




































文档内容
第 02 讲 成对数据的统计分析
目录
01 考情透视·目标导航..........................................................................................................................2
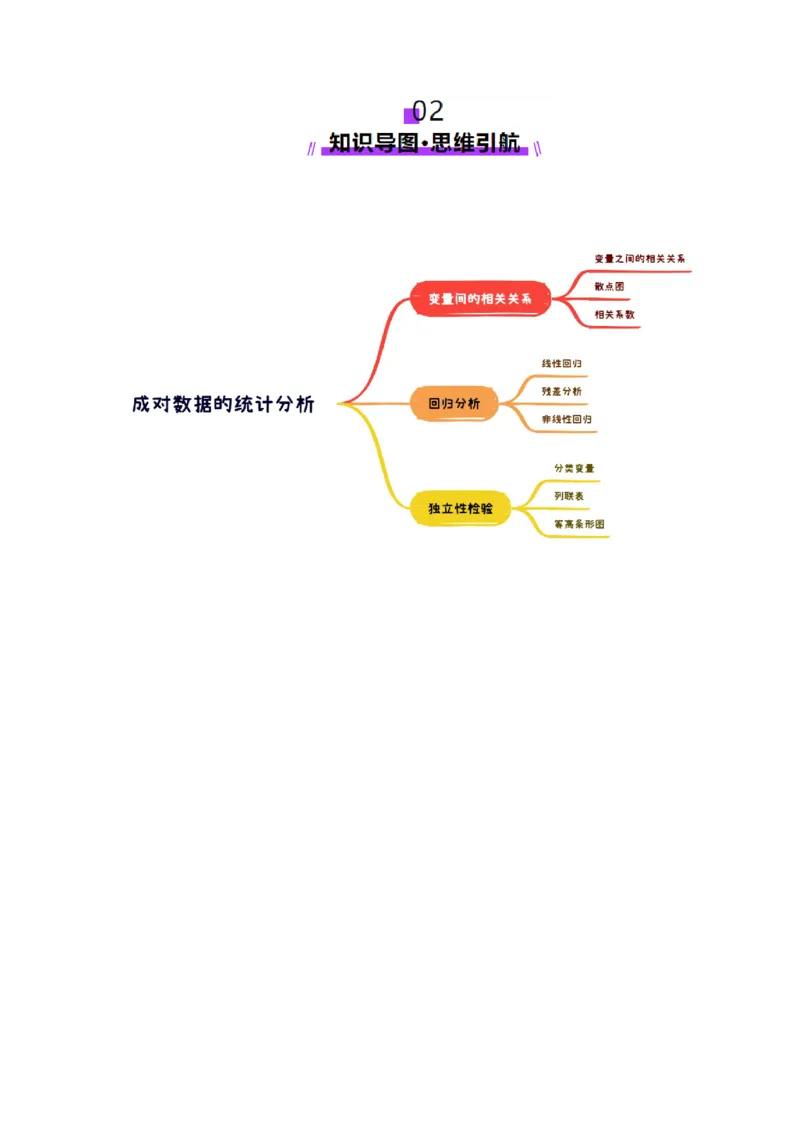
02 知识导图·思维引航..........................................................................................................................3
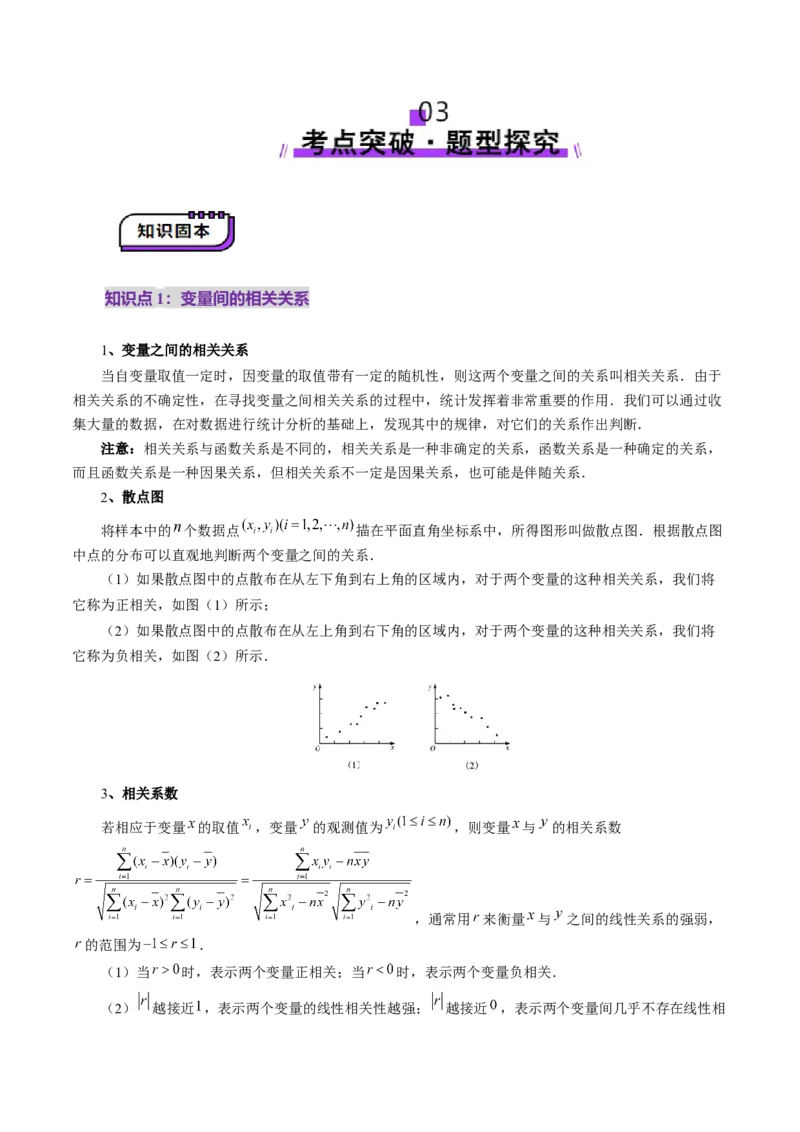
03 考点突破·题型探究..........................................................................................................................4
知识点1:变量间的相关关系.............................................................................................................4
知识点2:线性回归.............................................................................................................................5
知识点3:非线性回归.........................................................................................................................7
知识点4:独立性检验.........................................................................................................................8
解题方法总结......................................................................................................................................11
题型一:变量间的相关关系..............................................................................................................12
题型二:一元线性回归模型..............................................................................................................15
题型三:非线性回归..........................................................................................................................20
题型四:列联表与独立性检验..........................................................................................................28
题型五:误差分析..............................................................................................................................34
04真题练习·命题洞见........................................................................................................................39
05课本典例·高考素材........................................................................................................................41
06易错分析·答题模板........................................................................................................................46
易错点:对回归直线的性质理解不深刻..........................................................................................46
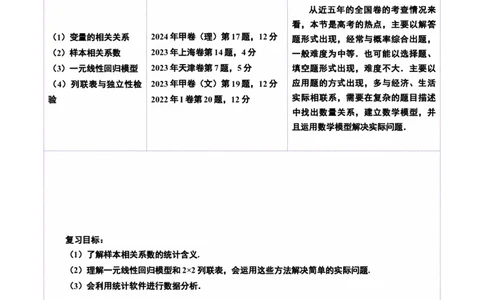
答题模板:独立性检验......................................................................................................................47考点要求 考题统计 考情分析
从近五年的全国卷的考查情况来
看,本节是高考的热点,主要以解答
(1)变量的相关关系 2024年甲卷(理)第17题,12分 题形式出现,经常与概率综合出题,
(2)样本相关系数 2023年上海卷第14题,4分 一般难度为中等.也可能以选择题、
(3)一元线性回归模型 2023年天津卷第7题,5分 填空题形式出现,难度不大.主要以
(4)列联表与独立性检 2023年甲卷(文)第19题,12分 应用题的方式出现,多与经济、生活
验 2022年I卷第20题,12分 实际相联系,需要在复杂的题目描述
中找出数量关系,建立数学模型,并
且运用数学模型解决实际问题.
复习目标:
(1)了解样本相关系数的统计含义.
(2)理解一元线性回归模型和2×2列联表,会运用这些方法解决简单的实际问题.
(3)会利用统计软件进行数据分析.知识点1:变量间的相关关系
1、变量之间的相关关系
当自变量取值一定时,因变量的取值带有一定的随机性,则这两个变量之间的关系叫相关关系.由于
相关关系的不确定性,在寻找变量之间相关关系的过程中,统计发挥着非常重要的作用.我们可以通过收
集大量的数据,在对数据进行统计分析的基础上,发现其中的规律,对它们的关系作出判断.
注意:相关关系与函数关系是不同的,相关关系是一种非确定的关系,函数关系是一种确定的关系,
而且函数关系是一种因果关系,但相关关系不一定是因果关系,也可能是伴随关系.
2、散点图
将样本中的 个数据点 描在平面直角坐标系中,所得图形叫做散点图.根据散点图
中点的分布可以直观地判断两个变量之间的关系.
(1)如果散点图中的点散布在从左下角到右上角的区域内,对于两个变量的这种相关关系,我们将
它称为正相关,如图(1)所示;
(2)如果散点图中的点散布在从左上角到右下角的区域内,对于两个变量的这种相关关系,我们将
它称为负相关,如图(2)所示.
3、相关系数
若相应于变量 的取值 ,变量 的观测值为 ,则变量 与 的相关系数
,通常用 来衡量 与 之间的线性关系的强弱,
的范围为 .
(1)当 时,表示两个变量正相关;当 时,表示两个变量负相关.
(2) 越接近 ,表示两个变量的线性相关性越强; 越接近 ,表示两个变量间几乎不存在线性相关关系.当 时,所有数据点都在一条直线上.
(3)通常当 时,认为两个变量具有很强的线性相关关系.
【诊断自测】如图,为某组数据的散点图,由最小二乘法计算得到回归直线 的方程为 ,相关
系数为 ,决定系数为 .若经过残差分析后去掉点P,剩余的点重新计算得到回归直线 的方程为
,相关系数为 ,决定系数为 .则下列结论一定正确的是( )
A. B. C. D. ,
【答案】C
【解析】共8个点且离群点P的横坐标较小而纵坐标相对过大,去掉离群点后回归方程的斜率更大,故C
正确
去掉离群点后相关性更强,拟合效果也更好,且还是正相关,故D错误
有 , ,故AB错误.
故选:C.
知识点2:线性回归
1、线性回归
线性回归是研究不具备确定的函数关系的两个变量之间的关系(相关关系)的方法.
