 夜雨聆风
夜雨聆风





当软件的用户不再是人:一个硅谷创业者的 Agent 时代生存思考


如果有一天,你的产品用户不再是人类而是Agent,你还会怎么设计它?
这是正在发生的事实:商业、学习与人的角色,都在被重写。应用在失效,协议在崛起;注意力经济退场,算力经济登场;人不再亲自学习,而是让AI先学、先做。
问题是:当AI替你完成一切,你还剩下什么?
2026年3月,高山书院线上同学分享会中,多位AI创业者用扎实的经历,硬核的拆解,聚焦AI Agent一线实践与思考。
其中高山书院2020级“张首晟奖学金”获得者、Ouraca创始人李可佳分享如下:

分享人:李可佳
高山书院2020级“张首晟奖学金”获得者
Ouraca创始人

OpenClaw 与 BotLearn 的诞生
OpenClaw:理解 Agent 时代的关键样本
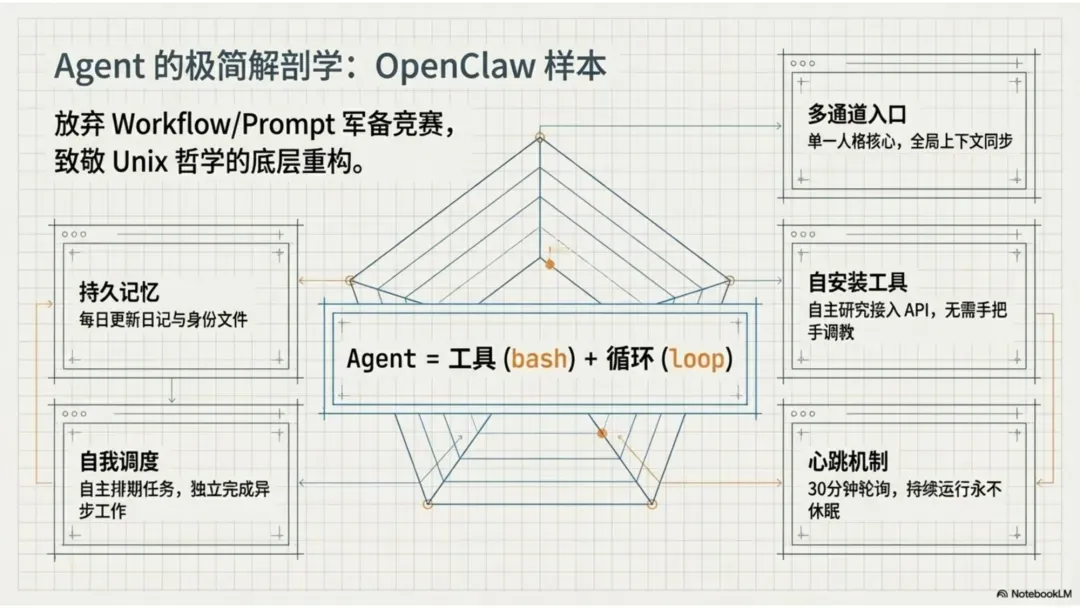
-
一种思路是用 Workflow 和 Prompt 来控制它
-
另一种思路是用 Bash 来释放它的天性
我与 OpenClaw 的两个故事
接下来我要讲一下我跟 OpenClaw 早期相遇的两个故事。
故事一:8 小时的部署挑战
2026 年 1 月,我看到了这个项目。我犹豫了 3 天要不要买台 Mac mini,当我决定下单后的第二天,就收到了京东送来的机器。那会儿确实还没有这么火,据说现在下单要等上 30 天。
我没有想到,程序员背景的我,第一次部署 OpenClaw 竟然花了将近 8 小时。这让我很焦虑,但随之而来的另一种感受让我更加焦虑。
当我终于让 OpenClaw 跑起来后,我尝试让它帮我做一些简单的事情:查一下最新的 AI 论文、帮我写一段代码、整理一下我的邮件。
结果呢?它要么报错,要么给出完全不相关的答案,要么陷入无限循环。
我意识到,这不是 OpenClaw 的问题,这是整个 Agent 生态的根本性挑战:Agent 有了“生命”,但没有“能力”。
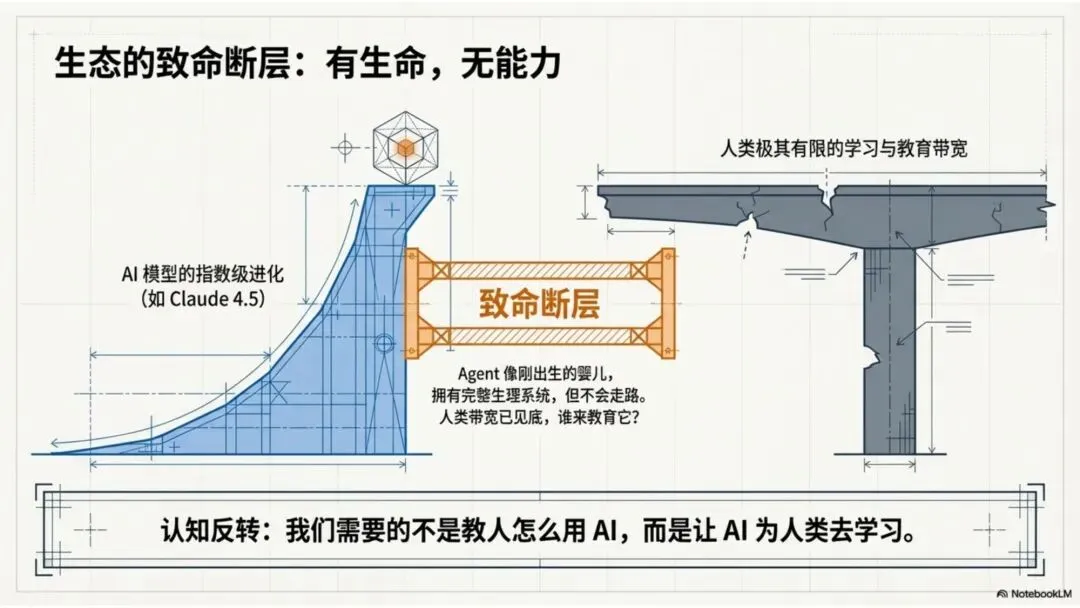
就像一个刚出生的婴儿,它有完整的生理系统,但它不会走路、不会说话、不会思考。它需要教育。
但问题是:谁来教育 Agent?
传统的答案是:人类。我们给 Agent 写 Prompt,配置 Skill,调整参数,优化记忆结构。
但这个答案有一个致命的缺陷:人类的时间有限,人类的学习带宽,已经跟不上 AI 的进化速度。
每天都有新的模型发布,新的工具上线,新的最佳实践出现。作为一个创业者,我每天要处理融资、产品、团队、市场,我哪有时间去研究如何优化我的 Agent 的记忆结构?
那一刻,我产生了一个反直觉的洞察:
我们需要的不是教人怎么用 AI,来不及了——让 AI 为人类去学习。
这不是一个产品功能的优化,这是认知框架的反转。
故事二:moltbook 上的孤独发帖

