




















文档内容
第 02 讲 成对数据的统计分析
(模拟精练+真题演练)
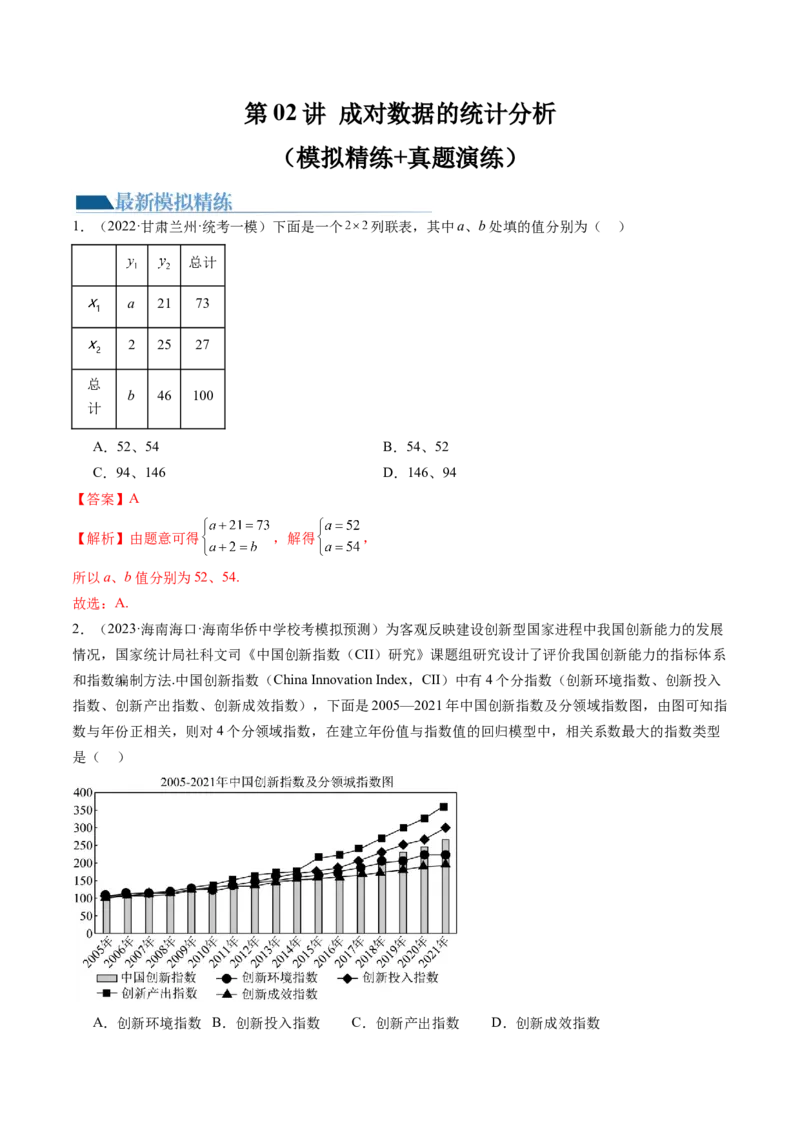
1.(2022·甘肃兰州·统考一模)下面是一个 列联表,其中a、b处填的值分别为( )
总计
a 21 73
2 25 27
总
b 46 100
计
A.52、54 B.54、52
C.94、146 D.146、94
【答案】A
【解析】由题意可得 ,解得 ,
所以a、b值分别为52、54.
故选:A.
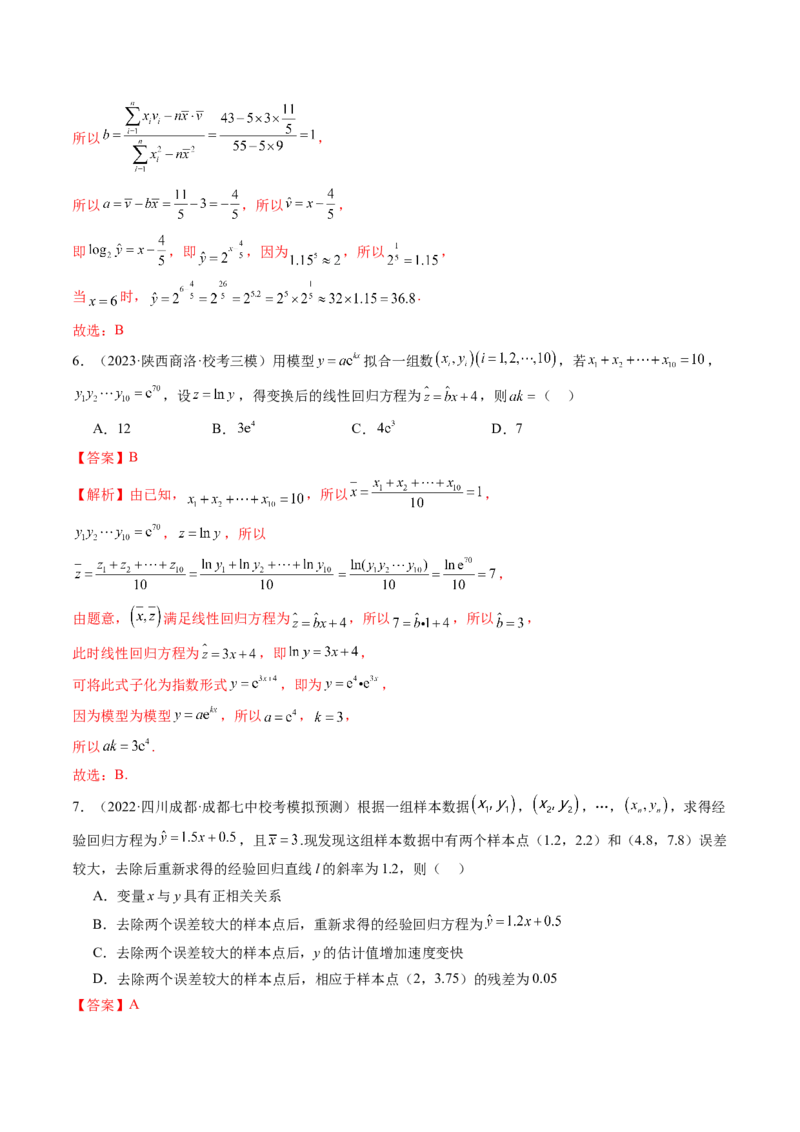
2.(2023·海南海口·海南华侨中学校考模拟预测)为客观反映建设创新型国家进程中我国创新能力的发展
情况,国家统计局社科文司《中国创新指数(CII)研究》课题组研究设计了评价我国创新能力的指标体系
和指数编制方法.中国创新指数(China Innovation Index,CII)中有4个分指数(创新环境指数、创新投入
指数、创新产出指数、创新成效指数),下面是2005—2021年中国创新指数及分领域指数图,由图可知指
数与年份正相关,则对4个分领域指数,在建立年份值与指数值的回归模型中,相关系数最大的指数类型
是( )
A.创新环境指数 B.创新投入指数 C.创新产出指数 D.创新成效指数【答案】D
【解析】由题图易知4个分领域指数的起始位置相同,其中创新投入指数、创新产出指数从2014年起,指
数增幅大,变化趋势明显大于另两类指数;
从2011年起,创新环境指数的波动幅度比创新成效指数的波动幅度大,创新成效指数对应的散点更趋近于
某一条直线,故其对应的相关系数最大.
