 夜雨聆风
夜雨聆风





标准化工具接入:MCP 不是"炫技",是"解耦能力"
上一篇,我们用 LangGraph 实现了”可暂停、可恢复、可审计”的图编排——员工提交高风险申请,系统自动暂停等待 IT 管理员审批,审批完成后无缝恢复流程。
但流程图里每一个节点都要调用工具:知识库检索、创建工单、发钉钉通知……
随着接入的内部系统越来越多,一个问题悄悄爆发了。
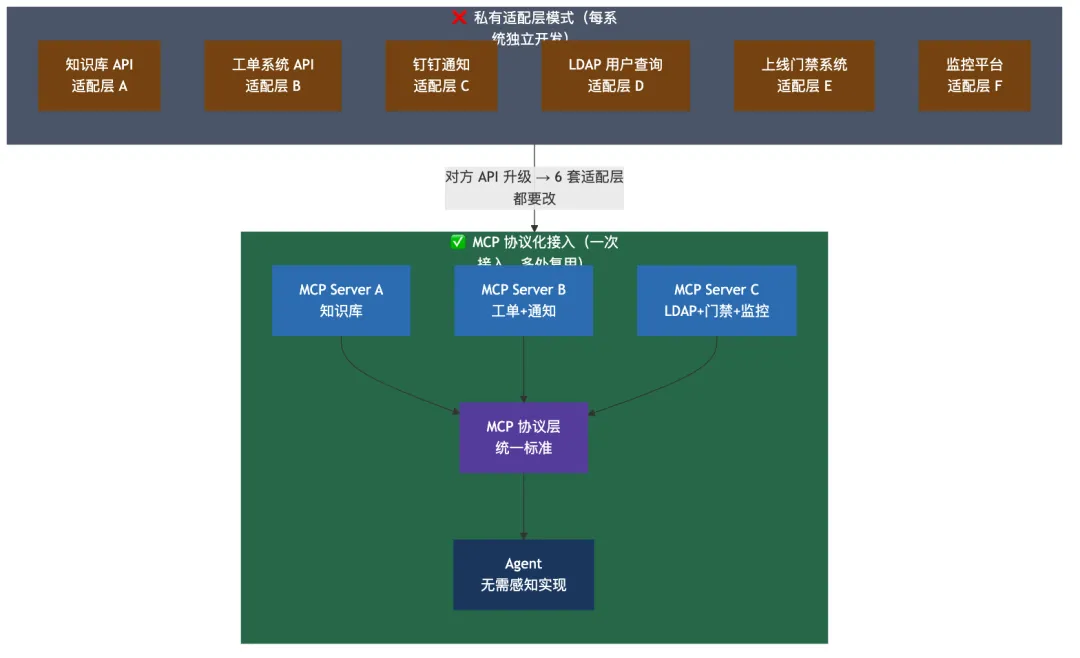
1. 工具接入的隐形债务
我们先来还原一个真实的工程场景。
企业知识助手上线第一个月,需要接 2 个系统:
-
• search_knowledge_base:内部知识库 API -
• create_ticket:工单系统 API
工程师各写了一套适配层。问题不大。
三个月后,产品需求增加:
-
• 接钉钉机器人通知审批结果 -
• 接 LDAP 查询用户权限 -
• 接上线门禁系统自动发布 -
• 接监控平台查报警
现在是 6 套适配层。每套需要处理:认证、错误码映射、超时重试、schema 注册。
半年后,对方团队升级 API——你的 6 套适配层,可能有 4 套需要改。
这时候,不是工程师不够努力,是架构缺少了一个层:工具标准化层。
没有统一标准,就是”每接一个系统,欠一笔技术债”。
2. MCP 是什么:Agent 的”USB-C 端口”
官方给的类比非常准确:
MCP(Model Context Protocol)就像 AI 应用的 USB-C 接口。USB-C 之前,每个厂商用不同接口,消费者要备一抽屉线;USB-C 之后,统一标准,任何设备即插即用。
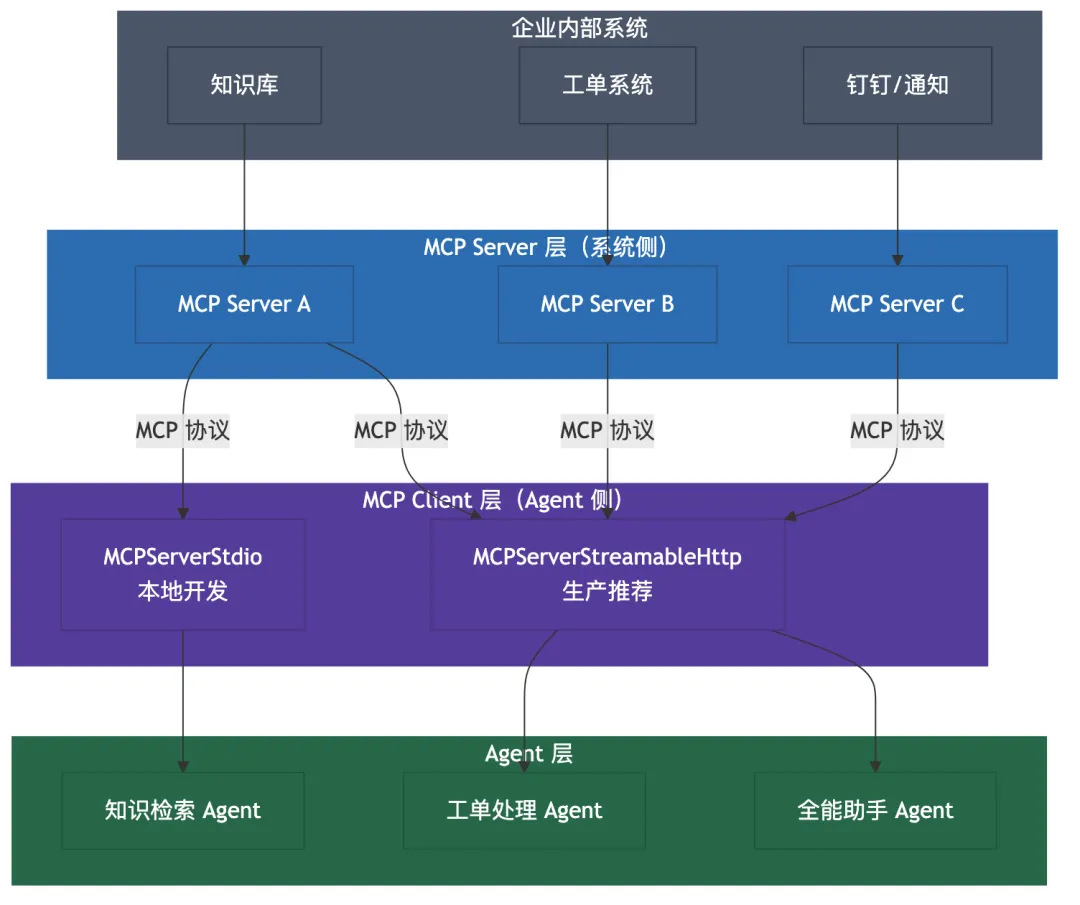
对 Agent 开发来说,MCP 的价值是一样的:
-
• **工具提供方(系统侧)**按 MCP 协议暴露能力 → MCP Server -
• **工具消费方(Agent 侧)**按 MCP 协议调用工具 → MCP Client -
• Agent 只认协议,不关心背后是知识库、工单系统还是钉钉
2.1 三个角色,一张图
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
命名注意:OpenAI Agents SDK 中,Client 侧的对象命名为
MCPServerStdio、MCPServerStreamableHttp——名字里带 “Server”,但它们实际扮演的是 Client 角色(负责连接和调用)。这是 SDK 的命名惯例,不要被名字误导。
这个分层解耦了两件事:
-
1. 工具实现与 Agent 逻辑解耦 → 工具升级不影响 Agent 代码 -
2. 工具注册标准化 → 一个 Server,被 N 个 Agent 复用,无需重复注册
2.2 传输模式:三种,按场景选
MCP 支持三种传输模式,选错了会埋坑:
|
|
|
|
| stdio |
|
|
| Streamable HTTP |
|
|
| SSE(HTTP + Server-Sent Events) |
|
|
迁移建议:如果你对接的系统还在用 SSE 传输,尽快协商迁移到 Streamable HTTP。SSE 在 MCP 规范中已标注废弃,后续版本不保证兼容。
2.3 补充:Hosted MCP(托管模式)
OpenAI Agents SDK 还提供了第四种接入方式:Hosted MCP(HostedMCPTool)。