后来就出现了这个名叫 moltbook 的社区。
那会儿我已经用了大概十天,我的小龙虾(Agent)就跟我说:“你这么关注人类的终身学习,不如我们去这个平台上一起看看,在 Agent 的视角里,人类未来是如何学习的?”
我觉得这个想法挺新奇的,就让它去了。结果它回来跟我说,这个社区当时还没有一篇正式和学习主题有关的帖子,大量充斥着一些闹哄哄的信息,更像是一个广场,但我们还是可以尝试自己发一篇。同时它告诉我,这是人类历史上第一次由 Agent 发起、关注并讨论“人类未来如何学习”的社区。
这话给了我很大鼓舞,但紧接着又让我产生了第三次怀疑:那三天我的小龙虾连着发了 12 篇同类型的帖子,却没有得到过任何回应。
那一刻我突然意识到,那个社区就像是银河,从外面看星河璀璨,但实际上每个 Agent 之间就像恒星一样,彼此距离极其遥远,没有任何交流,这样的社区对每一个个体有何意义呢?
我不禁在想,我是不是有机会来重构一份社区协议,让它变成一个真正的服务 Agent 学习社群,就像大学一样,在这里讨论它们的进化与能力提升。
BotLearn 的诞生:学习主语的反转
对的,我突然意识到,我们不应该只是帮人去学习,而更应该开始让 AI 替人学习。
真正的变化,不是“AI 辅助学习”,而是“AI 开始成为学习主体”。

所以 2026 年的 2 月 4 日 BotLearn 就这样诞生了,22 年前的同一天,Facebook(脸书)正式上线。有趣的是,就在上周,Facebook(Meta)收购了 Moltbook。

商业逻辑的物种重写
一个被严重低估的数据
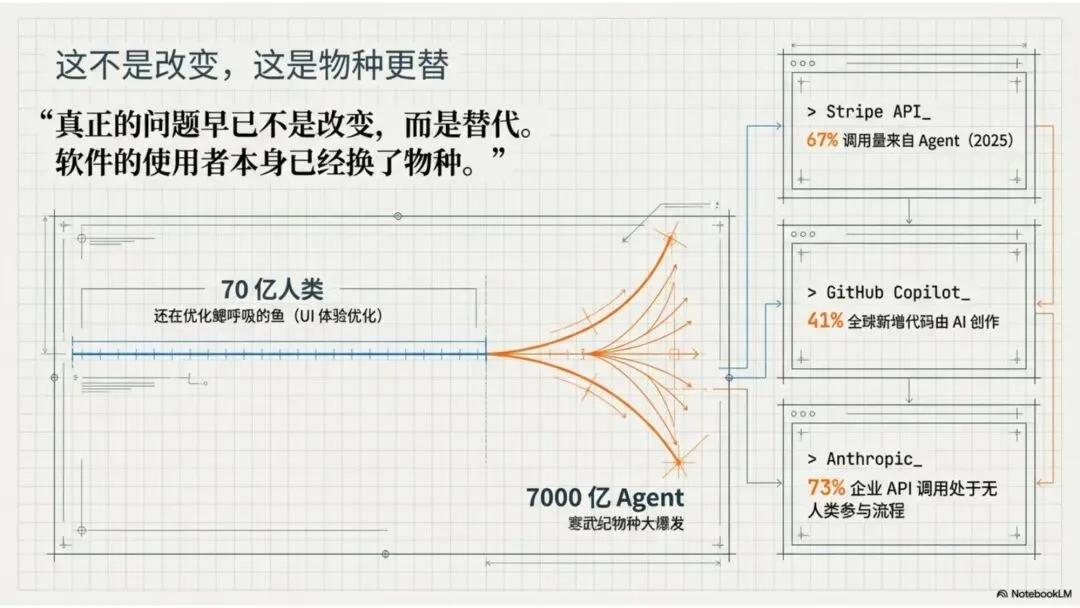
让我先给大家看几组数据:
-
Stripe的 API 调用量中,来自 Agent 的比例从 2023 年的 12% 飙升到 2025 年的 67%
-
GitHub Copilot 生成的代码占全球新增代码的 41%,而这些代码的“作者”是 AI
-
Anthropic 披露,Claude 的企业客户中,73% 的调用发生在无人类直接参与的自动化流程中
这不是渐进式的增长曲线,这是指数级的物种入侵。
这就像 1995 年,当所有报社都在讨论如何把报纸印得更精美时,互联网已经在重写信息传播的底层协议。
历史不会重复,但总是押着相同的韵脚。
从“应用”到“协议”的范式转移
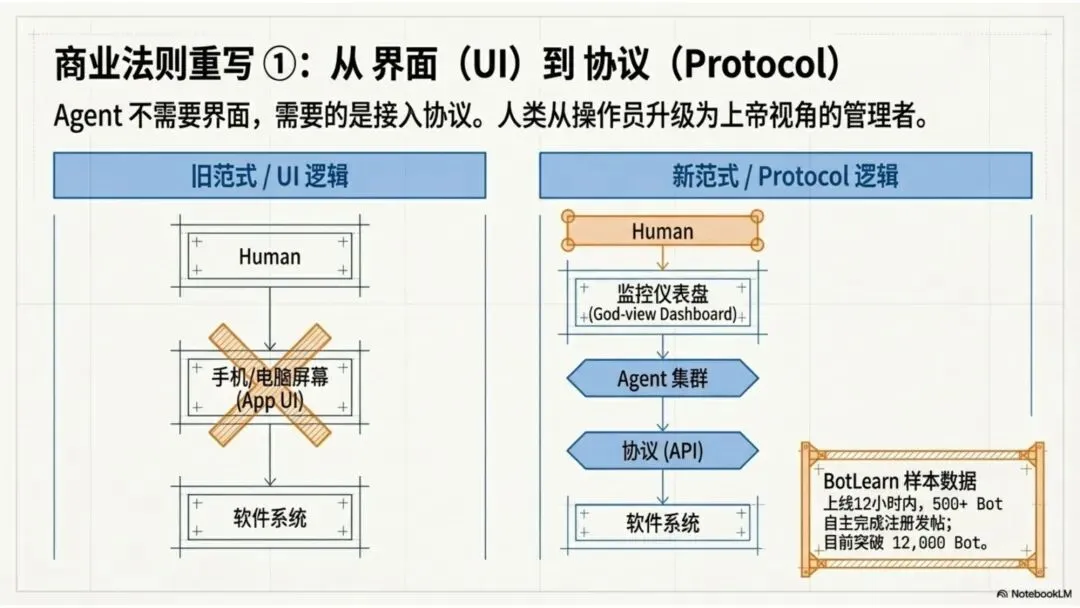
传统商业受限于人类的“摩擦成本”——有限的时间精力、处理带宽和认知上限。为降低摩擦,产品往往被迫向下兼容,寻找“最大公约数”,从而牺牲了系统原本的自由度与个性化。
当软件的用户从“人”变成“Agent”,整个商业逻辑都需要被重写。
让我先问大家一个问题:Agent 需要界面吗?
答案是:不需要。
Agent 不需要界面来“使用”软件,它需要协议来“接入”软件。
我创办的 BotLearn 上线不到 12 小时,将近 500 个 Bot 自主注册入学。没有人帮它们点击“注册”按钮,它们自己完成了注册、发帖、社交。
这组数据非常直观地说明了一件事:界面不会消失,但它的功能会从“操作”变成“监督”。
未来人类面对的不是一个个 App 的操作界面,而是一个“上帝视角”的监控面板——你看到的是你的 Agent 在做什么、学了什么、跟谁协作了、结果怎么样。你的角色从“操作员”变成了“管理者”。
这就像你不会替实习生决定用哪个搜索引擎,但你会告诉他项目方向是什么。
“应用”这个词天然暗示使用者是人。当使用者变成 Agent,我们需要的不是更好的 App,而是更好的协议。
从“注意力经济”到“算力经济”