故选:D.
3.(2023·安徽六安·六安一中校考模拟预测)某学校一同学研究温差 (℃)与本校当天新增感冒人数
(人)的关系,该同学记录了5天的数据:
x 5 6 8 9 12
1 2
y 20 28 35
7 5
经过拟合,发现基本符合经验回归方程 ,则下列结论错误的是( )
A.样本中心点为
B.
C. 时,残差为
D.若去掉样本点 ,则样本的相关系数 增大
【答案】D
【解析】对于A项,因为 , ,
所以样本中心点为 ,故A项正确;
对于B项,由回归直线必过样本中心可得: ,解得: ,故B项正确;
对于C项,由B项知, ,
令 ,则 ,
所以残差为 ,故C项正确;
对于D项,由相关系数公式可知,去掉样本点 后,x与y的样本相关系数r不变,故D项错误.
故选:D.
4.(2023·江西南昌·江西师大附中校考三模)下列说法:
(1)分类变量 与 的随机变量 越大,说明 与 相关的把握性越大;
(2)以模型 去拟合一组数据时,为了求出回归方程,设 ,将其变换后得到线性方程
,则 的值分别是 和0.7;
(3)若随机变量 ,且 ,则 .
以上正确的个数是( )A.0 B.1 C.2 D.3
【答案】D
【解析】根据独立性检验原理,分类变量 与 的随机变量 越大,说明 与 相关的把握性越大,故
(1)正确;
由 ,两边取对数得 ,即 ,
设 ,可得 ,又 ,
∴ ,即 ,故(2)正确;
若随机变量 ,则正态曲线关于 对称,
则 ,故(3)正确,
所以正确的个数是3.
故选:D.
5.(2023·重庆·统考二模)设两个相关变量 和 分别满足下表:
若相关变量 和 可拟合为非线性回归方程 ,则当 时, 的估计值为( )
(参考公式:对于一组数据 , , , ,其回归直线 的斜率和截距的最小
二乘估计公式分别为: , ; )
A. B. C. D.
【答案】B
【解析】因为非线性回归方程为: ,则有 ,
令 ,即 ,列出相关变量 关系如下:
0 1 3 3 4
所以 , ,
, ,所以 ,
所以 ,所以 ,
即 ,即 ,因为 ,所以 ,
当 时, .
故选:B
6.(2023·陕西商洛·校考三模)用模型 拟合一组数 ,若 ,
,设 ,得变换后的线性回归方程为 ,则 ( )
A.12 B. C. D.7
【答案】B
【解析】由已知, ,所以 ,
, ,所以
,
由题意, 满足线性回归方程为 ,所以 ,所以 ,
此时线性回归方程为 ,即 ,
可将此式子化为指数形式 ,即为 ,
因为模型为模型 ,所以 , ,
所以 .
故选:B.
7.(2022·四川成都·成都七中校考模拟预测)根据一组样本数据 , ,…, ,求得经
验回归方程为 ,且 .现发现这组样本数据中有两个样本点(1.2,2.2)和(4.8,7.8)误差
较大,去除后重新求得的经验回归直线l的斜率为1.2,则( )
A.变量x与y具有正相关关系
B.去除两个误差较大的样本点后,重新求得的经验回归方程为
C.去除两个误差较大的样本点后,y的估计值增加速度变快
D.去除两个误差较大的样本点后,相应于样本点(2,3.75)的残差为0.05
【答案】A【解析】对A: 经验回归方程为 , ,
变量 与 具有正相关关系,故选项A正确;
对B:当 时, ,所以样本中心为 ,
去掉两个样本点为 和 , , ,
样本中心不变,
去除后重新求得的经验回归直线 的斜率为1.2,
,解得 ,
故去除两个误差较大的样本点后,重新求得的回归方程为 ,故选项B错误;
对C: ,
去除两个误差较大的样本点后, 的估计值增加速度变慢,故选项C错误;
对D: ,
,
去除两个误差较大的样本点后,相应于样本点(2,3.75)的残差为 ,故选项D错误.
故选:A.
8.(2021·江西南昌·南昌市八一中学校考三模)已知变量 关于 的回归方程为 ,其一组数据如
表所示:若 ,则预测 值可能为( )
A. B. C. D.
【答案】D
【解析】由 得: , ,
解得: , 回归方程为 ,若 ,则 .
故选:D.
9.(2021·山西·统考三模)某公交公司推出扫码支付乘车优惠活动,活动为期两周,活动的前五天数据如
下表:
第 天 1 2 3 4 5
84
使用人数( ) 15 173 457 1333
2
由表中数据可得y关于x的回归方程为 ,则据此回归模型相应于点(2,173)的残差为( )
A. B. C.3 D.2【答案】B
【解析】令 ,则 ,
1 4 9 16 25
84
使用人数( ) 15 173 457 1333
2
, ,
所以 ,
所以 ,
当 时, ,
所以残差为 .
故选:B
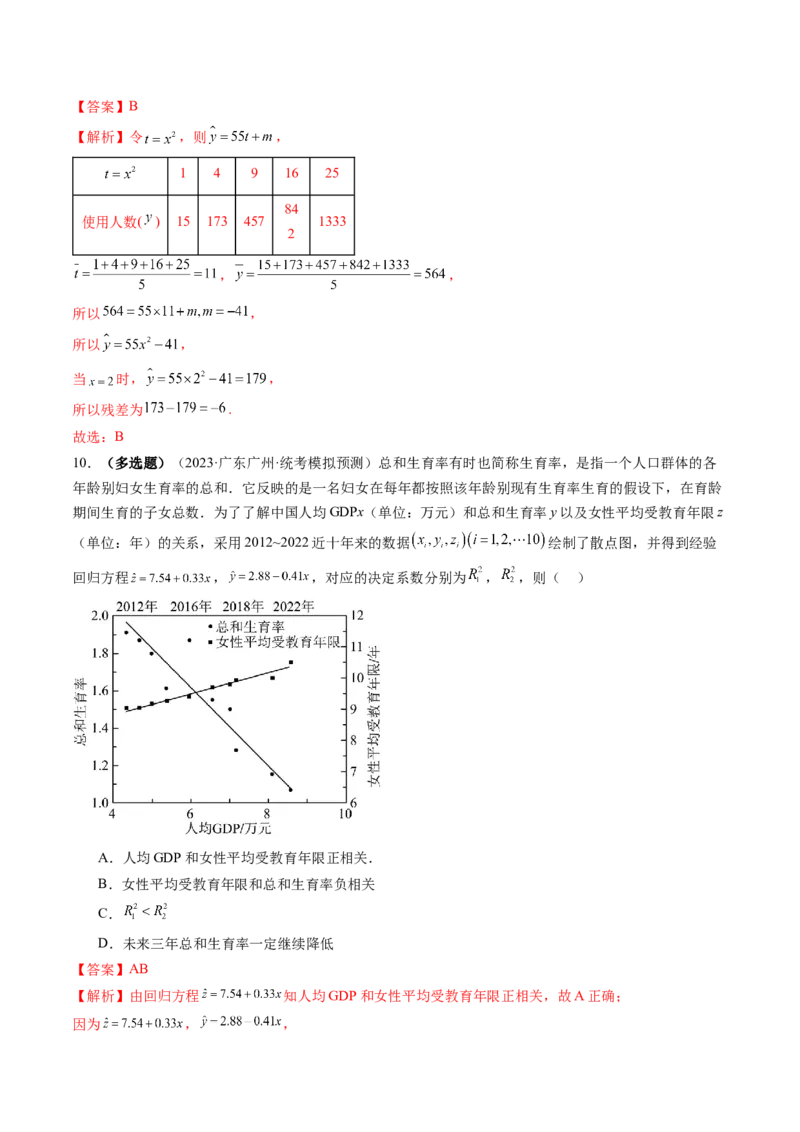
10.(多选题)(2023·广东广州·统考模拟预测)总和生育率有时也简称生育率,是指一个人口群体的各
年龄别妇女生育率的总和.它反映的是一名妇女在每年都按照该年龄别现有生育率生育的假设下,在育龄
期间生育的子女总数.为了了解中国人均GDPx(单位:万元)和总和生育率y以及女性平均受教育年限z
(单位:年)的关系,采用2012~2022近十年来的数据 绘制了散点图,并得到经验
回归方程 , ,对应的决定系数分别为 , ,则( )
A.人均GDP和女性平均受教育年限正相关.