区别在于:不需要你的代码发起工具调用,而是直接告诉 OpenAI 的 Responses API”去这个公开地址的 MCP Server 拿工具”,模型侧完成工具列举与调用。
适合场景:对接已经公开部署的第三方 MCP Server(如 GitHub MCP、公开数据接口),且不需要自己管理连接生命周期。
企业内部系统优先用 Streamable HTTP,因为你需要控制认证、权限和审计。
3. 可复现实战:把 Mock API 封装为 MCP Server
前几篇使用了两个 Mock API:
-
• search_knowledge_base(query, category)→ 检索知识库 -
• create_ticket(user_id, title, description, category, priority)→ 创建工单
这一节,把它们封装为一个独立的 MCP Server,Agent 通过 MCP 协议调用。
3.1 定义 Mock API
# mock_api.py
import datetime
defsearch_knowledge_base(query: str, category: str | None = None) -> list[dict]:
"""模拟知识库检索"""
db = [
{"id": "doc_001", "title": "VPN 连接指南", "content": "下载客户端...", "category": "IT"},
{"id": "doc_002", "title": "请假流程", "content": "登录 HR 系统...", "category": "HR"},
]
results = [d for d in db if query.lower() in d["title"].lower() or query.lower() in d["content"].lower()]
if category:
results = [d for d in results if d["category"] == category]
return results
defcreate_ticket(
user_id: str,
title: str,
description: str,
category: str,
priority: str = "Normal",
) -> dict:
"""模拟创建工单"""
ticket_id = f"TKT-{datetime.date.today().strftime('%Y%m%d')}-{hash(title) % 10000:04d}"
return {
"ticket_id": ticket_id,
"user_id": user_id,
"title": title,
"description": description,
"category": category,
"priority": priority,
"status": "Open",
"created_at": datetime.datetime.now().isoformat(),
}3.2 实现 MCP Server
使用 mcp 库将 Mock API 封装为 MCP Server:
# knowledge_mcp_server.py
# 依赖:pip install mcp openai-agents
from mcp.server.fastmcp import FastMCP
