 夜雨聆风
夜雨聆风





文档 OCR 为何依然是一道硬工程难题?

让 OCR(光学字符识别)真正服务于现实文档——而不只是干净整洁的演示图片——究竟需要付出多少代价?一个紧凑型多模态模型,能否在不把推理烧成一场资源烈焰的前提下,同时搞定解析、表格、公式与结构化提取?

这正是 GLM-OCR 想要回答的问题。该模型由智谱 AI 与清华大学研究团队联合提出,是一个拥有 9 亿(0.9B)参数的紧凑型多模态文档理解模型,由三个核心部件构成:4 亿参数的 CogViT 视觉编码器、一个轻量级跨模态连接器,以及 5 亿参数的 GLM 语言解码器。团队的目标清晰:在文档识别质量上与大模型掰手腕,同时大幅压低推理延迟和计算成本。
传统 OCR 系统在纯文本转写上表现尚可,但一旦遇到混合版面、表格、公式、代码块、印章或结构化字段,便往往力不从心。近年来,多模态大语言模型在文档理解方面取得了长足进步,但研究团队认为,这些大模型体量庞大、采用标准自回归解码(每次只预测一个词符),使其在边缘设备部署和大规模生产环境中代价高昂。GLM-OCR 的定位,正是一个为这些部署约束量身打造的精简系统,而非顺带把 OCR 当作附加功能的通用视觉语言模型。
专为 OCR 工作负载打造的紧凑架构
本研究的一大技术亮点,是引入了多令牌预测(MTP)机制。可以把它理解为手机输入法的”联想词”功能——只不过 GLM-OCR 每步不只联想一个词,而是同时预测一整批词符。标准自回归解码每步仅产出一个词符,对于 OCR 这类输出确定、局部高度结构化的任务来说效率低下。GLM-OCR 训练时设定每步预测 10 个词符,推理时平均每步实际生成 5.2 个词符,带来约 50% 的吞吐量提升——也就是说,每秒能处理的文本量提升了约一半。为控制内存开销,实现上在草稿模型之间采用了参数共享方案。
两阶段版面解析,而非平铺直叙地逐页扫读
在系统架构层面,GLM-OCR 采用两阶段流水线。第一阶段由 PP-DocLayout-V3 负责版面分析,定位页面上各个结构化区域;第二阶段对检测到的各区域并行执行识别。之所以这样设计,是因为模型不像普通视觉语言模型那样从左到右通读整页,而是先将页面拆解为具有语义意义的区块,再逐区处理。这不仅提升了效率,也让系统在面对复杂版面文档时更加稳健。
文档解析与关键信息提取,走不同的输出路径
架构上还将两类相关任务做了明确区分。对于文档解析,流水线通过版面检测与区域处理生成结构化输出(如 Markdown 或 JSON)。对于关键信息提取(KIE),论文描述了另一条路径:将完整文档图像连同任务提示一并输入模型,无需事先拆分版面,模型直接输出包含目标字段的 JSON。这种区分意味着:GLM-OCR 并非一个单一的”页面转文本”模型,而是一个会根据任务类型切换运行模式的结构化生成系统。
四阶段训练流水线,配备任务专属奖励
训练方案分为四个阶段。第一阶段在图文对与定位或检索数据上训练视觉编码器。第 2.1 阶段在图文、文档解析、定位与 VQA(视觉问答)数据上进行多模态预训练。第 2.2 阶段引入 MTP 目标函数。第三阶段针对 OCR 专项任务进行监督微调,涵盖文本识别、公式转写、表格结构恢复与关键信息提取。第四阶段采用强化学习算法 GRPO 进行训练,奖励函数因任务而异:文本识别用归一化编辑距离,公式识别用 CDM 分数,表格识别用 TEDS 分数,关键信息提取用字段级 F1,同时设有结构性惩罚项,包括重复惩罚、格式错误惩罚和 JSON 校验约束。
