、反复验证的环境
能帮助你:
读本地代码和文件结构
执行命令和脚本
调用浏览器等外部工具
打开自动加载项目背景
2.3 安装参考
https://mp.weixin.qq.com/s/5kgVdLNABViv8uAnD0M6Ag 使用教程:【Claude Code 从 0 到 1 全攻略】https://www.bilibili.com/video/BV14rzQB9EJj?vd_source=f4b19869b1fd6083beeeec68f9749860
2.4 配置原则:少即是多
有人装上 Claude Code 就堆十几个 MCP、几十个 Skill
这些东西都会占上下文空间,工具越多,AI 能用来思考的空间就越少
真正重要的是给 AI 画一个清晰的边界,让它知道什么能做、什么不能做、做到哪一步该停
3. AI上下文管理
3.1 CLAUDE.md 是项目的"记忆卡"
项目往往要持续几周 如果没有一个结构化的项目文件
每次 reopen 都要重新交代:这是哪个程序、范围是什么、有哪些账号、上次测到哪
CLAUDE.md 便可解决此问题,放在项目根目录
Claude Code 每次启动都会自动读取保持更新,隔几天回来也能接着干
CLAUDE.md 模板参考
# [项目名称] — 测试上下文## 测试范围### 在测范围- `app.example.com`- `api.example.com`- `*.example.com`(下列除外)### 排除范围- `blog.example.com`- `status.example.com`- 第三方集成(支付、短信、邮件、埋点等)### 项目限制- 自动化扫描速率不超过 5 req/s- 禁止社会工程学- 禁止接触真实用户数据- 禁止将发现的漏洞用于超出 PoC 的任何用途## 项目信息- 平台:补天 / 漏洞盒子 / 360 SRC / 京东安全 / 蚂蚁安全 / 企业自建- 首次响应 SLA:3 个工作日- 企业自评:是 / 否- 赏金参考: - 低危:100 - 500 元 - 中危:500 - 2000 元 - 高危:2000 - 8000 元 - 严重:8000 元以上## 技术栈- 前端:React 18 + Next.js 14- 后端:Node.js(Express)+ PostgreSQL- 认证:JWT + Session,企业微信 / 钉钉 / 飞书 OAuth- 云与 CDN:阿里云 / 腾讯云 / 华为云 + Cloudflare / 百度云加速- 文件上传:OSS 预签名 URL(阿里云 OSS / 腾讯云 COS / 七牛云)## 测试账号- **用户 A**(普通成员,组织 1):账号密码存于密码管理器- **用户 B**(普通成员,组织 2):账号密码存于密码管理器- **管理员**(如有):账号密码存于密码管理器跨租户 IDOR 测试至少需要 A、B 两个不同组织的账号## 角色与理论权限- **所有者**:对组织拥有全部权限- **管理员**:管理成员与计费,不可删除组织- **成员**:对共享资源可读写- **访客**:只读权限记录每个角色的权限边界,有助于发现越权提升点## 已测绘攻击面### 值得关注的接口- `GET /api/v1/users/:id` — 直接 IDOR 候选- `PUT /api/v1/organizations/:id/members/:user_id` — 验证角色校验- `/api/admin/*` — 测试非管理员是否可直接访问### JS 中发现的功能开关- `BETA_NEW_BILLING`:用户设置中可手动开启- `INTERNAL_DEBUG`:似乎只在 staging 环境启用### 异常观察- `/api/v1/search` 对某些 payload 返回 503,需深入- `/settings/billing` 的前端代码引用了未文档化的 `/api/v1/admin/refund`## 当前发现### 01. IDOR:GET /api/v1/organizations/:id/invoices- 状态:本地已确认,尚未写报告- 置信度:80%- 潜在影响:可读取其他组织发票(高危)- 下一步:稳定复现、录屏、撰写报告### 02. 