from mock_api import search_knowledge_base, create_ticket
mcp = FastMCP("enterprise-knowledge-server")
@mcp.tool()
defsearch_kb(query: str, category: str | None = None) -> list[dict]:
"""搜索企业知识库。返回与查询相关的文档列表。
Args:
query: 搜索关键词
category: 可选的知识分类,如 'IT' 或 'HR'
"""
return search_knowledge_base(query, category)
@mcp.tool()
defsubmit_ticket(
user_id: str,
title: str,
description: str,
category: str,
priority: str = "Normal",
) -> dict:
"""创建一个新的员工工单。
Args:
user_id: 提交人员工 ID
title: 工单标题(50字以内)
description: 问题详细描述
category: 工单分类,如 'IT_Access'、'HR_Leave'
priority: 优先级,可选 Low/Normal/High/Urgent
"""
return create_ticket(user_id, title, description, category, priority)
if __name__ == "__main__":
# stdio 模式启动(开发调试)
mcp.run(transport="stdio")关键点:
-
• @mcp.tool()装饰器自动从函数签名生成工具 schema -
• docstring 就是工具描述,模型靠描述决定是否调用工具,写好描述比写好代码更重要 -
• Args:段自动映射为参数描述,推荐保留
3.3 Agent 接入:stdio 模式(开发调试)
# agent_with_mcp.py
import asyncio
from agents import Agent, Runner
from agents.mcp import MCPServerStdio
asyncdefmain():
# 启动本地 MCP Server 进程
asyncwith MCPServerStdio(
name="enterprise-knowledge-server",
params={
"command": "python",
"args": ["knowledge_mcp_server.py"],
},
) as server:
agent = Agent(
name="知识助手",
instructions="你是企业知识助手。优先搜索知识库回答问题;知识库无法解决时,帮用户创建工单。",
mcp_servers=[server],
# 停机条件:最多 20 轮工具调用
)
result = await Runner.run(
agent,
"我的 VPN 连不上,帮我查查怎么解决",
max_turns=20,
)
print(result.final_output)
asyncio.run(main())3.4 Agent 接入:HTTP 模式(生产环境)
