夜雨聆风
夜雨聆风
导读:FinixDoc是一套面向金融文档解析的端到端智能体系统,核心模型 FinixDoc-VL基于4B级Qwen3-VL训练,在FinixDocBench评测中取得81.43的综合得分。团队还同步开源了FinixDocBench 的部分子集,覆盖真实金融业务中的低质拍摄、超长文档和密集表格等难点场景。

图1:FinixDoc输出示例
同样是“读一份文档”,PDF原生渲染出的高清文档图像,和真实金融业务里需要大量处理的票据、保单、理赔材料,几乎是两种任务。前者是数字原生文档,版式规整、分辨率稳定,很多模型已经能拿到不错分数;后者往往来自手机拍摄,带着阴影、反光、褶皱和透视变形,关键数字还可能被压缩和模糊吞掉。再进一步,如果遇到上亿像素的超长保险条款图像,或密密麻麻的大表格,问题甚至不只是“识别准不准”,而是模型能否返回完整、有效的解析结果。
FinixDoc是由蚂蚁保算法团队研发的一套面向金融文档解析的端到端智能体式解析系统:核心解析模型基于Qwen3-VL-4B训练,面向低质金融文档、复杂版式、表格结构、阅读顺序和超大版面处理等问题。同时,团队还开源了试用主页和金融文档解析评测集FinixDocBench的部分子集,覆盖数字原生保险条款、手机拍摄的票据清单、超长文档图像和大规模密集表格等真实业务难点。
项目主页:
https://finix.alipay.com/
技术报告:
https://openreview.net/forum?id=kjgpNlov2A
Hugging Face数据集:
https://huggingface.co/datasets/inclusionAI/FinixDocBench
01
先看成绩:主评测领先,超大文档成功率92%
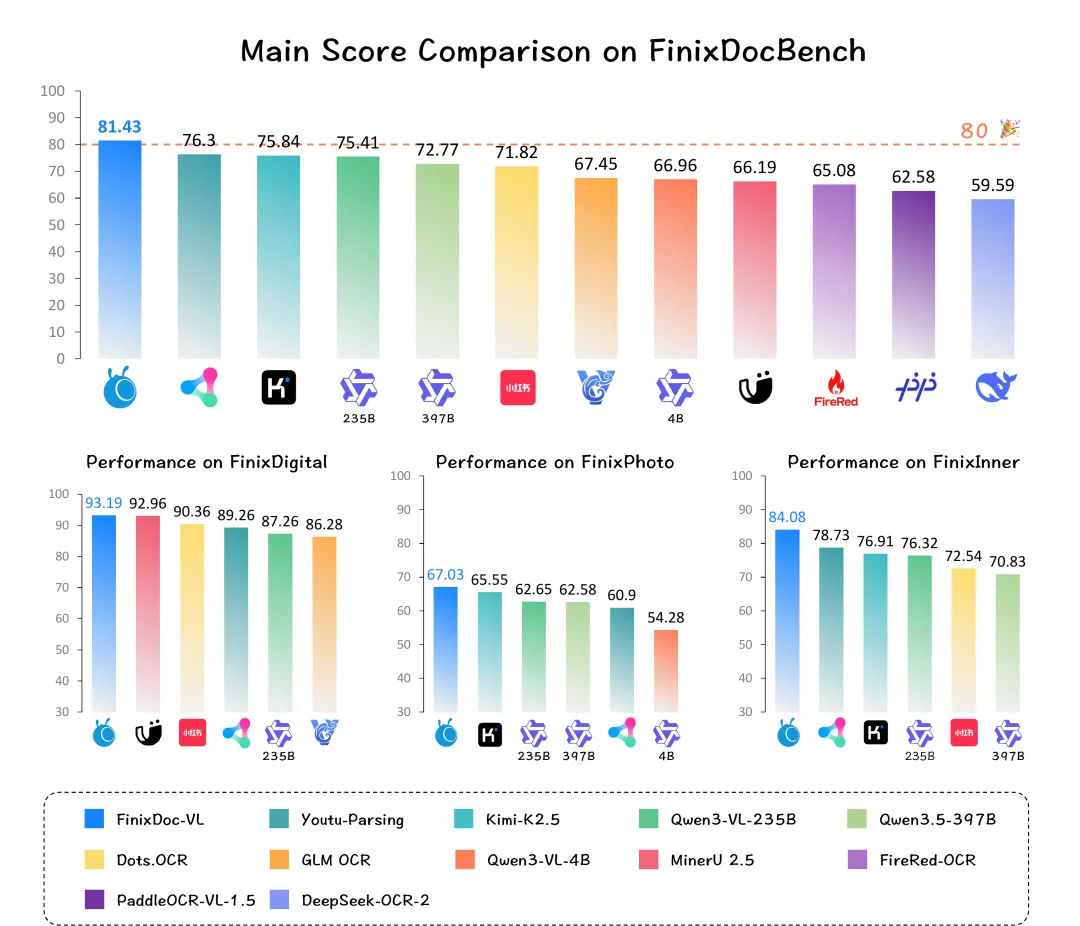
图3:FinixDocBench综合得分对比
在FinixDoc技术报告中,FinixDoc-VL在FinixDocBench 主评测子集上取得81.43的综合得分,比报告中排名第二的开源模型高5.13分。