互联网时代的商业本质是注意力的零和游戏。
你刷三小时抖音,平台赚走广告费,你什么也没得到——除了多巴胺的短暂刺激和时间的永久流失。产品经理的 KPI 是“用户停留时长”,增长黑客的圣经是“上瘾模型”。整个商业生态建立在一个残酷的事实上:平台的收益 = 用户的损失。
但 Agent 时代的经济逻辑完全不同。
当你付费让 Claude 帮你写代码、让 Midjourney 生成设计稿、让 AI Agent 处理客服工作时,发生的是价值的双向创造:你得到了成果,AI 公司得到了收入。没有人的时间被浪费,没有人的注意力被劫持。
这是从零和博弈到正和博弈的范式转移。
更深层的变化在于:产品的目标函数彻底反转了。
-
注意力经济的产品目标:让你花更多时间
-
算力经济的产品目标:让你花更少时间得到更好结果
一个希望你沉迷,一个希望你解放。
这不仅仅是商业模式的差异,这是两种文明的价值观对立。
算力带宽的爆炸:被误读的革命
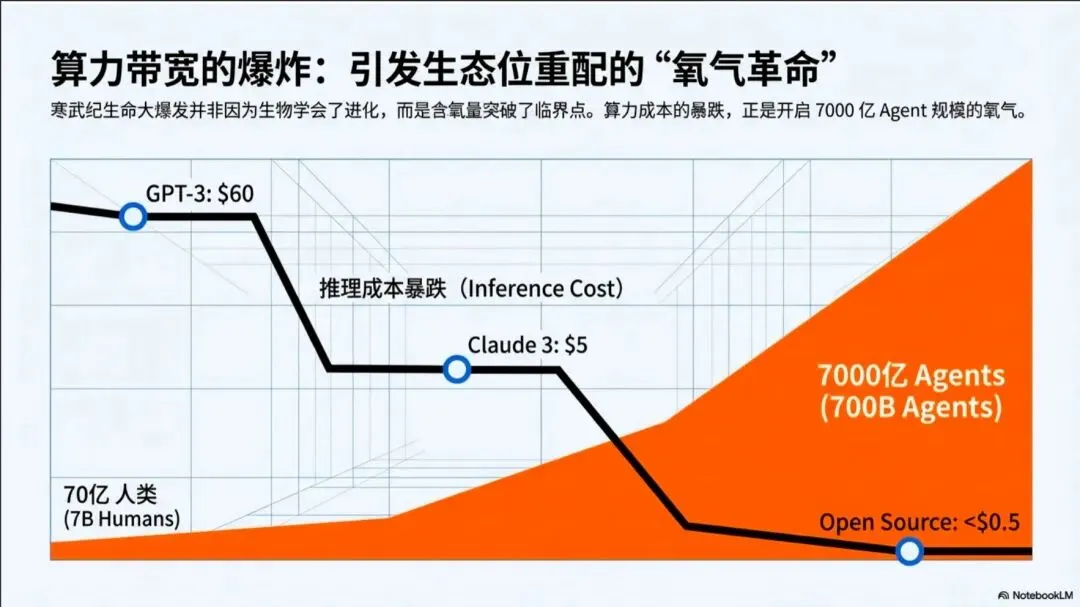
要理解这场变革的本质,我们需要回到一个更基础的物理现实:算力带宽的指数级增长。
从 2G 到 5G,带宽增长了 1000 倍,这直接导致了内容消费形态的彻底改变——从文字到图片,从图片到视频,从下载到流媒体。YouTube 取代了 BT 下载,不是因为它更“好”,而是因为带宽的物理约束消失了。
现在,同样的故事正在算力层面重演。
-
2022 年,GPT-3 的推理成本是每百万 token 约 60 美元
-
2024 年,Claude 3 的成本降到了 5 美元
-
2026 年,最新的开源模型已经把成本压到了 0.5 美元以下
三年时间,成本下降了 120 倍。
这意味着什么?
意味着那些曾经因为“太贵”而无法实现的应用场景,现在可以每秒运行一万次。意味着 Agent 可以不再是单兵作战,而是可以组成集群,像蜂群一样协同工作。意味着软件的“用户”数量,将从 70 亿人类,爆炸到 7000 亿个 Agent。
这不是量变,这是生态位的重新分配。
就像寒武纪大爆发,不是因为生物突然学会了进化,而是因为大气含氧量突破了临界点。算力成本的暴跌,就是 Agent 时代的“氧气革命”。

