

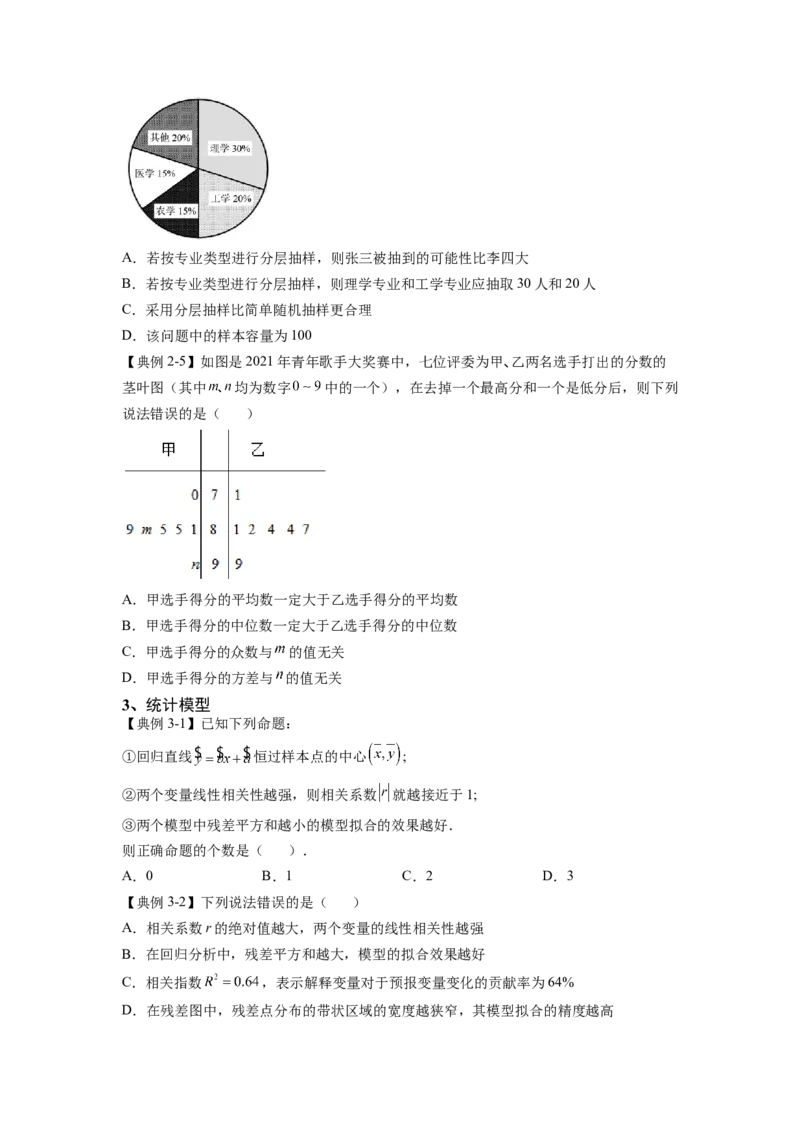
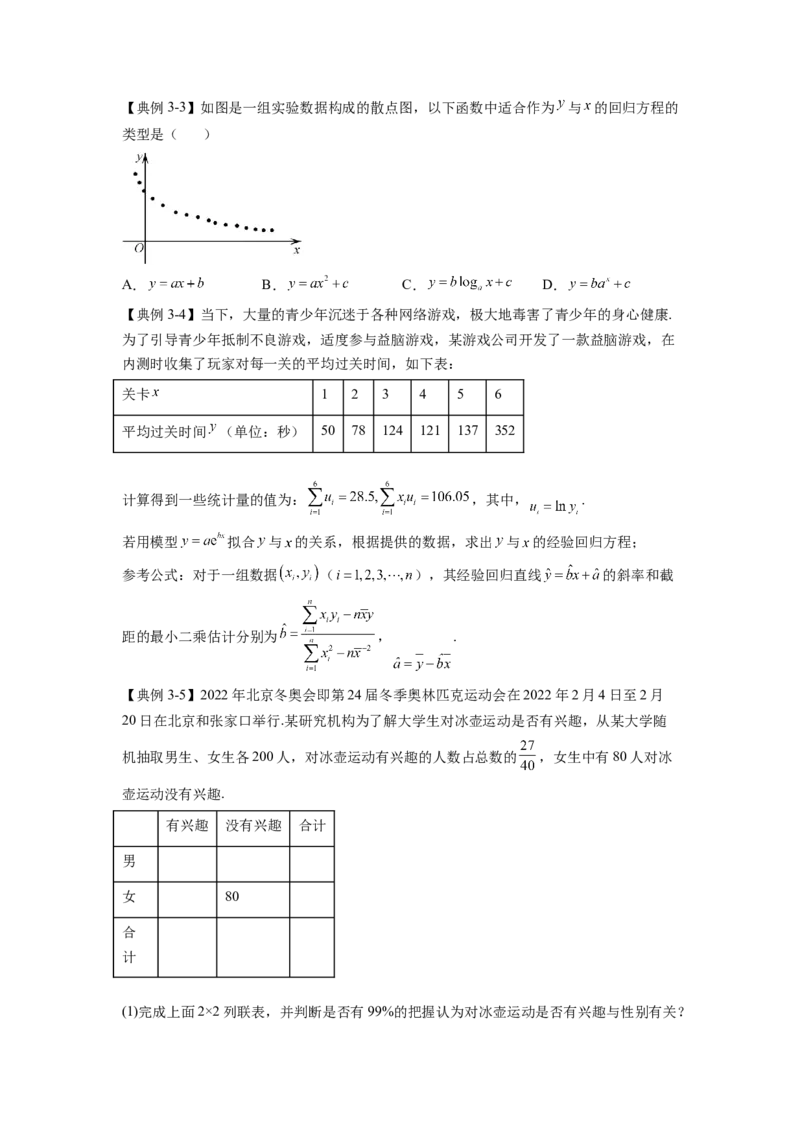


文档内容
第 31 讲 统计与统计模型
学校____________ 姓名____________ 班级____________
一、知识梳理
数据的收集与直观表示
1.总体、个体、样本与样本容量
考察问题涉及的对象全体是总体,总体中每个对象是个体,抽取的部分对象组
成总体的一个样本,一个样本中包含的个体数目是样本容量.
2.普查与抽样调查
(1)普查:一般地,对总体中每个个体都进行考察的方法称为普查(也称为全面
调查).
(2)抽样调查:只抽取样本进行考察的方法称为抽样调查.
3.简单随机抽样
(1)定义:一般地,简单随机抽样(也称为纯随机抽样)就是从总体中不加任何分
组、划类、排队等,完全随机地抽取个体.
(2)两种常用方法:抽签法,随机数表法.
4.分层抽样
一般地,如果相对于要考察的问题来说,总体可以分成有明显差别的、互不重
叠的几部分时,每一部分可称为层,在各层中按层在总体中所占比例进行随机
抽样的方法称为分层随机抽样(简称为分层抽样).
5.数据的直观表示
(1)常见的统计图表有柱形图、折线图、扇形图、茎叶图、频数分布直方图、频
率分布直方图等.
