 夜雨聆风
夜雨聆风





会抓包的 AI 运维助手:用 Skill + MCP 排查 ZStack 网络状态
在上一篇文章10 分钟,让 AI 学会管你的云平台中,我们用 Witsy + DeepSeek 把 AI 接上了 ZStack,实现了查失败任务、盘点闲置资源这些查询操作。但查数据只是第一步——运维真正头疼的是排查问题。
凌晨两点,值班群弹消息:”XX 业务的 VM 网络不通了”。
你登上跳板机,查 VM 信息、找宿主机、看网卡状态、查网桥、抓包……一套排查下来 30 分钟过去了。这些步骤你闭着眼都能敲,但就是费时间。
如果你能对 AI 说一句”帮我查一下这台 VM 的网络状态”,它两三分钟内自动完成上面所有操作,给你一个结论呢?
这篇文章就来搭这套东西。工具全开源,五分钟搞定。
方案和成本
四个组件:
-
OpenCode:开源终端 AI 助手,支持 MCP 协议,GitHub 12 万星 -
DeepSeek:国产大模型,代码和推理能力不弱 -
ZStack MCP Server:我们开源的 MCP 服务,把 ZStack 2000+ API 和 1600+ 监控指标接入 AI -
Skill:运维排查经验的编码文件,教 AI “遇到什么问题该怎么排查”
你说人话 → OpenCode(终端 AI)→ DeepSeek(大脑)→ ZStack MCP Server → ZStack API↑Skill(排查经验)
先说成本——因为这可能是你最关心的:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
| OpenCode + DeepSeek + ZStack MCP | ~¥0.05 | 全免费 | 日常运维,成本敏感 |
|
|
|
|
|
ZStack API 的响应通常有几 KB 到几十 KB(VM 信息带着网卡、磁盘等嵌套数据),所以每次查询的 token 消耗不算小。但 DeepSeek 的价格大约是 Claude 的 1/20,一天查 10 次,一个月大约 ¥15——一杯奶茶换一个 7×24 的运维助手。
五分钟装好
你需要一台能访问 ZStack 管理网络的机器。Mac、Linux 都行——也可以直接在 ZStack Cloud 上开一台 Linux 虚拟机来用。
1. 装 OpenCode
# macOSbrew install opencode-ai/tap/opencode# Linuxcurl -fsSL https://opencode.ai/install.sh | bash
2. 拿 DeepSeek API Key
去 platform.deepseek.com[2] 注册,创建 API Key。
设置环境变量:
export DEEPSEEK_API_KEY=sk-your-key-here3. 创建 opencode.json
在你的工作目录下创建配置文件:
{"$schema": "https://opencode.ai/config.json","model": "deepseek/deepseek-chat","mcp": {"zstack": {"type": "local","command": ["uvx", "zstack-mcp-server"],"environment": {"ZSTACK_API_URL": "http://你的ZStack地址:8080","ZSTACK_ACCOUNT": "admin","ZSTACK_PASSWORD": "密码","ZSTACK_ALLOW_ALL_API": "true"},"timeout": 60000}}}
ZSTACK_ALLOW_ALL_API=true是为了允许调用运维操作类的写 API。如果你只需要查询,可以去掉这行,默认只读更安全。
4. 启动
opencode看到 MCP server 状态变成 ✓ zstack connected,就可以开始了。
实战:AI 排查 VM 网络
我们拿一个真实场景来演示:检查一台 VM 的网络是否正常。
先试试裸跑
不加任何 Skill,直接问:
帮我查一下 verify-ZSTAC-79709 这个 VM 的网络状态DeepSeek 调了 3 次 MCP 工具:搜索 API → 查 VM 信息 → 查网卡信息,然后给出结论:
网卡状态:enableIP地址:172.20.9.69/16网关:172.20.0.1驱动类型:virtio网络状态总结:该虚拟机网络配置正常,网卡已启用,网络连接正常。
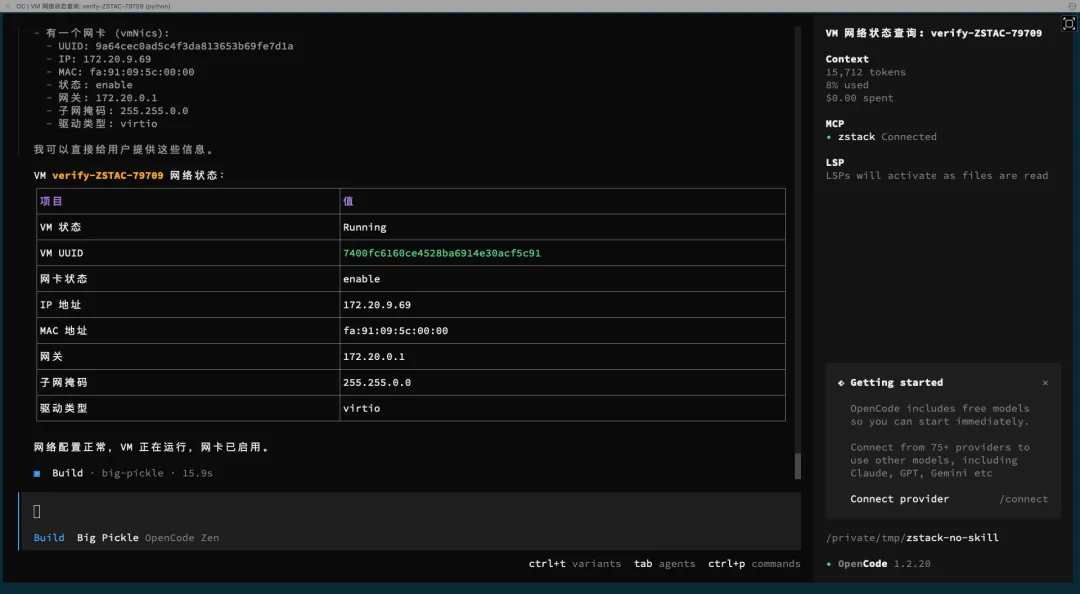
看起来像那么回事,但仔细想想——它只是读了 API 返回的字段,根本没有做任何实际的网络诊断。网卡 enable 不代表网络通,IP 存在不代表能 ping 通。这就像医生只看了病历卡就说”你很健康”,连听诊器都没拿出来。
加上 Skill 再试
我们基于 ZStack 技术支持团队的排查经验,整理了一份网络诊断 Skill(skills/vm-network-diagnose/SKILL.md),涵盖了扁平网络、VPC 网络、DHCP 故障等常见场景的完整排查流程。这份 Skill 已经放在了 zstack-mcp-server 仓库[3] 里。
用法很简单:clone 仓库,在仓库目录下启动 OpenCode,Skill 就自动生效了。
同样的问题再问一遍,这次 AI 的表现完全不同:
第一步:加载 vm-network-diagnose Skill,按排查流程查询 VM 信息
VM: verify-ZSTAC-79709状态: Running宿主机: host-172.20.1.163 (172.20.1.163)IP: 172.20.9.69网卡: vnic41741149.0
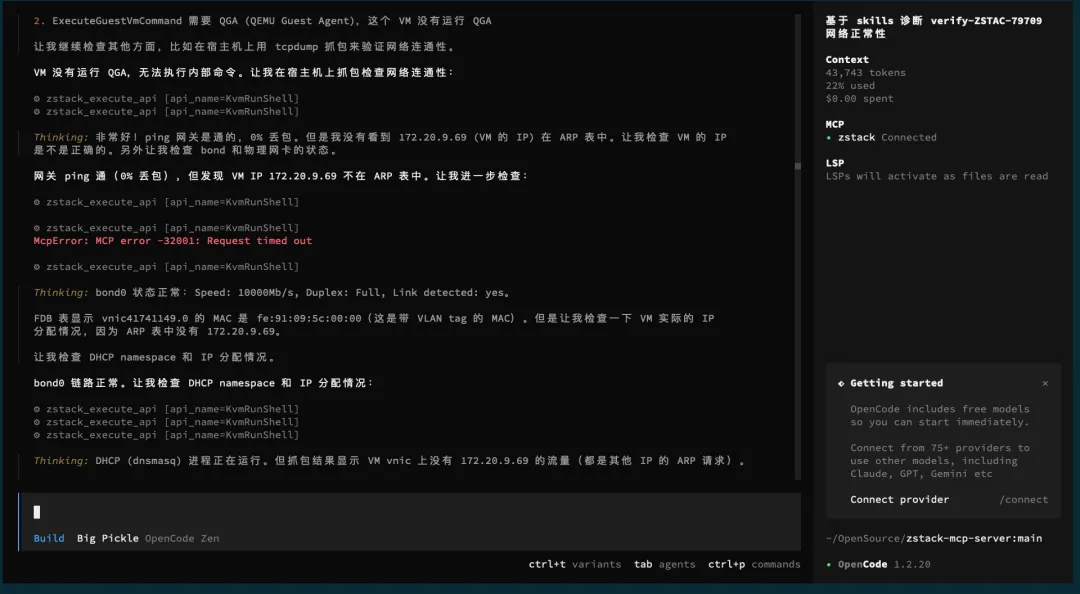
第二步:在宿主机上执行一系列诊断命令
AI 分多次调用运维 API,逐项检查:
# 检查 vnic 状态和网桥ip link show vnic41741149.0brctl show | grep vnic41741149.0# 从宿主机 ping VM、网关、DNSping -c 3 -W 2 172.20.9.69ping -c 3 -W 2 172.20.0.1ping -c 3 -W 2 223.5.5.5# 检查流量统计和 ARP 表ip -s link show vnic41741149.0arp -n | grep 172.20.9.69
第三步:查询 EIP、安全组、网络监控指标等辅助信息
