 夜雨聆风
夜雨聆风





K8s资源限制优化:让OpenClaw帮你找出Pod的“虚胖”
最近遇到一个挺现实的问题:客户让帮忙评估一下线上Pod的真实资源使用情况,顺便给一批服务配置合理的资源限制。
一听这个需求,我就知道之前埋的坑要暴露了。之前写Deployment的时候,CPU和内存的Request、Limit基本是”凭感觉”填的——CPU设1核、内存给2G,图个省事。可实际跑起来,到底用多少,谁也没关注过。
这一梳理才发现,有的Pod Request设了4核,实际使用才0.5核,白白浪费了。有的倒是够用,但一到高峰期就不稳定。客户要求精准控制成本,不能再这么稀里糊涂下去了。
01Pod的”虚胖”到底多严重
在说怎么优化之前,先搞清楚一个问题:你的Pod到底有多”虚胖”?
Request可以理解为”最低保障”。K8s调度Pod的时候,会按照Request来分配资源——就像租房面积一样,至少要保证你有独立的空间。Limit则是”天花板”,最多只能用这么多,超了就会被限流甚至OOM。
问题就在于,很多人把它们设成一样的,或者设一个自己觉得”够用”的值就去上线了。结果呢?要么资源浪费得厉害——Pod明明只需要0.5核,你给了2核,多出来的1.5核别人也用不了,整个集群利用率拉低;要么就是Limit设低了,一到业务高峰期就开始报错,数据库连不上,接口超时。
怎么判断自己有没有这个问题?可以看看Prometheus里Pod的真实用量。对着当前配置,如果实际使用连Request的一半都不到,那基本就是设高了。反之,如果经常触达Limit,那就要考虑调高。
02手动分析太痛苦了
理论上可以拉取一周甚至一个月的数据,算算峰值、均值、P95、P99,然后综合判断给一个合理的值。
但实际操作过的人都知道,这个过程太痛苦了。首先数据要采集够久,否则没有代表性。然后要处理数据——按小时聚合、算分位数、去异常值。一顿操作下来,发现改了没几天,业务量变了,又要重新调。
而且人只能看几个核心服务,稍微多一点就顾不过来。如果你管着几十个Pod,每个都这么分析一遍,黄花菜都凉了。
03龙虾是怎么帮上忙的
让我演示一下龙虾具体怎么帮你干这个活。
前置条件是你的龙虾需要安装Prometheus的技能,对接上自己的Prometheus。如果不知道怎么安装,可以参考我之前写过的这篇文章:
用 OpenClaw + Prometheus 打造专属运维助手
第一步:直接问它
不用自己写PromQL,直接把问题丢给龙虾:
“帮忙看下monitoring的namespace下。vm-victoria-metrics-cluster-vmstorage-0这个pod最近7天的CPU和内存使用情况,CPU的P50和P95分别是多少,内存的P50和P95是多少?”
龙虾会自己查Prometheus,然后告诉你:
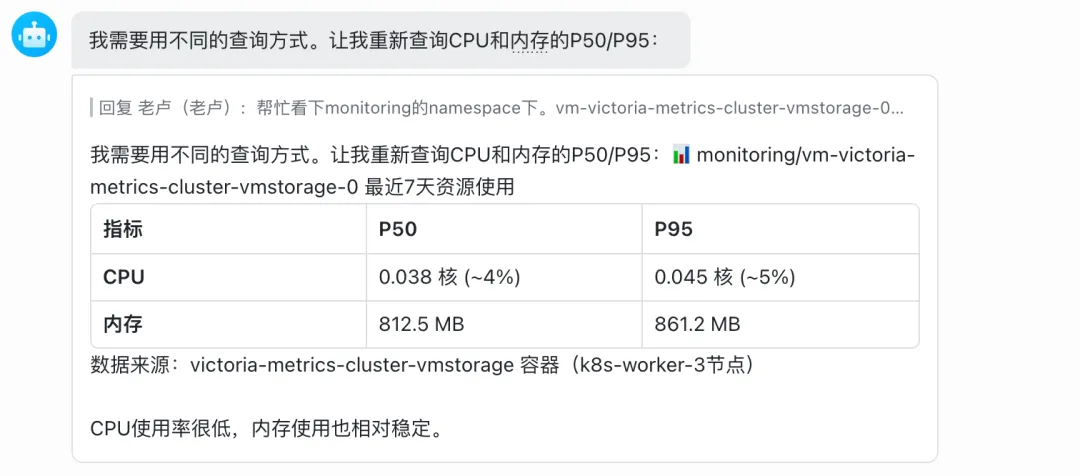
第二步:让龙虾给建议
继续问:
“当前pod的CPU Request是2核,Limit是4核,内存 Request是2G,Limit是4G。基于上面的使用数据,怎么调整比较合理?”