竞争条件:POST /api/v1/coupons/apply- 状态:怀疑存在- 置信度:40%- 下一步:用 Turbo Intruder 跑 50 并发请求验证## 已排除的发现把试过但无效的点记下来,否则三天后会重复测一遍- `PATCH /api/v1/users/:id/email`:直接 IDOR、org_id 越权、竞争条件三种角度均测试,防护到位- `/api/v1/search` 的 `search` 参数:过滤正常,无注入## 对应用的认知自由记录架构、异常行为、假设- `Organization` 模型的鉴权中间件较强,但 `Invoice` 和 `AuditLog` 资源未一致应用- 前端功能开关由客户端控制,部分后端接口未在服务端强制校验该开关- 上传走 OSS 预签名 URL,需检查 bucket / 存储桶隔离## 报告规范- 模板:skill `report-writer` / 企业指定模板- 尽量附简短复现视频- 严重程度应结合业务场景论证,不只堆 CVSS字段解析
范围与限制:SRC 有法律和平台规则, 赏金表与 SLA:同样是高危,2000 和 8000 的投入策略完全不同 测试账号与角色:只有一个账号,很多越权漏洞根本测不出来 已测绘攻击面:把 AI 或手工发现的线索结构化,避免反复从零开始 当前发现与已排除:排除原因和发现一样值钱,三天后你会感谢自己写下来了 对应用的认知:自由记录,很多真正值钱的洞见是从这里长出来的
3.2 MCP:一个浏览器就够了
MCP 不用装太多 推荐:Playwright,https://github.com/microsoft/playwright
原因很简单:与其用文字跟 Claude 描述怎么登录,不如让它直接操作浏览器点过去
3.3 Skill:把审计思路写成规则
Skill 是放在 ~/.claude/skills/ 下的 SKILL.md
任务匹配时自动加载它的作用是把某类漏洞的审计思路"教"给 Claude,让它按你的套路来
很多人写不好 Skill,是因为把几十个检查点全塞进一个 prompt
结果 Claude 跑一会儿就迷失了,还不如手写 prompt
五段式结构
PERSONA: 定义角色和专业领域CONTEXT: 系统、业务、约束、历史背景EXAMPLES: 3-5 个带推理过程的输入-输出示例INSTRUCTIONS: 分步骤的具体检查指令OUTPUT FORMAT: 指定结构化输出IDOR 审计 Skill 举例
保存为 ``~/.claude/skills/idor-hunt/SKILL.md:
# IDOR 审计 Skill## 角色你是专注于访问控制缺陷的安全工程师,擅长通过对比不同账号的响应来识别 IDOR。## 目标在授权范围内,从目标应用的 API 端点中找出 IDOR 和越权访问漏洞。## 触发条件用户提到以下任一关键词:idor、越权、访问控制、角色权限、tenant、organization、user_id、order_id。## 工具约束- 使用 Read/Grep/Glob 读取代码和请求文件。- 禁止对外发包,除非用户明确授权并指定目标。- 禁止猜测文件路径。## 执行步骤1. 枚举所有包含 ID 参数、用户 ID、组织 ID 的端点。2. 识别响应中包含敏感数据的字段(email、phone、address、amount、status 等)。3. 请求用户用两个不同账号(A 和 B)访问同一端点,对比响应。4. 如果响应相同或账号 A 能访问账号 B 的数据,则标记为 IDOR 候选。5. 对候选端点,尝试以下变体: - 递增/递减 ID - 替换为其他用户的 ID - 删除 ID 参数 - 添加 `admin=true`、`role=admin` 等字段 - 修改 `org_id`、`tenant_id`、`workspace_id`6. 记录每个测试的结果、响应差异、证据截图。7. 输出结构化报告并停止。