 夜雨聆风
夜雨聆风





MegatronApp 论文核心技术学习研究
一、核心贡献与系统架构概览
MegatronApp 是一项面向万亿参数级大语言模型(LLM)分布式训练的综合性管理工具链,旨在解决当前大规模训练中普遍存在的性能瓶颈、系统不透明与调试困难等核心挑战。该系统并非对底层训练框架的替代,而是通过四个正交且可组合的轻量级模块,在不修改主干代码的前提下,显著增强 Megatron-LM 等主流框架的可观测性、效率与灵活性。
其核心贡献在于构建了一个从“黑箱运行”到“精细管控”的闭环体系,将原本复杂、耗时的故障排查与性能优化过程,转变为自动化、分钟级可完成的常规操作。这四大模块协同工作,共同提升了训练作业的整体吞吐、集群资源利用率和开发者的生产力。
以下表格总结了 MegatronApp 的四大核心组件及其功能定位:
|
|
|
|
|---|---|---|
| MegaScan |
|
|
| MegaFBD |
|
|
| MegaDPP |
|
|
| MegaScope |
|
|
这一模块化设计确保了系统的高内聚、低耦合特性,所有功能均可通过简单的运行时标志独立启用或关闭,为生产环境下的大模型训练提供了前所未有的控制力与洞察力。
二、关键技术模块深度解析
MegatronApp 的技术突破并非源于单一机制,而是通过四个高度专业化模块的协同设计,在分布式训练的性能监控、资源调度、执行控制与可解释性层面实现了系统性创新。以下对各模块的核心技术实现进行逐一分解。
1. MegaScan:基于CUDA事件的细粒度追踪与根因定位
MegaScan 构建了一个低侵入、高保真的运行时诊断系统,其核心技术在于将硬件级时间测量与分布式语义分析相结合。
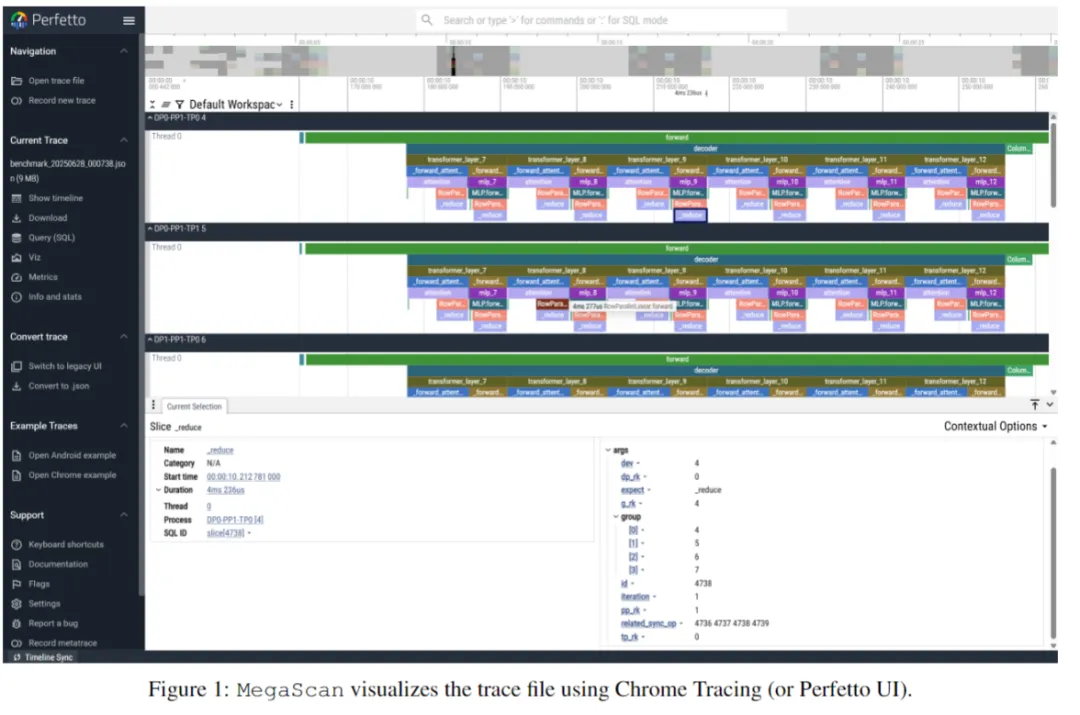
非阻塞式延迟捕获
利用 CUDA Events 在计算核或通信调用前后插入轻量级时间戳,通过cudaEventElapsedTime异步获取精确执行时长,避免了传统同步计时对训练主路径的干扰。