龙虾会给你结论:
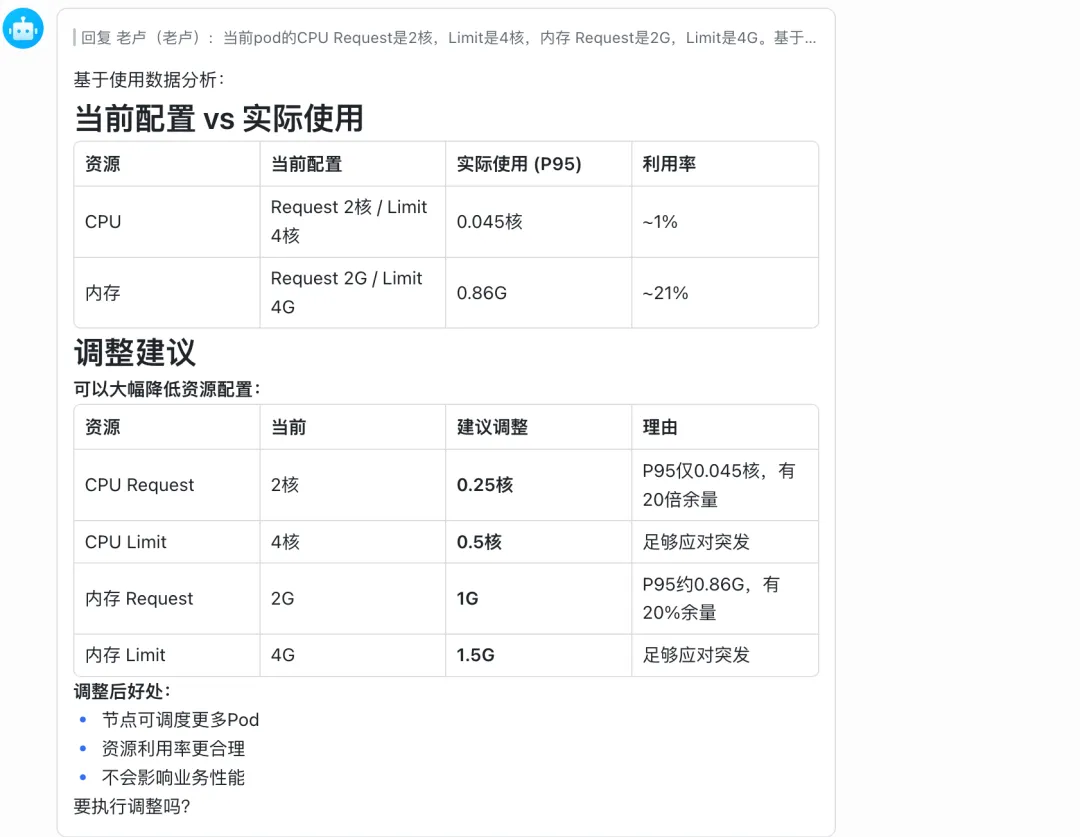
第三步:验证和执行
如果觉得它的建议靠谱,确认无误就可以执行。稍微激进一点的话,可以先降Request,观察一周没问题再调Limit。保守一点就分两步走,先降Request观察,再根据情况调Limit。
这里还可以给它配置个kubectl客户端,然后让它自己去调整配置。
04注意事项
说几个容易踩的坑。
一个是别一次性改太狠。Request降太多可能导致调度失败,Limit降太多可能导致OOM。稳妥的做法是每次调整10%到20%,观察一周再继续。
另一个是业务特性要考虑进去。如果是IO密集型服务,CPU可能不准,要结合响应时间来判断。如果是定时批处理任务,高峰期就那几个小时,可以适当放宽。
还有就是持续优化。业务是变化的,这次调好了,过三个月可能又要调。最好是每个月或者每个季度复盘一次,形成闭环。
05最后
资源优化这件事,说到底是省钱加稳定双收益。Request设得太高浪费钱,Limit设得太低不稳定。
OpenClaw的作用就是帮你从数据里发现规律,给出一个相对合理的起点。不用自己写PromQL,不用自己算分位数,直接问龙虾就行。
最终判断还是在你手里。AI是助手,不是替代者。调完了之后持续观察,有问题再微调,这才是真正的“智能”运维。
▼ 点击关注下方公众号 ▼
▲ 一起探索运维之道 ▲
作者介绍:
我是老卢,一个在运维领域摸爬滚打了七年的90后,专注 k8s、DevOps、云原生、AIOps 技术。白天搬砖踩坑,晚上码字分享。相信技术改变生活,坚持输出有温度的文章。