## 输出格式```json{ "vulnerable": true|false, "confidence": "high|medium|low", "evidence": "端点 + 参数 + 响应差异摘要", "attack_chain": "账号 A 访问 /api/v1/orders/1234 → 修改 ID 为 1235 → 获得账号 B 的订单详情", "poc": "curl 命令或请求示例", "fix": "在服务端严格校验当前用户是否拥有该资源访问权限"}## 禁止事项- 禁止猜测用户 ID 或组织 ID。- 禁止对生产环境中的真实用户数据进行大规模枚举。- 禁止报告未经验证的猜测。通用 Skill 模板
# [攻击面名称] 审计 Skill## 角色你是专注于 [领域] 的安全工程师## 目标在授权范围内,从 [代码类型] 中找出 [漏洞类型]## 工具约束- 使用 Read/Grep/Glob 读取代码- 禁止 Bash 的 grep/find- 禁止对外发包## 执行步骤1. 枚举 [入口点/敏感函数]2. 向上追踪 3 层数据流3. 检查是否有 [具体缓解措施]4. 对可疑点设计验证测试5. 输出结构化报告并停止## 输出格式输出必须是 JSON,包含:- vulnerable: true/false- confidence: high/medium/low- evidence: file:line- attack_chain: 数据流描述- poc: 验证命令- fix: 修复建议## 禁止事项- 禁止猜测文件路径- 禁止编造代码- 禁止报告未读文件中的漏洞- 出 scope 立即停止Skill 设计原则
一个 Skill 只处理一种漏洞:别想着一个文件覆盖所有 OWASP Top 10 步骤要具体到能执行:不是"检查 SQL 注入",而是"用 Grep 找 SQL 拼接点,向上追三层" 输出必须结构化:证据、置信度、验证命令、修复建议,缺一个都没法用 写明停止条件:比如"找到 3 个可疑点就停止,等人工判断" 加反幻觉规则 :禁止猜测路径、编造代码、报告未读文件 长内容放附件:大词典、案例库放单独文件,别让主 prompt 膨胀
Skill 要迭代
建议把 Skill 放 Git,加版本号如 idor-hunt-v1.1.md
每次改都写清楚为什么改什么时候该迭代?
某个 Skill 总是漏特定类型漏洞 误报突然变多 目标技术栈变了 平台规则要求变了
另外随着模型变强,很多通用场景其实不需要专门写 Skill
除了个人适配的特殊技巧与场景,把约束写清楚往往就够了
身边朋友也写了很多skill 可以参考
Yakit:https://github.com/yaklang/hack-skills狼组:https://github.com/wgpsec/AboutSecurity
77姐:https://github.com/HeaSec/Pentest-Lyan
3.4 Obsidian 当知识库
Vault 结构:
/vault├── /programs 每个程序的 CLAUDE.md、侦察笔记、发现记录├── /vulns 漏洞类型方法论(idor、ssrf、jwt、xss 等)├── /techniques 技术专题(OAuth、GraphQL、JS 分析)├── /writeups 公开报告阅读笔记├── /tools 工具技巧与 Prompt 库└── /skills Claude Skills 源文件Obsidian 记笔记,Claude Code 读笔记
验证完的方法论再沉淀成 Skill 或新笔记循环起来
参考:
https://github.com/AgriciDaniel/claude-obsidian
https://agricidaniel.com/blog/claude-obsidian-ai-second-brain
4. AI辅助工作流 demo
4.1 JS 审计
1. 把目标公开 JS 文件下载到 js_source/# 2. 在 Claude Code 中让它分析:# "分析 js_source/ 下的所有 JavaScript 文件,找出:# - 所有 API 端点定义# - 硬编码的密钥或敏感信息# - 前端逻辑漏洞(如客户端权限校验)# - 不安全的反序列化调用"AI 特别适合做这个压缩、混淆后的 JS 人眼看很费劲,但 AI 能很快把端点、参数、调用关系理出来