(2)频率分布直方图
①作频率分布直方图的步骤
(ⅰ)找出最值,计算极差:即一组数据中最大值与最小值的差;
(ⅱ)合理分组,确定区间:根据数据的多少,一般分5~9组;
(ⅲ)整理数据:
逐个检查原始数据,统计每个区间内数的个数(称为区间对应的频数),并求出
频数与数据个数的比值(称为区间对应的频率),各组均为左闭右开区间,最后
一组是闭区间;
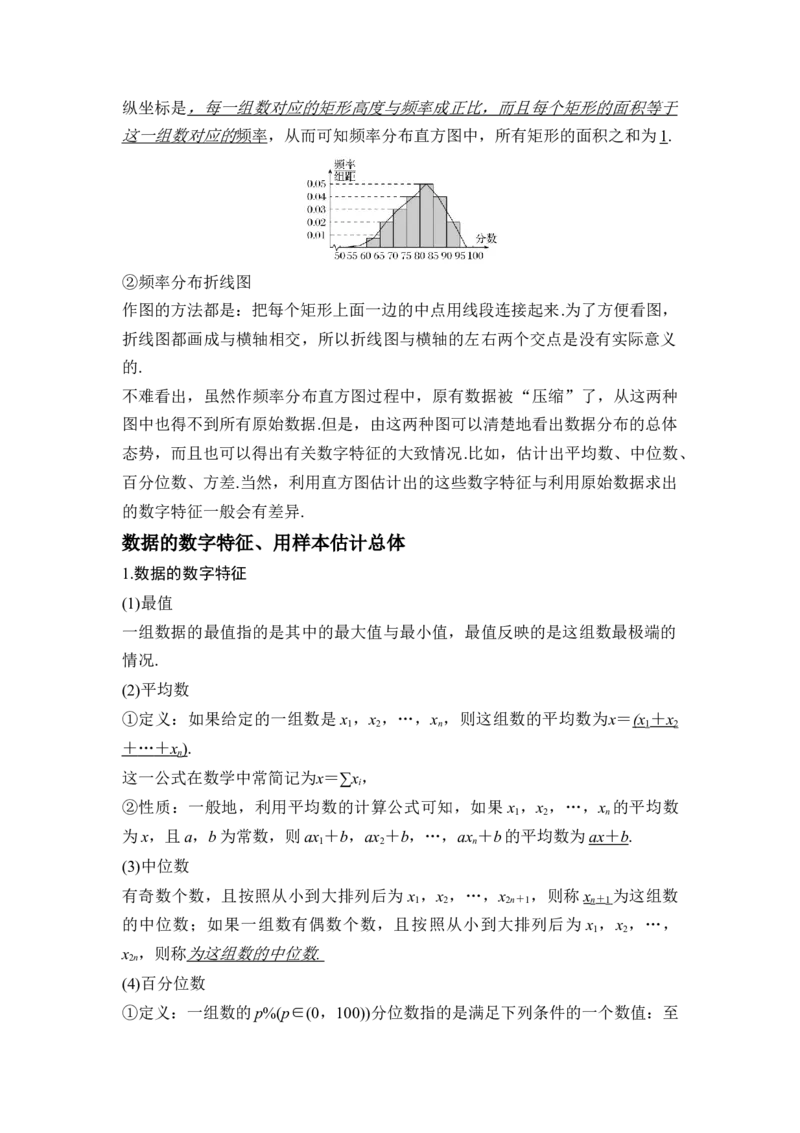
(ⅳ)作出有关图示:
根据上述整理后的数据,可以作出频率分布直方图,如图所示.频率分布直图的纵坐标是,每一组数对应的矩形高度与频率成正比,而且每个矩形的面积等于
这一组数对应的 频率 ,从而可知频率分布直方图中,所有矩形的面积之和为1.
②频率分布折线图
作图的方法都是:把每个矩形上面一边的中点用线段连接起来.为了方便看图,
折线图都画成与横轴相交,所以折线图与横轴的左右两个交点是没有实际意义
的.
不难看出,虽然作频率分布直方图过程中,原有数据被“压缩”了,从这两种
图中也得不到所有原始数据.但是,由这两种图可以清楚地看出数据分布的总体
态势,而且也可以得出有关数字特征的大致情况.比如,估计出平均数、中位数、
百分位数、方差.当然,利用直方图估计出的这些数字特征与利用原始数据求出
的数字特征一般会有差异.
数据的数字特征、用样本估计总体
1.数据的数字特征
(1)最值
一组数据的最值指的是其中的最大值与最小值,最值反映的是这组数最极端的
情况.