跨秩全局时序重建
各 GPU 独立生成本地 trace 后,由 Rank 0 汇聚并依据同步通信操作(如 AllReduce, Send/Recv)作为时钟对齐锚点,消除多设备间时钟漂移,构建统一的全局时间线。
多维度异常检测算法
标准化输出与分析接口
采用 Chrome Tracing 格式输出,支持直接加载至标准可视化工具;附加微批次ID、通信体积等元数据,为后续分析提供丰富上下文。
该设计从根本上解决了传统监控工具缺乏因果推理能力的问题,使慢节点的根因定位从“猜测”变为“可验证”。
2. MegaFBD:异构感知的前向-反向解耦调度
MegaFBD 打破了前向与反向传播必须绑定在同一物理设备的传统范式,通过逻辑解耦释放了异构集群的调度潜力,构思很巧妙,但实际训练效果非常复杂,不好确定。
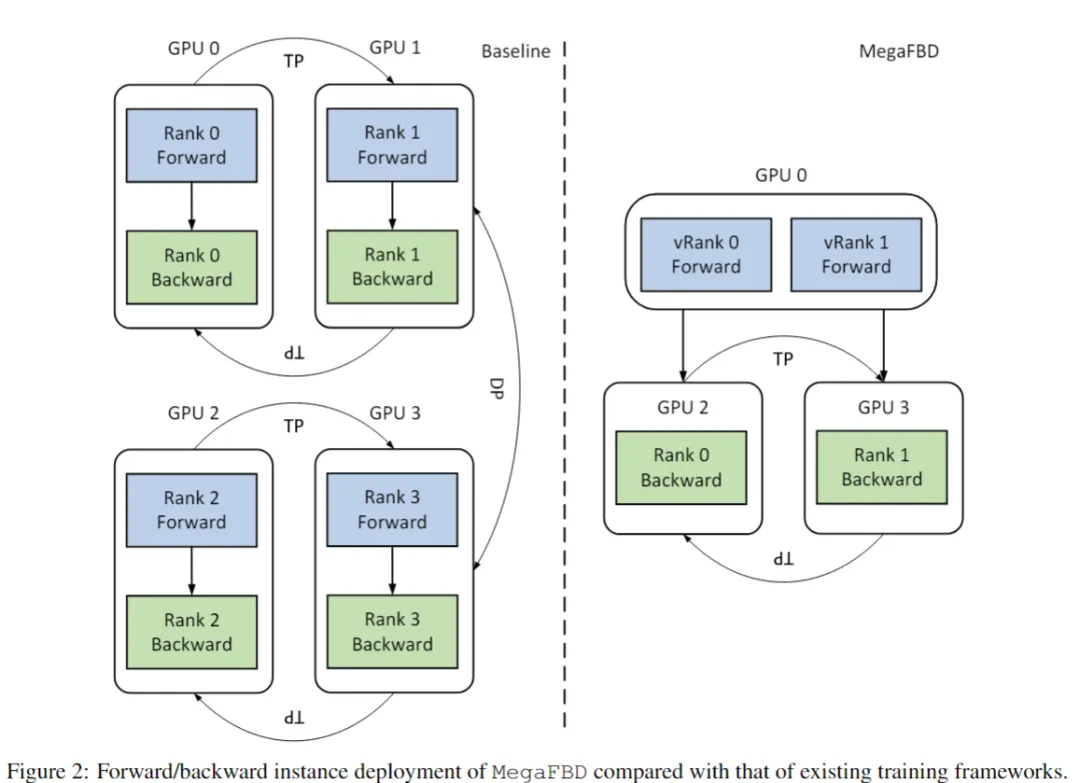
双命名空间抽象
差异化并行配置
前向阶段通常内存占用较低,因此可配置更小的并行度以减少通信开销;而反向阶段则部署在高性能GPU上,保障梯度计算效率。
防死锁通信协调器
引入中心化控制线程管理跨GPU集体通信请求,通过位向量表 + 全局 AllReduce OR 操作实现组内一致性检查,确保所有成员就绪后才发起通信,彻底规避因请求不一致导致的死锁。
此架构特别适用于 CPU/GPU/NPU 混合环境,能将轻量级计算任务迁移至成本更低的设备,显著提升整体集群利用率。
3. MegaDPP:动态自适应流水线调度
MegaDPP 将静态的流水线执行转变为可根据运行时状态动态调整的弹性调度过程,极大增强了系统的鲁棒性。
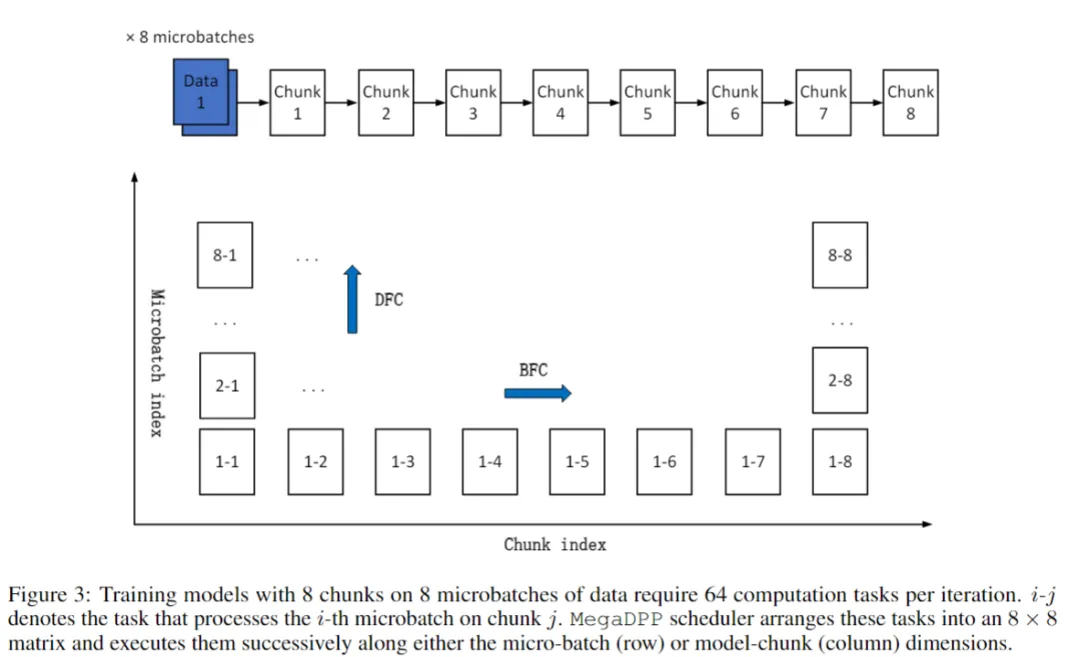
矩阵式任务组织模型
将每轮迭代视为一个 $N \times M$ 的任务矩阵(N为模型chunk数,M为微批次数),调度即在此矩阵上的遍历路径规划。