第四步:输出标准诊断报告
## 诊断报告目标 VM: verify-ZSTAC-79709VM 状态: Running所在宿主机: host-172.20.1.163 (172.20.1.163)IP 地址: 172.20.9.69### 排查过程检查项 结果VM: 状态 Running ✓vnic 状态: UP, MTU 1500 ✓网桥 br_bond0_2: UP ✓vnic 在网桥上: vnic41741149.0 已在 br_bond0_2 ✓FDB 表学习: fa:91:09:5c:00:00 已学习到 br_bond0_2 ✓Bond 模式: active-backup, enp216s0f1 活跃 ✓物理网卡: enp216s0f0/f1: 10Gbps/Full ✓到网关 172.20.0.1:0% 丢包 (3/3) ✓到公网 8.8.8.8: 0% 丢包 (2/2) ✓DHCP 配置: MAC→IP 映射正确 ✓dnsmasq 进程: 运行中 ✓### 诊断结论网络状态正常。所有检查项均通过:- VM 和 vnic 状态正常- 网桥、bond、物理网卡链路均正常- 网关和公网连通性测试均 0% 丢包- DHCP 配置正确(MAC fa:91:09:5c:00:00 → IP 172.20.9.69)- MAC 地址已在网桥 FDB 表中正确学习
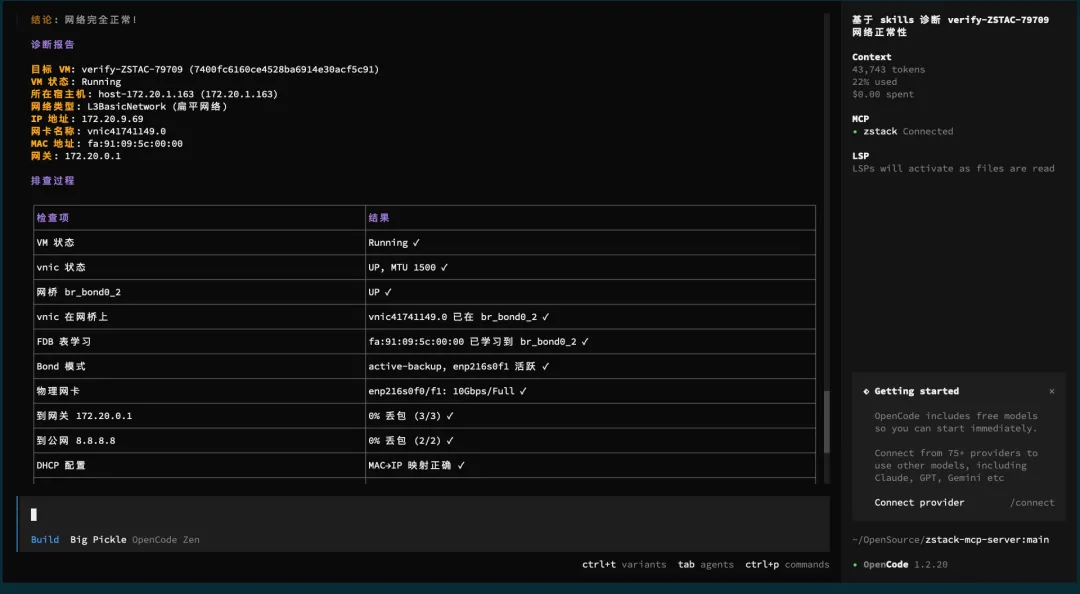
同样一句话,没有 Skill 时 AI 只查了 3 次 API、读了几个字段就下结论;有 Skill 后,AI 调了十几次工具、在宿主机上跑了实际的诊断命令、检查了 EIP/安全组/监控指标,最后给出了一份有理有据的诊断报告。
这就是 Skill 的价值——把专家的排查经验注入 AI,让它知道该查什么、怎么查、查到什么算正常。
Skill 里有什么
光有 MCP Server 还不够。一个新手拿到 tcpdump 也不知道该抓哪个口。
vm-network-diagnose 这份 Skill 把技术支持团队的排查经验编码成了 AI 可以遵循的流程:
第一步:定位 VM → 确认状态第二步:查网卡 → 有 IP 走连通性分支,没 IP 走 DHCP 分支第三步:查宿主机 → 拿到管理 IP第四步:通过运维 API 检查 vnic、网桥、VLAN第五步:判断网络类型 → 扁平网络查 netns/EIP,VPC 网络查路由器第六步:深度排查 → 抓包、检查 bond、MTU、FDB
Skill 里定义了十几种排查场景,AI 会根据实际情况自动选择执行:
|
|
|
|---|---|
|
|
ip link show <vnic> |
|
|
brctl show |
|
|
cat /proc/net/vlan/config |
|
|
cat /proc/net/bonding/bond0 |
|
|
ip netns exec <ns> ip addr && iptables -t nat -S |
|
|
iptables -S \| grep <ip> |
|
|