对于一组具有线性相关关系的数据(x ,y ),(x ,y ),…,(x ,y ),其回归方程 的
1 1 2 2 n n
求法为
其中, , ,( , )称为样本点的中心.
2、残差分析
对于预报变量 ,通过观测得到的数据称为观测值 ,通过回归方程得到的 称为预测值,观测值减去预测值等于残差, 称为相应于点 的残差,即有 .残差是随机误差的估计结果,通过
对残差的分析可以判断模型刻画数据的效果以及判断原始数据中是否存在可疑数据等,这方面工作称为残
差分析.
(1)残差图
通过残差分析,残差点 比较均匀地落在水平的带状区域中,说明选用的模型比较合适,其中这
样的带状区域的宽度越窄,说明模型拟合精确度越高;反之,不合适.
(2)通过残差平方和 分析,如果残差平方和越小,则说明选用的模型的拟合效果越好;
反之,不合适.
(3)相关指数
用相关指数来刻画回归的效果,其计算公式是: .
越接近于 ,说明残差的平方和越小,也表示回归的效果越好.
【诊断自测】将某保护区分为面积大小相近的多个区域,用简单随机抽样的方法抽取其中6个区域,统计
这些区域内的某种水源指标 和某植物分布的数量 ,得到样本 ,且其相关系数
,记 关于 的线性回归方程为 .经计算可知: ,则
.
参考公式: .
【答案】 /1.875
【解析】因为 ,
所以 ,
由 ,
解得 ,所以 .
故答案为:
知识点3:非线性回归
解答非线性拟合问题,要先根据散点图选择合适的函数类型,设出回归方程,通过换元将陌生的非线
性回归方程化归转化为我们熟悉的线性回归方程.
求出样本数据换元后的值,然后根据线性回归方程的计算方法计算变换后的线性回归方程系数,还原
后即可求出非线性回归方程,再利用回归方程进行预报预测,注意计算要细心,避免计算错误.
1、建立非线性回归模型的基本步骤:
(1)确定研究对象,明确哪个是解释变量,哪个是预报变量;
(2)画出确定好的解释变量和预报变量的散点图,观察它们之间的关系(是否存在非线性关系);
(3)由经验确定非线性回归方程的类型(如我们观察到数据呈非线性关系,一般选用反比例函数、
二次函数、指数函数、对数函数、幂函数模型等);
(4)通过换元,将非线性回归方程模型转化为线性回归方程模型;
(5)按照公式计算线性回归方程中的参数(如最小二乘法),得到线性回归方程;
(6)消去新元,得到非线性回归方程;
(7)得出结果后分析残差图是否有异常.若存在异常,则检查数据是否有误,或模型是否合适等.
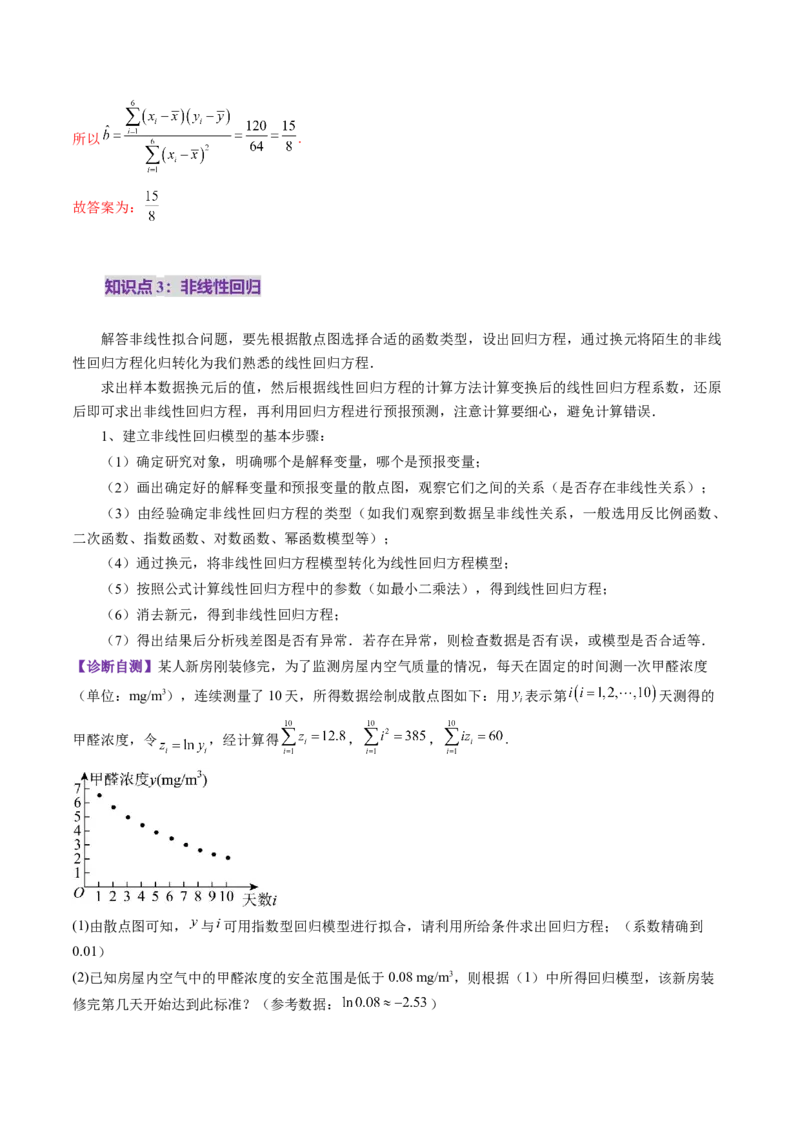
【诊断自测】某人新房刚装修完,为了监测房屋内空气质量的情况,每天在固定的时间测一次甲醛浓度
(单位:mg/m3),连续测量了10天,所得数据绘制成散点图如下:用 表示第 天测得的
甲醛浓度,令 ,经计算得 , , .
(1)由散点图可知, 与 可用指数型回归模型进行拟合,请利用所给条件求出回归方程;(系数精确到
0.01)
(2)已知房屋内空气中的甲醛浓度的安全范围是低于0.08 mg/m3,则根据(1)中所得回归模型,该新房装
修完第几天开始达到此标准?(参考数据: )附: , .
【解析】(1)令 ,而 , ,
则 , ,
因此 ,即 ,
所以所求回归方程为 .
(2)由(1)知: ,即 ,解得 ,
所以 ,即在新房装修完第35天开始达到此标准.
知识点4:独立性检验
1、分类变量和列联表
(1)分类变量:
变量的不同“值”表示个体所属的不同类别,像这样的变量称为分类变量.
(2)列联表:
①定义:列出的两个分类变量的频数表称为列联表.
②2×2列联表.
一般地,假设有两个分类变量X和Y,它们的取值分别为{ , }和{ , },其样本频数列联表
(称为2×2列联表)为
总计
总计
从 列表中,依据 与 的值可直观得出结论:两个变量是否有关系.
2、等高条形图
(1)等高条形图和表格相比,更能直观地反映出两个分类变量间是否相互影响,常用等高条形图表示列联表数据的频率特征.
(2)观察等高条形图发现 与 相差很大,就判断两个分类变量之间有关系.
3、独立性检验
计算随机变量 利用 的取值推断分类变量X和Y是否独立的方法称为
χ2独立性检验.
0.10 0.05 0.010 0.005 0.001
2.706 3.841 6.635 7.879 10.828
【诊断自测】近年中国新能源汽车进入高速发展时期.专家预测2024年中国汽车总销售量将超过3100万辆,
继续领跑全球.为了了解广大消费者购买新能源汽车意向与年龄是否具有相关性,某汽车APP采用问卷调
查形式对400名消费者进行调查,数据显示这400人中中老年人共有150人,且愿意购买新能源车的人数
是愿意购买燃油车的2倍;青年中愿意购买新能源车的人数是愿意购买燃油车的4倍.
购车意向
年龄
合计
段
愿意购买新能源车 愿意购买燃油车
青年
中老
年
合计
(1)完善2×2列联表,请根据小概率值 的独立性检验,分析消费者对新能源车和燃油车的意向购买
与年龄是否有关;
(2)采用分层随机抽样从愿意购买新能源车的消费者中抽取9人,再从这9人中随机抽取4人,求这4人中
青年人数的期望.
附: , .
0.05 0.01 0.001
6.63
3.841 10.828
5
【解析】(1)中老年共有150人,且愿意购买新能源车的人数是愿意购买燃油车的2倍,
所以愿意购买新能源车的中老年人数为100人,
愿意购买燃油车的中老年人数为50人,青年共有250人,
愿意购买新能源车是愿意购买燃油车的4倍,
所以青年中愿意购买新能源车为200人,愿意购买燃油车为50人,得到如下2×2列联表:
购车意向
年龄
合计
段
愿意购买新能源车 愿意购买燃油车
青年 200 50 250
中老
100 50 150
年
合计 300 100 400
零假设 :消费者购买新能源车和燃油车的意向与年龄无关,
,
根据小概率值 的独立性检验,我们推断 不成立,
即认为消费者购买新能源车和燃油车的意向与年龄有关.
(2)愿意购买新能源车的共有300人,青年人与中老年人的比例为2:1,
所以分层随机抽样抽取的9人中6人是青年人,3人是中老年人,
记这4人中,青年的人数为 ,则 的可能取值为1,2,3,4,
, ,
, ,
所以 的分布列如下:
1 2 3 4
,
所以这4人中青年人数的期望为 .
解题方法总结
常见的非线性回归模型
(1)指数函数型 ( 且 , )两边取自然对数, ,即 ,
令 ,原方程变为 ,然后按线性回归模型求出 , .
(2)对数函数型
令 ,原方程变为 ,然后按线性回归模型求出 , .
(3)幂函数型
两边取常用对数, ,即 ,
令 ,原方程变为 ,然后按线性回归模型求出 , .
(4)二次函数型
令 ,原方程变为 ,然后按线性回归模型求出 , .
(5)反比例函数型 型
令 ,原方程变为 ,然后按线性回归模型求出 , .
题型一:变量间的相关关系
【典例1-1】已知5个成对数据 的散点图如下,若去掉点 ,则下列说法正确的是( )
A.变量x与变量y呈正相关 B.变量x与变量y的相关性变强
C.残差平方和变大 D.样本相关系数r变大
【答案】B【解析】由散点图可知,去掉点 后, 与 的线性相关加强,且为负相关,
所以B正确,A错误;
由于 与 的线性相关加强,所以残差平方和变小,所以C错误,
由于 与 的线性相关加强,且为负相关,所以相关系数的绝对值变大,
而相关系数为负的,所以样本相关系数r变小,所以D错误.