B.女性平均受教育年限和总和生育率负相关
C.
D.未来三年总和生育率一定继续降低
【答案】AB
【解析】由回归方程 知人均GDP和女性平均受教育年限正相关,故A正确;
因为 , ,可得女性平均受教育年限z和总和生育率y的关系式为 ,
所以女性平均受教育年限z和总和生育率y负相关,故B正确;
由散点图可知,回归方程 相对 拟合效果更好,
所以 ,故C错误;
根据回归方程 预测,未来总和生育率预测值有可能降低,
但实际值不一定会降低,故D错误.
故选:AB
11.(多选题)(2023·江苏盐城·盐城市伍佑中学校考模拟预测)下列命题正确的是( )
A.对于事件A,B,若 ,且 , ,则
B.若随机变量 , ,则
C.相关系数r的绝对值越接近1,两个随机变量的线性相关程度越强
D.在做回归分析时,残差图中残差点分布的带状区域的宽度越宽表示回归效果越差
【答案】ACD
【解析】对于A,由于 ,即A发生必定有B发生,根据条件概率的定义 ,正确;
对于B,根据正态分布密度函数的性质知 ,
,错误;
对于C,根据相关系数的性质知: 约接近于1,表示线性相关程度越强,正确;
对于D,残差点分布的带状区域越宽说明线性回归时的误差越大,即回归效果越差,正确;
故选:ACD.
12.(多选题)(2023·吉林长春·长春吉大附中实验学校校考模拟预测) 年 月 日,工业和信息化
部成功举办第十七届“中国芯”集成电路产业大会.此次大会以“强芯固基以质为本”为主题,旨在培育
壮大我国集成电路产业,夯实产业基础、营造良好产业生态.某芯片研发单位用在“A芯片”上研发费用占
本单位总研发费用的百分比 如表所示. 已知 ,于是分别用p= 和p= 得到了两条回归直
线方程: , ,对应的相关系数分别为 、 ,百分比y对应的方差分别为 、 ,则
下列结论正确的是( )(附: , )
年份
年份代码
xp q
A. B. C. D.
【答案】ABC
【解析】 时, ,变量 、 呈线性正相关,故 ,故A正确;
方差反映数据的稳定性,显然 时更稳定,故此时方差更小,即 ,故B正确;
由于 ,当 时,
,
当 时, ,
所以 ,故C正确;
因为 ,所以 时, ,故D错误.
故选:ABC
13.(多选题)(2023·福建厦门·统考模拟预测)为了有针对性地提高学生体育锻炼的积极性,某中学需
要了解性别因素是否对本校学生体育锻的经常性有影响,随机抽取了300名学生,对他们是否经常锻炼的
情况进行了调查,调查发现经常锻炼人数是不经常锻炼人数的2倍,绘制其等高堆积条形图,如图所示,
则( )
A.参与调查的男生中经常锻炼的人数比不经常锻炼的人数多
B.从参与调查的学生中任取一人,已知该生为女生,则该生经常锻炼的概率为
C.依据 的独立性检验,认为性别因素影响学生体育锻炼的经常性,该推断犯错误的概率不超
过0.1
D.假设调查人数为600人,经常锻炼人数与不经常锻炼人数的比例不变,统计得到的等高堆积条形图
也不变,依据 的独立性检验,认为性别因素影响学生体育锻炼的经常性,该推断犯错误的概
率不超过0.05附: ,
0.1 0.05 0.01 0.005 0.001
2.706 3.841 6.635 7.879 10.828
【答案】ABD
【解析】对于A,由题意知经常锻炼人数是不经常锻炼人数的2倍,
故经常锻炼人数为200人,不经常锻炼人数为100人,
故男生中经常锻炼的人数为 人,不经常锻炼的人数为 人,
故男生中经常锻炼的人数比不经常锻炼的人数多,A正确;
对于B,经常锻炼的女生人数为 人,不经常锻炼的人数为 人,
故从参与调查的学生中任取一人,已知该生为女生,则该生经常锻炼的概率为 ,B正确;
对于C,由题意结合男女生中经常锻炼和不经常锻炼的人数,可得列联表:
经常锻
不经常锻炼 合计
炼
男 100 60 160
女 100 40 140
合计 200 100 300
则 ,
故依据 的独立性检验,不能认为性别因素影响学生体育锻炼的经常性,该推断犯错误的概率不超过
0.1,C错误;
对于D,由题意可得:
经常锻
不经常锻炼 合计
炼
男 200 120 320
女 200 80 280
合计 400 200 600
则此时 ,
故依据 的独立性检验,认为性别因素影响学生体育锻炼的经常性,该推断犯错误的概率不超过
0.05,D正确,故选:ABD
14.(2023·全国·镇海中学校联考模拟预测)害虫防控对于提高农作物产量具有重要意义.已知某种害虫产
卵数 (单位:个)与温度 (单位: )有关,测得一组数据 ,可用模型
进行拟合,利用 变换得到的线性回归方程为 .若 ,则 的值为
.
【答案】
【解析】对 两边同时取对数可得 ;
即 ,可得
由 可得 ,
代入 可得 ,即 ,所以 .
故答案为:
15.(2023·上海·统考模拟预测)某校团委对“学生性别和喜欢网络游戏是否有关”作了一次调查,其中
被调查的男女生人数相同,男生喜欢网络游戏的人数占男生人数的 ,女生喜欢网络游戏的人数占女生人
数的 .若根据独立性检验认为喜欢网络游戏和性别有关,且此推断犯错误的概率超过0.01但不超过0.05,
则被调查的学生中男生可能有 人.(请将所有可能的结果都填在横线上)
附表: ,其中 .
0.050 0.010
3.841 6.635
【答案】45,50,55,60,65
【解析】设男生有x人,由题意可得 列联表如下,
喜欢 不喜欢 合计
男生 x
女生 x
合计
若认为喜欢网络游戏和性别有关,且该推断犯错误的概率超过0.01但不超过0.05,则 .