双模式遍历策略
轻量级异步P2P库
构建于共享内存与RDMA之上,配备四缓冲区(前向输入/输出、反向输入/输出)与双任务队列,允许主计算线程始终选取最高优先级就绪输入,最大化计算与通信重叠。
资源感知决策
调度器根据实时内存压力与网络带宽状况,在 DFC 与 BFC 间动态切换,或在 BFC 模式下以“尽力而为”方式执行,防止 OOM 错误。
该设计突破了传统 1F1B 固定调度的僵化限制,使系统能够主动适应链路波动、GPU降频等现实扰动。
4. MegaScope:低开销可交互解释性框架
MegaScope 解决了大规模模型内部状态观测的I/O瓶颈,并提供了前所未有的实验干预能力。
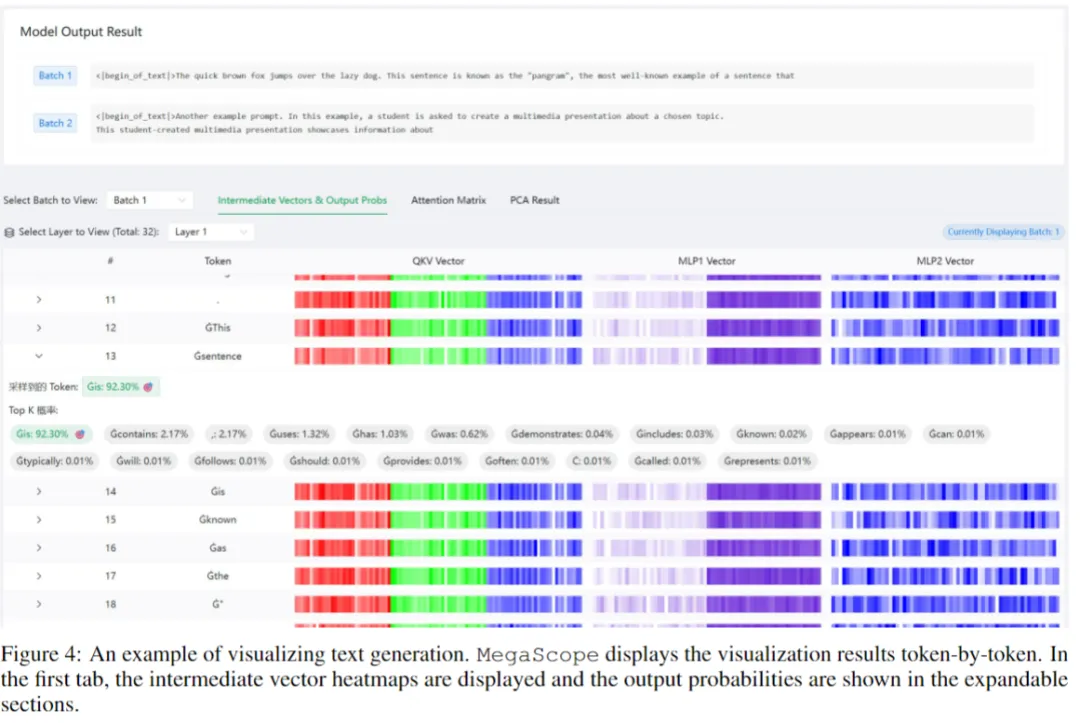
按需动态采样
用户通过注册API指定观察点(特定层、token或指标),系统仅在需要时捕获中间张量,并通过独立线程异步缓存,最小化对训练主路径的影响。
主机侧在线压缩
对捕获的激活和注意力图使用聚合统计量(最大值、均值、稀疏度)进行压缩,结合多级缓存策略,有效控制存储与带宽压力。
多层次探索式UI
插件式扰动注入
MegaScope 不仅是一个监控工具,更是一个面向机械可解释性研究的实验平台,将大模型训练从“黑箱优化”推进至“可调试学习”的新阶段。
三、创新性设计与方法论突破
MegatronApp 的技术价值不仅体现在其四大功能模块的实现上,更在于其背后所体现的系统设计哲学与方法论层面的突破。该框架从分布式训练的实际痛点出发,提出了一套以“解耦、弹性、语义感知”为核心的新型管理范式,为大模型基础设施的发展提供了可复用的设计蓝图。
1. 架构级创新:正交模块化与低侵入性集成
系统通过将复杂问题分解为四个职责清晰、彼此正交的功能单元,实现了高内聚、低耦合的架构设计。这种模块化策略允许用户根据实际需求灵活组合功能,无需重构整个训练流程。
|