分场景看,FinixDoc-VL在数字原生金融文档FinixDigital上达到93.19,在手机拍摄票据FinixPhoto上达到67.03,在内部金融流程文档FinixInner上达到84.08。

图2:低质拍摄医疗票据示例
尤其值得注意的是 FinixPhoto 。这个子集对应真实低质拍摄场景(如图2所示),包含模糊、透视、打印噪声等因素。许多在数字原生高清文档评测上表现不错的专用OCR或文档解析模型,到这里会明显掉分。FinixDoc-VL相比训练前的Qwen3-VL-4B基座提升12.75分,也超过Kimi-K2.5、Qwen3-VL-235B-A22B-Instruct等大模型基线。

图3:超大表格图像示例(节选预览)
而在FinixHuge这类超大文档图像上,评测重点变成“能否完整处理”。这里的“超大”并不是普通高分辨率图片,而是长宽比动辄30:1以上的超长条款,或一张图中包含数千到上万单元格的密集表格(如图3所示)。FinixDoc完整系统通过split-then-merge策略,成功率达到0.92(92%);Qwen3-VL-235B-A22B-Instruct和GLM-OCR分别为0.68、0.34,优势明显。
换句话说,FinixDoc想证明的不是“在数字原生高清文档基准上再卷一点”,而是:面对真实业务里的低质、复杂和超大金融文档图像,系统还能稳定输出可用的结构化结果。
02
为什么金融文档解析不能只看传统评测集?
在金融场景中,往往真实的业务场景与通用的评测榜单之间存在较大的数据分布偏差。为了客观展现真实业务场景对模型的能力要求,FinixDoc团队在其技术报告中提出了一个新颖的行业理念:文档解析能力矩阵(Document Parsing Capability Matrix)。
这个矩阵旨在描述文档解析任务的真实难度:
横轴是文档图像质量:从数字原生、扫描件,到手机拍摄、模糊、反光、扭曲、遮挡。
纵轴是文档版面规模:从常规单页,到超长版面、超大图像和复杂密集表格。
据此,团队把真实文档解析场景分成几类:
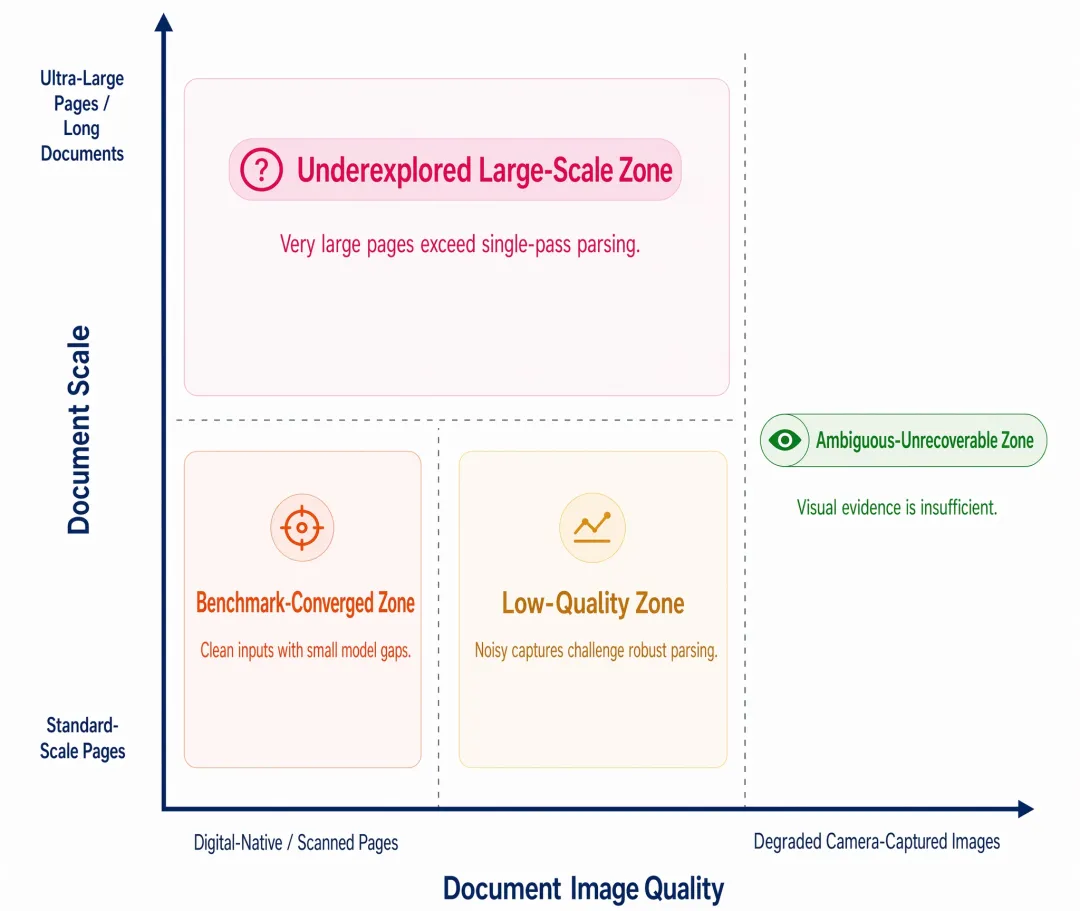
图4:Document Parsing Capability Matrix
Benchmark-Converged Zone:数字原生、高清规整、规模可控。大量现有评测集集中在这里,领先模型之间差距不大。
Low-Quality Zone:手机拍摄票据、理赔材料、各类证件等真实低质输入。这里对鲁棒性要求高,专用文档模型反而可能输给通用VLM。
Underexplored Large-Scale Zone:超长保险条款、超大密集表格。直接输入VLM时,容易因为下采样、token预算压力或输出长度限制而失败。
Ambiguous-Unrecoverable Zone:视觉证据本身不足。金融场景下,模型不能靠语言先验“猜一个看起来合理的答案”,宁可漏掉,也不能编造。
03
训练关键:把金融场景里的“看错一个字”
当成高风险问题
在FinixDoc中,除了配备了常用的图像处理工具外,FinixDoc-VL是其还原文档全文的核心。为了应用真实业务中严苛的挑战,我们基于Qwen3-VL-4B进行了充分的领域后训练工作。
金融文档解析里,最可怕的错误往往很小。比如“0”和“O”,“1”和“I/l/|”,“清”和“请/情/靖”,在低质图像里可能差别极细,但一旦出现在账号、金额、姓名、医院票据或保险条款中,就可能带来高业务风险。
FinixDoc-VL的训练第一步,就是围绕这类视觉混淆做金融域视觉表示适配。
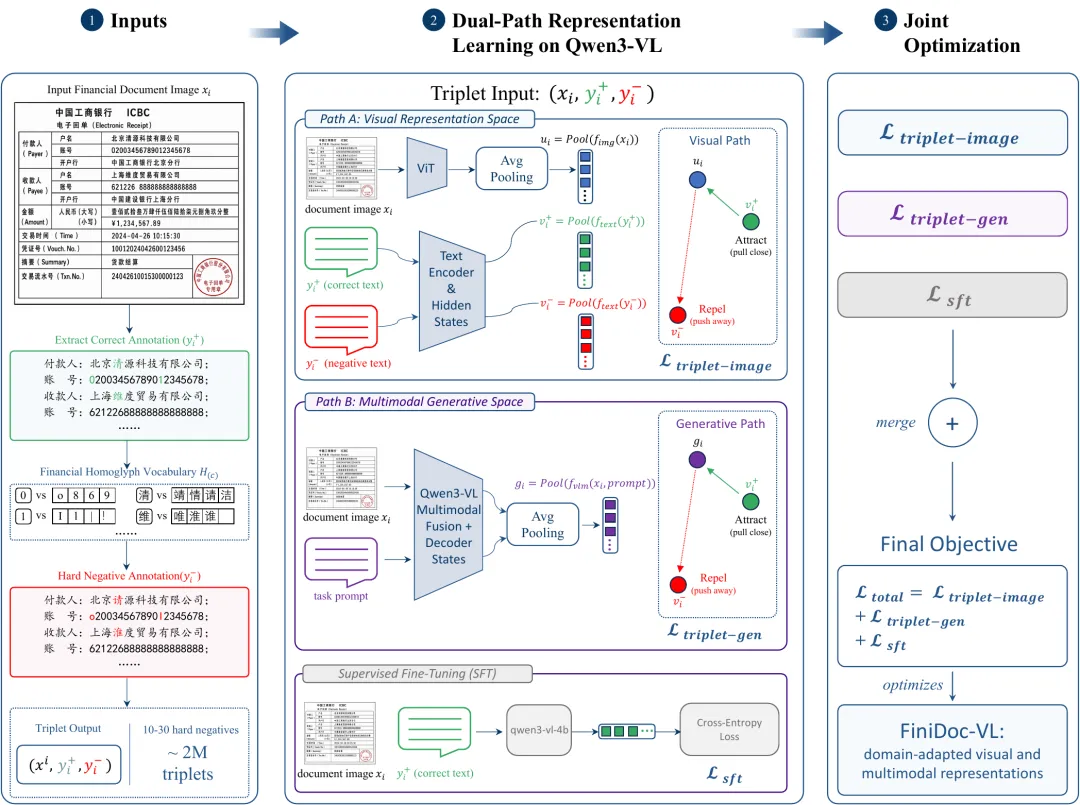
图5:金融视觉表示适配的对比学习框架
团队从约10万份真实金融文档中分析整理了约4500多个金融场景高频字符,并结合渲染字形相似度、感知哈希、笔顺相似度、笔画数等信号,为每个高频字符匹配了5-20个高度相似的形近字符。
在此基础上,系统会为每条正确样本构造10到30个困难负样本(hard negatives),例如把正确文本里的关键字符替换成视觉上极像、但语义上错误的字符,最终形成约200万组三元组训练样本用于对比学习。
