 夜雨聆风
夜雨聆风从 NotebookLM 到 MinerU,三个小时、八个坑、一个拖拽就能用的工具。
最近在加强建筑施工安全知识的学习,找到了一本非常好的资料。

没有出版社,没有作者,只有一个 PDF 文件。
我在电脑上翻了几天,觉得不行——这么好的东西,零零散散地看太浪费了。我得把它变成 Obsidian 里的个人知识库,能搜索、能链接、能和其他笔记串在一起。
然后就开始了。
第一反应:AI 帮我读
我最先想到的是 NotebookLM,谷歌那个。
把 PDF 传上去,它的理解和归纳能力确实很强——几秒钟就能给你一个结构清晰的摘要,关键知识点也能提炼出来。我用它做了几个章节的个人知识库 MD 文件,甚至尝试让它整了几个演示文稿 PPT。
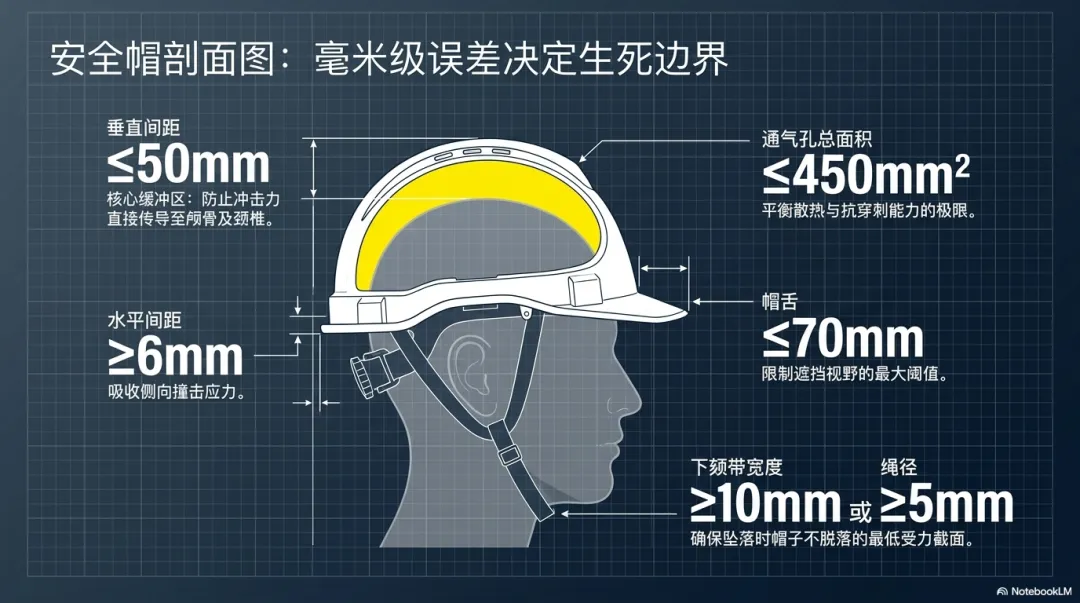

但问题很快就出现了:还原度不够。
NotebookLM 擅长的是"理解之后重新表达",不是"忠实还原原文"。它给你的摘要看起来都对,但你把原文翻开对照,就会发现一些关键数据、具体参数、操作细节——那些真正在工地上有用的东西——要么被省略了,要么被改写了。
这不行。做知识库,我要的是原文的完整性,不是 AI 的二次创作。
第二反应:自己转
那就自己来。把 PDF 直接转成文字,再手动整理成 Markdown 放进 Obsidian。
我以为这件事很简单——PDF 转文字而已,网上工具一大堆。
昨天试了很多种方法。在线工具、本地软件、PDF 提取库,结果没有一个能让人满意的。要么排版全乱,要么图片丢失,要么中文识别一塌糊涂。有些工具看着功能很强大,但不知道是算法水土不服还是训练数据的问题,出来的结果完全不能用。
折腾了大半天,进度为零。
我甚至尝试了用 Claude Code 来解析。调了几种方法,每一种测试的时间都很长。得出的教训倒是值钱——以后做这种摸索性的工作,应该先用小样本测试,摸索出正确的工具和方法,再大规模调用。 方法论对了,但工具还没找到。
第三反应:MinerU
昨天晚上刷公众号,看到一篇文章推荐了一个叫 MinerU 的开源文档解析工具。
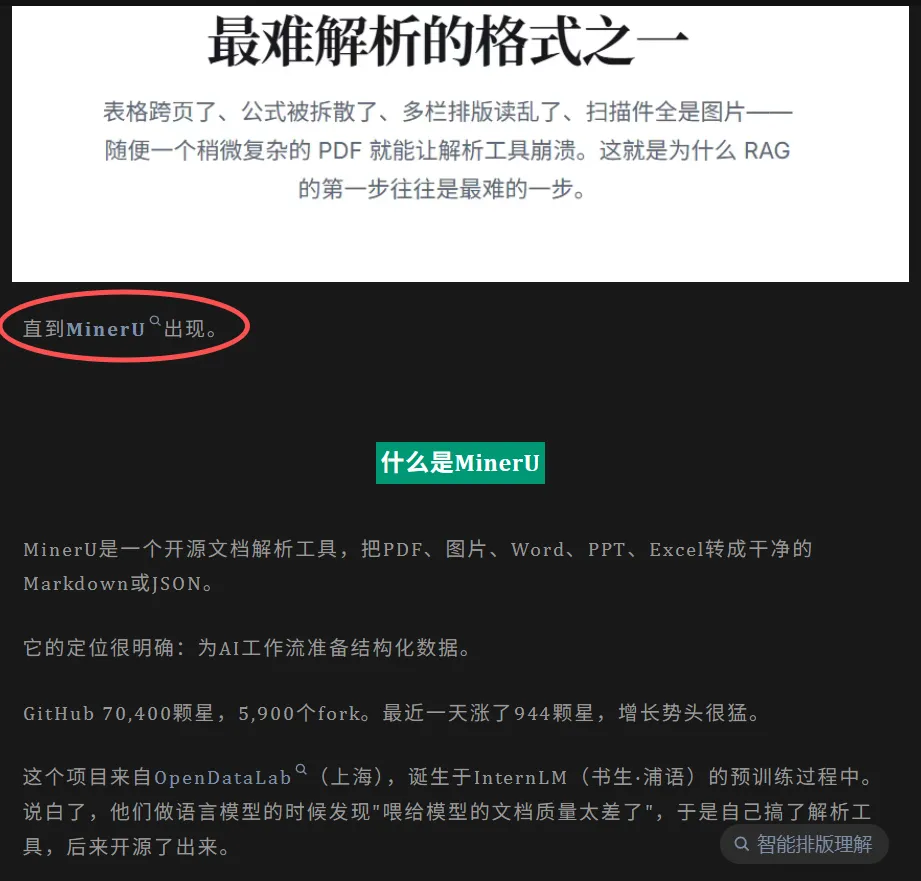
开源,专注 PDF 转 Markdown,能保留排版结构、提取图片、识别表格公式。看介绍是专门为知识库和 RAG(检索增强生成)场景设计的——这简直是我要的东西。
今天午睡后,开干。
手搓的三个小时
我以为装个开源工具就一行 pip install 的事。
