夜雨聆风
夜雨聆风





解析文档中的一切元素!论文里的图表、公式终于能编辑了?这个开源的多模态OCR刷新SOTA

传统文档解析模型的文本+图像识别
现在的OCR模型解析上面的文档已经不成问题。
但除了提取文字、布局等文档元素外,我们可能还会有一个需求:
论文里的图表,产品文档里面的UI,这些想编辑但只能截图的内容怎么办?
现有的文档解析流程仍然以文本为中心,这些承载着密集信息的视觉元素,统统被裁剪掉、丢弃掉。
这不仅是信息的损失,更是对构建文档理解预训练语料库的巨大浪费。
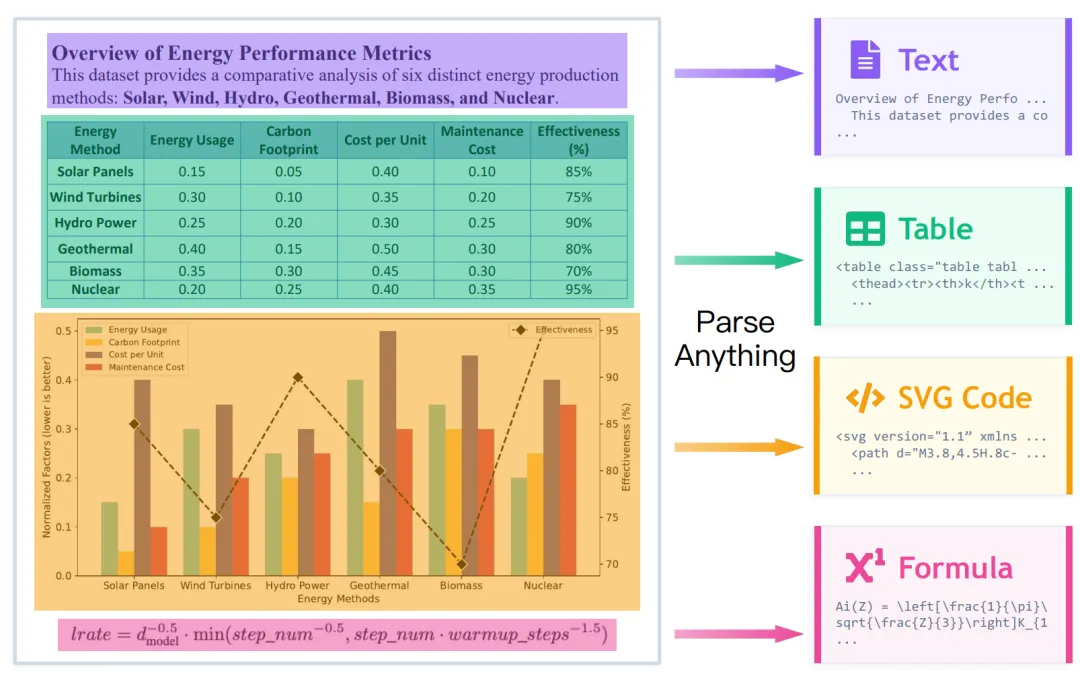
文本、图表、公式、示意图的解析
文档不仅通过文本传递信息,还通过图表、流程图、UI元素和科学插图等图形传递信息。
那文档解析模型是否可以超越文本提取,解析文档里的一切元素呢?
