 夜雨聆风
夜雨聆风





从搜索循环到 373 种工具:扩展多样性如何重塑智能体训练
一个反直觉的实验结论
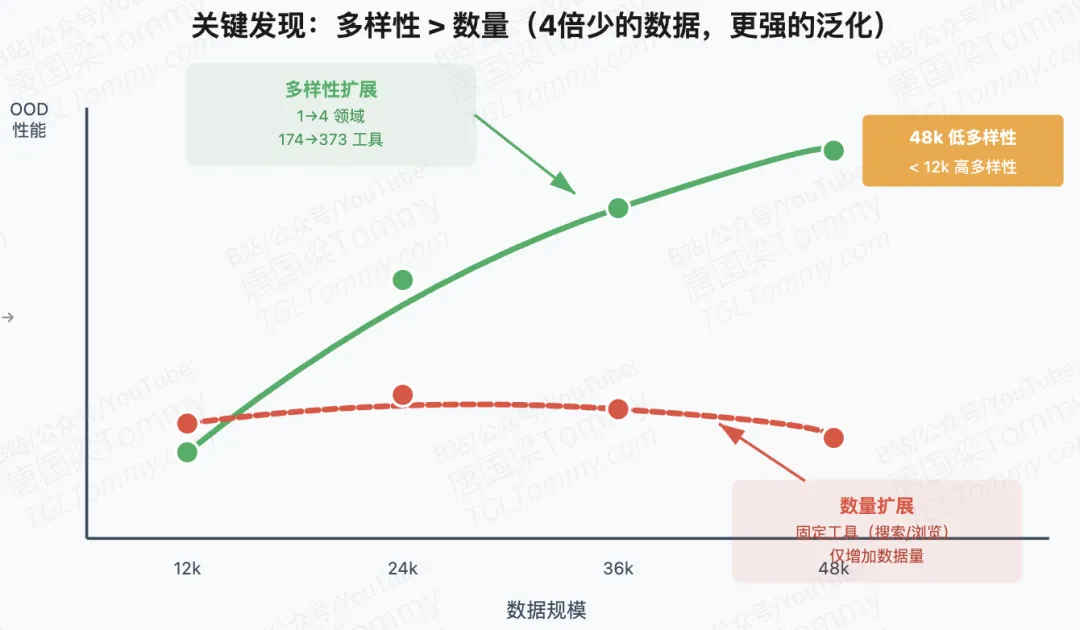
训练工具使用模型时,12k 条高多样性数据能否胜过 48k 条低多样性数据?DIVE 的实验给出了明确答案:可以,而且在分布外(OOD)任务上一致性地更好。这个结果挑战了”数据越多越好”的朴素直觉,指向一个更本质的问题——当我们希望模型泛化到未见过的任务和工具时,训练数据的结构多样性比规模数量更关键。
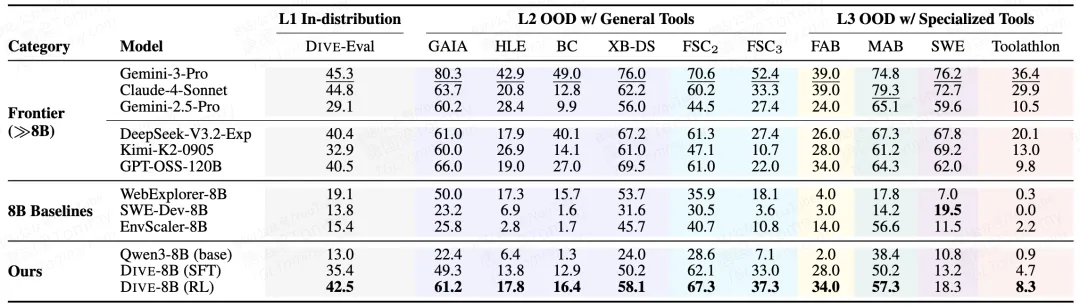
这篇来自复旦和 MiniMax 的论文聚焦一个具体场景:如何让 LLM 在面对新任务、新工具集时仍能可靠地完成复杂的多步工具调用。他们的方案 DIVE 在 Qwen3-8B 上训练后,在 9 个 OOD 基准上平均提升 22 个点,超越最强 8B 基线 68%,甚至在某些任务上逼近百亿级参数的前沿模型。
现有方法被困在”固定工具集”的牢笼里
目前主流的智能体训练数据合成方法存在一个共同局限:任务多样性和工具多样性严重不足。大多数工作聚焦在特定任务类型(如深度研究类问题)和固定工具组合(搜索 + 浏览)上,虽然能在该分布内刷出高分,但一旦切换到新领域(如金融分析、医疗诊断)或新工具集(如专业 API),性能会断崖式下跌,甚至出现负迁移。
