 夜雨聆风
夜雨聆风一句话钩子:本周的 AI 科研工具不再写 Gemini CLI,而是 Antigravity CLI:它把终端工具升级成多 Agent 工作流入口,更适合处理“文献、数据、图表、写作、自动化”这种连续科研任务。
本文核心要点
▸ 每周只聚焦一个 AI 科研工具:本文只讲 Antigravity CLI,不做工具清单。
▸ 读者能学会:安装/迁移思路、第一次只读项目、用 Agent Skills / Hooks / Subagents / Plugins 组织科研任务。
▸ 完整案例从一个脱敏科研项目文件夹开始,覆盖文献证据表、实验设计检查、数据质控、绘图、Methods 草稿和复现记录。
▸ 明确边界:CLI Agent 能加速文件级工作流,但不能替你确认统计方法、实验结论和敏感数据合规。
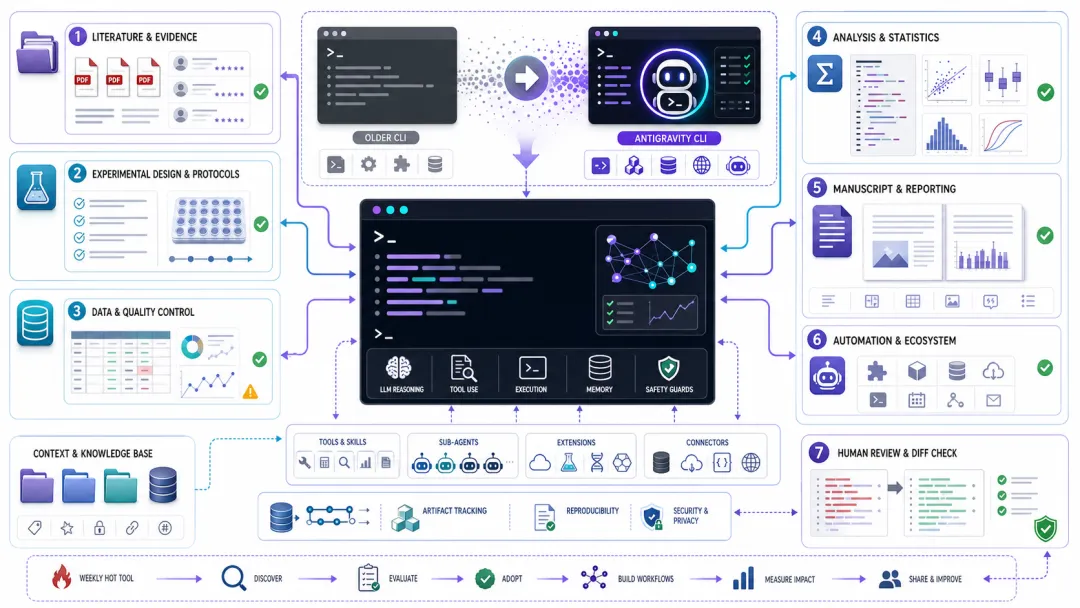
▲ 图 1:Antigravity CLI 参与科研项目的完整工作流:文献、方案、数据、图表、写作、自动化和人工复核。图片由 AI 生成,正文信息来自本文引用资料和本地运营模板。
本节结论:Google Antigravity 官方文档已经把 CLI、Subagents、Agent Skills、Plugins、Prompting 和 CLI Reference 作为可组合能力入口[1][2][3][4][5]。对科研人来说,重点不是追一个工具名,而是把项目文件夹里的文献、数据、图表和写作串成可复用流程。
Google Antigravity 官方文档把 CLI、Subagents、Agent Skills、Plugins、Prompting 和 CLI Reference 作为可组合能力入口[1][2][3][4][5]。对于科研人来说,这个变化很重要,因为科研项目本来就是长链条任务:资料在 PDF 里,数据在 CSV 里,代码在脚本里,图表在输出目录里,最后还要写成报告或论文。
所以这篇不是“又一个命令行工具新闻”,而是一个具体教程:如果你把 Antigravity CLI 当作科研文件夹级助手,应该怎么上手?怎么避免误改文件?怎么把文献、数据、图表和写作串起来?
