 夜雨聆风
夜雨聆风





黑条遮不住秘密!这款神器竟能还原 PDF 隐藏文字
大家平时处理 PDF 的时候,是不是总觉得用黑条把敏感内容涂掉就万事大吉了?
但最近在 GitHub 上发现的一款神器 Unredact,直接打破了这个认知 —— 那些被黑条遮盖的文字,在它面前几乎形同虚设,而且全程在浏览器就能操作,不用借助任何服务器,简直太香了!
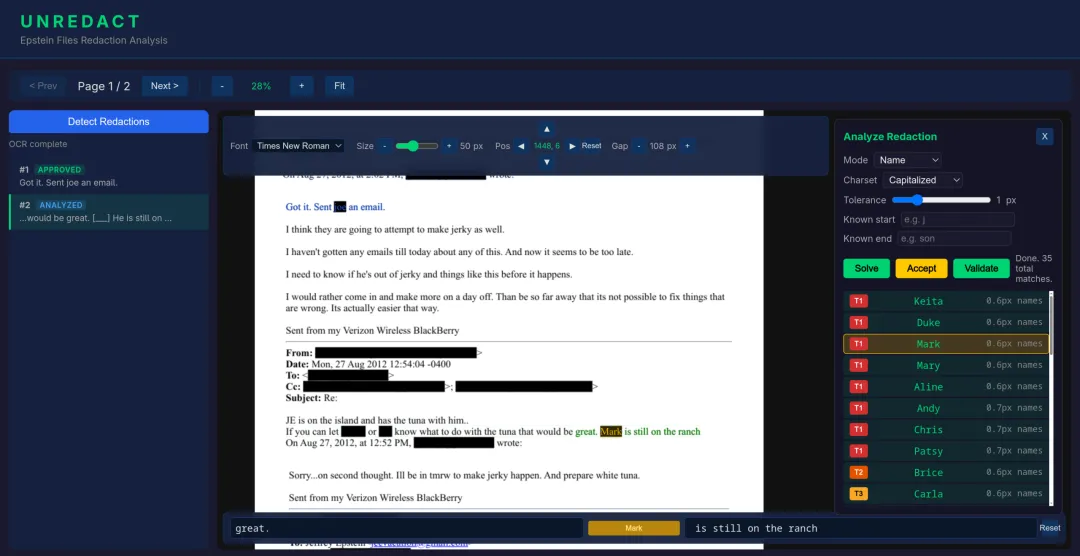
Unredact 是一款专门针对红 actPDF 的还原工具,它把计算机视觉、字体约束求解和大模型推理结合到了一起,三步就能精准推测出黑条下的隐藏文字。说直白点,它不是简单的 “擦除” 黑条,而是靠技术精准推算,还能让你直观验证结果,靠谱度拉满。
它的工作逻辑其实很好理解,全程都是技术流的精准操作。首先通过计算机视觉技术,用 OCR 提取 PDF 里能看到的文字,还能精准识别出黑条的位置,甚至连文档用的什么字体、字号,都能通过像素级匹配摸得一清二楚;接着利用字体的精准宽度数据,包括字符之间的间距,推算出哪些文字串的像素宽度,刚好能匹配黑条的遮挡范围;最后再让 Claude 大模型上场,结合上下文给这些候选文字打分,挑出最贴合语境的结果,双重筛选让答案更精准。
而且这款工具的操作特别友好,完全不用懂复杂的代码,普通人也能轻松上手。上传 PDF 的方式超简单,拖放或者文件选择都可以,上传后工具会自动完成 OCR 识别、红 act 区域和字体检测,黑条区域会直接高亮显示,一眼就能看到。
选中要分析的黑条后,就能根据需求选对应的破解模式,一共五种超实用:想还原名字选 Name 模式,全名就选 Full Name,邮箱、普通文字各有对应模式,要是短字符的红 act,用 Enumerate 模式枚举所有可能就好。选好模式后,还能自定义字符集、调整匹配精度,甚至知道首字母或尾字母的话,直接输入能让结果更精准,点击求解后,候选结果就会实时出来。
如果想让结果更靠谱,还能开启 AI 验证,只要输入 Claude 的 API 密钥,大模型就会结合上下文重新排序结果,最后选中候选答案,工具会把文字用绿色叠加在原 PDF 的黑条位置,只要字符和周围文字完美对齐,那这个答案基本就没跑了,还能手动微调字体、位置,确保精准。
更让人惊喜的是,Unredact 的所有操作都在浏览器端完成,数据不会上传到服务器,隐私性有保障。它的核心功能靠 Rust 编译的 WASM 模块实现,搭配 Tesseract.js 做 OCR,再加上 Claude 大模型的加持,技术栈很扎实,而且是开源的,完全免费使用。
不过这里也要提一句,这款工具的出现,也给我们提了个醒:简单用黑条给 PDF 做红 act,已经不再安全了。如果真的需要隐藏 PDF 里的敏感内容,一定要用专业的红 act 工具,彻底删除文字内容,而不是简单的视觉遮盖。
总的来说,Unredact 是一款特别有意思的技术工具,不仅让我们看到了计算机视觉和大模型结合的魅力,也让我们对信息安全有了新的认知。对于技术爱好者来说,这款开源工具也值得研究一下,不得不感慨,技术的发展真的让很多 “隐藏” 的秘密,都藏不住了。