 夜雨聆风
夜雨聆风





实用干货|Python 批量校验 Word 文档标号,精准识别跳号异常
日常办公中,我们经常需要检查 Word 文档里的编号是否规范 —— 比如 “3、……5.” 这种缺号且中间有内容的情况需要重点标注,但 “3、5、9、”“1、1、1、” 这类无间隔的标号却无需判定为异常。今天就分享一款定制化的 Python 工具,帮你批量搞定 Word 文档标号校验,告别手动逐页检查的低效操作!

一、工具核心开发逻辑
这款工具的核心是精准区分 “合规标号” 和 “异常标号”,完全贴合实际办公需求,整体开发逻辑分为 3 个核心步骤:
1. 标号提取:精准识别目标标号类型
首先遍历 Word 文档的每个段落,通过正则表达式匹配所有需要检查的标号类型,同时记录标号的关键信息(便于后续校验):
- 匹配的标号类型
(覆盖办公常用标号):✅ 阿拉伯数字 + 顿号 / 点:1、 2. 3、✅ 汉字数字 + 顿号 / 点:一、 贰。三、✅ 括号标号(眼镜标号):(1) (2) (壹) (贰)✅ “一是 / 二是” 类:一是 二是 叁是✅ 带圈数字:① ② ③ ⑩ - 记录的关键信息
:标号文本、数字值(如 “壹、”→1)、所在段落索引、字符位置、段落原文(用于后续校验中间内容)。
2. 分组校验:按段落划分 “连续文本块”
将提取的标号按段落分组(同一段落视为 “连续文本块”,跨段落不校验),避免误判跨段落的正常标号:
-
同一段落内的标号:视为连续上下文,需要校验; -
不同段落的标号:视为独立内容,无需校验。
3. 异常判定:仅识别 “跳号 + 中间有内容” 的异常
这是工具的核心规则,完全贴合实际需求:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
判定逻辑:仅当「标号跳号(下一个标号数字>当前数字 + 1)」且「两个标号之间有非空内容」时,才判定为异常。
二、完整代码(开箱即用)
import osimport refrom docx import Document # 需要安装python-docx库# 大写汉字数字映射CHINESE_NUM_MAP = {'零': 0, '一': 1, '二': 2, '三': 3, '四': 4, '五': 5,'六': 6, '七': 7, '八': 8, '九': 9, '十': 10,'壹': 1, '贰': 2, '叁': 3, '肆': 4, '伍': 5,'陆': 6, '柒': 7, '捌': 8, '玖': 9, '拾': 10}# 带圈数字映射CIRCLED_NUM_MAP = {'①': 1, '②': 2, '③': 3, '④': 4, '⑤': 5,'⑥': 6, '⑦': 7, '⑧': 8, '⑨': 9, '⑩': 10,'⑪': 11, '⑫': 12, '⑬': 13, '⑭': 14, '⑮': 15,'⑯': 16, '⑰': 17, '⑱': 18, '⑲': 19, '⑳': 20}def extract_labels_with_context(file_path):"""提取标号并保留上下文(段落+位置),用于判断是否为连续文本块:param file_path: Word文件路径:return: 标号列表,格式:[(标号文本, 数字值, 段落索引, 字符位置, 段落文本), ...] """try: doc = Document(file_path) labels = []# 遍历每个段落,记录段落索引和文本for para_idx, para in enumerate(doc.paragraphs): para_text = para.text# 定义标号匹配规则label_patterns = [ (r'(\d+[、.])', lambda x: int(x[:-1])), (r'([零一二三四五六七八九十壹贰叁肆伍陆柒捌玖拾]+[、.])',lambda x: CHINESE_NUM_MAP.get(x[:-1], None)), (r'([((][零一二三四五六七八九十壹贰叁肆伍陆柒捌玖拾\d]+[))])',lambda x: CHINESE_NUM_MAP.get(x[1:-1], int(x[1:-1])) if x[1:-1] in CHINESE_NUM_MAP else (int(x[1:-1]) if x[1:-1].isdigit() else None)), (r'([零一二三四五六七八九十壹贰叁肆伍陆柒捌玖拾]+是)',lambda x: CHINESE_NUM_MAP.get(x[:-1], None)), (r'([' + ''.join(CIRCLED_NUM_MAP.keys()) + '])',lambda x: CIRCLED_NUM_MAP.get(x, None)) ]# 匹配当前段落的标号for pattern, convert_func in label_patterns:for match in re.finditer(pattern, para_text): label_text = match.group(1) char_pos = match.start(1)try: label_num = convert_func(label_text)if label_num is not None and label_num > 0: labels.append((label_text, label_num, para_idx, char_pos, para_text))except:continue# 按段落索引+字符位置排序(文档内实际顺序)labels.sort(key=lambda x: (x[2], x[3]))return labelsexcept Exception as e:print(f"读取文件 {file_path} 出错:{str(e)}")return []def check_continuous_label_error(labels):"""校验标号异常:仅判定「同一连续文本块内跳号且中间有内容」的情况 规则: 1. 同数字连续(1、1、)→ 正常 2. 不同数字无间隔连续(3、5、9、)→ 正常 3. 同一文本块内标号跳号且中间有内容(3、……5.)