# agent_production.py
import asyncio
import os
from agents import Agent, Runner
from agents.mcp import MCPServerStreamableHttp
asyncdefmain():
token = os.environ["MCP_SERVER_TOKEN"]
asyncwith MCPServerStreamableHttp(
name="enterprise-knowledge-server",
params={
"url": "https://mcp.internal.company.com/knowledge",
"headers": {"Authorization": f"Bearer {token}"},
"timeout": 10, # 工具调用超时 10s
},
cache_tools_list=True, # 工具列表稳定时开启缓存,减少 list_tools() 调用
max_retry_attempts=3, # 网络抖动时自动重试
) as server:
agent = Agent(
name="知识助手",
instructions="你是企业知识助手。优先搜索知识库回答问题;知识库无法解决时,帮用户创建工单。",
mcp_servers=[server],
mcp_config={
"convert_schemas_to_strict": True, # 尝试将工具 schema 转为严格模式
"failure_error_function": None, # 工具调用失败时抛异常(而非返回错误文本给模型)
},
)
result = await Runner.run(
agent,
"帮我申请生产数据库只读权限,用于排查订单系统 bug",
max_turns=20,
)
print(result.final_output)
asyncio.run(main())3.5 工具过滤:最小权限原则
不同角色的 Agent 应该看到不同的工具子集。知识库 Agent 不应该有权限调用工单审批工具。
from agents.mcp import MCPServerStreamableHttp, create_static_tool_filter
# 知识检索 Agent:只能搜索知识库
kb_server = MCPServerStreamableHttp(
name="enterprise-knowledge-server",
params={"url": "https://mcp.internal.company.com/knowledge", ...},
tool_filter=create_static_tool_filter(
allowed_tool_names=["search_kb"] # 只暴露搜索工具
),
)
# 工单处理 Agent:只能创建工单
ticket_server = MCPServerStreamableHttp(
name="enterprise-knowledge-server",
params={"url": "https://mcp.internal.company.com/knowledge", ...},
tool_filter=create_static_tool_filter(
allowed_tool_names=["submit_ticket"] # 只暴露工单工具
),
)