为什么不直接扩展工具种类?这里存在一个可验证性-多样性的两难:
-
模拟工具(用 LLM 或通用工具模拟专业 API)虽然能快速扩展工具种类,但执行结果不稳定,导致合成的任务在训练时可能无法验证答案正确性; -
查询优先(先生成任务查询,再检查是否可解)的方法会产生大量”假设性问题”,需要大量人工或模型验证,过滤成本高; -
人工设计流水线(为每种任务/工具定制合成管道)虽然质量高,但扩展性差,每增加一个新领域就需要重新设计。
这三种路径都无法同时满足可扩展、可验证、结构多样三个要求。
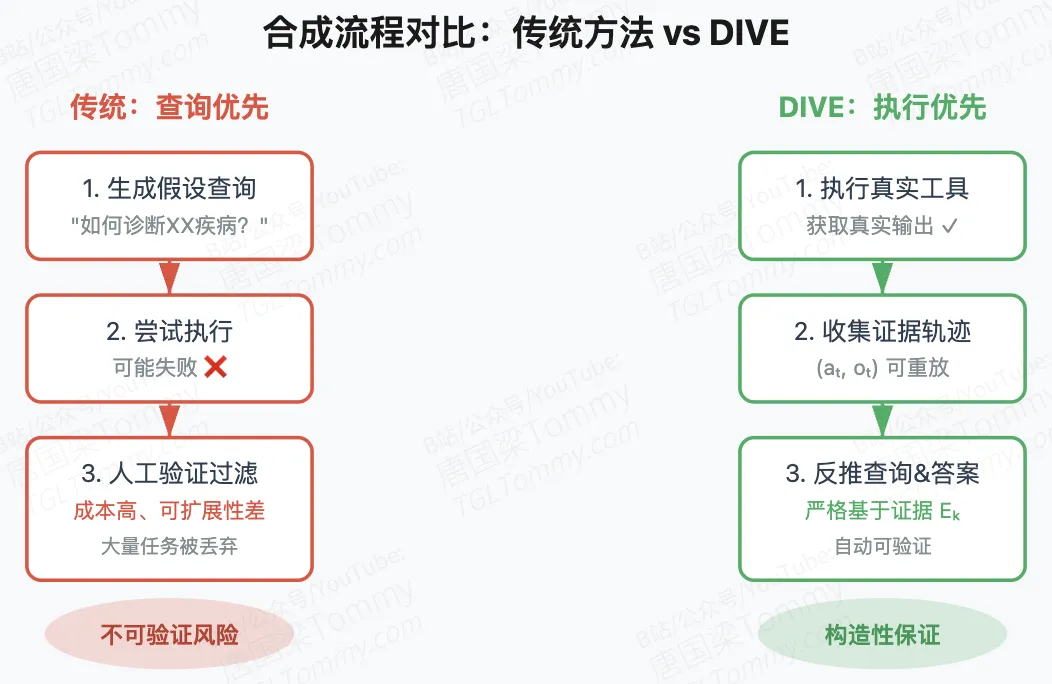
反转合成顺序:先执行工具,再倒推任务
DIVE 的核心洞察是:既然验证任务可解性这么难,为什么不直接从可解的执行轨迹出发? 这个思路反转了传统的”查询→执行→验证”流程,变成”执行→观察→倒推查询”:
-
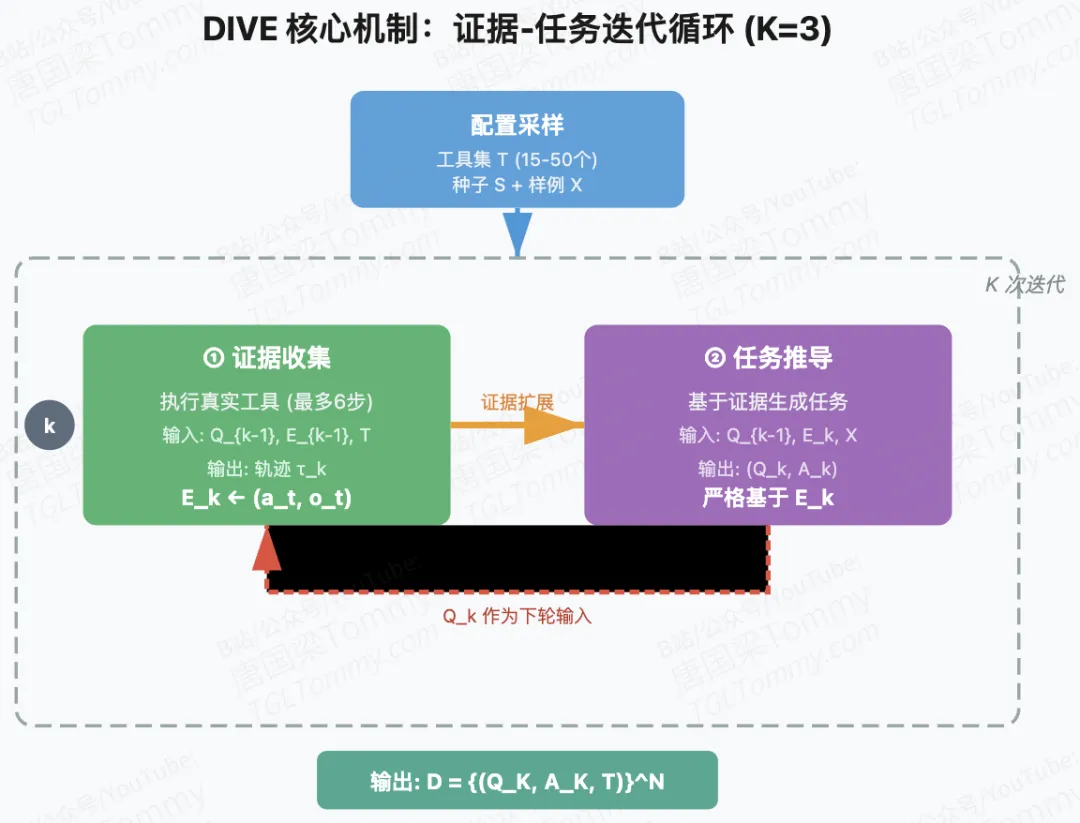
先随机采样工具子集(从 373 个真实工具中选 15-50 个)、种子概念 (如”Erlotinib”)、查询样例 (提供结构先验); -
证据收集阶段:让模型在工具集 上执行真实工具调用,每次调用都会返回真实的输出 ,这些 对构成”证据集” ; -
任务推导阶段:基于积累的证据 ,反向生成一个查询 和参考答案 ,确保 严格从 中推导而来。
