 夜雨聆风
夜雨聆风你有没有遇到过这种情况——让AI读一份几十页的PDF,它读到第5页就忘了第1页说了啥。目前现在几乎所有AI大模型都有这个毛病。它们处理长文档的方式很粗暴:一页一页分开读,读完一页清空记忆,再读下一页。
百度刚刚开源了一个新模型,叫Unlimited OCR,专门解决这个问题。
它能干什么?
简单说,就是把一堆扫描件、PDF、论文、合同扔给它,它能从头到尾一口气读完,而且读得又快又准。
1.一次能读几十页,不会读到后面忘了前面
2.表格、公式、文字混排的复杂页面也能搞定
3.模型非常小,对电脑配置要求不高
它有多准?
在一个叫OmniDocBench的权威测试里,它拿了第一名,分数超过了一堆比它大几十倍甚至上百倍的模型。
模型大小对比一下:
1.百度这个:参数30亿,实际只用5亿
2.对手A:参数2350亿,分数不如它
3.对手B:谷歌的,没公布大小,分数也不如它
为什么它能做到别人做不到的事?
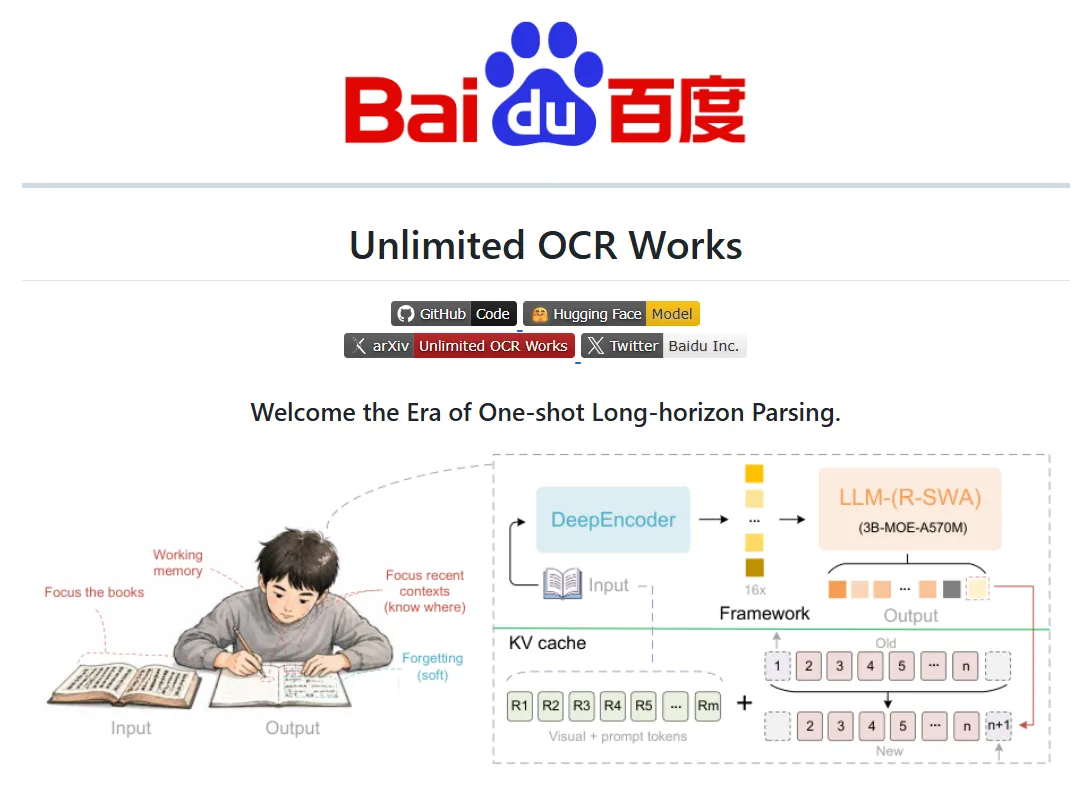
这里有个很有意思的设计思路。人类抄书的时候怎么做的?眼睛盯着原文,脑子里只记刚刚写的那几句话,早先写过的内容慢慢淡忘。这样既不会抄错,脑子也不会爆炸。
百度给模型设计了类似的机制——叫R-SWA,意思是:
1.原文永远看得见,不会忘
2.已经写过的内容,只记最近一小段
3.旧的记忆自动清掉,腾出空间
这样一来,不管读多少页,模型占用的内存始终不变,速度也不会变慢。
有什么意义?
百度之前有一个叫PaddleOCR的工具,国内用得特别多,手机端、服务器端、嵌入式设备都能跑,主打实用。现在加上这个能一口气读几十页的新模型,相当于把最前沿的研究和最大规模的落地经验合在一起了。
而且,按照论文里的说法,这个技术不只用于OCR,以后还可以用在语音识别、翻译这些同样需要处理长内容的场景。如果能成,就意味着AI处理长文本、长语音的能力会整体上一个台阶。
在哪里能用?
模型已经开源了,代码和权重都在网上可以下载。
GitHub地址:https://github.com/baidu/Unlimited-OCR