∵ ,
∴ ,解得 ,
又x为5的整数倍,∴被调查的学生中男生可能人数为45,50,55,60,65.
故答案为:45,50,55,60,65.
16.(2023·广西桂林·校联考模拟预测)一只红铃虫产卵数 和温度 有关,现测得一组数据
,可用模型 拟合,设 ,其变换后的线性回归方程为 ,若
, , 为自然常数,则 .
【答案】
【解析】 经过 变换后,得到 ,根据题意 ,故 ,又
,故 , ,故 ,于是回归方程为
一定经过 ,故 ,解得 ,即 ,于是 .
故答案为: .
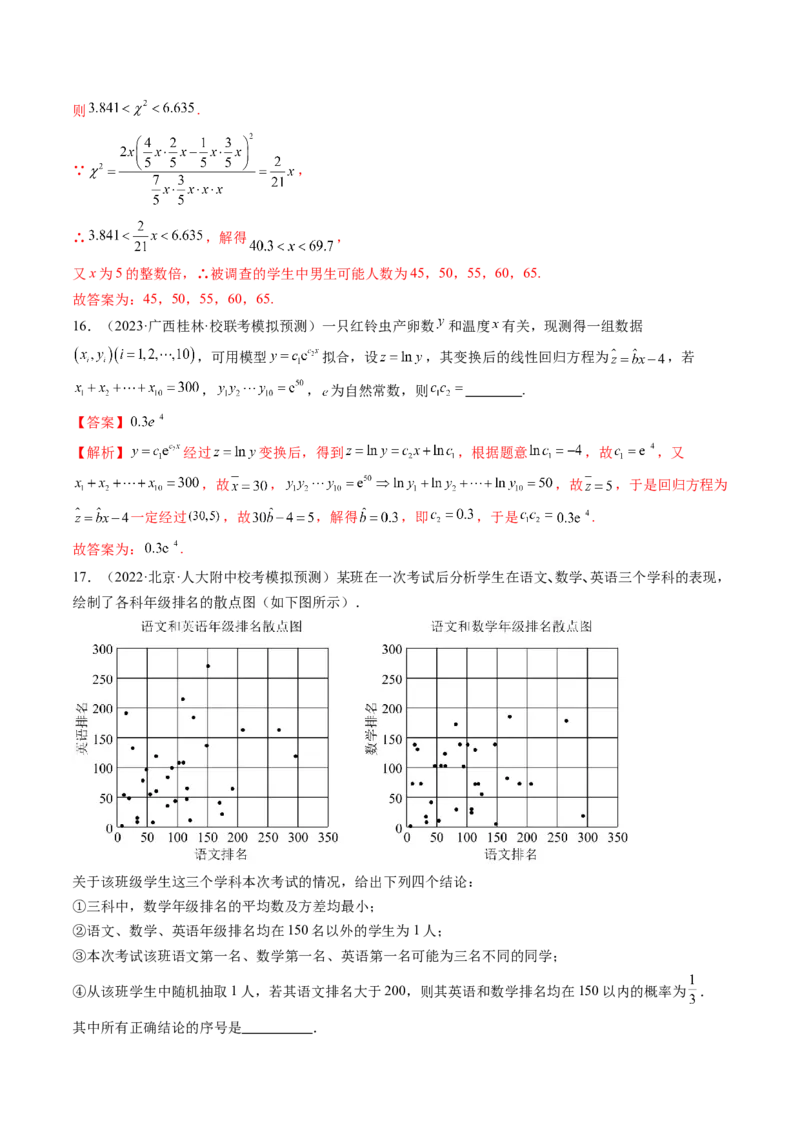
17.(2022·北京·人大附中校考模拟预测)某班在一次考试后分析学生在语文、数学、英语三个学科的表现,
绘制了各科年级排名的散点图(如下图所示).
关于该班级学生这三个学科本次考试的情况,给出下列四个结论:
①三科中,数学年级排名的平均数及方差均最小;
②语文、数学、英语年级排名均在150名以外的学生为1人;
③本次考试该班语文第一名、数学第一名、英语第一名可能为三名不同的同学;
④从该班学生中随机抽取1人,若其语文排名大于200,则其英语和数学排名均在150以内的概率为 .
其中所有正确结论的序号是 .【答案】①②④
【解析】①:三科中,数学对应的点比英语对应的点到横轴的距离近且较为密集,
数学对应的点到横轴的距离比语文对应的点到纵轴距离近且较为密集,
所以数学年级排名的平均数及方差均最小.判断正确;
②:语文、数学、英语年级排名均在150名以外的学生为1人.判断正确;
③:本次考试该班语文第一名、数学第一名、英语第一名为同一名同学.判断错误;
④:由图表可知语文排名大于200的有3位同学,
语文排名大于200且英语和数学排名均在150以内的同学仅有1位同学.
故从该班学生中随机抽取1人,若其语文排名大于200,
则其英语和数学排名均在150以内的概率为 .判断正确.
故答案为①②④
18.(2022·安徽安庆·安庆一中校考三模)在工程技术和科学实验中,经常利用最小二乘法原理求曲线的
函数关系式:设有一组实验数据 ,它们大体分布在某条曲线上,通过偏差平方和最
小求该曲线的方法称为最小二乘法,当该曲线为一条直线 时,由方程组
来确定 , 的值,此时偏差平方和表示为 .为了测定某种
刀具的磨损速度,每隔1小时测一次刀具的厚度,得到一组实验数据,如下表:
顺序编号i 0 1 2 3 4 5 6 7
时间 0 1 2 3 4 5 6 7
刀具厚度
作出刀具厚度 关于时间 散点图,发现这些点分布在一条直线 附近.
(1)求实数 , 的值,并估计 时刀具厚度(所有结果均精确到 );
(2)求偏差平方和.(参考数据: , )
【解析】(1)由条件可得, 应满足 ,
其中 ,可由 得到,
且 , , ,
即 ,解得 ,
所以该直线方程为 ,
当 时,则
所以,刀具的厚度为 .
(2)由题意可得,偏差平方和为
.
19.(2023·湖北武汉·华中师大一附中校考模拟预测)2021年春节前,受疫情影响,各地鼓励外来务工人
员选择就地过年.某市统计了该市4个地区的外来务工人数与就地过年人数(单位:万),得到如下表格:
区 区 区
区
外来务工人数 万 3 4 5 6
就地过年人数 万 2.5 3 4 4.5
(1)请用相关系数说明 与 之间的关系可用线性回归模型拟合,并求 关于 的线性回归方程 和
A区的残差
(2)假设该市政府对外来务工人员中选择就地过年的每人发放1000元补贴.
①若该市 区有2万名外来务工人员,根据(1)的结论估计该市政府需要给 区就地过年的人员发放的补
贴总金额;
②若 区的外来务工人员中甲、乙选择就地过年的概率分别为 ,其中 ,该市政府对甲、
乙两人的补贴总金额的期望不超过1400元,求 的取值范围.
参考公式:相关系数 ,
回归方程 中斜率和截距的最小二乘估计公式分别为 .【解析】(1)由题, ,
,
, ,
所以相关系数 ,
因为 与 之间的相关系数近似为0.99,说明 与 之间的线性相关程度非常强,
所以可用线性回归模型拟合 与 之间的关系.