故选:B.
【典例1-2】已知 表示变量x与y之间的相关系数, 表示变量u与v之间的相关系数,且 ,
,则( )
A.变量x与y之间呈正相关关系,且x与y之间的相关性强于u与v之间的相关性
B.变量x与y之间呈负相关关系,且x与y之间的相关性强于u与v之间的相关性
C.变量u与v之间呈负相关关系,且x与y之间的相关性弱于u与v之间的相关性
D.变量u与v之间呈正相关关系,且x与y之间的相关性弱于u与v之间的相关性
【答案】C
【解析】因为线性相关系数 , ,
所以变量x与y之间呈正相关关系,变量u与v之间呈负相关关系.
因为|r|越接近1,两个变量的线性相关程度越高,所以x与y之间的相关性弱于u与v之间的相关性.
故选:C.
【方法技巧】
判定两个变量相关性的方法
(1)画散点图:点的分布从左下角到右上角,两个变量正相关;点的分布从左上角到右下角,两个
变量负相关.
(2)样本相关系数:当r>0时,正相关;当r<0时,负相关;|r|越接近于1,相关性越强.
(3)经验回归方程:当 时,正相关;当 时,负相关.
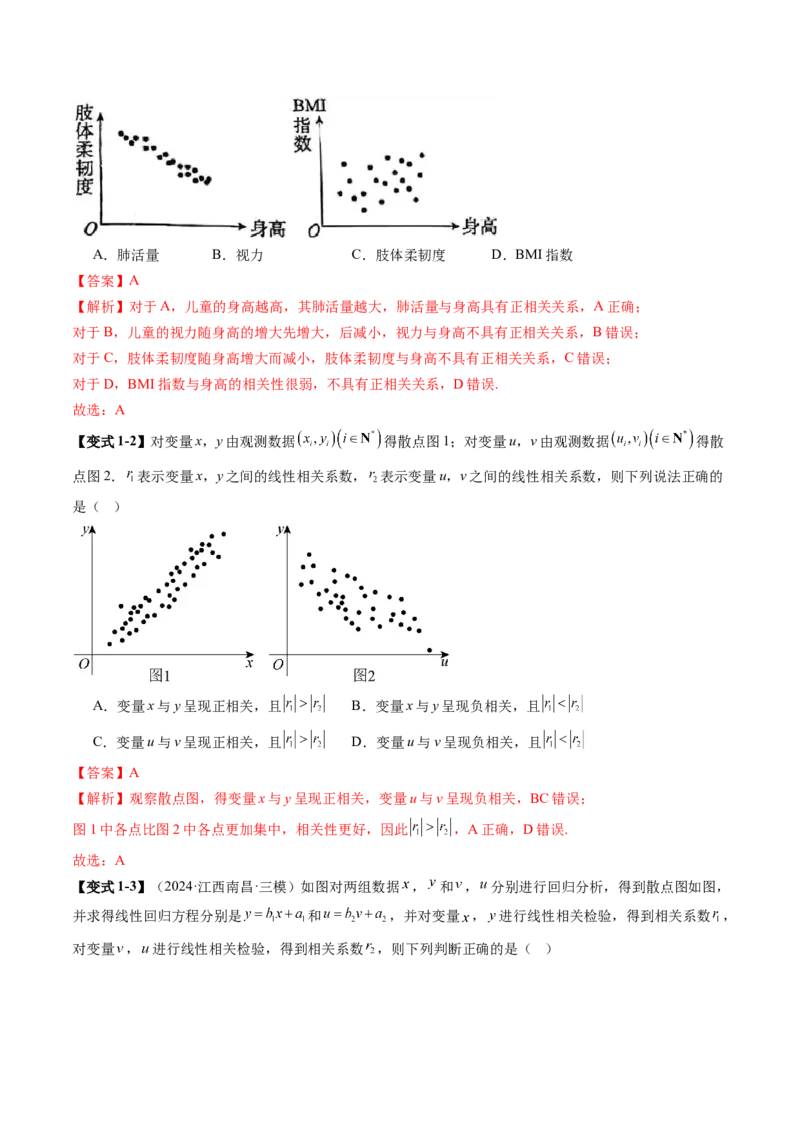
【变式1-1】某校学生科研兴趣小组为了解1~12岁儿童的体质健康情况,随机调查了20名儿童的相关数据,
分别制作了肺活量、视力、肢体柔韧度、BMI指数和身高之间的散点图,则与身高之间具有正相关关系的
是( )A.肺活量 B.视力 C.肢体柔韧度 D.BMI指数
【答案】A
【解析】对于A,儿童的身高越高,其肺活量越大,肺活量与身高具有正相关关系,A正确;
对于B,儿童的视力随身高的增大先增大,后减小,视力与身高不具有正相关关系,B错误;
对于C,肢体柔韧度随身高增大而减小,肢体柔韧度与身高不具有正相关关系,C错误;
对于D,BMI指数与身高的相关性很弱,不具有正相关关系,D错误.
故选:A
【变式1-2】对变量x,y由观测数据 得散点图1;对变量u,v由观测数据 得散
点图2. 表示变量x,y之间的线性相关系数, 表示变量u,v之间的线性相关系数,则下列说法正确的
是( )
A.变量x与y呈现正相关,且 B.变量x与y呈现负相关,且
C.变量u与v呈现正相关,且 D.变量u与v呈现负相关,且
【答案】A
【解析】观察散点图,得变量x与y呈现正相关,变量u与v呈现负相关,BC错误;
图1中各点比图2中各点更加集中,相关性更好,因此 ,A正确,D错误.
故选:A
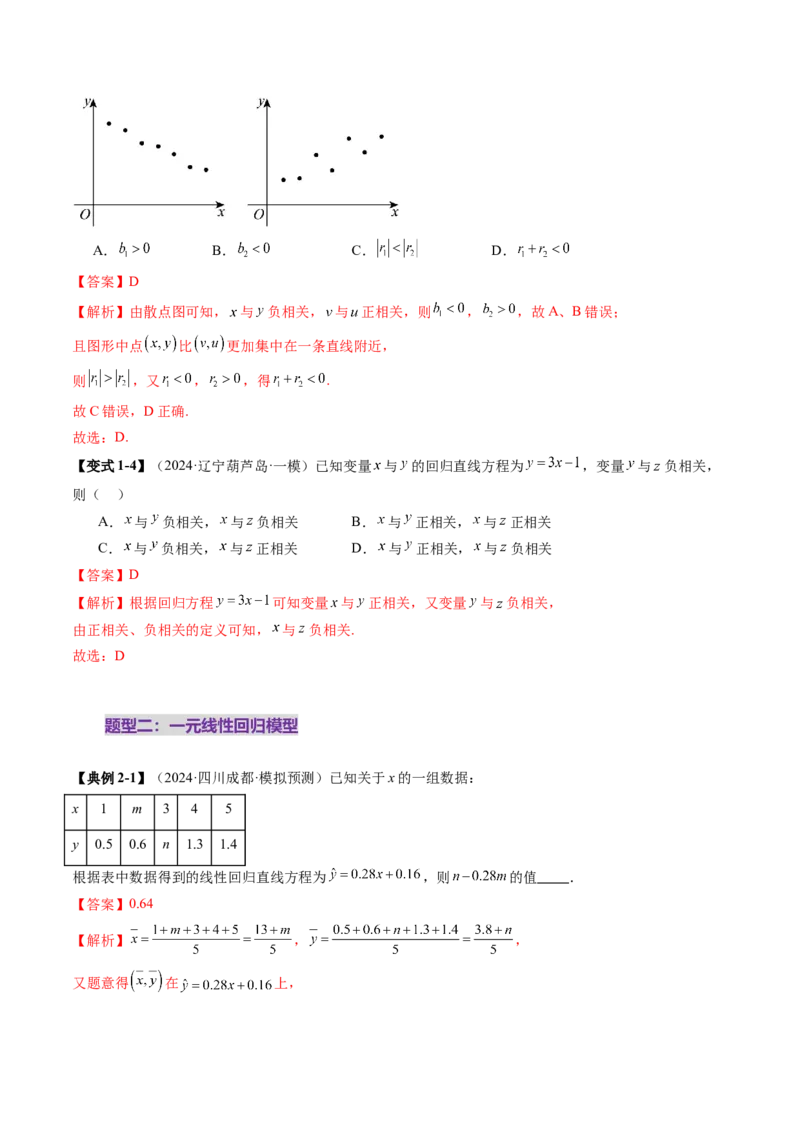
【变式1-3】(2024·江西南昌·三模)如图对两组数据 , 和 , 分别进行回归分析,得到散点图如图,
并求得线性回归方程分别是 和 ,并对变量 , 进行线性相关检验,得到相关系数 ,
对变量 , 进行线性相关检验,得到相关系数 ,则下列判断正确的是( )A. B. C. D.
【答案】D
【解析】由散点图可知, 与 负相关, 与 正相关,则 , ,故A、B错误;
且图形中点 比 更加集中在一条直线附近,
则 ,又 , ,得 .
故C错误,D正确.
故选:D.
【变式1-4】(2024·辽宁葫芦岛·一模)已知变量 与 的回归直线方程为 ,变量 与 负相关,
则( )
A. 与 负相关, 与 负相关 B. 与 正相关, 与 正相关
C. 与 负相关, 与 正相关 D. 与 正相关, 与 负相关
【答案】D
【解析】根据回归方程 可知变量 与 正相关,又变量 与 负相关,
由正相关、负相关的定义可知, 与 负相关.
故选:D
题型二:一元线性回归模型
【典例2-1】(2024·四川成都·模拟预测)已知关于x的一组数据:
x 1 m 3 4 5
y 0.5 0.6 n 1.3 1.4
根据表中数据得到的线性回归直线方程为 ,则 的值 .
【答案】0.64
【解析】 , ,
又题意得 在 上,故 ,故 .
故答案为:0.64
【典例2-2】(2024·四川绵阳·三模)根据统计, 某蔬菜基地西红柿亩产量的增加量 (百千克)与某种液
体肥料每亩的使用量 (千克)之间 的对应数据的散点图如图所示.
(1)从散点图可以看出, 可用线性回归方程拟合 与 的关系, 请计算样本相关系数 并判断它们的相关
程度;
(2)求 关于 的线性回归方程 , 并预测液体肥料每亩的使用量为 12 千克时西红柿亩产量的增
加量.
附: .
【解析】(1)由题知:
所以
所以
所以 与 程正线性相关, 且相关程度很强.
(2)因为 ,
所以 关于 的线性回归方程为 ,
当 时, .