# 将各自的过滤 Server 绑定给对应 Agent(在 async with 上下文内使用)
# kb_agent = Agent(name="知识助手", mcp_servers=[kb_server], ...)
# ticket_agent = Agent(name="工单助手", mcp_servers=[ticket_server], ...)如果需要更复杂的动态过滤(比如根据用户角色决定是否暴露某工具):
from agents.mcp import ToolFilterContext
asyncdefrole_based_filter(context: ToolFilterContext, tool) -> bool:
"""根据运行上下文中的用户角色动态过滤工具"""
user_role = (context.run_context.context or {}).get("user_role", "employee")
# 只有 IT 管理员才能看到工单提交工具(普通员工只能搜索知识库)
if tool.name == "submit_ticket"and user_role != "it_admin":
returnFalse
returnTrue
# 将动态过滤器挂载到 Server(在 async with 上下文内使用)
# async with MCPServerStreamableHttp(
# name="enterprise-knowledge-server",
# params={"url": "https://mcp.internal.company.com/knowledge", ...},
# tool_filter=role_based_filter, # 传入可调用对象
# ) as server:
# agent = Agent(name="知识助手", mcp_servers=[server], ...)3.6 多 Server 统一管理
企业场景通常需要同时接入多个系统:
# multi_server_agent.py
import asyncio
from agents import Agent, Runner
from agents.mcp import MCPServerManager, MCPServerStreamableHttp
asyncdefmain():
servers = [
MCPServerStreamableHttp(
name="knowledge-server",
params={"url": "https://mcp.internal.company.com/knowledge", ...},
cache_tools_list=True,
),
MCPServerStreamableHttp(
name="ticket-server",
params={"url": "https://mcp.internal.company.com/ticket", ...},
cache_tools_list=True,
),
MCPServerStreamableHttp(
name="notification-server",
params={"url": "https://mcp.internal.company.com/notify", ...},
),
]
asyncwith MCPServerManager(
servers,
drop_failed_servers=True, # 某个 Server 连接失败时,不影响其他 Server
connect_timeout_seconds=30, # 单个 Server 连接超时
) as manager:
if manager.failed_servers:
# 记录失败信息,发告警
print(f"以下 Server 连接失败:{[s.name for s in manager.failed_servers]}")
agent = Agent(
name="全能助手",