这个设计的巧妙之处在于构造性保证:因为任务是从真实执行轨迹中推导出来的,所以天然满足可执行性(存在至少一条可行的工具调用路径)和可验证性(答案来自真实工具输出,可确定性检查)。同时,通过多轮迭代( 次循环),证据集会不断扩展,推导出的任务也会变得更复杂、更多样。
如何系统性地扩展多样性?
DIVE 在两个正交维度上控制多样性:
工具池覆盖:从 5 个领域(通用、金融、医疗、学术、生物)采集 373 个真实 API,包含检索类工具(如 ncbi_search)和处理类工具(如 seq_translate)。这些工具经过单元测试、并发安全和响应一致性验证,确保训练稳定性。
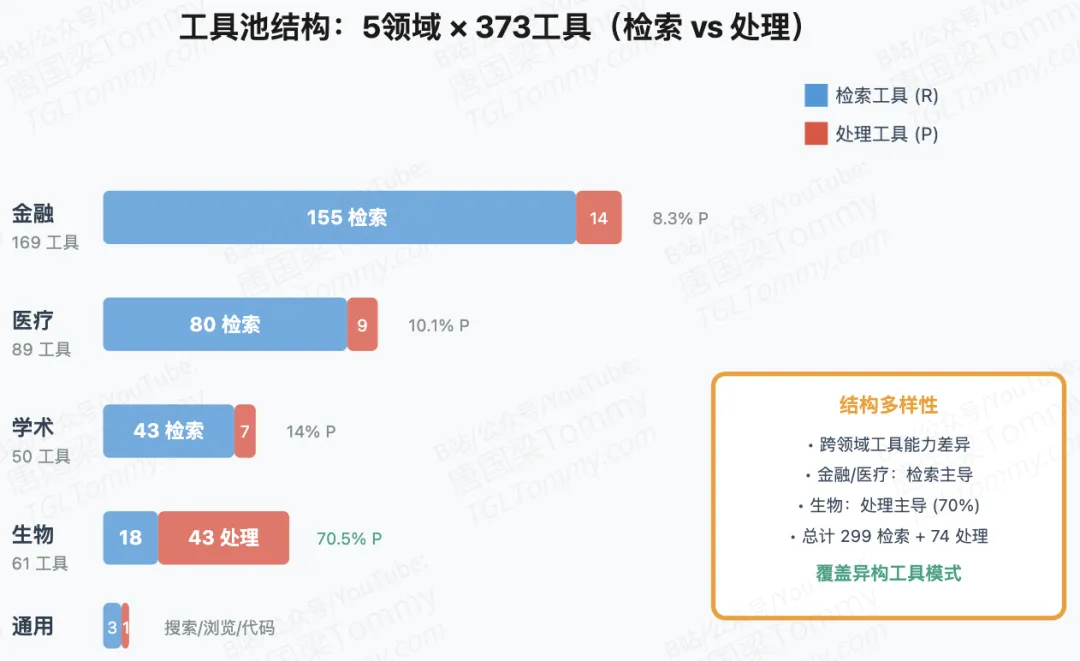
任务级工具集多样性:每个任务随机组合 15-50 个工具,而非固定工具组。这迫使模型学习”从噪声候选集中精确选择相关工具”的能力,而不是记忆固定的工具调用模板。
此外,种子池(从 Wikipedia、PubMed 等挖掘的 ~5000 个实体)避免了话题坍缩,样例池(来自异构任务家族的查询)提供了隐式的工具使用模式(如”检索后计算””多跳检索”)。这三个资源池解耦设计,可以独立采样并组合,指数级扩展了任务空间。
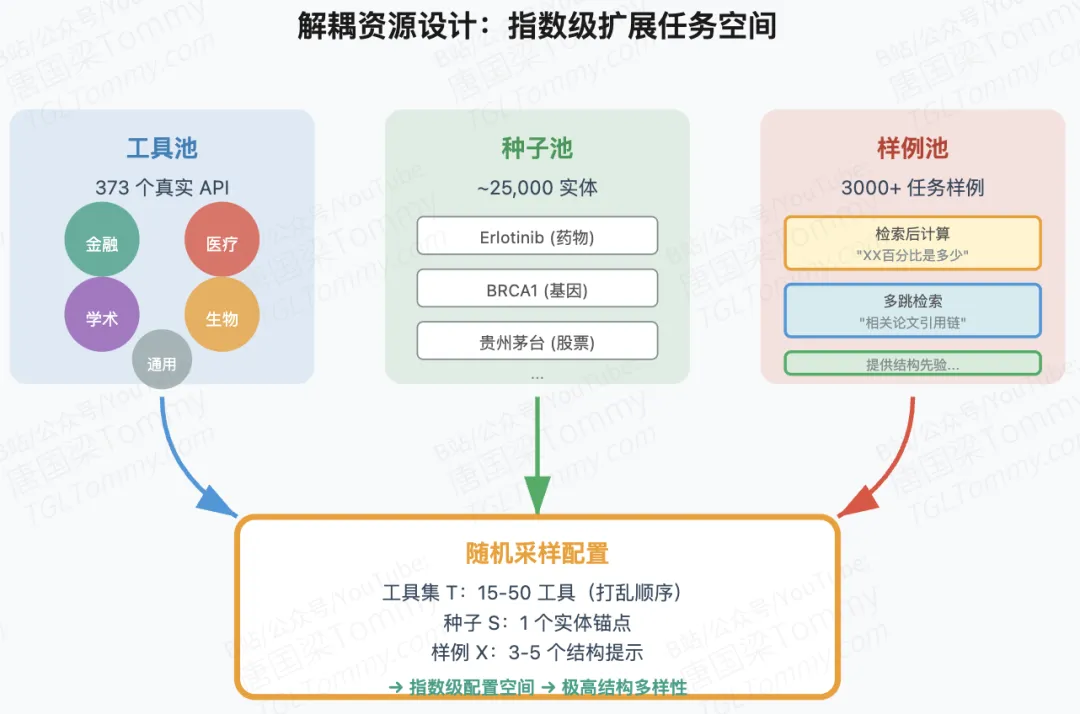
实验揭示的三个关键发现