所以预测液体肥料每亩的使用量为 12 千克时西红柿亩产量的增加量为 9.9 百千克.【方法技巧】
求经验回归方程的步骤
【变式2-1】某中医药企业根据市场调研与模拟,得到研发投入 (亿元)与产品收益 (亿元)的数据统
计如下:
研发投入 (亿元) 1 2 3 4 5
产品收益 (亿
3 7 9 10 11
元)
(1)计算 , 的相关系数 ,并判断是否可以认为研发投入与产品收益具有较高的线性相关程度?(若
,则线性相关程度一般;若 ,则线性相关程度较高)
(2)求出 关于 的线性回归方程,并预测若想收益超过20(亿元),则需研发投入至少多少亿元?(结果
保留一位小数)
参考公式:回归直线的斜率和截距的最小二乘法估计公式,相关系数 的公式分别为 ,
, .
参考数据: , , .
【解析】(1)由表中数据可知, , ,
, , ,
则 ,
故相关程度较高;
(2) , ,则 , ,
故 ,
令 ,解得 ,
故研发投入至少9.3亿元.
【变式2-2】(2024·河南周口·模拟预测)直播带货是扶贫助农的一种新模式,这种模式是利用主流媒体的
公信力,聚合销售主播的力量助力打通农产品产销链条,切实助力农民增收.我国南方某蜜桔种植县通过
网络平台直播销售蜜桔,其中每箱蜜桔重5千克,单价为40元/箱,已知最近5天单日直播总时长x(即所
有主播的直播时长之和,单位:小时)与蜜桔的单目销售量y(单位:百箱)之间的统计数据如下表:
直播总时长x 8 9 11 12 15
6
单日销售量y 67 80 80 85
3
可用线性回归模型拟合y与x之间的关系.
(1)试求变量y与x的线性回归方程 ;
(2)若每位主播每天直播的时间不超过4小时,要使每天直播带货销售蜜桔的总金额超过60万元,则至少
要请几位主播进行直播?
(3)直播带货大大提升销量的同时,也增加了坏果赔付的成本.该蜜桔平均每箱按80个计算,若客户在收
到货时有坏果,则每个坏果要赔付1元.现有甲、乙两款包装箱,若采用甲款包装箱,成本为
元/箱,且每箱坏果的个数X服从 ;若采用乙款包装箱,成本为 元/箱,且
每箱坏果的个数Y服从 .请运用概率统计的相关知识分析,选择哪款包装箱获
得的利润更大?
附: , , , .
【解析】(1)由题意得 , ,又 , ,
所以 ,
所以 ,
所以经验回归方程为 .
(2)根据题意得:
,
解得 ,又 ,
所以至少要请 位主播进行直播;
(3)对于乙款包装箱,
由 ,所以 .
设采用甲款包装箱每箱获得的利润的数学期望为 ,
则 ,
设采用乙款包装箱每箱获得的利润的数学期望为
则 ,
令 ,解得 .
因为 ,所以令 解得 ,
令 解得 .
综上所述,当 时,采用两款包装箱获得的利润一样;
当 时,采用甲款包装箱获得的利润更大;
当 时,采用乙款包装箱获得的利润更大.
【变式2-3】(2024·全国·模拟预测)氮氧化物是一种常见的大气污染物,它是由氮和氧两种元素组成的化
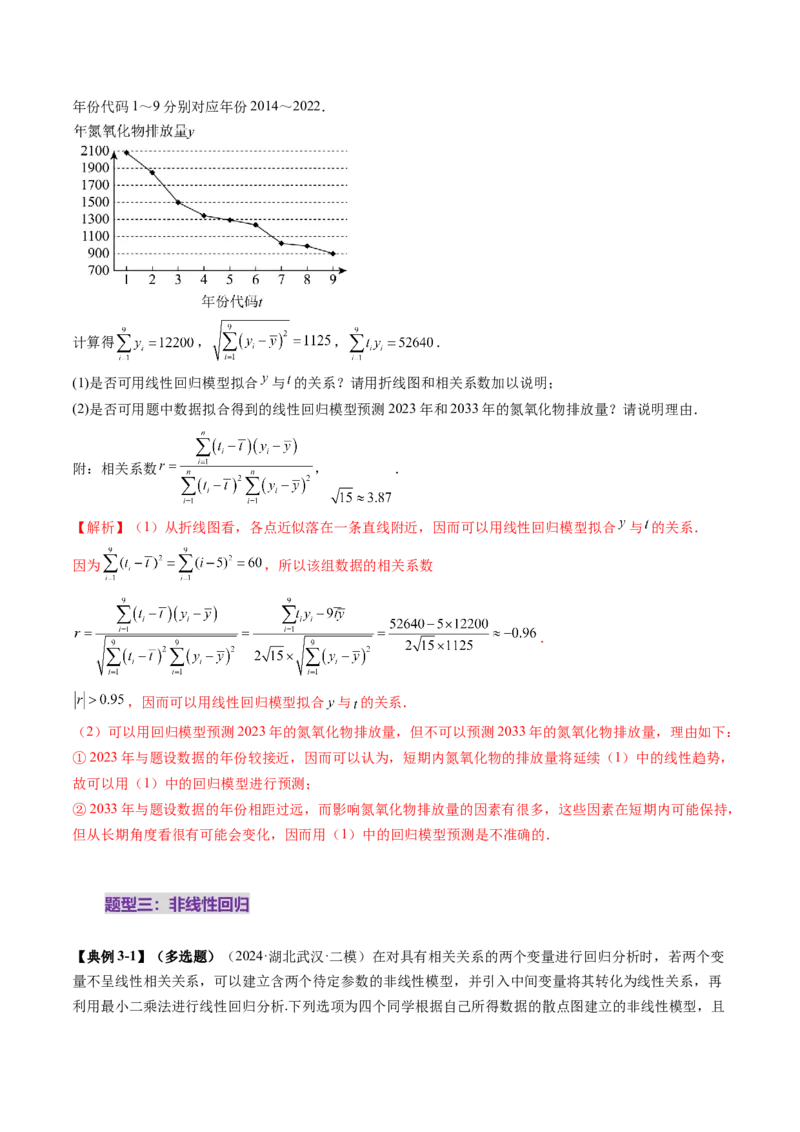
合物,有多种不同的形式.下图为我国2014年至2022年氮氧化物排放量(单位:万吨)的折线图,其中,年份代码1~9分别对应年份2014~2022.
计算得 , , .
(1)是否可用线性回归模型拟合 与 的关系?请用折线图和相关系数加以说明;
(2)是否可用题中数据拟合得到的线性回归模型预测2023年和2033年的氮氧化物排放量?请说明理由.
附:相关系数 , .
【解析】(1)从折线图看,各点近似落在一条直线附近,因而可以用线性回归模型拟合 与 的关系.
因为 ,所以该组数据的相关系数
.
,因而可以用线性回归模型拟合 与 的关系.
(2)可以用回归模型预测2023年的氮氧化物排放量,但不可以预测2033年的氮氧化物排放量,理由如下:
①2023年与题设数据的年份较接近,因而可以认为,短期内氮氧化物的排放量将延续(1)中的线性趋势,
故可以用(1)中的回归模型进行预测;
②2033年与题设数据的年份相距过远,而影响氮氧化物排放量的因素有很多,这些因素在短期内可能保持,
但从长期角度看很有可能会变化,因而用(1)中的回归模型预测是不准确的.
题型三:非线性回归
【典例3-1】(多选题)(2024·湖北武汉·二模)在对具有相关关系的两个变量进行回归分析时,若两个变
量不呈线性相关关系,可以建立含两个待定参数的非线性模型,并引入中间变量将其转化为线性关系,再
利用最小二乘法进行线性回归分析.下列选项为四个同学根据自己所得数据的散点图建立的非线性模型,且散点图的样本点均位于第一象限,则其中可以根据上述方法进行回归分析的模型有( )
A. B.
C. D.
【答案】ABC
【解析】对于选项A : ,令 则 ;
对于选项B:
令 ;
对于选项 C:
即 令 则 ;
对于选项D: 令 则
此时斜率为 ,与最小二乘法不符.
故选:ABC
【典例3-2】已知变量 和 之间的关系可以用模型 来拟合.设 ,若根据样本数据计算可得
,且 与 的线性回归方程为 ,则 .(参考数据:
)
【答案】0.3
【解析】由题意知 ,解得 ,
所以 ,
由 ,得 ,所以 ,
则 .
故答案为:0.3
【方法技巧】
换元法变成一元线性回归模型
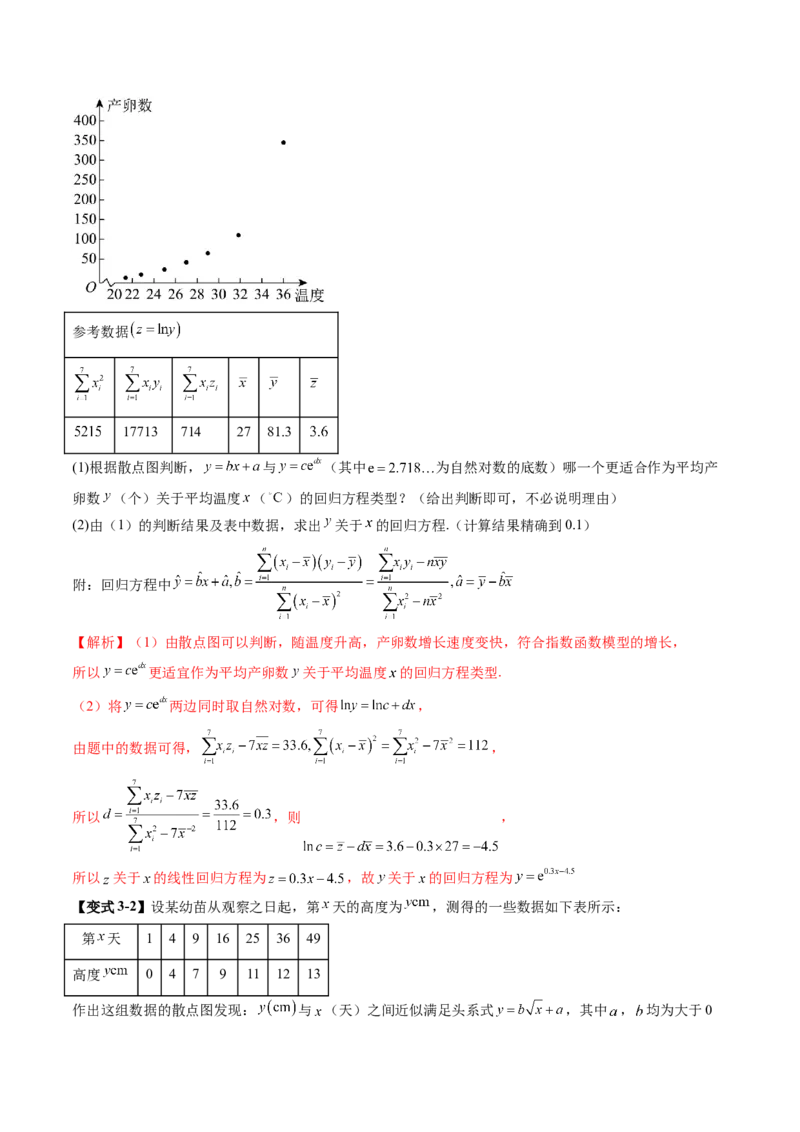
【变式3-1】红蜘蛛是柚子的主要害虫之一,能对柚子树造成严重伤害,每只红蜘蛛的平均产卵数
(个)和平均温度 有关,现收集了以往某地的7组数据,得到下面的散点图及一些统计量的值.参考数据
17713 714 27 81.3
(1)根据散点图判断, 与 (其中 为自然对数的底数)哪一个更适合作为平均产
卵数 (个)关于平均温度 ( )的回归方程类型?(给出判断即可,不必说明理由)
(2)由(1)的判断结果及表中数据,求出 关于 的回归方程.(计算结果精确到0.1)
附:回归方程中
【解析】(1)由散点图可以判断,随温度升高,产卵数增长速度变快,符合指数函数模型的增长,
所以 更适宜作为平均产卵数 关于平均温度 的回归方程类型.