一个UI界面,布局比文字更关键,我们希望可以将UI截图转换为代码,将图标转换为可渲染的向量代码。
最近小红书HiLab联合华中科技大学研究团队,开源了一个多模态OCR模型:dots.mocr。
其目标是要把文档里的一切,将文本、图表、示意图、UI元素和领域绘图等都转换为可重用、可编辑、可渲染的表示。
# 论文Multimodal OCR: Parse Anything from Documents# Arxivhttps://arxiv.org/pdf/2603.13032# 数据https://github.com/rednote-hilab/dots.mocr一、把图变代码,让文档可解析
dots.mocr的核心思想很简单,就是把文档里的一切都视为一等解析目标。
文字?解析成文本。图表?解析成SVG。UI界面?解析成HTML。
通读完论文,我先来给大家总结下dots.mocr的优势:
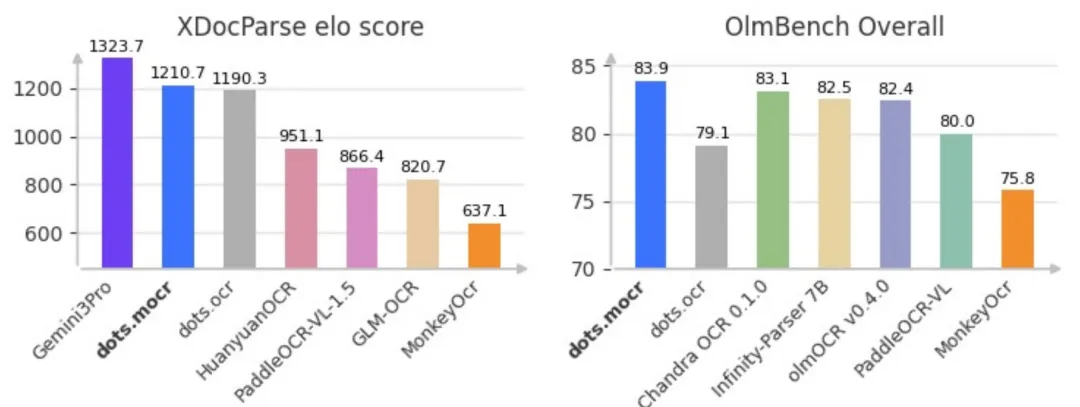
优势一:性能指标,开源模型最强
在olmOCR-Bench数据集上:83.9分,超越Paddle-OCR-VL,创造新的SOTA。
在OCR竞技场Elo排行榜上:仅次于Gemini 3 Pro,位居第二,超越所有现有的开源文档解析系统。
在结构化图形解析测试上:超越Gemini 3 Pro,在图表、UI布局、科学图形和化学图表上有更好的重建质量。
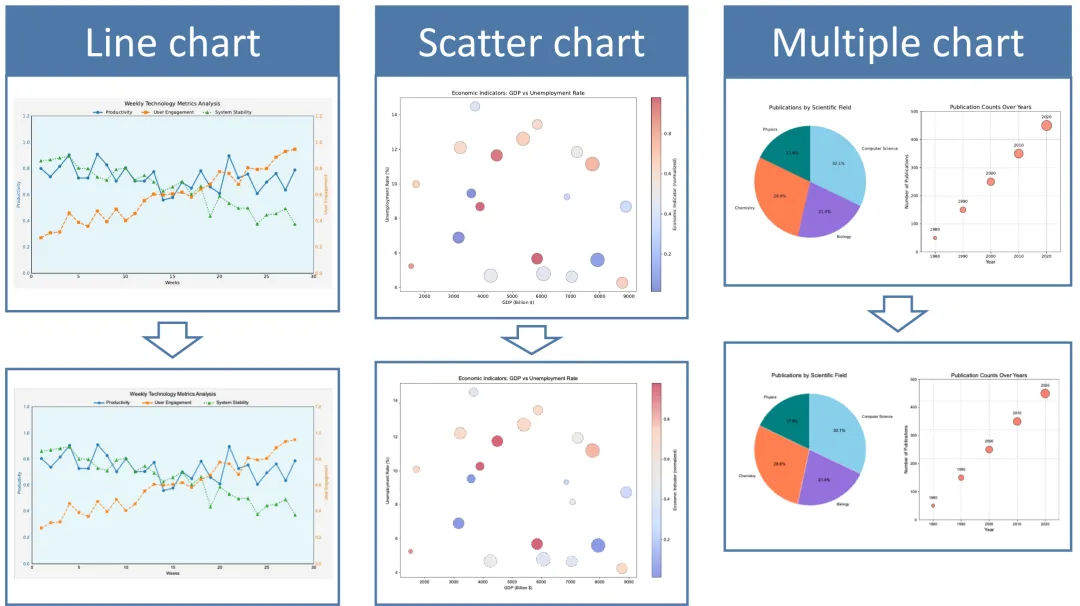
优势二:完全重建,不再是有损压缩
输出的是完整的、可渲染的文档。
比如将解析后的SVG代码扔进渲染器,出来的图表和原图一模一样,颜色、形状、位置,分毫不差。
优势三:解锁海量多模态监督数据
Dots.mocr把图也变成代码,等于把现有文档都变成了多模态训练数据。
我们可以用现成的文档,构建大规模的多模态预训练语料库,而不用依赖昂贵的人工标注。