→ 异常 """if len(labels) <= 1:return [] errors = []# 按段落分组(同一段落视为连续文本块,跨段落不校验)para_groups = {}for label in labels: para_idx = label[2]if para_idx not in para_groups: para_groups[para_idx] = [] para_groups[para_idx].append(label)# 校验每个段落内的标号for para_idx, para_labels in para_groups.items():if len(para_labels) <= 1:continue# 遍历段落内的标号,检查连续标号间的文本for i in range(len(para_labels) - 1): curr_label = para_labels[i] next_label = para_labels[i + 1] curr_num = curr_label[1] next_num = next_label[1] curr_pos = curr_label[3] + len(curr_label[0]) # 标号结束位置next_pos = next_label[3] # 下一个标号起始位置para_text = curr_label[4] # 段落文本# 提取两个标号之间的文本middle_text = para_text[curr_pos:next_pos].strip()# 判定规则:跳号(next_num > curr_num+1)且中间有非空内容 → 异常if next_num > curr_num + 1 and len(middle_text) > 0: err_desc = f"同一段落内跳号({curr_num}→{next_num},缺失{curr_num + 1}~{next_num - 1}),且中间有内容:「{middle_text}」"errors.append((next_label[0], next_num, para_idx, next_pos, err_desc))return errorsdef batch_check_label(folder_path):"""批量检查Word文档标号异常(精准匹配需求) """if not os.path.exists(folder_path):print(f"❌ 错误:文件夹 {folder_path} 不存在!")returnword_files = [f for f in os.listdir(folder_path) if f.lower().endswith('.docx')]if not word_files:print("ℹ️ 未找到任何.docx格式的Word文件!")return for file_name in word_files: file_path = os.path.join(folder_path, file_name)print(f"\n========== 检查文件:{file_name} ==========") labels = extract_labels_with_context(file_path)if not labels:print("ℹ️ 未找到指定类型的标号")continue# 打印提取的标号print(f"📌 提取的标号序列(按文档顺序):")for idx, (text, num, para_idx, char_pos, _) in enumerate(labels, 1):print(f" 第{idx}个:{text} (数字值:{num},段落{para_idx + 1},位置{char_pos})")# 校验异常errors = check_continuous_label_error(labels)if errors:print("❌ 发现标号异常:")for text, num, para_idx, char_pos, err_desc in errors:print(f" 标号:{text},段落{para_idx + 1},位置{char_pos} → {err_desc}")else:print("✅ 无异常:同数字连续/不同数字无间隔连续均正常,无跳号且中间有内容的情况")# ------------------- 主程序执行 -------------------if __name__ == "__main__":# 替换为你的Word文件路径TARGET_FOLDER = r"D:\需要检查的文档文件夹"batch_check_label(TARGET_FOLDER) |
-
Windows 示例: r"D:\办公文档\需要检查的文档" -
Mac/Linux 示例: "/Users/XXX/Documents/待检查文件"
步骤 5:运行代码
保存修改后的代码,双击运行(或在命令提示符 / 终端中输入python 文件名.py运行),工具会自动:
-
遍历文件夹下所有.docx 文件; -
提取每个文件中的目标标号; -
校验并输出异常标号(含段落、位置、异常原因)。
步骤 6:查看检查结果
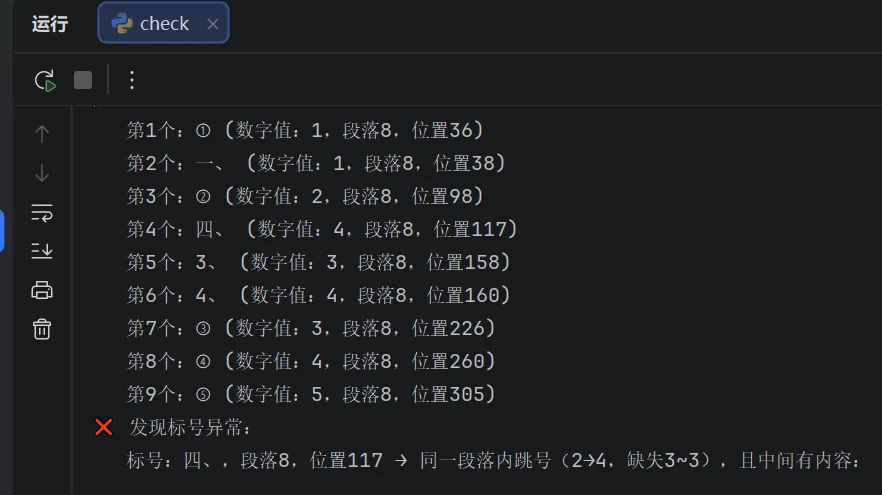
运行完成后,终端 / 命令提示符会输出每个文件的检查结果:
-
✅ 无异常:直接提示 “无异常”; -
❌ 有异常:标注异常标号的位置和原因,可直接定位到文档中修改。 -
四、开发 & 使用注意点
1. 开发注意点
- 标号扩展
:如果需要支持更大的带圈数字(如㉑、㉒),只需在 CIRCLED_NUM_MAP中补充键值对(如'㉑': 21); - 正则优化
:如果需要新增标号类型(如 “第一、第二”),可在 label_patterns中添加对应的正则规则; - 异常捕获
:代码已包含基础的异常捕获,避免单个文件出错导致整体中断。
2. 使用注意点
- 文件格式
:仅支持.docx 格式,.doc 格式需要先转换为.docx; - 路径格式
:文件夹路径不要包含中文空格(或确保编码正常),路径前必须加 r; - 跨段落不校验
:如果需要校验跨段落的标号,可修改 check_continuous_label_error函数,去掉按段落分组的逻辑。
五、总结
这款工具完全贴合办公场景的标号校验需求,既避免了 “一刀切” 的误判(如把 “3、5、9、” 判定为异常),又精准识别真正的跳号问题(如 “3、……5.”)。只需简单几步,就能批量完成 Word 文档标号校验,大幅提升办公效率!
如果有其他定制化需求(比如新增标号类型、导出检查报告),可以基于这个基础代码调整,也欢迎在评论区交流~