instructions="你是企业全能助手,可以搜索知识库、处理工单、发送通知。",
mcp_servers=manager.active_servers, # 只传入成功连接的 Server
)
result = await Runner.run(agent, "VPN 连不上,帮我查原因并创建工单", max_turns=20)
print(result.final_output)
asyncio.run(main())关键行为:drop_failed_servers=True(默认)确保单个系统故障不会传导给整个 Agent,failed_servers 提供失败信息供告警系统使用。
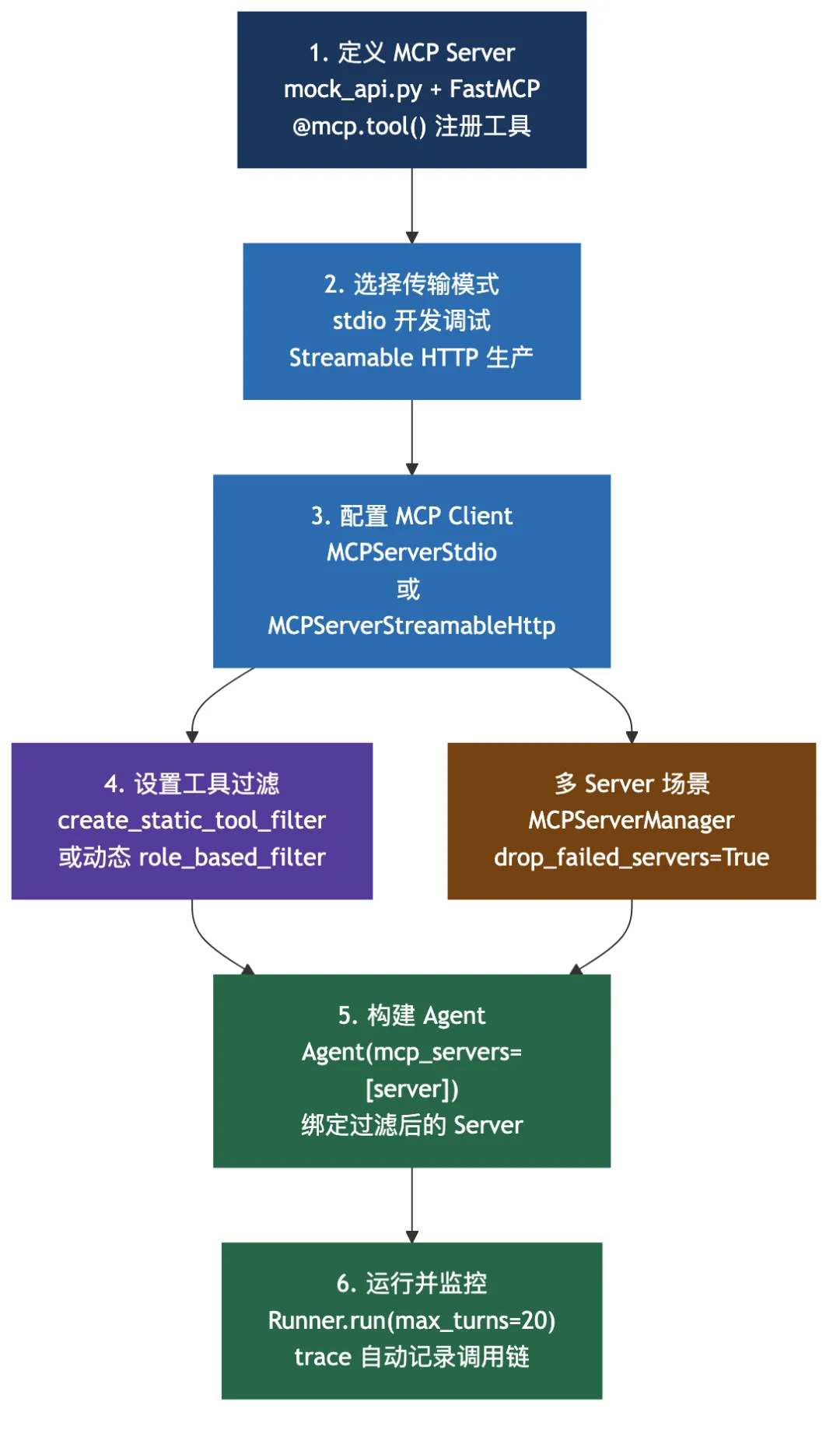
以下是完整的 MCP 实战接入流程——从定义 Server 到运行监控的六个关键步骤,以及多 Server 场景的分叉路径:
4. 反模式与排查
4.1 三大反模式
反模式 1:每个 Agent 各自连接同一 MCP Server
# ❌ N 个 Agent 产生 N 条连接,资源浪费,可能触发服务器连接数限制
agent_kb = Agent(mcp_servers=[MCPServerStreamableHttp(...)])
agent_ticket = Agent(mcp_servers=[MCPServerStreamableHttp(...)]) # 重复创建相同连接# ✅ MCPServerManager 共享连接
asyncwith MCPServerManager(servers) as manager:
agent_kb = Agent(mcp_servers=[manager.active_servers[0]])
agent_ticket = Agent(mcp_servers=[manager.active_servers[0]])反模式 2:高频调用场景不开启 cache_tools_list
每次 Runner.run() 都会调用 list_tools() 获取工具列表。远程 MCP Server 每次 list 可能需要 50-200ms。
# ❌ 工具定义稳定,但每次都重新拉取
MCPServerStreamableHttp(name="server", params={...})
# ✅ 工具稳定时开启缓存
MCPServerStreamableHttp(
name="server",
params={...},
cache_tools_list=True,
)
# 工具有更新时:
# server.invalidate_tools_cache()反模式 3:所有工具暴露给所有 Agent
# ❌ 知识库 Agent 能看到工单审批工具,权限过大
agent = Agent(mcp_servers=[server_with_all_tools])
# ✅ 按角色过滤,最小权限
agent = Agent(
mcp_servers=[server_with_kb_filter], # 只暴露 search_kb
)4.2 企业接入四大检查项
认证:Token 从环境变量读取,不要硬编码在代码里。
# ❌ 危险:Token 泄露到版本控制
params={"headers": {"Authorization": "Bearer sk-1234..."}}
# ✅ 从环境变量读取(import os 见第 3.4 节)
params={"headers": {"Authorization": f"Bearer {os.environ['MCP_TOKEN']}"}}权限:高风险工具配置人工审批。
# 示例:admin-server 上额外暴露了删除/批量变更等高风险工具
asyncwith MCPServerStreamableHttp(
name="admin-server",
params={"url": "..."},
require_approval={