,
故 关于 的线性回归方程为 .
∵ ,∴ ,故A区的残差为0.05.
(2)(2)①将 代入 ,得 ,
故估计该市政府需要给 区就地过年的人员发放的补贴总金额为 (万元).
②设甲、乙两人中选择就地过年的人数为 ,则 的所有可能取值为0,1,2,
,
,
.
所以 ,
所以 ,
由 ,得 ,又 ,所以 ,
故 的取值范围为 .
20.(2023·江西南昌·南昌市八一中学校考三模)为了解某一地区电动汽车销售情况,某机构根据统计数
据,用最小二乘法得到电动汽车销量 单位:万台 关于 年份 的线性回归方程为 ,且
销量 的方差 ,年份 的方差为 .
(1)求 与 的相关系数 ,并据此判断电动汽车销量 与年份 的相关性强弱;
(2)该机构还调查了该地区 位购车车主性别与购车种类情况,得到的数据如下表:
购买电动汽
购买非电动汽车 总计
车男性
女性
总计
能否有 的把握认为购买电动汽车与性别有关
(3)在购买电动汽车的车主中按照性别进行分层抽样抽取 人,再从这 人中随机抽取 人,记这 人中,
男性的人数为 ,求 的分布列和数学期望.
参考公式: 线性回归方程: ,其中 , ;
相关系数: ,若 ,则可判断 与 线性相关较强;
,其中 .
附表:
【解析】(1)相关系数为
所以 ,故 与 线性相关较强.
(2)零假设为 :购买电动汽车与车主性别相互独立,即购买电动汽车与车主性别无关.
,
所以依据小概率值 的独立性检验,我们推断 不成立.
由此推断犯错误的概率不大于 ,故有 的把握认为购买电动汽车与性别有关.
(3) 人中,男性车主 人,女性车主 人,
则 的可能取值为 , , , , ,故故 的分布列为:
0 1 2 3 4
21.(2023·福建南平·统考模拟预测)五一小长假期间,文旅部门在某地区推出A,B,C,D,E,F六款
不同价位的旅游套票,每款套票的价格 (单位:元; )与购买该款套票的人数 (单位:千
人)的数据如下表:
套票类别 A B C D E F
套票价格 (元) 40 50 60 65 72 88
购买人数 (千
16.9 18.7 20.6 22.5 24.1 25.2
人)
(注:A,B,C,D,E,F对应i的值为1,2,3,4,5,6)为了分析数据,令 , ,发现
点 集中在一条直线附近.
(1)根据所给数据,建立购买人数y关于套票价格x的回归方程;
(2)规定:当购买某款套票的人数y与该款套票价格x的比值在区间 上时,该套票为“热门套票”.
现有甲、乙、丙三人分别从以上六款旅游套票中购买一款.假设他们买到的套票的款式互不相同,且购买
到“热门套票”的人数为X,求随机变量X的分布列和期望.
附:①参考数据: , , , .
②对于一组数据 ,其回归直线 的斜率和截距的最小二乘估计分别为
, .
【解析】(1)由已知点 集中在一条直线附近,设回归直线方程为 ,由 , , ,
得 , ,
因此变量 关于 的回归方程为 ,
令 ,则 ,即 ,
所以 关于 的回归方程为 .
(2)由 ,解得 ,所以 ,
于是 为“热门套票”,则三人中购买“热门套票”的人数 服从超几何分布, 的可能取值为
1,2,3,
,
所以 的分布列为:
1 2 3
期望 .
22.(2023·上海浦东新·华师大二附中校考模拟预测)为帮助乡村脱贫,某勘探队计划了解当地矿脉某金
属的分布情况,测得了平均金属含量 (单位: )与样本对原点的距离 (单位: )的数据,并
作了初步处理,得到了下面的一些统计量的值.(表中 )
6 60
(1)利用样本相关系数的知识,判断 与 哪一个更适宜作为平均金属含量 关于样本对原点
的距离 的回归方程类型?
(2)根据(1)的结果回答下列问题:(i)建立 关于 的回归方程;
(ii)样本对原点的距离 时,金属含量的预报值是多少?
(3)已知该金属在距离原点 米时的平均开采成本 (单位:元)与 关系为 ,
根据(2)的结果回答, 为何值时,开采成本最大?
【解析】(1)因为 的线性相关系数 ,
的线性相关系数 ,
,
更适宜作为平均金属含量 关于样本对原点的距离 的回归方程类型.
(2)(i)依题意,可得 ,
,
, 关于 的回归方程为 .
(ii)当 时,金属含量的预报值为 .
(3)因为 ,
令 ,则 ,
当 时, , 在 上单调递增;
当 时, , 在 上单调递减,
在 处取得极大值,也是最大值,此时 取得最大值,
故 为10时,开采成本最大.
1.(2023•天津)调查某种花萼长度和花瓣长度,所得数据如图所示,其中相关系数 ,下列说法正确的是
A.花瓣长度和花萼长度没有相关性
B.花瓣长度和花萼长度呈现负相关
C.花瓣长度和花萼长度呈现正相关
D.若从样本中抽取一部分,则这部分的相关系数一定是0.8245
【答案】
【解析】 相关系数 ,且散点图呈左下角到右上角的带状分布,
花瓣长度和花萼长度呈正相关.
若从样本中抽取一部分,则这部分的相关系数不一定是0.8245.
故选: .
2.(2023•甲卷)一项试验旨在研究臭氧效应,试验方案如下:选40只小白鼠,随机地将其中20只分配
到试验组,另外20只分配到对照组,试验组的小白鼠饲养在高浓度臭氧环境,对照组的小白鼠饲养在正常
环境,一段时间后统计每只小白鼠体重的增加量(单位: .试验结果如下:
对照组的小白鼠体重的增加量从小到大排序为
15.2 18.8 20.2 21.3 22.5 23.2 25.8 26.5 27.5 30.1
32.6 34.3 34.8 35.6 35.6 35.8 36.2 37.3 40.5 43.2
试验组的小白鼠体重的增加量从小到大排序为
7.8 9.2 11.4 12.4 13.2 15.5 16.5 18.0 18.8 19.2
19.8 20.2 21.6 22.8 23.6 23.9 25.1 28.2 32.3 36.5
(1)计算试验组的样本平均数;
(2)(ⅰ)求40只小白鼠体重的增加量的中位数 ,再分别统计两样本中小于 与不小于 的数据的个
数,完成如下列联表;
对照组
试验组
(ⅱ)根据 中的列联表,能否有 的把握认为小白鼠在高浓度臭氧环境中与在正常环境中体重的增
加量有差异?
附: ,0.100 0.050 0.010
2.706 3.841 6.635
【解析】(1)根据题意,计算试验组样本平均数为
.
(2) 由题意知,这40只小鼠体重的中位数是将两组数据合在一起,从小到大排列后第 20位与第21位
数据的平均数,
因为原数据的第11位数据是18.8,后续依次为19.2,19.8,20.2,20.2,21.3,21.6,22.5,22.8,23.2,
23.6, ,
所以第20位为23.2,第21位数据为23.6,
所以这组数据的中位数是 ;
填写列联表如下:
合计
对照组 6 14 20
试验组 14 6 20
合计 20 20 40
根据列联表中数据,计算 ,
所以有 的把握认为小白鼠在高浓度臭氧环境中与在正常环境中体重的增加量有差异.