(2)将 两边同时取自然对数,可得 ,
由题中的数据可得, ,
所以 ,则 ,
所以 关于 的线性回归方程为 ,故 关于 的回归方程为
【变式3-2】设某幼苗从观察之日起,第 天的高度为 ,测得的一些数据如下表所示:
第 天 1 4 9 16 25 36 49
高度 0 4 7 9 11 12 13
作出这组数据的散点图发现: 与 (天)之间近似满足头系式 ,其中 , 均为大于0的常数.
(1)试借助一元线性回归模型,根据所给数据,用最小二乘法对 , 作出估计,并求出 关于 的经验回
归方程;
(2)在作出的这组数据的散点图中,甲同学随机圈取了其中的4个点,记这4个点中幼苗的高度大于 的点
的个数为 ,其中 为表格中所给的幼苗高度的平均数,试求随机变量 的分布列和数学期望.
附:对于一组数据 , ,…, ,其回归直线方程 的斜率和截距的最小二乘估
计分别为 , .
【解析】(1)令 ,则 ,根据已知数据表得到如下表:
x
y
则 , ,
可得 ,
,
通过上表计算可得: ,
因为回归直线 过点 ,则 ,
所以y关于 的回归方程 .
(2)由题意可知:7天中幼苗高度大于 的有4天,小于等于8的有3天,
从散点图中任取4个点,即从这7天中任取4天,
所以这4个点中幼苗的高度大于 的点的个数 的取值为1,2,3,4,则有:
; ;
; ;所以随机变量 的分布列为:
1 2 3 4
随机变量 的期望值 .
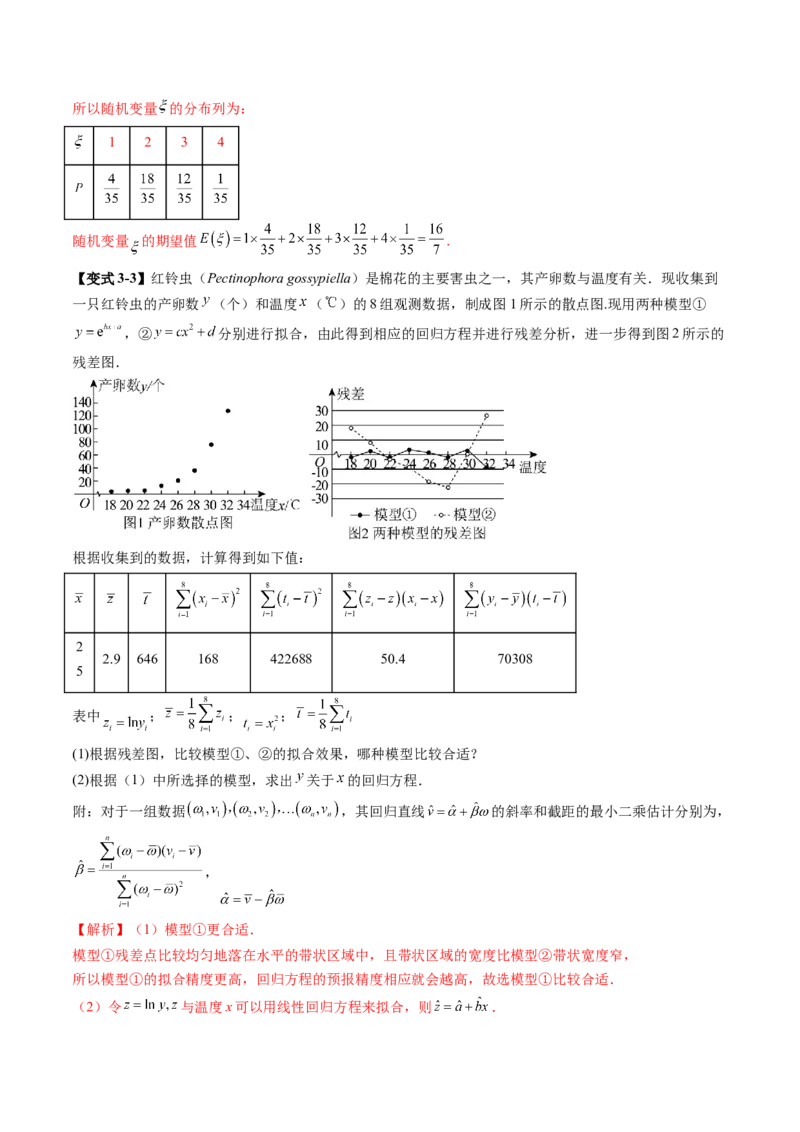
【变式3-3】红铃虫(Pectinophora gossypiella)是棉花的主要害虫之一,其产卵数与温度有关.现收集到
一只红铃虫的产卵数 (个)和温度 ( )的8组观测数据,制成图1所示的散点图.现用两种模型①
,② 分别进行拟合,由此得到相应的回归方程并进行残差分析,进一步得到图2所示的
残差图.
根据收集到的数据,计算得到如下值:
2
2.9 646 168 422688 50.4 70308
5
表中 ; ; ;
(1)根据残差图,比较模型①、②的拟合效果,哪种模型比较合适?
(2)根据(1)中所选择的模型,求出 关于 的回归方程.
附:对于一组数据 ,其回归直线 的斜率和截距的最小二乘估计分别为,
,
【解析】(1)模型①更合适.
模型①残差点比较均匀地落在水平的带状区域中,且带状区域的宽度比模型②带状宽度窄,
所以模型①的拟合精度更高,回归方程的预报精度相应就会越高,故选模型①比较合适.
(2)令 与温度x可以用线性回归方程来拟合,则 .,
则 关于 的线性回归方程为 ,即 ,
产卵数y关于温度x的回归方程为 .
【变式3-4】(2024·福建南平·模拟预测)某大型商场的所有饮料自动售卖机在一天中某种饮料的销售量
(单位:瓶)与天气温度 (单位: )有很强的相关关系,为能及时给饮料自动售卖机添加该种饮料,
该商场对天气温度 和饮料的销售量 进行了数据收集,得到下面的表格:
1
10 20 25 30 35 40
5
1 204
4 64 256 4096 8192
6 8
经分析,可以用 作为 关于 的经验回归方程.
(1)根据表中数据,求 关于 的经验回归方程(结果保留两位小数);
(2)若饮料自动售卖机在一天中不需添加饮料的记1分,需添加饮料的记2分,每台饮料自动售卖机在一天
中需添加饮料的概率均为 ,在商场的所有饮料自动售卖机中随机抽取3台,记总得分为随机变量 ,求
的分布列与数学期望.
参考公式及数据:对于一组数据 ,经验回归方程 的斜率和截距的最小
二乘估计公式分别为
【解析】(1)设 ,由 ,可得 ,
因为 , ,
,所以 ,
由表中的数据可得 ,
则 ,
所以 ,则 ,可得 ,
所以 关于 的经验回归方程为 .
(2)由题意,随机变量 的可能取值为 ,
可得 , ,
, ,
所以变量 的分布列为
3 4 5 6
P
所以,期望为
【变式3-5】在国家积极推动美丽乡村建设的政策背景下,各地根据当地生态资源打造了众多特色纷呈的
乡村旅游胜地.某人意图将自己位于乡村旅游胜地的房子改造成民宿用于出租,在旅游淡季随机选取100
天,对当地已有的六间不同价位的民宿进行跟踪,统计其出租率 ,设民宿租金为
(单位:元/日),得到如图的数据散点图.
(1)若用“出租率”近似估计旅游淡季民宿每天租出去的概率,求租金为388元的那间民宿在淡季内的3天
中至少有2天闲置的概率.
(2)(i)根据散点图判断, 与 哪个更适合此模型(给出判断即可,不必说明理由)?
根据判断结果求经验回归方程.
(ii)若该地一年中旅游淡季约为280天,在此期间无论民宿是否出租,每天都要付出 的固定成本,
若民宿出租,则每天需要再付出 的日常支出成本.试用(i)中模型进行分析,旅游淡季民宿租金定
为多少元时,该民宿在这280天的收益 达到最大.
附:记 , , , , ,, , , , , .
【解析】(1)因为每天的出租率为0.2,所以每天闲置的概率为 ,
所以3天中至少有2天闲置的概率 .
(2)(i)根据散点图的分布情况,各散点连线更贴近 的图象,
故 的拟合效果更好.
依题意, , ,
所以 ,
所以 ,
所以经验回归方程为 .
(ii)设旅游淡季民宿租金为 ,则淡季该民宿的出租率 ,
所以该民宿在这280天的收益为:
,
所以 .
令 ,得 ,
所以 ,
且当 时, , 时, ,
所以 在 上单调递增,在 上单调递减,
所以当 时, 取得最大值.
所以旅游淡季民宿租金定为181元时,该民宿在这280天的收益 达到最大.
【变式3-6】(2024·全国·模拟预测)近三年的新冠肺炎疫情对我们的生活产生了很大的影响,当然也影响
着我们的旅游习惯,乡村游、近郊游、周边游热闹了许多,甚至出现“微度假”的概念.在国家有条不紊
的防疫政策下,旅游又重新回到了老百姓的日常生活中.某乡村抓住机遇,依托良好的生态环境、厚重的
民族文化,开展乡村旅游.通过文旅度假项目考察,该村推出了多款套票文旅产品,得到消费者的积极回
应.该村推出了六条乡村旅游经典线路,对应六款不同价位的旅游套票,相应的价格x与购买人数y的数
据如下表.