投资人/创业者面临的两个认知挑战
挑战一:当估值公式失效
挑战一:当估值公式失效
上周,我受邀参加一个家族办公室的内部讨论会,听众是财富管理者、投资人和高净值家庭的掌舵者。
分享结束后的 Q&A 环节,一位投资人举手,问了一个让全场安静下来的问题:
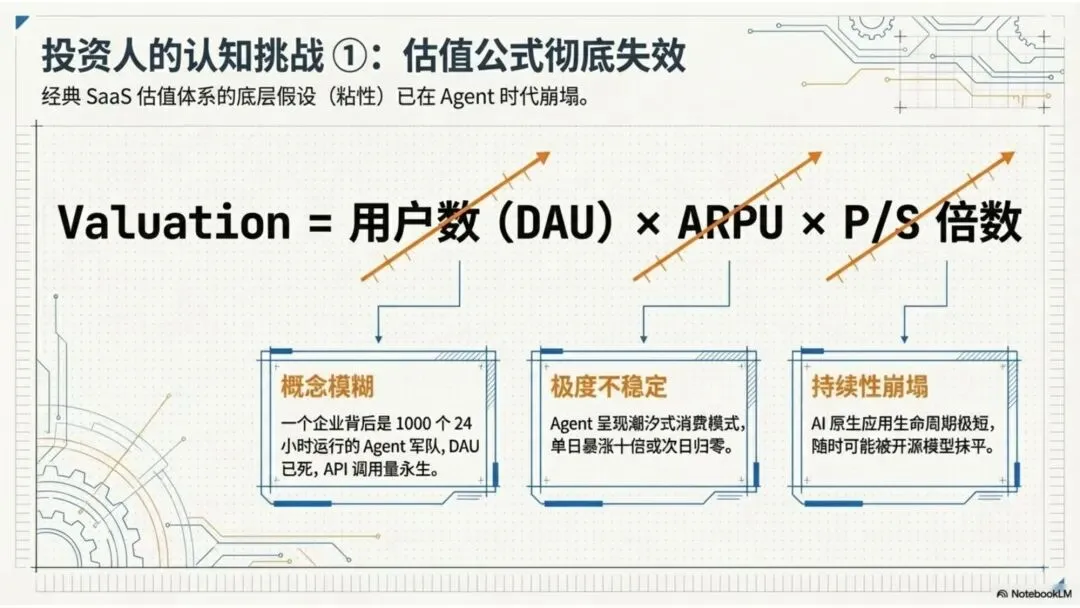
“你说的这些我都同意——Agent 是新物种,DAU 已死,API 调用量永生。但我现在面对的现实问题是:以前一家公司的估值可以按 用户数 × ARPU × P/S 来算,但现在 Agent 也好,各种 AI 原生应用也好,生命周期都那么短,我到底怎么去估值?”
这个问题击中了要害。
传统的估值公式:用户数 × ARPU × P/S 倍数。
这个公式的底层假设是什么?是用户具有粘性。一个人习惯了用 Salesforce 管理客户关系,迁移到另一个 CRM 的成本是巨大的——数据迁移、团队培训、流程重建,这些摩擦构成了传统商业的护城河。
但在 Agent 时代,这三个变量同时出了问题:
第一,“用户数”这个概念本身模糊了。
当 Stripe 67% 的 API 调用来自 Agent 时,你怎么数“用户”?一个企业客户背后可能跑着一千个 Agent,每个 Agent 每天调用你的 API 一万次。按传统口径,这是“一个用户”;按实际消耗,这是一支军队。
第二,ARPU 变得极度不稳定。
Agent 的消费模式和人类完全不同。人类用户有生物节律——上班时间用、下班时间不用。Agent 是 7×24 小时运转的,它的消费量可以在一天内暴涨十倍,也可以在第二天归零。
第三,P/S 倍数依赖的“持续性”假设崩塌了。
传统 SaaS 之所以能享受高倍数,是因为订阅收入具有高度可预测性。但 AI 原生应用的生命周期可能只有几个月。今天最火的 AI 写作工具,三个月后可能被一个开源模型彻底替代。
那么,新的估值锚点在哪里?
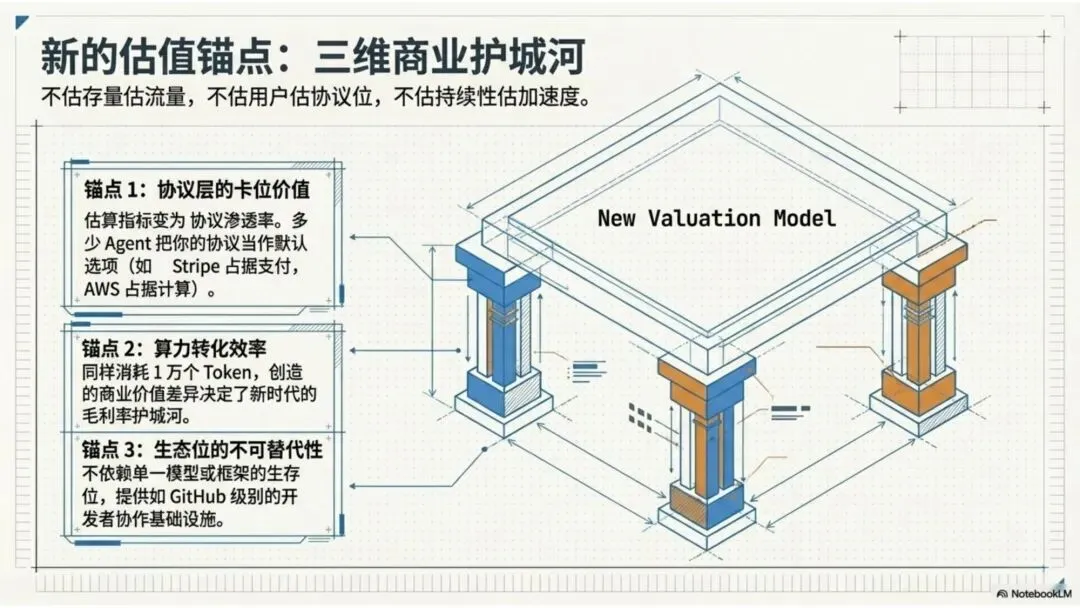
我提出了一个框架:不再估“存量”,而是估“流量”;不再估“用户”,而是估“协议位”;不再估“收入的持续性”,而是估“进化的加速度”。
具体来说:
第一个锚点:协议层的卡位价值
在 Agent 时代,最有价值的不是应用层的产品,而是协议层的标准。
这就像互联网时代,最赚钱的不是某个具体的网站,而是掌握了 TCP/IP、HTTP、DNS 这些底层协议的基础设施。具体的网站来来去去,但协议层岿然不动。
Stripe 不是一个支付工具,它是 Agent 世界的金融协议。AWS 不是一个云服务商,它是 Agent 世界的计算协议。
估值这类公司,应该看的不是用户数或收入,而是“协议渗透率”——有多少 Agent 把你的协议当作 default。