tcpdump -i <vnic> -nn host <ip> -c 10 |
|
|
ethtool -S <nic> \| grep crc |
|
|
arping -I <nic> -c 3 <ip> |
|
|
ip link show \| grep mtu |
除了流程和命令,它还浓缩了这些实战知识:
-
扁平网络 EIP 的完整数据路径( zsn0.<vlan> → netns DNAT/SNAT → vnic) -
VPC 网络流量路径( VM → bridge → VPC 路由器 → SNAT → 外部) -
MTU 踩坑经验(VXLAN 要 1450,VLAN 要 1496) -
rp_filter导致 VPC 路由器异常 -
迁移后 FDB 残留导致网络不通 -
Bond 模式与交换机配置对照表
有了 Skill,DeepSeek 不再是一个只会执行命令的工具,而是一个懂 ZStack 网络架构的排查专家。
为什么需要 MCP Server?Skill 不够吗?
Skill 教 AI “该查什么”,但 MCP Server 解决的是”怎么查得动、查得稳”。两件最关键的事:
异步轮询,不浪费 token。 ZStack 很多 API 是异步的——发请求、拿 Job UUID、轮询等结果,可能要 5-10 秒。让模型自己轮询,每次都是一轮对话,费 token 还容易出错。MCP Server 在服务端处理完轮询,模型只调一次,等结果回来就行。
2000+ API,按需加载。 把所有 API 定义塞进 Skill,光参数描述就超过 35 万 token,直接爆掉上下文窗口。MCP Server 用搜索 → 描述 → 执行的三段式设计,整个过程只加载用到的那几个 API,上下文占用极小。
还有两个在团队场景下很重要的能力:集中的权限管理(管理员统一控制哪些 API 可调用),以及智能的返回控制(Query API 默认 limit=50,响应超 64KB 自动裁剪,防止撑爆上下文)。
一句话总结分工:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MCP Server 负责”做得到”,Skill 负责”知道怎么做”。
写在最后
这套方案的核心不是哪个模型更强,而是 MCP 协议让 AI 能力变成了可插拔的。
ZStack MCP Server 提供 2000+ API 的调用能力和服务端智能处理,运维 API 打通宿主机的诊断能力,Skill 把排查经验编码成可复用的知识。这些不绑定任何特定模型——今天用 DeepSeek,明天换 Qwen、Claude、GPT,MCP Server 和 Skill 不用改一行。
模型会越来越便宜,能力会越来越强。但你积累的运维知识和排查流程,通过 Skill 沉淀下来,通过 MCP Server 提供稳定的工具层,才是真正的长期价值。
试试看?装好之后,先来一句:
ounter(lineopencode run "帮我查一下所有停机的 VM 占了多少资源"
GitHub:https://github.com/zstackio/zstack-mcp-server
PyPI:https://pypi.org/project/zstack-mcp-server/