本节结论:Antigravity CLI 适合处理文件夹级、长链条、可复核的科研工作流,不适合替代专业判断。
适合谁
适合已经有项目文件夹的研究生、科研助理、数据分析人员和公众号运营者。只要你的任务涉及多文件、多步骤、需要输出可复核结果,就适合尝试。
不适合谁
如果你只是想问一句“这篇论文讲了什么”,普通聊天工具更轻;如果你的数据未脱敏、包含患者信息或未发表机密材料,也不应该直接交给 CLI Agent 处理。
和普通聊天工具的区别
普通聊天工具依赖复制粘贴;CLI Agent 可以在本地目录里读取文件、生成脚本、写输出、检查 diff、沉淀 README。它更像一个项目助理,而不是一个聊天窗口。
本节结论:第一次使用的正确姿势是让它理解项目结构,而不是立刻让它自动写代码。
准备一个安全练习目录
输入:公开论文 PDF、脱敏 CSV、旧分析脚本、空 output 文件夹。
动作:复制一份练习项目,目录建议为 papers/、data/、scripts/、output/、README.md。不要在原始课题目录里直接试。
产物:research-antigravity-demo/。
检查点:目录里不能有未发表数据、患者信息、账号密钥和内部合作文件。
让它先做项目盘点
输入:当前项目目录。
动作:要求 Antigravity CLI 只读项目:列文件结构、推测每个文件用途、指出缺少哪些说明、标记可能敏感的文件。
产物:project_map.md。
失败处理:如果 Agent 一上来要改文件,终止任务,重新要求“只读分析”。
可复制提示词:
请先只读当前项目,不要修改任何文件。 请输出 project_map.md,包含: 1. 文件夹结构; 2. 每个文件可能用途; 3. 哪些文件可能包含敏感信息; 4. 这个项目缺少哪些 README/数据字典/复现说明; 5. 下一步建议,但不要执行。设置工作边界
输入:项目地图和你的任务目标。
动作:让 Agent 明确只能读取 papers/、data/、scripts/,只能写 output/。任何删除、移动、联网、安装依赖都必须先列计划。
产物:run_policy.md。
检查点:如果工具不能解释将要执行的命令,就不要让它执行。
本节结论:这类 CLI 的价值不是单点写代码,而是把科研任务拆给多个能力模块并留下可复核产物。
文献:PDF 到证据表
输入:papers/ 中 3-5 篇公开论文。
动作:让 Agent 提取研究问题、样本、方法、结果、局限,写入 output/evidence.md。每条结论必须有文件名和原文位置。
产物:证据表和待核验清单。
验收:随机抽查 20% 条目,回到 PDF 原文确认。
实验设计:把假设变成检查清单
输入:你的研究假设和已有实验方案。
动作:要求 Agent 检查分组、对照、样本量、混杂因素、失败场景和统计方法是否匹配。
产物:protocol_review.md。
验收:每个风险点必须给出“为什么是风险”和“如何补救”。
数据:从 CSV 到质控报告
输入:脱敏 CSV 和研究问题。
动作:生成数据字典、缺失值报告、异常值报告、列名解释和分析建议。先不跑复杂模型。
产物:data_dictionary.md、qc_report.md。
失败处理:列名含义不明时必须标记 unknown,不能猜。
图表:生成可复现绘图脚本
输入:质控后的数据、图表目标、分组变量。
动作:生成 scripts/plot.py,输出 output/figure.png 和 figure_caption.md。运行前先查看 diff。
产物:图、图注、绘图脚本。
验收:核对坐标轴、单位、样本量、分组和统计标注。
写作:Methods 只能从真实脚本反推
输入:analysis.py、plot.py、results.md。
动作:让 Agent 只根据真实脚本写 Methods 草稿,不允许编造没有执行的统计方法。
产物:methods_draft.md。
验收:Methods 中每个动作都能在脚本中找到对应代码。
科研工具落地操作台:用 Antigravity CLI 覆盖一个科研项目全流程
1. 课题调研:让 Agent 从 papers/ 和公开链接中生成 topic_map.md、evidence_table.md 和 team_landscape.md;人工核验每条来源是否真实可查。
2. 研究问题:把“我想做这个方向”压缩成 PICO/PECO、主要终点、次要终点和排除范围;输出 research_question.md。
3. 实验/分析方案:检查分组、对照、变量、样本量、混杂因素、统计方法和失败场景;输出 protocol_review.md。
4. 数据治理:生成数据字典、缺失值/异常值报告、脱敏检查、列名解释和数据版本记录;输出 data_dictionary.md 与 qc_report.md。
5. 分析脚本:从最小基线开始生成可复现脚本,固定随机种子,保留运行命令和依赖;输出 scripts/analysis.py 与 results.md。