旅游线 慢生活
奇山秀水游 古村落游 亲子游 采摘游 舌尖之旅
路 游套票型
A B C D E F
号
价格x/元 39 49 58 67 77 86
经数据分析、描点绘图,发现价格x与购买人数y近似满足关系式 ,即
,对上述数据进行初步处理,其中 , , ,2,…,6.
附:①可能用到的数据: , , , .
②对于一组数据 , ,…, ,其回归直线 的斜率和截距的最小二乘估计值分
别为 , .
(1)根据所给数据,求 关于x的回归方程.
(2)按照相关部门的指标测定,当套票价格 时,该套票受消费者的欢迎程度更高,可以被认定为
“热门套票”.现有三位游客,每人从以上六款套票中购买一款旅游,购买任意一款的可能性相等.若三
人买的套票各不相同,记三人中购买“热门套票”的人数为X,求随机变量X的分布列和期望.
【解析】(1)散点 集中在一条直线附近,
设回归直线方程为 , , ,
则 , ,
所以回归直线方程为 .
因为 , ,所以 ,则 , ,所以 .
综上,y关于x的回归方程为 .
(2)由题意知B,C,D,E为“热门套票”,则三人中购买“热门套票”的人数X服从超几何分布,
X的可能取值为1,2,3,且 , , .
X的分布列如下.
X 1 2 3P
.
题型四:列联表与独立性检验
【典例4-1】观察下图的等高条形图,其中最有把握认为两个分类变量 , 之间没有关系的是( )
A. B.
C. D.
【答案】B
【解析】根据题意,在等高的条形图中,当 , 所占比例相差越大时,越有把握认为两个分类变量 ,
之间有关系,
由选项可得:B选项中, , 所占比例相差无几,所以最有把握认为两个分类变量 , 之间没有关系,
故选:B
【典例4-2】(2024·上海金山·二模)为了考察某种药物预防疾病的效果,进行动物试验,得到如下图所示
列联表:
疾病
药物 合计
未患病 患病
服用 50
未服用 50
合计 80 20 100
取显著性水平 ,若本次考察结果支持“药物对疾病预防有显著效果”,则 ( )的最小
值为 .(参考公式: ;参考值: )
【答案】
【解析】由题意可知 ,
则 ,
解得 或 ,而 ,
故m的最小值为44.
故答案为:44.
【方法技巧】
独立性检验的一般步骤
(1)根据样本数据制成2×2列联表.
(2)根据公式 计算.
(3)比较 与临界值的大小关系,作统计推断.
【变式4-1】(2024·四川成都·模拟预测)在学校食堂就餐成为了很多学生的就餐选择.学校为了解学生食
堂就餐情况,在校内随机抽取了100名学生,其中男生和女生人数之比为 ,现将一周内在食堂就餐超
过8次的学生认定为“喜欢食堂就餐”,不超过8次的学生认定为“不喜欢食堂就餐”.“喜欢食堂就
餐”的人数比“不喜欢食堂就餐”人数多20人,“不喜欢食堂就餐”的男生只有10人.
女
男生 合计
生
喜欢食堂就餐
不喜欢食堂就
10
餐
合计 100
(1)将上面的列联表补充完整,并依据小概率值 的独立性检验,分析学生喜欢食堂就餐是否与性别
有关:
(2)用频率估计概率,从该校学生中随机抽取10名,记其中“喜欢食堂就餐”的人数为X.事件“ ”
的概率为 ,求随机变量X的期望和方差.
参考公式: ,其中 .
a 0.1 0.05 0.01 0.005 0.0013.84
2.706 6.635 7.879 10.828
1
【解析】(1)列联表见图,
女
男生 合计
生
喜欢食堂就餐 40 20 60
不喜欢食堂就
10 30 40
餐
合计 50 50 100
零假设 :假设食堂就餐与性别无关,
由列联表可得 ,
根据小概率 的独立性检验推断 不成立,
即可以得到学生喜欢食堂就餐与性别有关,此推断犯错误的概率不超过 .
(2)由题意可知,抽取的10名学生,喜欢饭堂就餐的学生人数 服从二项分布,
且喜欢饭堂就餐的频率为 ,则 ,
故其期望 ,方差 .
【变式4-2】(2024·高三·河南焦作·开学考试)交通强国,铁路先行,每年我国铁路部门都会根据运输需
求进行铁路调图,一铁路线l上有自东向西依次编号为1,2,…,21的21个车站.
(1)为调查乘客对调图的满意度,在编号为10和11两个站点多次乘坐列车P的旅客中,随机抽取100名旅
客,得出数据(不完整)如下表所示:
满
车站编号 不满意 合计
意
10 28 40
11 3
合计 85
完善表格数据并计算分析:依据小概率值 的独立性检验,在这两个车站中,能否认为旅客满意程
度与车站编号有关联?
(2)根据以往调图经验,列车P在编号为8至14的终到站每次调图时有 的概率改为当前终到站的西侧一站,
有 的概率改为当前终到站的东侧一站,每次调图之间相互独立.已知原定终到站编号为11的列车P经历了3次调图,第3次调图后的终到站编号记为X,求X的分布列及均值.
附: ,其中 .
0.1 0.01 0.001
2.706 6.635 10.828
【解析】(1)补充列联表如下:
满
车站编号 不满意 合计
意
10 28 12 40
11 57 3 60
合计 85 15 100
零假设为 :旅客满意程度与车站编号无关,
则 ,
所以根据小概率值 的独立性检验,推断 不成立,
即认为旅客满意程度与车站编号有关联.
(2)由题X的可能取值为 ,
则 ; ;
; ,
所以X的分布列为
X 8 10 12 14
P
所以 .
【变式4-3】2024年7月26日,第33届夏季奥林匹克运动会在法国巴黎正式开幕.人们在观看奥运比赛的
同时,开始投入健身的行列.某兴趣小组为了解成都市不同年龄段的市民每周锻炼时长情况,随机从抽取
200人进行调查,得到如下列联表:
年龄 周平均锻炼时长 合计周平均锻炼时间少于4小时 周平均锻炼时间不少于4小时
50岁以下 40 60 100
50岁以上(含50) 25 75 100
合计 65 135 200
(1)试根据 的 独立性检验,分析周平均锻炼时长是否与年龄有关? 精确到0.001 ;
(2)现从50岁以下的样本中按周平均锻炼时间是否少于4小时,用分层随机抽样法抽取5人做进一步访谈,
再从这5人中随机抽取3人填写调查问卷.记抽取3人中周平均锻炼时间不少于4小时的人数为 ,求 的
分布列和数学期望.
0.1 0.05 0.01 0.005 0.001
2.706 3.841 6.635 7.879 10.828
参考公式及数据: ,其中 .
【解析】(1)零假设 :周平均锻炼时长与年龄无关联.
由 列联表中的数据,可得 ,
.
根据小概率值 的独立性检验,我们推断 不成立,
即认为周平均锻炼时长与年龄有关联,此推断犯错误的概率不大于 .
所以50岁以下和50岁以上(含50)周平均锻炼时长有差异.
(2)抽取的5人中,周平均锻炼时长少于4小时的有 人,不少于4小时的有 人,
所以 所有可能的取值为 ,
所以 , , ,
所以随机变量 的分布列为:
1 2 3
随机变量 的数学期望
【变式4-4】为研究“眼睛近视是否与长时间看电子产品有关”的问题,对某班同学的近视情况和看电子
产品的时间进行了统计,得到如下的列联表:每天看电子产品的时间
近视情况 合计
一小时
超过一小时
内
近视 10人 5人 15人
不近视 10人 25人 35人
合计 20人 30人 50人
附表:
0.1 0.05 0.01 0.005 0.001
2.706 3.841 6.635 7.879 10.828
.
(1)根据小概率值 的 独立性检验,判断眼睛近视是否与长时间看电子产品有关;
(2)在该班近视的同学中随机抽取3人,则至少有两人每天看电子产品超过一小时的概率是多少?
(3)以频率估计概率,在该班所在学校随机抽取2人,记其中近视的人数为X,每天看电子产品超过一小时
的人数为Y,求 的值.
【解析】(1)零假设 为:学生患近视与长时间使用电子产品无关.
计算可得, ,
根据小概率值 的 独立性检验,我们推断 不成立,即认为患近视与长时间使用电子产品的习惯
有关.
(2)每天看电子产品超过一小时的人数为 ,
则 ,
所以在该班近视的同学中随机抽取3人,则至少有两人每天看电子产品超过一小时的概率是 .
(3)依题意, , ,
事件 包含两种情况:
①其中一人每天看电子产品超过一小时且近视,另一人既不近视,每天看电子产品也没超过一小时;
②其中一人每天看电子产品超过一小时且不近视,另一人近视且每天看电子产品没超过一小时,
于是 ,所以 .
题型五:误差分析
【典例5-1】设满足一元线性回归模型的两个变量的 对样本数据为 ,下列统计
量中不能刻画数据与直线 的“整体接近程度”的是( )
A. B. C. D.
【答案】D
【解析】统计量 和 可以刻画数据点与直线 的竖直距离,
进而可以刻画数据与直线 的“整体接近程度”,AC选项不符合题意.
统计量 可以刻画数据点与直线 的距离,
也可以刻画数据与直线 的“整体接近程度”,B选项不符合题意.
统计量 的计算会出现直线两侧的数据点在代数上正负抵消的情况,
因此不能刻画数据与直线 的“整体接近程度”,D选项符合题意.
故选:D.
【典例5-2】对于数据组 ,如果由线性回归方程得到的自变量 的估计值是 ,那么将
称为样本点 处的残差.某商场为了给一种新商品进行合理定价,将该商品按事先拟定的价格
进行试销,得到下表所示数据.若某商品销量y(单位:件)与单价x(单位:元)之间的线性回归方程为
,且样本点 处的残差为2,则 ( )
8.
单价x/元 8.2 8.6 8.8
4
销量y/件 84 82 78 m
A.66 B.68 C.70 D.72
【答案】B
【解析】由条件知当 时, ,代入 ,解得 ,于是 ,
又 ,所以 ,即 ,解得 .
故选:B.