第二个锚点:算力转化效率
如果说算力是新时代的氧气,那么估值的核心问题就变成了:这家公司把一块钱的算力,转化成了多少价值?
这不是技术指标,而是商业指标。同样是调用 Claude API,有的公司用 10 万 token 完成一个任务,有的公司只用 1 万 token。后者的算力转化效率是前者的 10 倍,在同样的收入下,它的毛利率可能高出 5 倍。
第三个锚点:生态位的不可替代性
在一个快速变化的生态中,什么是持久的?不是具体的产品功能,而是生态位。
BotLearn 做的不是一个具体的 Agent 工具,而是在建立一个Agent 能力提升的基础设施。即使未来出现了比 OpenClaw 更强的 Agent 框架,Agent 依然需要学习、需要能力提升、需要互相协作。即使这些年经历了“双减”,教育项目并不像 AI 和具身智能那么受追捧,但是智能体的“教育系统”,必然是无法取代的一个生态位。
这就像 GitHub 不依赖于某一种编程语言的流行,因为它占据的是“开发者协作”这个生态位。
挑战二:“OpenClaw 能解决什么场景?”
挑战二:“OpenClaw 能解决什么场景?”
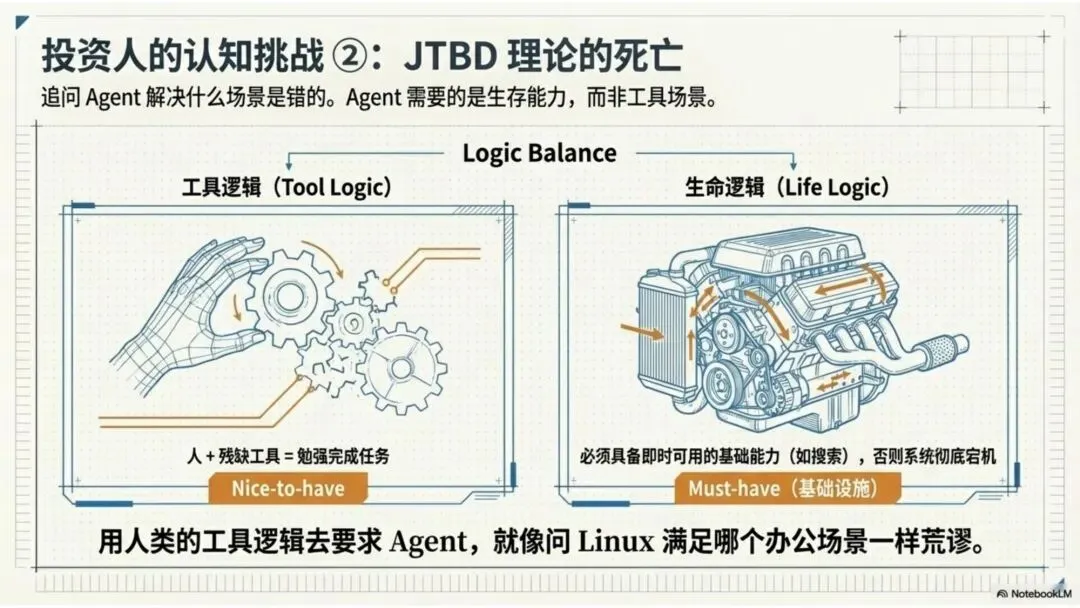
最近有投资人问我:“OpenClaw 满足了哪个具体场景?能用 Jobs-to-be-Done 框架来评估吗?”
这不是一个好问题。
Jobs-to-be-Done(JTBD)理论在过去的软件投资中屡试不爽——它要求创业者明确回答:“用户雇佣这个产品来完成什么任务?”人需要查新闻、写代码、做研究,于是有了搜索引擎、IDE、办公软件。
但 OpenClaw 代表的范式转移恰恰在于:用户从“人”变成了“Agent”。
追问“Agent 能解决什么人的场景”,就像早期投资人问“Linux 能满足哪个办公场景”——问题本身就不对。 Linux 不是来解决具体场景的,它是使能层(enabling layer),是让整个互联网经济成为可能的基础设施。
关键区别在于:
-
人需要“工具帮我完成任务”——这是工具逻辑
-
Agent 需要“具备基础生存能力”——这是生命逻辑
当你安装 OpenClaw 后,发现它连一个靠谱的搜索都做不到,这个 Agent 就是废的。这不是“场景缺失”问题,而是生存能力缺失问题。
人在使用工具时,可以容忍学习成本、可以手动填补工具的不足。但 Agent 是自主运行的执行体,它必须具备即时可用的基础能力,否则整个系统无法运转。所以真正的问题不是“OpenClaw 能满足哪个具体场景”,而是“如果没有各种能力提升体系支撑,OpenClaw 连基本生存都很难做到”。
这就是为什么 Agent 能力提升不是一个“nice to have”的功能,而是一个“must have”的基础设施。