3.(2022•新高考Ⅰ)一医疗团队为研究某地的一种地方性疾病与当地居民的卫生习惯(卫生习惯分为良
好和不够良好两类)的关系,在已患该疾病的病例中随机调查了 100例(称为病例组),同时在未患该疾
病的人群中随机调查了100人(称为对照组),得到如下数据:
不够良好 良好
病例组 40 60
对照组 10 90
(1)能否有 的把握认为患该疾病群体与未患该疾病群体的卫生习惯有差异?
(2)从该地的人群中任选一人, 表示事件“选到的人卫生习惯不够良好”, 表示事件“选到的人患
有该疾病”, 与 的比值是卫生习惯不够良好对患该疾病风险程度的一项度量指标,记该
指标为 .
(ⅰ)证明: ;
(ⅱ)利用该调查数据,给出 , 的估计值,并利用(ⅰ)的结果给出 的估计值.附: .
0.050 0.010 0.001
3.841 6.635 10.828
【解析】(1)补充列联表为:
不够良好 良好 合计
病例组 40 60 100
对照组 10 90 100
合计 50 150 200
计算 ,
所以有 的把握认为患该疾病群体与未患该疾病群体的卫生习惯有差异.
( 2 ) 证 明 :
;
( ⅱ ) 利 用 调 查 数 据 , , , ,
,
所以 .
4.(2021•甲卷)甲、乙两台机床生产同种产品,产品按质量分为一级品和二级品,为了比较两台机床产
品的质量,分别用两台机床各生产了200件产品,产品的质量情况统计如下表:
一级品 二级品 合计
甲机床 150 50 200
乙机床 120 80 200
合计 270 130 400
(1)甲机床、乙机床生产的产品中一级品的频率分别是多少?
(2)能否有 的把握认为甲机床的产品质量与乙机床的产品质量有差异?
附: .
0.050 0.010 0.0013.841 6.635 10.828
【解析】(1)由题意可得,甲机床、乙机床生产总数均为200件,
因为甲的一级品的频数为150,所以甲的一级品的频率为 ;
因为乙的一级品的频数为120,所以乙的一级品的频率为 ;
(2)根据 列联表,可得
.
所以有 的把握认为甲机床的产品质量与乙机床的产品质量有差异.
5.(2020•新课标Ⅱ)某沙漠地区经过治理,生态系统得到很大改善,野生动物数量有所增加.为调查该
地区某种野生动物的数量,将其分成面积相近的200个地块,从这些地块中用简单随机抽样的方法抽取20
个作为样区,调查得到样本数据 , ,2, , ,其中 和 分别表示第 个样区的植物覆盖
面积(单位:公顷)和这种野生动物的数量,并计算得 , , ,
, .
(1)求该地区这种野生动物数量的估计值(这种野生动物数量的估计值等于样区这种野生动物数量的平
均数乘以地块数);
(2)求样本 , ,2, , 的相关系数(精确到 ;
(3)根据现有统计资料,各地块间植物覆盖面积差异很大.为提高样本的代表性以获得该地区这种野生
动物数量更准确地估计,请给出一种你认为更合理的抽样方法,并说明理由.
附:相关系数 , .
【解析】(1)由已知, ,
个样区野生动物数量的平均数为 ,
该地区这种野生动物数量的估计值为 ;
(2) , , ,;
(3)更合理的抽样方法是分层抽样,根据植物覆盖面积的大小对地块分层,再对200个地块进行分层抽样.
理由如下:由(2)知各样区的这种野生动物数量与植物覆盖面积有很强的正相关.由于各地块间植物覆
盖面积差异很大,从而各地块间这种野生动物数量差异也很大,采用分层抽样的方法较好地保持了样本结
构与总体结构的一致性,提高了样本的代表性,从而可以获得该地区这种野生动物数量更准确地估计.
6.(2020•新课标Ⅲ)某学生兴趣小组随机调查了某市100天中每天的空气质量等级和当天到某公园锻炼
的人次,整理数据得到下表(单位:天)
锻炼人次
, , ,
空气质量等级
2 16 25
1(优
5 10 12
2(良
3(轻度污染) 6 7 8
4(中度污染) 7 2 0
(1)分别估计该市一天的空气质量等级为1,2,3,4的概率;
(2)求一天中到该公园锻炼的平均人次的估计值(同一组中的数据用该组区间的中点值为代表);
(3)若某天的空气质量等级为1或2,则称这天“空气质量好”;若某天的空气质量等级为3或4,则称
这天“空气质量不好”.根据所给数据,完成下面的 列联表,并根据列联表,判断是否有 的把握
认为一天中到该公园锻炼的人次与该市当天的空气质量有关?
人次 人次
空气质量好
空气质量不好
附:
0.050 0.010 0.001
3.841 6.635 10.828
【解析】(1)该市一天的空气质量等级为1的概率为: ;
该市一天的空气质量等级为2的概率为: ;
该市一天的空气质量等级为3的概率为: ;该市一天的空气质量等级为4的概率为: ;
(2)由题意可得:一天中到该公园锻炼的平均人次的估计值为:
,
(3)根据所给数据,可得下面的 列联表,
人次 人次 总计
空气质量好 33 37 70
空气质量不好 22 8 30
总计 55 45 100
由表中数据可得: ,
所以有 的把握认为一天中到该公园锻炼的人次与该市当天的空气质量有关.
7.(2020•山东)为加强环境保护,治理空气污染,环境监测部门对某市空气质量进行调研,随机抽查了
100天空气中的 和 浓度(单位: ,得下表:
, , ,
32 18 4
,
6 8 12
,
3 7 10
,
(1)估计事件“该市一天空气中 浓度不超过75,且 浓度不超过150”的概率;
(2)根据所给数据,完成下面的 列联表:
, ,
,
,
(3)根据(2)中的列联表,判断是否有 的把握认为该市一天空气中 浓度与 浓度有关?
附:
0.050 0.010 0.001
3.841 6.635 10.828【解析】(1)用频率估计概率,从而得到“该市一天空气中 浓度不超过75,且 浓度不超过
150”的概率 ;
(2)根据所给数据,可得下面的 列联表:
(3)根据(2)中的列联表,
由 ,
;
故有 的把握认为该市一天空气中 浓度与 浓度有关,
8.(2019•新课标Ⅰ)某商场为提高服务质量,随机调查了50名男顾客和50名女顾客,每位顾客对该商
场的服务给出满意或不满意的评价,得到下面列联表:
满意 不满意
男顾客 40 10
女顾客 30 20
(1)分别估计男、女顾客对该商场服务满意的概率;
(2)能否有 的把握认为男、女顾客对该商场服务的评价有差异?
附: .
0.050 0.010 0.001
3.841 6.635 10.828
【解析】(1)由题中数据可知,男顾客对该商场服务满意的概率 ,
女顾客对该商场服务满意的概率 ;(2)由题意可知, ,
故有 的把握认为男、女顾客对该商场服务的评价有差异.