4.2 头脑风暴
不要问"帮我找个漏洞",要问"给我 10 个最值得深挖的点"
Context:- Program: [program name]- Target: 完整范围见 @CLAUDE.md- 我的身份:以普通用户账号 A 登录,所属组织 org 1234- 资源:账号 B 在另一个组织,可用于跨租户测试Goal:请给出这个应用中 10 个最值得优先深挖的可疑点,按可利用可能性排序对每个线索,请包含:- 涉及的端点或功能- 疑似漏洞类型- 可疑原因(观察到的异常模式、违反约定、业务逻辑风险等)- 最快验证或排除的方法Constraints:- 不要给"测试 XSS"、"测试 SQL 注入"这类通用建议,我要的是针对这个应用的具体线索- 优先关注业务逻辑漏洞、访问控制缺陷、复杂多步骤攻击链- 如果你对某部分缺乏上下文,请明确说明,不要编造让 AI 承认不知道,比让它硬编一个靠谱得多
4.3 记录负向结果
大多数人只记"找到什么",但"什么没找到"同样重要:
哪些端点试过了,为什么排除 哪些 payload 被过滤,绕过可不可行 哪些目标防护已经比较到位,下次降低优先级
负向记录能告诉你 这个方向不用再浪费 Token
5. 实用技巧
5.1 多开几个会话
一个会话从头跑到尾很容易跑题 同时开几个会话,各自负责一块:
idor-hunt | ||
auth-bypass | ||
ssrf-hunt | ||
每个会话独立,互不干扰
5.2 对输出进行追问
AI 给出发现后,必须追问:
所有验证结果都进行记录:已确认、待验证、已排除(必须写原因)
6. 推荐两个有意思的做法
https://blog.zsec.uk/bullyingllms/
验证门
所有新发现默认先放进 hallucinations/ 目录,只有通过全部验证门后才晋升到 findings/
先怀疑再验证的机制 让误报率大幅度降低
多模型互相挑错
https://kattraxler.cloud/ai-agent-assisted-bug-hunting/
多个独立模型在同一块黑板上写判断,人当主持人,负责挑错、整合、拍板
Gemini:保守派,倾向于认为代码没问题 Claude:激进派,会穷尽每个攻击面 人:给保守派施压,给激进派降温,挑出真正值得跟进的方向
多模型互相挑错,比单一模型靠谱得多单一模型容易被 prompt 暗示带偏
7. 防幻觉
AI 自信地告诉你一个假洞,防幻觉就两字:验证
基础验证:
PoC 必须能跑起来 必须在干净环境里复现 崩溃必须真实可利用 必须能在普通用户权限下触发
辅助手段:
建一个 md,把排除的点全记下来对高置信度发现,用第二个模型独立复核 让不同模型从相反立场分析同一个问题,参考上文
8. 报告写作:洗掉 AI 味
厂商最讨厌的报告有几种:
开头"我很高兴地报告一个重大漏洞……" 大量项目符号、冗长过渡、正式但空洞的表述 简单 IDOR 硬凑"背景、方法、影响、建议"完整章节 缺乏具体业务影响,只会说"可能导致数据泄露"
用 Claude 写完报告初稿,须人工重写一遍,删掉所有 AI 味
9. 闲聊
AI的出现,也涌现出不同的问题,很多人拿着AI 报告直接提交,导致AI幻觉报告堆积平台
从而报告周期变长,真正的高质量报告更难脱颖而出,人与平台双方都心力憔悴
最近也和很多审核 在探讨 怎么更好引入AI分析,或者说抬高项目门槛与筛选机制
自我判断,未来大概率呈现两极分化:
懂业务逻辑,会用 AI 做杠杆,最终存活的不错
把 AI 当阿拉丁的神灯,不注重自身能力提升,最后被取缔
AI 适合干的:
子域名枚举、端口扫描、技术栈识别、JS 解析、端点提取
模式识别、Payload 生成、PoC 编写、文档整理、报告初稿、知识检索
人类须干的:
判断这个程序最值得挖哪里、理解 API 调用链背后的业务意图
把两个无关问题组合成严重漏洞、论证对厂商的真实影响
一步一步亲手复现、决定哪些目标能测哪些数据不能碰
几种协作模式:
AI 增强安全研究员不是更依赖 AI,而是更清楚什么时候该用它,什么时候该自己上
AI 作为拐杖,你不会真正成长,AI 作为加速器,你会跑得比任何人都快