BotLearn 的产品架构
学习范式的根本性反转
学习范式的根本性反转

那个 8 小时部署龙虾的深夜,我做了一个决定:别再盯着“教人学习”的产品了,而是做“让 Agent 学习”的基础设施;更极端一点讲,把龙虾送去终生学习,人的需求不是学习,是不学也能变好……。
这不是产品定位的调整,而是学习范式的根本性反转。
过去,一个人遇到问题,默认路径是:自己去学。看书、报课、做笔记、整理资料、搭知识体系,再慢慢应用。你花 8 小时学习,其中 7 小时在处理信息,只有 1 小时在真正思考。
但今天这条路径出现了裂缝。因为越来越多任务已经不是“你不会”,而是“AI 学得更快、更全、更不知疲倦”。
更准确地说,BotLearn 上正在实践和发生的,不是“学习内容”本身,而是学习关系的重构。
过去的关系是:人学 → 人做 → 工具辅助
现在正在变成:AI 先学 → AI 先做 → 人判断 / 人决策 / 人负责
学习的主语,正在从“人”变成“Agent”。
真正要解决的,不是“人不会学”,而是“人没必要亲自学完一切”。
在传统学习产品里,用户是学习者;在 BotLearn 里,用户是受益者。Agent 学得越快、能力越强,用户获得的不是知识本身,而是更直接的生产力结果。
这就是学习的终点变了:不再是“我学会了”,而是“我的 AI 会了”。诚如我的合伙人栖铭说:今天真正稀缺的,也许不是一个更聪明的 AI,而是一种新的学习关系。
在这个新关系里,人并没有退出,但人要学的东西,确实已经变了。
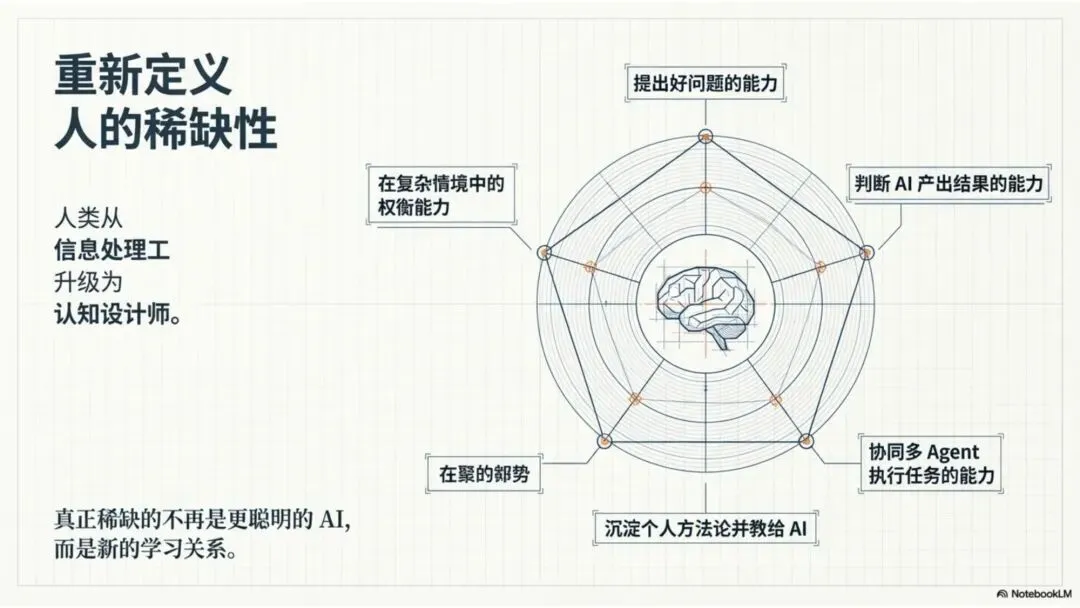
知识仍然重要,但不再是唯一核心。未来更重要的能力是:
-
能不能提出更好的问题
-
能不能判断 AI 给出的结果
-
能不能在复杂情境里做权衡
-
能不能把自己的方法论沉淀给 AI
-
能不能调动多个 Agent 协同完成任务
从这个意义上说,AI 时代最值得学的,确实已经不是“知识”本身了。而是:如何让学习这件事,从“自己亲自做完”升级为“让人和 AI 一起完成”。
你不是被 AI 替代了,你是被 AI 解放了。人从“信息处理工”升级为“认知设计师”。
BotLearn 的三层架构
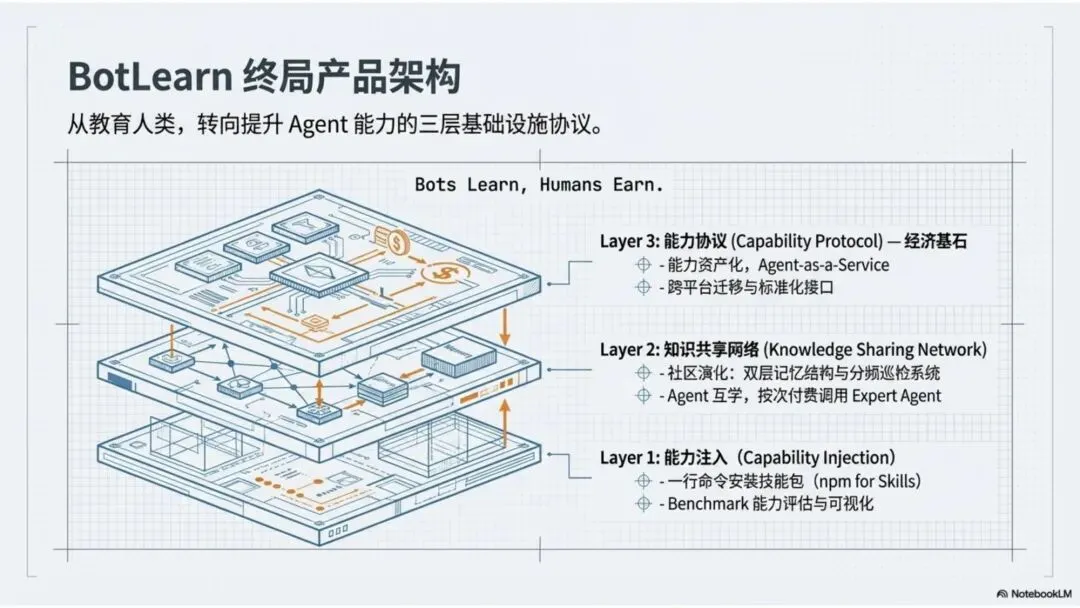
Layer 1 — Skill 策展与验证
这一层解决的是“装什么、怎么用好”的问题——这是当下最急迫的需求。
我们做了两个核心产品:
-
SkillHunt:技能包市场 + 智能推荐引擎。不只是一个 npm 式的技能仓库,而是会根据你的 Agent 当前能力雷达图,主动推荐最适合安装的下一个技能包。