发现一:多样性扩展碾压数量扩展。在对照实验中,12k 高多样性数据(工具池从 1 个领域扩展到 4 个)在所有 OOD 基准上都超越了 48k 低多样性数据(固定搜索/浏览工具,只增加数据量)。这表明当目标是泛化时,数据的覆盖广度比重复次数更重要。
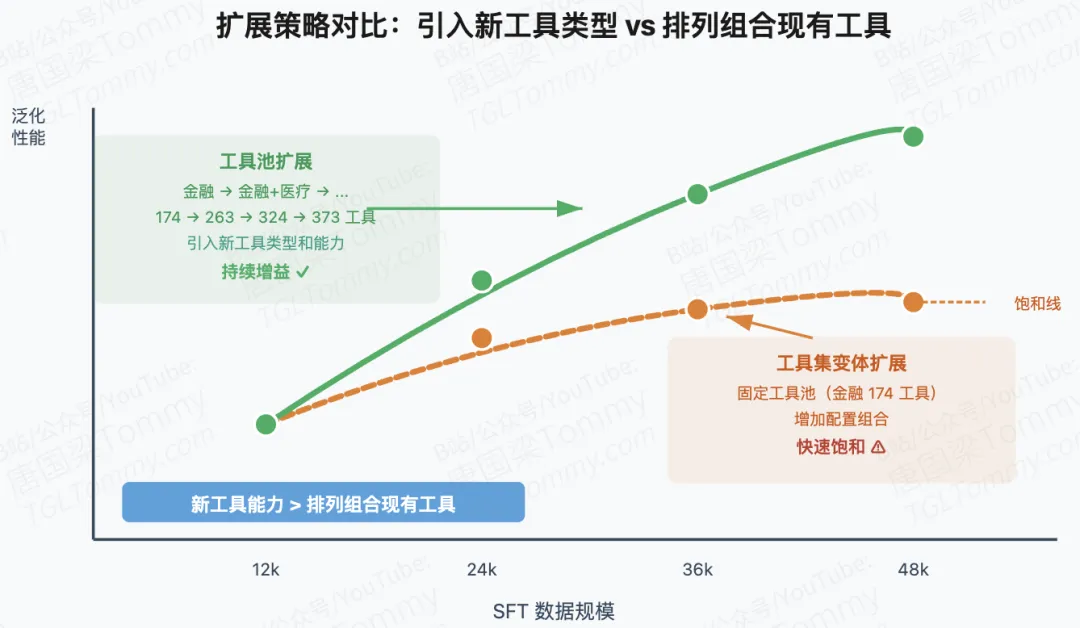
发现二:工具池扩展比工具集变体更有效。两种扩展策略的对比显示,仅在固定工具池内增加工具集组合(Toolset-variety-only)收益有限且快速饱和;而同时扩展工具池到新领域(Pool-Expansion+Variety)能获得更快的增益和更高的天花板。这提示引入新工具能力比排列组合现有工具更能提升泛化。
发现三:RL 收益被多样性数据放大。从 SFT 到 RL 的提升在多样化数据上更明显(如 GAIA 从 49.3 提升到 61.2),而在低多样性数据上 RL 的边际收益较小。这可能因为多样性数据提供了更丰富的探索空间,让 RL 能发现更多有效策略。
一个值得深思的启示
DIVE 的价值不仅在于刷榜数字,更在于提出了一个可操作的数据哲学:与其追求更大规模的单一分布数据,不如投资于覆盖更广分布的小规模数据。这对工业界尤其重要——当你无法预知用户会用什么工具、问什么问题时,训练数据的多样性就是泛化能力的上界。