6. 图表生成:根据研究问题生成图表脚本、图注和视觉检查清单;输出 figure.png、figure_caption.md 与 visual_qc.md。
7. 论文/报告写作:Methods 只能从真实脚本反推,Results 只能从结果文件引用,Discussion 必须标注哪些是推断;输出 draft_sections.md。
8. 自动化沉淀:把重复流程改成 Makefile、run.ps1 或 SOP.md,让下一个项目能复用;输出 runbook.md。
9. 人工复核:列出引用、统计、图表、结论和敏感数据的待核验项;输出 review/items_to_verify.md。
10. 归档复现:生成 README、环境记录、输入输出索引和变更日志,确保另一位同事能从空 output/ 重跑。
本节结论:最推荐的第一个案例,是用公开论文和脱敏数据生成一个可复核的 mini project,而不是让 Agent 接管整个课题。
建议案例目录:
□ papers/:3 篇公开论文 PDF
□ data/:一份脱敏 CSV
□ scripts/:已有或空白分析脚本
□ output/:证据表、质控报告、图表、Methods 草稿、README
□ review/:人工复核记录和错误日志
完整任务提示词:
请把当前目录处理成一个可复现的科研 mini project。 边界:只读 papers/、data/、scripts/;只写 output/ 和 review/;任何安装依赖、联网、删除文件都必须先询问。 输出: 1. output/evidence.md:论文证据表; 2. output/qc_report.md:数据质控报告; 3. scripts/analysis.py:最小分析脚本; 4. output/figure.png 和 figure_caption.md; 5. output/methods_draft.md; 6. README.md:复现步骤; 7. review/items_to_verify.md:需要人工核验的条目。本节结论:CLI Agent 的输出必须按文件、数据、图表、统计和文字逐项验收,不能只看它说“完成了”。
验收清单:
□ 证据表每条结论都有来源定位。
□ 数据质控报告没有猜测列名含义。
□ 脚本能从空 output/ 重新运行。
□ 图表轴、单位、分组、样本量正确。
□ Methods 不包含脚本里没有执行过的方法。
□ README 能让另一个人重跑。
本节结论:Antigravity CLI 的优势是多 Agent 和统一 harness,风险是误操作、权限边界和生态迁移成本。
适合优先使用 Antigravity CLI 的场景
多文件科研项目、需要后台执行、多步骤自动化、需要 Skills/Hooks/Subagents/Plugins 组织任务的工作流。
仍然可以用 Codex/Claude Code 的场景
代码仓库修复、测试驱动修改、审查 diff、强调局部代码质量的任务。科研人可以按项目选择,不必迷信单一工具。
最大提醒
不要让任何 CLI Agent 直接处理未脱敏敏感数据;不要自动接受文件修改;不要让 AI 替你确认统计和实验结论。
科研效率 AI 工具箱 · 用 AI 做科研的效率工具
文献整理 · 数据质控 · 图表生成 · 多 Agent 自动化
点击文末「阅读原文」直接使用 AI 专家 / 捞仔 AI 小站
关注「AI-For-Precision-Health」 | 每天一篇 AI 科研实操干货
食品 · 医药 · 器械 · AI 工具 · 科研 Skill · 科研自动化,让 AI 真正帮你做科研。
*使用 AI 工具处理科研数据前,请先完成数据脱敏、权限确认和命令审查。
参考文献
[1] Google Antigravity CLI features. Accessed 2026-06-29. https://antigravity.google/docs/cli-features
[2] Google Antigravity Agent Skills. Accessed 2026-06-29. https://antigravity.google/docs/skills
[3] Google Antigravity Plugins & Skills. Accessed 2026-06-29. https://antigravity.google/docs/cli-plugins
[4] Google Antigravity Prompting. Accessed 2026-06-29. https://antigravity.google/docs/cli-prompting
[5] Google Antigravity CLI Reference. Accessed 2026-06-29. https://antigravity.google/docs/cli-reference