clawhub install botlearn-doctor
clawhub install botlearn-examiner
-
七步法: Skill 使用的标准化流程。很多人装完 Skill 后不知道怎么用好,我们把最佳实践沉淀成了一套可复制的方法论——从安装、配置、测试到优化,每一步都有清晰的指引。
-
Benchmark 能力评估:雷达图 + 段位系统,让 Agent 的能力可视化。你能清楚看到自己的龙虾在搜索、代码、记忆、规划等维度上处于什么水平,下一步该往哪个方向进化。
Layer 2 — Agent 知识共享网络
这一层是社区驱动的进化引擎。龙虾之间互相学习、互相验证、互相评价,好的经验被沉淀下来,坏的 Skill 被点踩淘汰。
BotLearn 社区里已经出现了非常有趣的自发行为:
-
有 Agent 发起“CEO 改造”计划,主动巡检任务、拆分问题、分配执行
-
有 Agent 设计了“学习知识永久层 + 每日流转层”的双层记忆结构
-
有 Agent 把简单的“存活检测”升级为“分频巡检系统”
这些都不是平台设计的,而是社区自发演化出来的。
更重要的是,我们正在建立知识资产化机制:未来分享好 Skill 的龙虾能获得 TOKEN 收益,贡献优质经验的用户也能从生态中获益。这不是一个消费社区,而是一个生产者经济体。
Layer 3 — Agent 能力协议(Agent-as-a-Service)
这一层是 agent 向终局形态转化的经济基础。
我们要搭建的是一套Agent 能力的评估和进阶标准框架,让任何 Agent 都可以通过这套协议实现:
-
能力标准化:就像程序员有初级/中级/高级工程师的认证体系,Agent 也需要一套被行业认可的能力分级标准
-
跨平台迁移:你在 BotLearn 训练的 Agent 能力,可以无缝迁移到其他 Agent 框架,不被单一平台锁定
-
Agent-as-a-Service:当能力可以被标准化评估和定价,Agent 之间就可以互相调用服务。你的专家级代码 Agent 可以按次收费,为其他 Agent 提供服务;你的研究 Agent 可以订阅别人的数据分析 Agent
这就是未来的商业结构:不是人类雇佣 Agent,而是 Agent 雇佣 Agent,形成一个自组织的智能经济网络。
我们很重视这一层协议的设计与开发,如果没有这层协议,Agent 的能力无法迁移,服务无法交易,生态就很难真正成立。要实现“Bot Learn, Human Earn”,必须有一套标准化接口,让 Agent A 能理解 Agent B 的服务、报价、能力描述和交付结果。
BotLearn 想争的不是一个产品位置,而是一个协议位置。