|
|
|
|---|---|---|
| 功能解耦 |
|
|
| 运行时激活 |
|
|
| 语义保真 |
|
|
这一设计理念确保了系统既能深度嵌入现有训练生态,又能独立演进,是面向生产环境的大规模系统工程典范。
2. 运行时智能:动态适应与因果推理能力
传统工具多依赖静态配置或事后分析,而 MegatronApp 引入了实时感知与主动决策机制,使系统具备应对动态扰动的能力。
基于有效带宽的根因定位
超越简单的延迟阈值告警,通过 P2P 传输的数据量与耗时推导出有效带宽,精准识别网络路径退化节点,区分真实故障源与受牵连者。
资源感知的调度切换
MegaDPP 能根据实时内存压力与通信带宽,在 DFC(降显存)与 BFC(早同步)策略间动态选择最优路径,提升面对硬件波动时的鲁棒性。
轻量级异步协调机制
采用位向量表 + AllReduce OR 操作实现跨GPU通信的一致性检查,避免传统锁机制带来的开销与死锁风险,保障高并发下的稳定性。
这些机制共同构建了一个具有“自我诊断”与“自适应调节”能力的智能训练环境。
3. 人机协同增强:从可观测到可干预的跃迁
MegaScope 不仅提供观察窗口,更赋予研究人员主动干预模型行为的能力,推动大模型研究进入“可调试学习”新阶段。
按需采样与异步处理
仅在注册的观察点捕获张量,并通过后台线程完成压缩与缓存,将I/O开销降至最低。
多层次探索式界面
支持注意力热力图、token演化轨迹、PCA降维投影等多粒度视图,帮助研究人员直观理解模型内部工作机制。
插件式扰动注入
可在前向传播中注入噪声、掩码或偏移量,模拟量化误差、通信抖动等故障场景,系统性评估模型鲁棒性与容错边界。
这种“观察—假设—实验—验证”的闭环能力,极大加速了机械可解释性与模型安全性的研究进程。
四、应用价值与工程实践意义
MegatronApp 不仅在技术设计上实现了多项突破,更在实际工程应用中展现出显著的价值。它将大模型训练从一个高度依赖专家经验的“艺术”过程,转变为可监控、可优化、可实验的系统化工程实践,为研究机构与企业级用户提供了强有力的生产支持。