【方法技巧】
线性回归误差分析是评估模型预测结果与实际值之间差异的过程。误差主要分为偏差和方差两部分:
偏差衡量了模型预测结果的平均准确性,反映了模型本身的拟合能力;方差则反映了模型在不同训练集上
的稳定性。在线性回归模型中,通过调整模型复杂度、特征选择、数据预处理等方式,可以有效降低偏差
和方差,从而提升模型的预测性能。误差分析有助于理解模型的表现,指导模型的改进方向。
【变式5-1】(2024·江西萍乡·三模)现收集到变量 的六组观测数据为:
,用最小二乘法计算得其回归直线为 ,相关系数为 ;经
过残差分析后发现 为离群点(对应残差绝对值过大的点),剔除后,用剩下的五组数据计算得其回归
直线为 ,相关系数为 .则下列结论不正确的是( )
A. B.
C. D.去掉离群点后,残差平方和变小
【答案】B
【解析】由数据得: ,
,则 ,
剔除离群点后:
,
,则 ,
A. ,故正确;
B. ,故错误;
C. 剔除离群点后,相关程度越大,所以相关系数 ,故正确;
D.剔除离群点后,相关程度越大,所以残差平方和变小,故正确.
故选:B.
【变式5-2】2024年全国田径冠军赛暨全国田径大奖赛总决赛于6月30日在山东省日照市落幕.四川田径队
的吴艳妮以12秒74分的成绩打破了100米女子跨栏的亚洲纪录,并夺得了2024年全国田径冠军赛女子
100米跨栏决赛的冠军,通过跑道侧面的高清轨道摄像机记录了该运动员时间 (单位: )与位移 (单
位: )之间的关系,得到如下表数据:2.
2.8 3 3.1 3.2
9
24 25 29 32 34
画出散点图观察可得 与 之间近似为线性相关关系.
(1)求出 关于 的线性回归方程;
(2)记 ,其中 为观测值, 为预测值, 为对应 的残差,求前3项残差的和.
参考数据: ,参考公式: .
【解析】(1)依题意可得
所以 关于 的线性回归方程为 .
(2)根据(1)得到 ;
;
,
所以 .
【变式5-3】某公司为了解年研发资金 (单位:亿元)对年产值 (单位:亿元)的影响,对公司近8年
的年研发资金 和年产值 ( , )的数据对比分析中,选用了两个回归模型,并利用最小二
乘法求得相应的 关于 的经验回归方程:
① ;② .
(1)求 的值;
(2)已知①中的残差平方和 ,②中的残差平方和 ,请根据决定系数选择拟合效果更好的经
验回归方程,并利用该经验回归方程预测年研发资金为20亿元时的年产值.
参考数据: , , , .参考公式;刻画回归模型拟合效果的决定系数 .
【解析】(1)根据题意, , ,
所以样本中心点为 ,代入经验回归方程 ,
得 ,解得 .
所以 的值为 .
(2)设经验回归方程①的决定系数为 ,由 ,
则 ,
设经验回归方程②的决定系数为 ,由 ,
则 ,
因为 ,所以经验回归方程②的拟合效果更好;
当 时, ,
所以年研发资金为20亿元时的年产值约为 亿元.
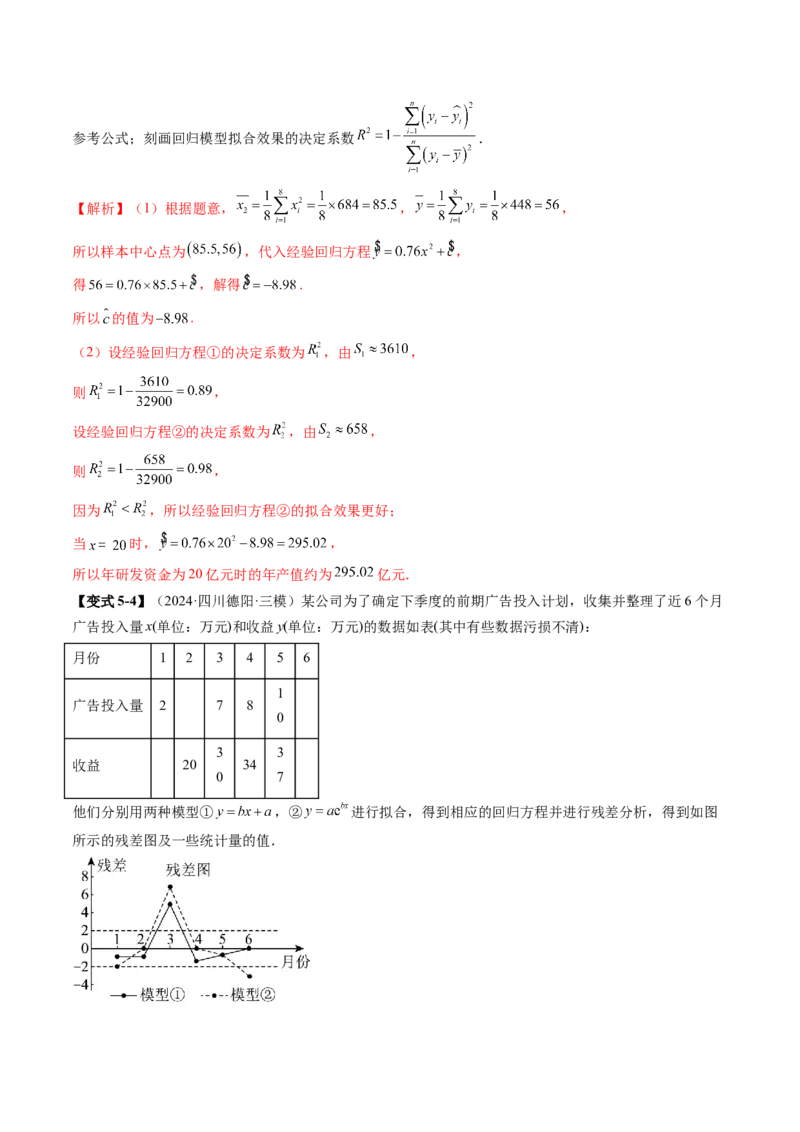
【变式5-4】(2024·四川德阳·三模)某公司为了确定下季度的前期广告投入计划,收集并整理了近6个月
广告投入量x(单位:万元)和收益y(单位:万元)的数据如表(其中有些数据污损不清):
月份 1 2 3 4 5 6
1
广告投入量 2 7 8
0
3 3
收益 20 34
0 7
他们分别用两种模型① ,② 进行拟合,得到相应的回归方程并进行残差分析,得到如图
所示的残差图及一些统计量的值.3
7 1470 370
0
(1)根据残差图,比较模型①,②的拟合效果,应选择哪个模型?
(2)残差绝对值大于2 的数据被认为是异常数据,需要剔除.
(i)剔除异常数据后,求出(1)中所选模型的回归方程;
(ii)若广告投入量x=19,则(1)中所选模型收益的预报值是多少万元?(精确到0.01)
附:对于一组数据 其回归直线 的斜率和截距的最小二乘估计分别为:
.
【解析】(1)由于模型①残差波动小,应该选择模型①.
(2)(i)剔除异常数据,即3月份的数据,剩下数据的平均数为 ,
, , ,
, ,
,
所以所选模型的回归方程为 .
(ii)若广告投入量 ,
则该模型收益的预报值是 (万元).
1.(2024年上海秋季高考数学真题)已知气候温度和海水表层温度相关,且相关系数为正数,对此描述
正确的是( )A.气候温度高,海水表层温度就高
B.气候温度高,海水表层温度就低
C.随着气候温度由低到高,海水表层温度呈上升趋势
D.随着气候温度由低到高,海水表层温度呈下降趋势
【答案】C
【解析】对于AB,当气候温度高,海水表层温度变高变低不确定,故AB错误.
对于CD,因为相关系数为正,故随着气候温度由低到高时,海水表层温度呈上升趋势,
故C正确,D错误.
故选:C.
2.(2023年天津高考数学真题)鸢是鹰科的一种鸟,《诗经·大雅·旱麓》曰:“鸢飞戾天,鱼跃余渊”.
鸢尾花因花瓣形如鸢尾而得名,寓意鹏程万里、前途无量.通过随机抽样,收集了若干朵某品种鸢尾花的花
萼长度和花瓣长度(单位:cm),绘制散点图如图所示,计算得样本相关系数为 ,利用最小二
乘法求得相应的经验回归方程为 ,根据以上信息,如下判断正确的为( )
A.花瓣长度和花萼长度不存在相关关系
B.花瓣长度和花萼长度负相关
C.花萼长度为7cm的该品种鸢尾花的花瓣长度的平均值为
D.若从样本中抽取一部分,则这部分的相关系数一定是
【答案】C
【解析】根据散点的集中程度可知,花瓣长度和花萼长度有相关性,A选项错误
散点的分布是从左下到右上,从而花瓣长度和花萼长度呈现正相关性,B选项错误,
把 代入 可得 ,C选项正确;
由于 是全部数据的相关系数,取出来一部分数据,相关性可能变强,可能变弱,即取出的数据
的相关系数不一定是 ,D选项错误
故选:C
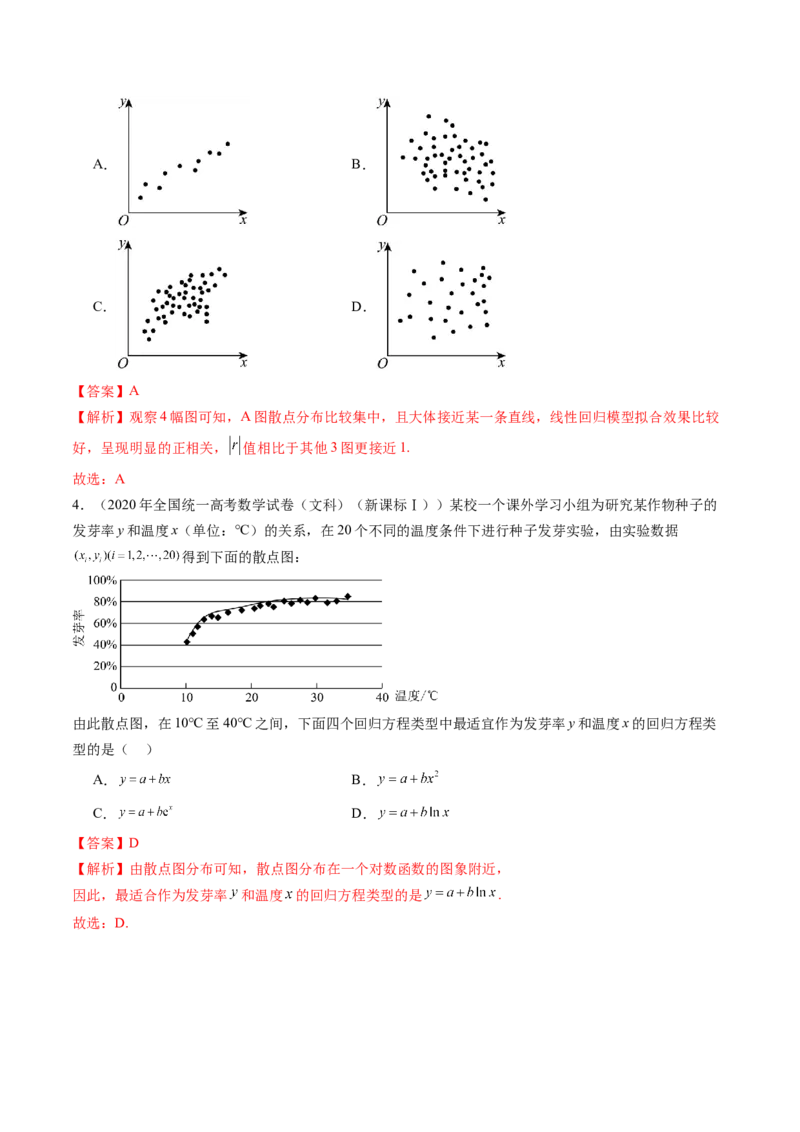
3.(2024年天津高考数学真题)下列图中,线性相关性系数最大的是( )A. B.