实际花了三个小时,踩了八个坑。我把它拉出来给你看:
坑一:Python 3.14 不兼容。 我的系统 Python 是最新的 3.14,MinerU 最高只支持 3.13。重新装 Python 3.12。
坑二:用 uv 创建的虚拟环境缺 DLL。 uv 下载的 standalone Python 在我这个 Windows 11 版本上不完整,Python 能跑但 _ctypes 模块加载失败,MinerU 起不来。改用 winget 安装官方 Python。
坑三:onnxruntime 版本 bug。 最新版 1.27.0 在这台机器上 DLL 加载失败。降级到 1.20.1 解决。
坑四:HuggingFace 直连超时。 模型要从 huggingface.co 下载 13 个文件,国内网络直连全部超时。
坑五:HuggingFace 镜像 Xet bridge 超时。 换了国内的 hf-mirror.com,小文件秒下,但最大的模型文件(2.31GB)被重定向到国外的 Xet bridge CDN,照样超时。
坑六:两个模型结构还不一样。 折腾半天发现 MinerU 有两个后端——hybrid 后端需要 GPU(我没有),pipeline 后端用 CPU 但需要另一个 6.5GB 的模型。从 ModelScope 手动下载,两个模型加起来快 9 个 G,下载就用了一个多小时。
坑七:ModelScope 和 HuggingFace 的缓存目录结构不兼容。 手动创建目录、复制文件、建符号链接——这些平时写代码不屑于做的体力活,今天一样没少。
坑八:也是最隐蔽的一个——Windows 用户名里的中文。
我的 Windows 用户名是"三思",路径是 C:\Users\三思\。MinerU 的 FastText 语言检测模块在加载模型时调用了一个 C++ 扩展,而这个 C++ 库的 fopen 函数无法处理含中文字符的 Windows 路径。
文件确实存在,大小也正常,Python 层一切正常——但底层 C++ 就是打不开它。这个 bug 的排查过程最折磨人:你看到的所有信息都告诉你"东西没问题",但它就是不行。
最后找到根因:把模型文件复制到 C:/tmp/(纯 ASCII 路径),问题瞬间消失。然后手动改了 fast_langdetect 的源码,加了一个自动回退逻辑——如果原始路径加载失败,自动复制到 C:/tmp/ 再加载。
三个小时后