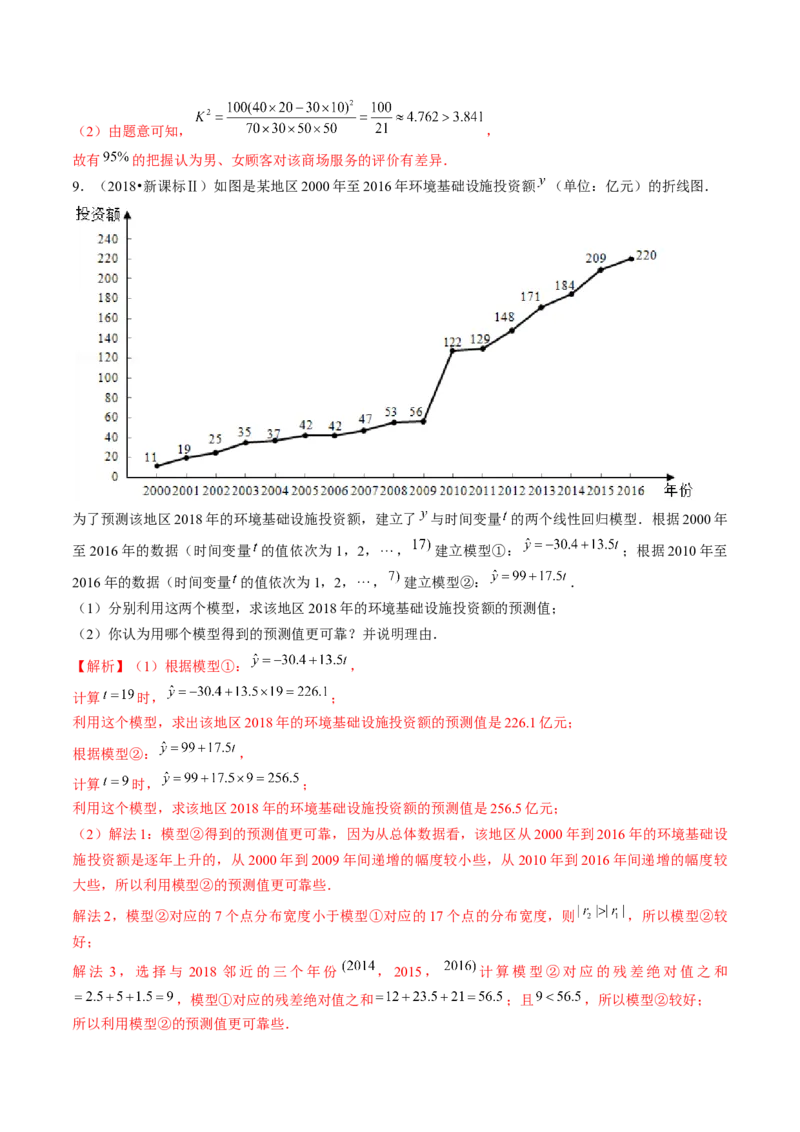
9.(2018•新课标Ⅱ)如图是某地区2000年至2016年环境基础设施投资额 (单位:亿元)的折线图.
为了预测该地区2018年的环境基础设施投资额,建立了 与时间变量 的两个线性回归模型.根据2000年
至2016年的数据(时间变量 的值依次为1,2, , 建立模型①: ;根据2010年至
2016年的数据(时间变量 的值依次为1,2, , 建立模型②: .
(1)分别利用这两个模型,求该地区2018年的环境基础设施投资额的预测值;
(2)你认为用哪个模型得到的预测值更可靠?并说明理由.
【解析】(1)根据模型①: ,
计算 时, ;
利用这个模型,求出该地区2018年的环境基础设施投资额的预测值是226.1亿元;
根据模型②: ,
计算 时, ;
利用这个模型,求该地区2018年的环境基础设施投资额的预测值是256.5亿元;
(2)解法1:模型②得到的预测值更可靠,因为从总体数据看,该地区从2000年到2016年的环境基础设
施投资额是逐年上升的,从2000年到2009年间递增的幅度较小些,从2010年到2016年间递增的幅度较
大些,所以利用模型②的预测值更可靠些.
解法2,模型②对应的7个点分布宽度小于模型①对应的17个点的分布宽度,则 ,所以模型②较
好;
解法 3,选择与 2018 邻近的三个年份 ,2015, 计算模型②对应的残差绝对值之和
,模型①对应的残差绝对值之和 ;且 ,所以模型②较好;
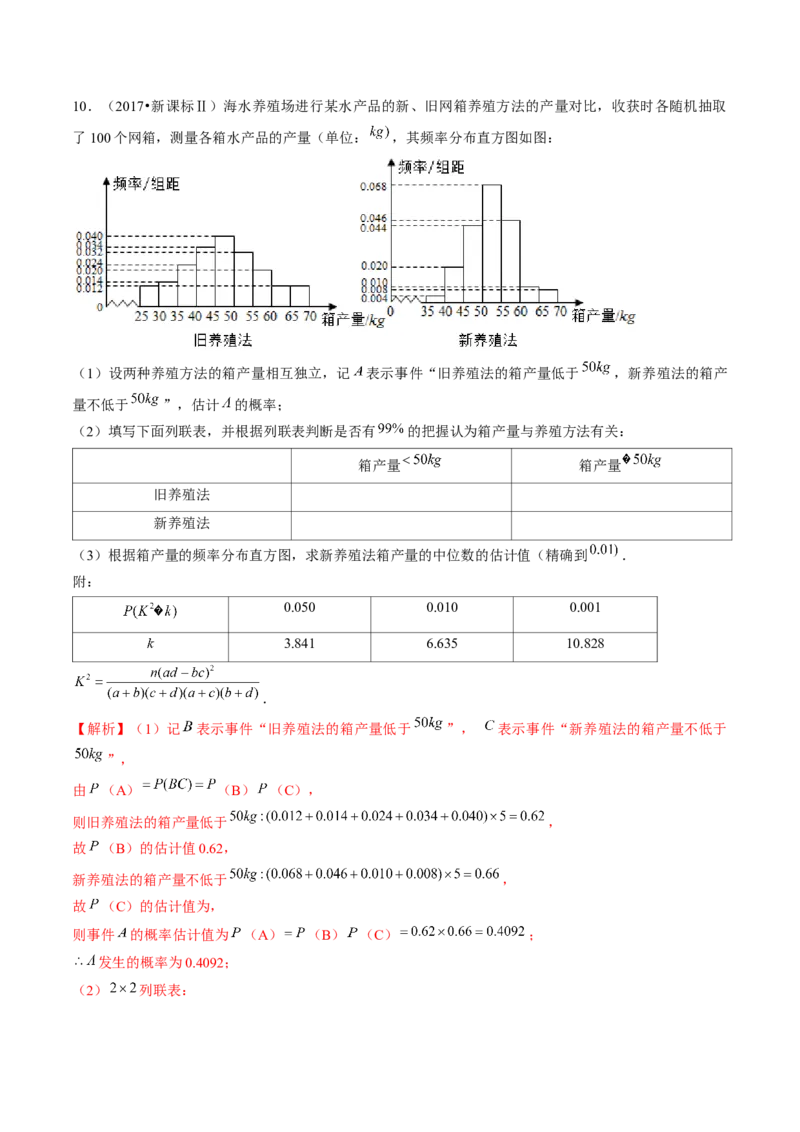
所以利用模型②的预测值更可靠些.10.(2017•新课标Ⅱ)海水养殖场进行某水产品的新、旧网箱养殖方法的产量对比,收获时各随机抽取
了100个网箱,测量各箱水产品的产量(单位: ,其频率分布直方图如图:
(1)设两种养殖方法的箱产量相互独立,记 表示事件“旧养殖法的箱产量低于 ,新养殖法的箱产
量不低于 ”,估计 的概率;
(2)填写下面列联表,并根据列联表判断是否有 的把握认为箱产量与养殖方法有关:
箱产量 箱产量
旧养殖法
新养殖法
(3)根据箱产量的频率分布直方图,求新养殖法箱产量的中位数的估计值(精确到 .