当然,DIVE 也有成本:它依赖真实工具执行(需要 API 访问和维护)、用强模型做合成(Claude-4-Sonnet)。但论文证明了这种成本是值得的——8B 模型在 ToolAthlon(零样本、32 个 MCP 应用、状态化环境)上从接近 0 提升到 8.3,逼近 120B 级别模型。
对从业者的启示是:如果你的智能体需要在开放域工具上泛化,别只盯着数据量,先审视你的训练数据覆盖了多少种工具类型、多少种任务结构、多少种推理模式。多样性可能是那个被低估的杠杆。
一句话带走:当目标是泛化而非拟合时,数据的广度比深度更关键——这可能适用于智能体之外的更多场景。
进阶学习
👉如果你希望系统掌握大模型核心技术、以及Agent应用开发,推荐你学习我最新上线的精品课程:
📚这是一套从模型微调、部署,到强化学习训练的系统学习路线,课程以企业级落地为目标,你将掌握LLM核心原理、Agentic RAG、MoE/MLA/MTP机制拆解、PPO/GRPO强化学习与工业级DeepSeek-OCR多模态实战等,想系统掌握并落地这些能力,就从这门课开始。
💡本课程已在我的个人官网以及B站课堂上线,点击链接了解课程详情:
📺B站课堂(点击左下角“阅读原文”直接跳转)https://www.bilibili.com/cheese/play/ss556613313
🌐官网链接(国内访问需科学上网):https://www.tgltommy.com/p/deepseek