Processing pages: 5/5
Completed batch 1/1 | Processed 5/5 pages
成功了。5 页的测试 PDF,8 秒钟解析完成。
输出目录里安安静静躺着:
test.md—— Markdown 正文,排版结构完整 images/—— 提取出来的所有图片 test_layout.pdf—— 版面分析可视化 test_content_list.json—— 结构化内容数据
那一刻的感觉很奇妙。不是"AI 好强大"的感觉——因为 AI 只负责了里面的版面分析和 OCR,其他所有步骤都是人类在爬坑。是一种"我终于把这个东西搞定了"的感觉。
工具化
能用是能用了,但每次都要激活虚拟环境、设置环境变量、输入完整路径——这一套下来谁记得住。
就又花了二十分钟,做了三件事:
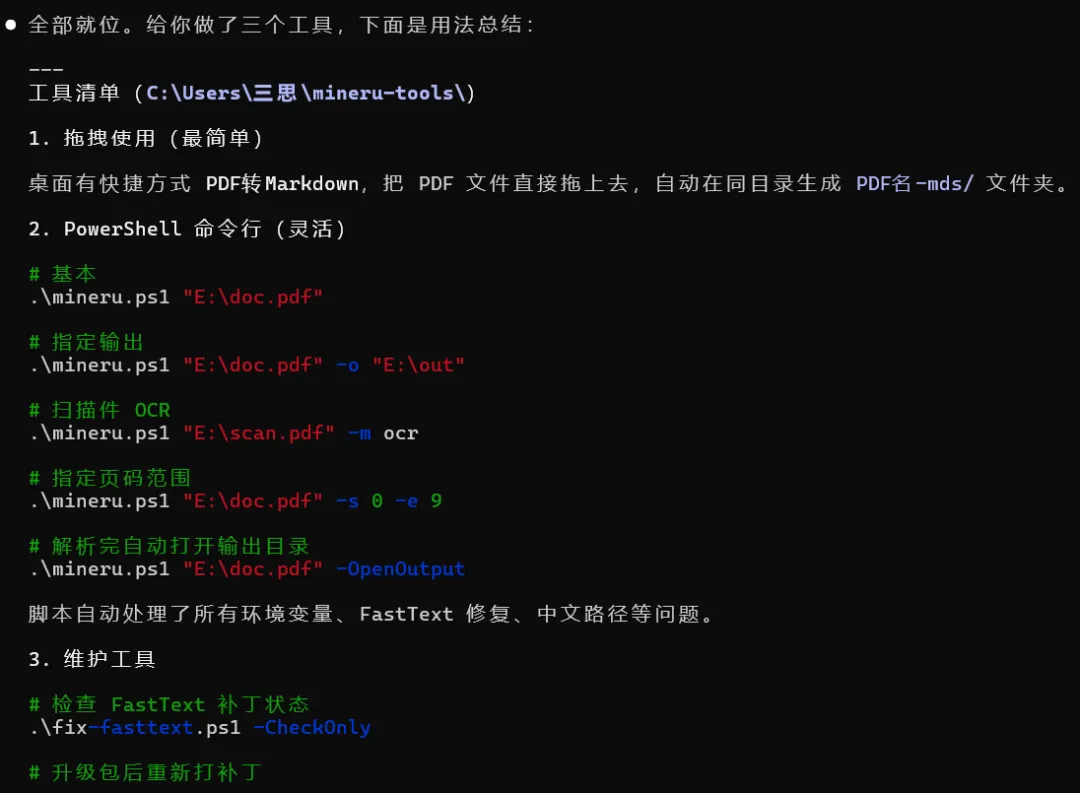
写了一个 PowerShell 封装脚本。 把所有环境变量、FastText 修复、路径处理全包进去。一行命令搞定:
.\mineru.ps1 "E:\doc.pdf"
做了一个拖拽快捷方式。 桌面放一个图标"PDF 转 Markdown",把 PDF 拖上去,松手,几秒钟后自动在同目录生成结果并打开文件夹。零命令,零配置。
写了一个补丁维护脚本。 万一 pip install --upgrade 更新了 fast-langdetect,运行一下自动重新打中文路径的补丁。
从此刻起,MinuerU 在我手上的使用成本降到零。拖一下,等几秒,Markdown 就有了。
最后
今天这件事让我想明白一个道理:工具和成品之间的距离,往往是踩坑填坑的一整个下午。
网上介绍 MinerU 的文章很多——"一行命令安装""强大的 PDF 解析工具""支持多种输出格式"。这些都没错。但没有人告诉你 Python 版本不兼容怎么办,没有人告诉你中文用户名会让 C++ 库崩溃怎么办,没有人告诉你国内下载模型要走什么路径。
这些东西,只有你真的动手去装、去用、去解决一个又一个看起来像死胡同的问题之后,才知道。
但正是这些东西,是你和"只是看看文章"的人之间真正的差距。
今天手搓了三个小时。但以后每天用的时候,只要三秒。
值。
本文基于 2026 年 7 月 5 日 MinerU 安装使用完整记录。MinerU 是 opendatalab 开源的 PDF 文档解析工具,GitHub: github.com/opendatalab/MinerU。