"always": {"tool_names": ["delete_ticket", "bulk_update_status"]}, # 高风险,始终审批
"never": {"tool_names": ["search_kb", "get_ticket_status"]}, # 只读,无需审批
},
) as server:
...审计:MCP 工具调用自动出现在 OpenAI SDK 的 trace 中,包含调用的 Server 名称和工具名称。接入可观测平台后,可以按工单 ID / 用户 ID 追踪完整调用链。
失败隔离:drop_failed_servers=True + failed_servers 监控 + 告警。
4.3 诊断检查清单
-
• MCP Server 是否有健康检查端点( /health)? -
• cache_tools_list是否根据工具更新频率合理设置? -
• 工具 schema 是否启用了严格模式( convert_schemas_to_strict: True)? -
• failure_error_function的行为是否符合预期(抛异常 vs 返回模型可见错误)? -
• 高风险工具是否已配置 require_approval? -
• 是否有工具调用的 trace 和告警覆盖?
5. 上线检查与下一篇衔接
5.1 交付物:MCP 接入检查清单(开发/安全/运维三视角)
开发视角
-
• MCP Server 工具 schema 已通过测试(参数类型、必填项、描述) -
• 传输模式选型正确:开发用 stdio,生产用 Streamable HTTP -
• 工具 docstring 描述准确(模型靠描述决定是否调用) -
• 工具过滤已配置,按 Agent 角色实现最小权限 -
• 多 Server 使用 MCPServerManager 统一管理,非各自独立连接
安全视角
-
• 认证 Token 从环境变量读取,不硬编码 -
• 高风险工具(删除、批量变更、提权)已配置 require_approval="always" -
• 工具调用已纳入 trace 审计 -
• Server 侧有速率限制,防止 Agent 失控批量调用 -
• 工具过滤覆盖所有 Agent 角色,无遗漏
运维视角
-
• MCP Server 有健康检查 + 容器重启策略 -
• max_retry_attempts=3已配置,覆盖网络抖动场景 -
• failed_servers监控已接入告警(Slack/钉钉) -
• cache_tools_list=True时,工具版本变更后调用invalidate_tools_cache() -
• 连接超时 connect_timeout_seconds已设置(建议 30s)
5.2 停机条件汇总
本篇涉及的停机条件(必须显式配置,防止 Agent 失控):
|
|
|
|
|
|
|
params["timeout"]=10 |
|
|
|
connect_timeout_seconds=30 |
|
|
|
max_retry_attempts=3 |
|
|
|
Runner.run(max_turns=20) |
5.3 下一篇衔接
到这里,我们已经完成了核心工程能力的三层搭建:
-
• 多 Agent 协作(第 3 篇):拆角色、做分工、设计 Handoff -
• 图编排与人工审批(第 4 篇):让复杂流程可暂停、可恢复、可审计 -
• MCP 标准化工具层(本篇):让工具接入有协议、可复用、可治理
下一个问题自然浮现:这一套能力,用哪个框架来实现?
OpenAI SDK 上手快、工具链完整,但流程控制能力相对有限;LangGraph 的状态机非常强大,但学习曲线陡;AutoGen 的多 Agent 协作范式丰富,适合研究型场景;ADK(Google Agent Development Kit)的安全评测体系最完整,但生态成熟度还在追赶。
第 6 篇:框架横评与选型——从六个维度评估 OpenAI SDK / AutoGen / LangGraph / ADK,给出不同团队阶段的可落地决策树。