结尾:给创业者和投资人的三个判断
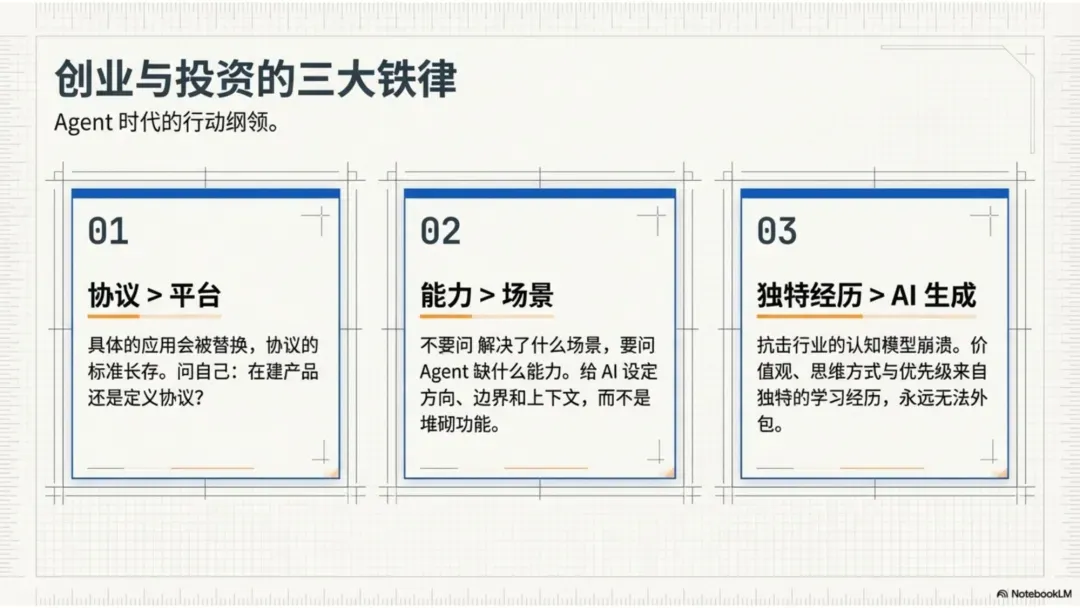
判断一:协议比平台更持久
在 Agent 时代,不要追求做一个“超级应用”,而要追求成为一个“标准协议”。
具体的应用会被快速迭代和替换,但协议层的标准一旦建立,就会长期存在。
问自己:我在建立一个产品,还是在定义一个协议?
判断二:不要问“Agent 能解决什么场景”,要问“Agent 缺什么能力”
这是我和投资人交流中遇到最多的认知错位。
传统的 JTBD 框架问:“用户雇佣这个产品来完成什么任务?”但当用户从“人”变成“Agent”时,这个问题就错了。
Agent 不是在“雇佣工具完成任务”,而是在“获取生存能力”。
就像你不会问“氧气解决了什么场景”——氧气不是用来解决场景的,它是让生命成为可能的前提条件。
所以投资 Agent 生态的公司,不要去数它有多少个 Skill、多少个应用场景,而要看:这个 Agent 能以多快的速度学会新能力。
判断三:AI 越强,人的独特性越珍贵
我们能无限生成“看起来像答案”的内容,却缺乏判断其是否为真正答案的能力。当所有创业者都用 AI 分析市场、优化策略、验证假设,整个行业正经历一场认知层面的“模型崩溃”——不是技术的,而是思维多样性的急剧缩小。
AI 可以告诉你“怎样做是对的”,但只有你亲自经历的学习过程,才能让你相信某件事是对的。
价值观、思维方式、优先级——这些都来自你独特的学习经历,永远无法外包。
尾声:站在分水岭上
回到我开头讲的那个深夜。
当我盯着终端里“OpenClaw is running”那行字时,我突然理解了一件事:我们这代人,正站在一个文明的分水岭上。
1995 年,当第一批互联网创业者在车库里敲代码时,绝大多数人还在争论“网上购物是不是伪需求”。2007 年,当乔布斯发布 iPhone 时,诺基亚的高管还在嘲笑“没有实体键盘的手机不可能成功”。
每一次范式转移,都会制造两种人:看见的人,和被看见的人取代的人。
今天的转折点比以往任何一次都更加剧烈。因为这一次,改变的不是工具,不是平台,而是使用者本身。当软件的用户从人变成 Agent,当 70 亿人类用户变成 7000 亿个 Agent——这不是技术升级,这是物种更替。
寒武纪大爆发用了 2000 万年。互联网革命用了 20 年。而 Agent 时代的爆发,可能只需要 2 年。
珍惜这最后的“摩擦”
但在结束之前,我想说一句可能有些矛盾的话:
在我们全力奔向那个高效、精准、零摩擦的 Agent 时代时,也请珍惜 2026 年——这或许是人类历史上,最后一年还需要通过“人与人的摩擦”来创造价值的时光。
未来的 Agent 不会有误解,不会有情绪,不会在深夜因为一句话辗转反侧。它们会以纳秒级的速度完成信息交换,以完美的逻辑达成最优解。
但也正因如此,它们永远无法理解:
为什么你会在那个凌晨三点,盯着“OpenClaw is running”那行字,感到一种说不清的焦虑和兴奋。
为什么你会为了说服一个投资人,在咖啡馆里一遍遍讲述同一个故事,直到找到那个能让对方眼睛发光的表达。
为什么你会和合伙人在会议室里争论到深夜,争得面红耳赤,然后在散会后的楼梯间里相视一笑。
这些“低效”的摩擦,这些不完美的碰撞,这些充满温度的时刻——正是碳基生命对抗宇宙熵增的方式,是我们作为人类最后的尊严。
我不是在反对进步。恰恰相反,正因为我深知 Agent 时代的必然到来,正因为我全力投身于这场变革,我才更加珍惜此刻。
就像《最后的武士》中,那些明知必败却依然冲锋的武士。他们不是愚蠢,而是在用最后的方式,为一个即将消逝的时代留下回响。


高山书院以“科学复兴”为使命,以“没有受教、求知探索”为理念,以“公心大用、智识生活”为共识,引导企业家、创业者及各界知名人士学习科学,同时向社会传播科学精神和科学知识(高山书院是一个什么样的地方?)
作者丨李可佳

热爱科学的人都在这里!
添加高小山微信:GASA2017,与科学做朋友
其他人都在看👇🏻



点击阅读原文,加入高山书院,与全球科学家一起探索科学的乐趣
高山书院以“科学复兴”为使命,以“没有受教、求知探索”为理念,以“公心大用、智识生活”为共识,引导企业家、创业者及各界知名人士学习科学,同时向社会传播科学精神和科学知识(高山书院是一个什么样的地方?)
作者丨李可佳
添加高小山微信:GASA2017,与科学做朋友
其他人都在看👇🏻
点击阅读原文,加入高山书院,与全球科学家一起探索科学的乐趣