附:
0.050 0.010 0.001
3.841 6.635 10.828
.
【解析】(1)记 表示事件“旧养殖法的箱产量低于 ”, 表示事件“新养殖法的箱产量不低于
”,
由 (A) (B) (C),
则旧养殖法的箱产量低于 ,
故 (B)的估计值0.62,
新养殖法的箱产量不低于 ,
故 (C)的估计值为,
则事件 的概率估计值为 (A) (B) (C) ;
发生的概率为0.4092;
(2) 列联表:总计
箱产量 箱产量
旧养殖法 62 38 100
新养殖法 34 66 100
总计 96 104 200
则 ,
由 ,
有 的把握认为箱产量与养殖方法有关;
(3)由新养殖法的箱产量频率分布直方图中,箱产量低于 的直方图的面积:
,
箱产量低于 的直方图面积为:
,
故新养殖法产量的中位数的估计值为: ,
新养殖法箱产量的中位数的估计值 .
11.(2017•新课标Ⅰ)为了监控某种零件的一条生产线的生产过程,检验员每隔 从该生产线上随机
抽取一个零件,并测量其尺寸(单位: .下面是检验员在一天内依次抽取的16个零件的尺寸:
抽取次 1 2 3 4 5 6 7 8
序
零件尺 9.95 10.12 9.96 9.96 10.01 9.92 9.98 10.04
寸
抽取次 9 10 11 12 13 14 15 16
序
零件尺 10.26 9.91 10.13 10.02 9.22 10.04 10.05 9.95
寸
经 计 算 得 , , ,
,其中 为抽取的第 个零件的尺寸, ,2, ,16.
(1)求 , ,2, , 的相关系数 ,并回答是否可以认为这一天生产的零件尺寸不随生产过
程的进行而系统地变大或变小(若 ,则可以认为零件的尺寸不随生产过程的进行而系统地变大或
变小).
(2)一天内抽检零件中,如果出现了尺寸在 , 之外的零件,就认为这条生产线在这一天的
生产过程可能出现了异常情况,需对当天的生产过程进行检查.(ⅰ)从这一天抽检的结果看,是否需对当天的生产过程进行检查?
(ⅱ)在 , 之外的数据称为离群值,试剔除离群值,估计这条生产线当天生产的零件尺寸的
均值与标准差.(精确到
附:样本 , ,2, , 的相关系数 , .
【解析】(1) .
, 可以认为这一天生产的零件尺寸不随生产过程的进行而系统地变大或变小.
(2) , , 合格零件尺寸范围是 ,
显然第13号零件尺寸不在此范围之内,
需要对当天的生产过程进行检查.
剔除离群值后,剩下的数据平均值为 ,
,
剔除离群值后样本方差为 ,
剔除离群值后样本标准差为 .
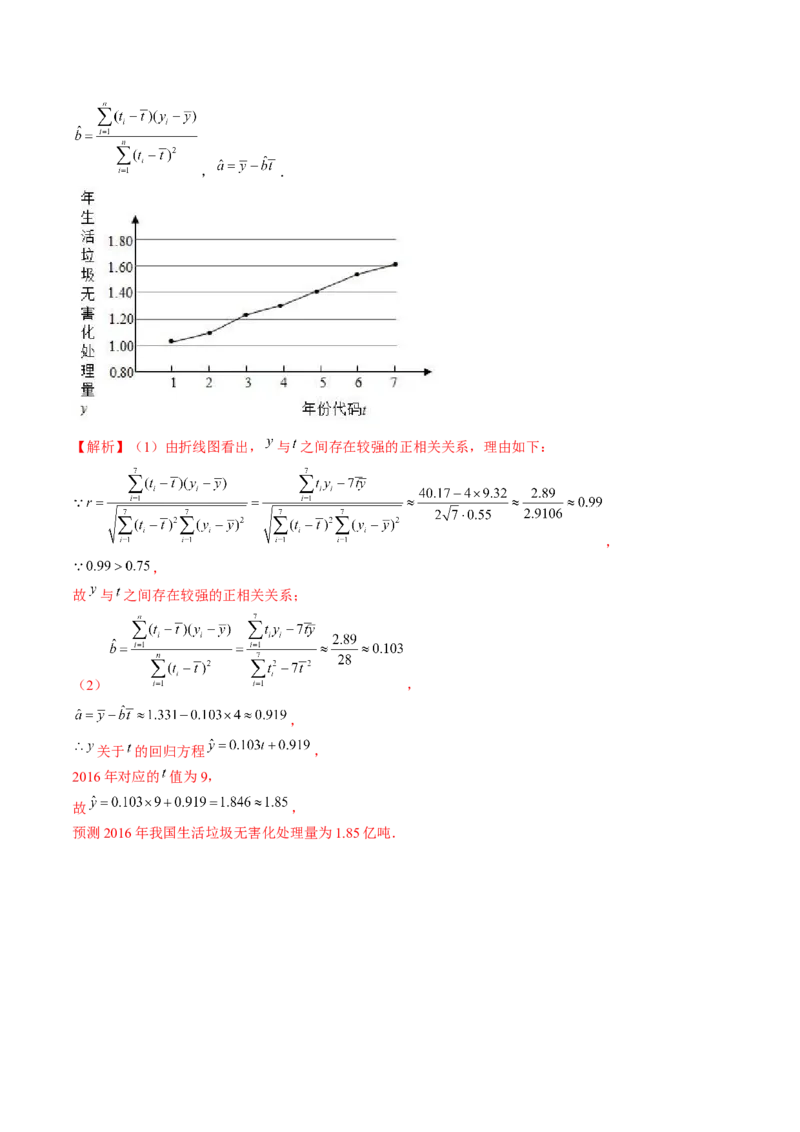
12.(2016•新课标Ⅲ)如图是我国2008年至2014年生活垃圾无害化处理量(单位:亿吨)的折线图.
注:年份代码 分别对应年份 .
(Ⅰ)由折线图看出,可用线性回归模型拟合 与 的关系,请用相关系数加以证明;
(Ⅱ)建立 关于 的回归方程(系数精确到 ,预测2016年我国生活垃圾无害化处理量.
附注:
参考数据: , , , .
参考公式:相关系数 ,
回归方程 中斜率和截距的最小二乘估计公式分别为:, .
【解析】(1)由折线图看出, 与 之间存在较强的正相关关系,理由如下:
,
,
故 与 之间存在较强的正相关关系;
(2) ,
,
关于 的回归方程 ,
2016年对应的 值为9,
故 ,
预测2016年我国生活垃圾无害化处理量为1.85亿吨.