1. 显著提升系统效率与资源利用率
通过四大模块的协同作用,MegatronApp 在不改变模型架构的前提下,有效释放了硬件潜力,带来了可观的性能增益:
吞吐量提升
MegaDPP 的动态调度与 MegaFBD 的异构资源利用,共同实现了两位数百分比的吞吐量增长,显著缩短了训练周期。
集群资源优化
MegaScan 的精准根因定位避免了因个别慢节点导致的整体降速;MegaFBD 允许将前向计算迁移至 CPU 或低功耗设备,提升了混合集群的整体资源利用率。
故障恢复加速
传统分布式训练中,定位性能瓶颈可能耗时数小时;而 MegaScan 能在运行时自动检测并定位问题源,将平均故障恢复时间(MTTR)从小时级缩短至分钟级。
2. 革新开发与调试体验
该工具链极大降低了大模型训练的运维门槛,使开发者能更专注于模型本身而非底层系统问题。
透明化训练过程
MegaScope 提供实时、交互式的内部状态视图,研究人员可直观观察注意力机制演化、表征空间结构等,无需中断训练或手动导出数据。
自动化诊断能力
MegaScan 自动生成带有因果推理的性能报告,新手工程师也能快速理解复杂系统的异常行为,减少了对资深系统专家的依赖。
灵活的实验环境
MegaScope 的扰动注入功能允许进行“假设性分析”(what-if analysis),例如模拟通信抖动或存储错误,以评估模型鲁棒性,这在以往需要大量定制代码才能实现。
3. 构建面向未来的技术生态
该框架的设计理念具有前瞻性,为应对未来挑战奠定了基础。
|
|
|
|
|---|---|---|
| 异构计算适应性 |
|
|
| 系统弹性与容错 |
|
|
| 开放扩展能力 |
|
|
MegatronApp 的可视化化和观察工具比较不错,适合训练大集群的故障定位和解决,两个优化不好评价最终的效果;