相比于过去的训练方式,这一步不是随机扰动,而是模拟金融文档中真实出现过、且业务风险更高的识别错误,从而极大提高了训练任务难度。
第二步则是强化学习。FinixDoc-VL采用GRPO进行多阶段优化,训练数据包括10万页金融领域文档数据和10万页公开域外数据。
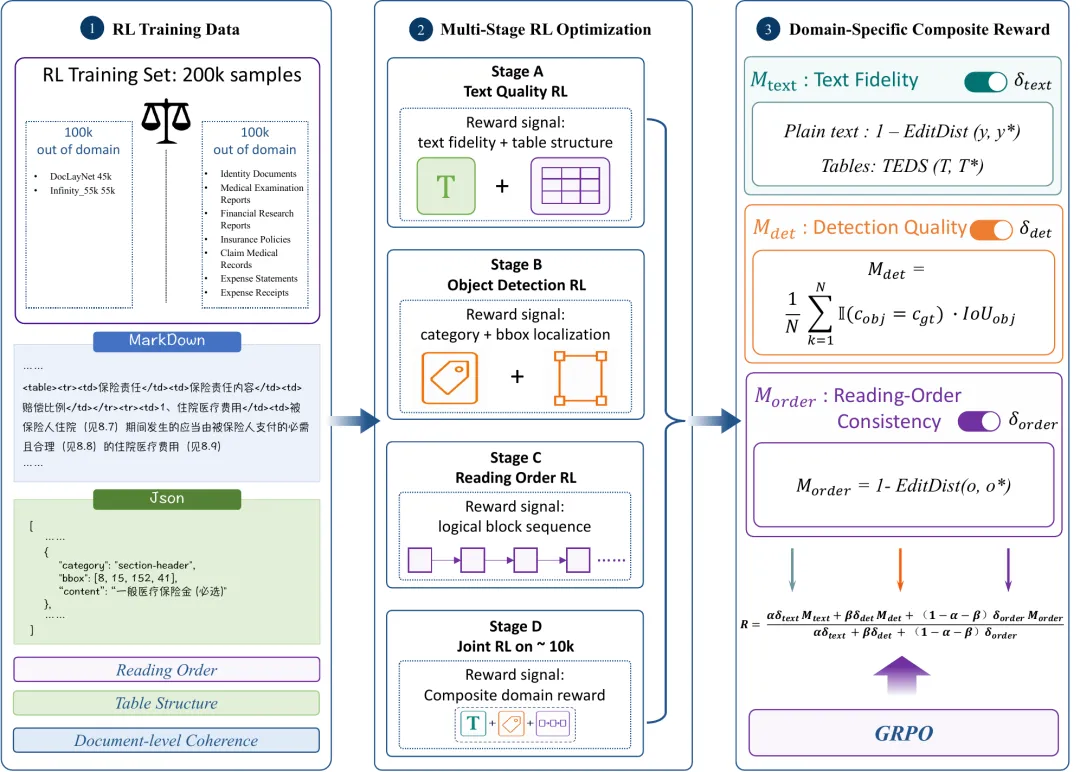
图6:领域奖励驱动的强化学习框架
奖励函数也不是简单比较整段文本相似度,而是拆成金融文档真正关心的几个维度:
文本保真度:普通文本看编辑距离,表格看TEDS结构相似度。
检测质量:面向JSON输出,关注类别和bbox定位。
阅读顺序:面向多栏、表格混排、长文档,约束版面块顺序。
因此,FinixDoc-VL同时学习两类输出:JSON适合供业务系统、规则引擎和字段抽取模块使用;Markdown适合给后续LLM做问答、总结、条款理解和检索增强。
04
Data Factory:
从千万页原始材料里筛出1%高价值样本
FinixDoc背后还有一条AI驱动、human-in-the-loop的数据生产流水线:Data Factory。
当前的金融保险业务已积累了亿级别的行业数据,如果依赖纯人工标注成本太高,但完全用模型自动预标注又很难保证质量,于是团队把流程拆成三段。
第一段是多模型协同预标注。系统并行使用PP-DocLayoutV3、FinixDoc-VL和Qwen3-VL-235B-A22B-Instruct:前者负责稳定版式检测,FinixDoc-VL提供金融域结构先验,大模型补充更广的语义判断。之后再按类别兼容性、空间重叠和文本相似度做融合。
第二段是大模型校准与精修。使用Kimi-K2.5对照原图、预标注和文本证据重新校准结果,从OCR、结构、全局一致性三个层面修正错误,包括bbox偏移、重复区域、阅读顺序、幻觉元素和复杂表格破碎等问题。
第三段是规则校验和质量路由。系统会检查坐标合法性、标签与内容兼容性、阅读顺序、重叠异常、HTML表格完整性等,再把样本分流到自动通过、抽检或专家复审队列。