基准测试成绩亮眼,但有几点值得仔细品味
在公开基准测试上,GLM-OCR 在多项文档任务中交出了强劲成绩:OmniDocBench v1.5 得分 94.6、OCRBench(文本)得分 94.0、UniMERNet 得分 96.5、PubTabNet 得分 85.2、TEDS_TEST 得分 86.0;关键信息提取方面,Nanonets-KIE 得分 93.7,Handwritten-KIE 得分 86.1。值得注意的是,Gemini-3-Pro 和 GPT-5.2-2025-12-11 的结果仅作参考展示,不计入最优分数排名——解读”模型领先”声明时,这一细节不可忽视。
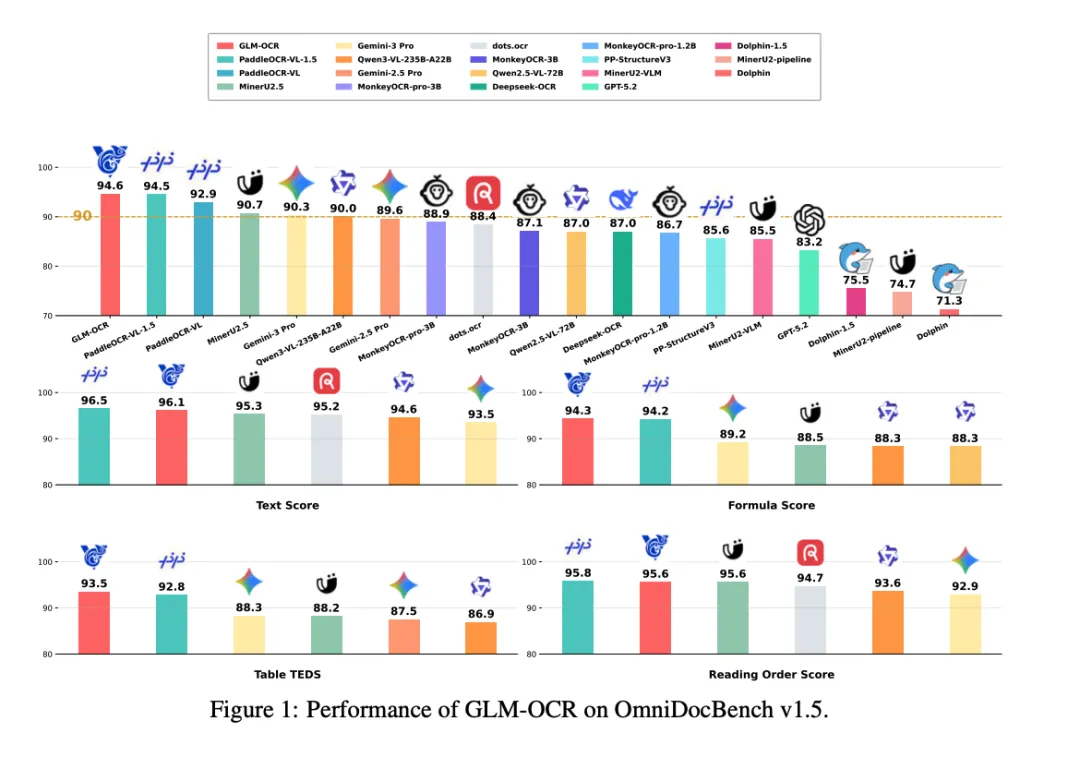
但这份成绩单需要细读。在参与正式评测的非参考模型中,GLM-OCR 在 OmniDocBench v1.5、OCRBench(文本)、UniMERNet 和 TEDS_TEST 上均排名第一;然而在 PubTabNet 上并非最优——MinerU 2.5 以 88.4 分胜过 GLM-OCR 的 85.2 分。关键信息提取方面,GLM-OCR 超越了表格中列出的其他开源竞品,但在仅供参考的参考列中,Gemini-3-Pro 在 Nanonets-KIE 和 Handwritten-KIE 两项上均高于它。综合来看,研究团队的竞争力声明有据可依,但并非”全面第一”的一概而论。
部署细节
论文指出,GLM-OCR 支持 vLLM、SGLang 和 Ollama 三种推理框架,并可通过 LLaMA-Factory 进行微调。在评测环境下,模型吞吐量为每秒处理 0.67 张图片、1.86 页 PDF。团队还提供了 MaaS API(模型即服务接口),定价为每百万令牌 0.2 元人民币,并附有扫描图片与简单版面 PDF 的成本估算示例。种种细节表明,GLM-OCR 被同时定位为一项研究成果与一个可真实落地的商用系统。
核心要点
-
GLM-OCR 是一个 9 亿参数的紧凑型多模态 OCR 模型,由 4 亿参数的 CogViT 编码器和 5 亿参数的 GLM 解码器构成。 -
引入多令牌预测(MTP)提升解码效率,推理时平均每步生成 5.2 个词符,吞吐量提升约 50%。 -
采用两阶段流水线:PP-DocLayout-V3 负责版面分析,随后由模型对各区域并行识别。 -
支持文档解析和关键信息提取(KIE)两种模式:解析输出 Markdown/JSON;KIE 整页输入后直接生成 JSON,无需版面拆分。 -
基准成绩亮眼但并非全面领先:GLM-OCR 在多项非参考基准测试中排名第一,但 MinerU 2.5 在 PubTabNet 上更优,Gemini-3-Pro 在参考列 KIE 分数上更高。
如果你喜欢这篇文章,别忘了 关注我们!
AI在持续学习,你我也该更新了。