(2)平均数
①定义:如果给定的一组数是x ,x ,…,x ,则这组数的平均数为x= ( x + x
1 2 n 1 2
+ … + x ).
n
这一公式在数学中常简记为x=∑x,
i
②性质:一般地,利用平均数的计算公式可知,如果 x ,x ,…,x 的平均数
1 2 n
为x,且a,b为常数,则ax +b,ax +b,…,ax +b的平均数为 a x + b .
1 2 n
(3)中位数
有奇数个数,且按照从小到大排列后为 x ,x ,…,x ,则称x 为这组数
1 2 2n+1 n+1
的中位数;如果一组数有偶数个数,且按照从小到大排列后为 x ,x ,…,
1 2
x ,则称 为这组数的中位数 .
2n
(4)百分位数
①定义:一组数的p%(p∈(0,100))分位数指的是满足下列条件的一个数值:至少有p%的数据不大于该值,且至少有(100-p)%的数据不小于该值.
②确定方法:设一组数按照从小到大排列后为x ,x ,…,x ,计算i=np%的
1 2 n
值,如果i不是整数,设i 为大于i的最小整数,取xi 为p%分位数;如果i是
0 0
整数,取为 p%分位数.
(5)众数
一组数据中,出现次数最多的数据称为这组数据的众数.
(6)极差、方差与标准差
①极差:一组数的极差指的是这组数的最大值减去最小值所得的差,描述了这
组数的离散程度.
②方差
定义:如果x ,x ,…,x 的平均数为x,则方差可用求和符号表示为s2= ∑ ( x
1 2 n i
- x)2=∑x-x2.
性质:如果a,b为常数,则ax +b,ax +b,…,ax +b的方差为 a 2 s 2 .
1 2 n
③标准差
定义:方差的算术平方根称为标准差.一般用s表示,即样本数据x ,x ,…,
1 2
x 的标准差为s=.
n
性质:如果a,b为常数,则ax +b,ax +b,…,ax +b的标准差为|a|s.
1 2 n
2.用样本的数字特征估计总体的数字特征
一般情况下,如果样本容量恰当,抽样方法合理,在估计总体的数字特征时,
只需直接算出样本对应的数字特征即可.
统计模型
1.变量的相关关系
(1)相关关系:两个变量有关系,但又没有确切到可由其中的一个去精确地决定
另一个的程度,这种关系称为相关关系.
(2)相关关系的分类:正相关和负相关.
(3)线性相关:如果变量x与变量y之间的关系可以近似地用一次函数来刻画,
则称x与y线性相关.
2.相关系数
(1)r=xyxy
=xyx.
(2)当r>0时,成对样本数据正相关;当r<0时,成对样本数据负相关.
(3)|r|≤1;当|r|越接近1时,成对样本数据的线性相关程度越强;当|r|越接近0时,成对样本数据的线性相关程度越弱.
3.一元线性回归模型
(1)我们将y=bx+a称为y关于x的回归直线方程,其中
xyxxyxx
(2)残差:观测值减去预测值,称为残差.
4.2×2列联表和χ2
如果随机事件A与B的样本数据的2×2列联表如下.
A A 总计
B a b a+b
B c d c+d
总计 a+c b+d a+b+c+d
记n=a+b+c+d,则
χ2=.
5.独立性检验
统计学中,常用的显著性水平α以及对应的分位数k如下表所示.
α=P(χ2≥k) 0.1 0.05 0.01 0.005 0.001
K 2.706 3.841 6.635 7.879 10.828
要推断“A与B有关系”可按下面的步骤
(1)作2×2列联表.
(2)根据2×2列联表计算 χ 2 的值.
(3)查对分位数k,作出判断.如果根据样本数据算出χ2的值后,发现χ2≥k成立,
就称在犯错误的概率不超过α的前提下,可以认为A与B不独立(也称为A与B
有关);或说有 1 - α 的把握认为A与B有关.若χ2