最后,团队从千万页级原始金融材料中筛选出约10万页验证后的金融领域训练数据,按页保留率约1%。这些数据覆盖体检报告、金融研报、保险条款、理赔病历、费用清单和费用票据等高频场景。
05
FinixDocBench:
把真实金融难题做成公开评测基准
为了避免“训练投入很多,评测还停留在数字原生高清文档”的困惑,团队构建了FinixDocBench。
完整FinixDocBench约5000页,覆盖四类评测子集:
FinixDigital:数字原生金融文档,包括金融研报和保险条款。
FinixPhoto:手机拍摄医疗票据,重新按统一schema做全页标注。
FinixHuge:超大金融文档图像,包括超长条款和大规模密集表格。
FinixInner:内部金融流程文档,只用于内部held-out评测,不公开。
本次开源的子集包括742页样本:
Track | 公开 页数 | 场景 | 标注 |
FinixDigital | 242 | 数字原生保险条款 | 图片+Markdown +JSON |
FinixPhoto | 300 | 手机拍摄医疗票据 | 图片+Markdown +JSON |
FinixHuge-Long | 100 | 超长金融/保险文档图像 | 图片+Markdown |
FinixHuge-Table | 100 | 大规模密集表格图像 | 图片+Markdown |
所有公开样本都包含逐页图像和Markdown真值,其中542页还提供结构化JSON标注,包含类别、bbox、内容和阅读顺序。公开版FinixHuge中,单页图像最高达到386M像素级别。
06
文档解析真正的难点
正在从“识字”变成“可靠理解”
FinixDoc给出的方案,是通过4B级核心模型、金融域形近字对比学习、业务对齐强化学习、human-in-the-loop数据工厂,以及面向真实场景的FinixDocBench,系统化回答金融文档解析该如何训练、评测和部署。而开源FinixDocBench之后,这些低质、复杂、超大的金融文档难题,也有了一个可复现、可比较的公开坐标系。