C. D.
【答案】A
【解析】观察4幅图可知,A图散点分布比较集中,且大体接近某一条直线,线性回归模型拟合效果比较
好,呈现明显的正相关, 值相比于其他3图更接近1.
故选:A
4.(2020年全国统一高考数学试卷(文科)(新课标Ⅰ))某校一个课外学习小组为研究某作物种子的
发芽率y和温度x(单位:°C)的关系,在20个不同的温度条件下进行种子发芽实验,由实验数据
得到下面的散点图:
由此散点图,在10°C至40°C之间,下面四个回归方程类型中最适宜作为发芽率y和温度x的回归方程类
型的是( )
A. B.
C. D.
【答案】D
【解析】由散点图分布可知,散点图分布在一个对数函数的图象附近,
因此,最适合作为发芽率 和温度 的回归方程类型的是 .
故选:D.1.某地区的环境条件适合天鹅栖息繁衍.有人发现了一个有趣的现象,该地区有5个村庄,其中3个村庄
附近栖息的天鹅较多,婴儿出生率也较高;2个村庄附近栖息的天鹅较少,婴儿的出生率也较低.有人认
为婴儿出生率和天鹅数之间存在相关关系,并得出一个结论:天鹅能够带来孩子,你同意这个结论吗?为
什么?
【解析】某个地区的环境条件适合天鹅栖息繁衍,
与这个地区的环境条件有很大的关系,适合天鹅栖息的地区天鹅栖息就较多,
不适合天鹅栖息的地区天鹅栖息就较少,婴儿出生率与生理遗传有关,
当然也受地区环境的影响,但是两者并不存在必然的相关关系,
“天鹅能够带来孩子”这个结论是错误的.
2.对于变量Y和变量x的成对样本观测数据,用一元线性回归模型 得到经验回归模型
,对应的残差如下图所示,模型误差( )
A.满足一元线性回归模型的所有假设
B.不满足一元线性回归模型的 的假设
C.不满足一元线性回归模型的 假设
D.不满足一元线性回归模型的 和 的假设
【答案】C
【解析】用一元线性回归模型 得到经验回归模型 ,根据对应的残差图,残差
的均值 可能成立,但明显残差的 轴上方的数据更分散, 不满足一元线性回归模型,正
确的只有C.
故选:C.
3.根据分类变量 与 的观测数据,计算得到 .依据 的独立性检验,结论为( ).A.变量 与 不独立
B.变量 与 不独立,这个结论犯错误的概率不超过
C.变量 与 独立
D.变量 与 独立,这个结论犯错误的概率不超过
【答案】C
【解析】由表可知当 时, ,
因为 ,所以分类变量 与 相互独立,
因为 ,
所以分类变量 与 相互独立,这个结论犯错误的概率不超过 ,
故选:C
4.如果散点图中所有的散点都落在一条斜率为非0的直线上,请回答下列问题:
(1)解释变量和响应变量的关系是什么?
(2) 是多少?
【解析】(1)因为散点图中所有的散点都落在一条斜率为非0的直线上,
所以解释变量和响应变量的关系是线性函数关系.
(2)由(1)知:
5.一个车间为了规定工时定额,需要确定加工零件所花费的时间,为此进行了10次试验,收集数据如下
表所示.
6
零件数x个 10 20 30 40 50 70 80 90 100
0
9 10
加工时间ymin 62 68 75 81 89 102 115 122
5 8
(1)画出散点图;
(2)建立加工时间关于零件数的一元线性回归模型(精确到0.001);
(3)关于加工零件的个数与加工时间,你能得出什么结论?
【解析】(1)画出散点图如下图所示:(2) ,
,
,
所以 .
(3)根据回归直线方程可知:每多加工 个零件,需要增加 分钟加工时间.
6.单位:人
数学成绩
学校 优秀 合计
不优秀
甲校
乙校
合计
对列联表中的数据,依据 的独立性检验,我们已经知道独立性检验的结论是学校和成绩无关.如果
表中所有数据都扩大为原来的 倍,在相同的检验标准下,再用独立性检验推断学校和数学成绩之间的关
联性,结论还一样吗?请你试着解释其中的原因.
附:临界值表:
【解析】数据扩大 倍的 列联表为:数学成绩
学校 优秀 合计
不优秀
甲校
乙校
合计
假设 学校与数学成绩无关,
由列联表数据得 ,
根据小概率值 的独立性检验,我们推断假设 不成立,即认为学校与数学成绩有关,
又因为甲校成绩优秀和不优秀的概率分别为 , ,
乙校成绩优秀和不优秀的概率分别为 , ,
又因为 ,所以,从甲校、乙校各抽取一个学生,甲校学生数学成绩优秀的概率比乙校学生
优秀的概率大.
所以,结论不一样,不一样的原因在于样本容量,
当样本容量越大时,用样本估计总体的准确性会越高.
7.调查某医院一段时间内婴儿出生的时间和性别的关联性,得到如下的列联表:
单位:人
出生时间
性别 合计
晚上 白天
女 24 31 55
男 8 26 34
合计 32 57 89
依据 的独立性检验,能否认为性别与出生时间有关联?解释所得结论的实际含义.
【解析】由题意得 的观测值为:
,
∴在犯错的概率不超过0.1的前提下可以认为性别与出生时间有关联.
8.为考查某种药物预防疾病的效果,进行动物试验,得到如下列联表:单位:只疾病
药物 合计
未患病 患病
未服
75 66 141
用
服用 112 47 159
合计 187 113 300
依据 的独立性检验,能否认为药物有效呢?如何解释得到的结论?
【解析】由列联表可得
,
,
在犯错误的概率不超过 的前提下认为药物有效.
解释:由于 ,所以表示有小于 的可能性证明这两个事件无关,
也就是在犯错误的概率不超过 的前提下认为药物有效
易错点:对回归直线的性质理解不深刻
易错分析: 对回归直线的性质理解不到位,容易出错.
【易错题1】为了考查两个变量x和y之间的线性相关性,甲、乙两位同学各自独立地做10次和15次验,
并且利用线性回归方程,求得回归直线分别为 和 .已知两个人在试验中发现对变x的观测数据的平均
值都是s,对变量y的观测数据的平均值都为t,那么下列说法正确的( )
A. 与 相交于点(s,t)
B. 与 相交,交点不一定是(s,t)
C. 与 必关于点(s,t)对称
D. 与 必定重合
【答案】A
【解析】根据线性回归方程l 和l 都过样本中心点(s,t),
1 2∴ 与 相交于点 ,A说法正确.
故选A.
【易错题2】(多选题)对于变量 和变量 ,经过随机抽样获得成对样本数据 , ,2,3,…,
10,且 ,样本数据对应的散点大致分布在一条直线附近.利用最小二乘法求得经验回归方程:
,分析发现样本数据 对应的散点远离经验回归直线,将其剔除后得到新的经验回归直
线,则( )
A.变量 与变量 具有正相关关系
B.剔除后,变量 与变量 的样本相关系数变小
C.新的经验回归直线经过点
D.若新的经验回归直线经过点 ,则其方程为
【答案】AD
【解析】依题意,经验回归方程: ,
因此相关变量x,y具有正相关关系,A正确;
由剔除的是偏离直线较大的异常点,得剔除该点后,新样本数据的线性相关程度变强,
即样本相关系数的绝对值变大,B错误;
原样本中, ,
剔除一个偏离直线较大的异常点 后,新样本中, ,
因此剔除该异常点后的回归直线方程经过点 ,C错误;
由新的回归直线经过点 ,得新的回归直线斜率为 ,
设 ,将点 代入,得 ,所以其方程为 ,D正确.
故选:AD
答题模板:独立性检验
1、模板解决思路
解 决 独 立 性 检 验 问 题 的 关 键 , 是 在 已 知 列 联 表 的 前 提 下 , 利 用 公 式
求得 的值,然后与临界值 比较即可得出相关结论.
2、模板解决步骤第一步:提出零假设 与 相互独立,并给出在问题中的解释.
第二步:根据抽样数据整理出 列联表,计算 的值,并与临界值 比较.
第三步:根据检验规则得出结论.
【经典例题1】下表是某届某校本科志愿报名时,对其中304名学生进入高校时是否了解所学专业的调查
表:
了解所学专
不了解所学专业 合计
业
男生 63 117 180
女生 42 82 124
合计 105 199 304
根据表中数据,下列说法正确的是 .(填序号)
①性别与了解所学专业有关;
②性别与了解所学专业无关;
③女生比男生更了解所学专业.
【答案】②
【解析】 ,所以性别是否与了解所学专业无关.
故答案为:②
【经典例题2】某学校高三年级有学生1000人,经调查,其中750人经常参加体育锻炼(称为A类同学),
另外250人不经常参加体育锻炼(称为B类同学).现用按比例分配的分层抽样方法(按A类、B类分两
层)从该年级的学生中共抽查100人,如果以身高达到 作为达标的标准,对抽取的100人,得到以
下列联表(单位:人):
身高达标 身高不达标 总计
经常参加体育锻炼 40
不经常参加体育锻炼 15
总计 100
(1)完成上表;
(2)依据 的独立性检验,能否认为经常参加体育锻炼与身高达标有关系?
注: .
附表:0.10 0.05 0.025 0.010 0.005 0.001
2.706 3.841 5.024 6.635 7.879 10.828
【解析】(1)填写列联表(单位:人)如下:
身高达标 身高不达标 总计
经常参加体育锻炼 40 35 75
不经常参加体育锻炼 10 15 25
总计 50 50 100
(2)零假设为 :经常参加体育锻炼与身高达标无关联.
由列联表中的数据,
.
根据 的独立性检验,没有充分证据证明 不成立,即认为经常参加体育锻炼与身高达标无关联.
