 夜雨聆风
夜雨聆风





OpenClaw 工具引擎架构全解析:AI Agent 的"双手"是怎么工作的?
大语言模型很会”想”,但它自己不能读文件、不能跑命令、不能上网。AI Agent 之所以能真正干活,靠的是一套工具引擎——它是 Agent 的”双手”,负责把模型的思考变成实际操作。
OpenClaw 的工具引擎不是一个单体模块,而是由 Agent Runtime 和 Gateway 两端协同执行:Runtime 负责调度工具调用,Gateway 负责管理浏览器实例、MCP Server 进程等重资源。两者通过 Session 共享状态。
这套引擎的设计相当精巧:三层工具体系、权限-审批-沙盒三重安全网、并行执行、自动容错。这篇文章从源码层面拆解它的每一个环节。
读完这篇你会了解:
-
• 一个工具调用从发起到返回的完整链路(7 步) -
• 内置工具、Skills 插件、MCP Server 三层架构各自的定位和取舍 -
• exec / browser 这两个高危工具的安全设计细节 -
• 并行执行的策略和边界情况处理 -
• 生产环境下的容错哲学——为什么”把错误暴露给模型”比”隐藏错误”更好
一、一个工具调用的完整旅程
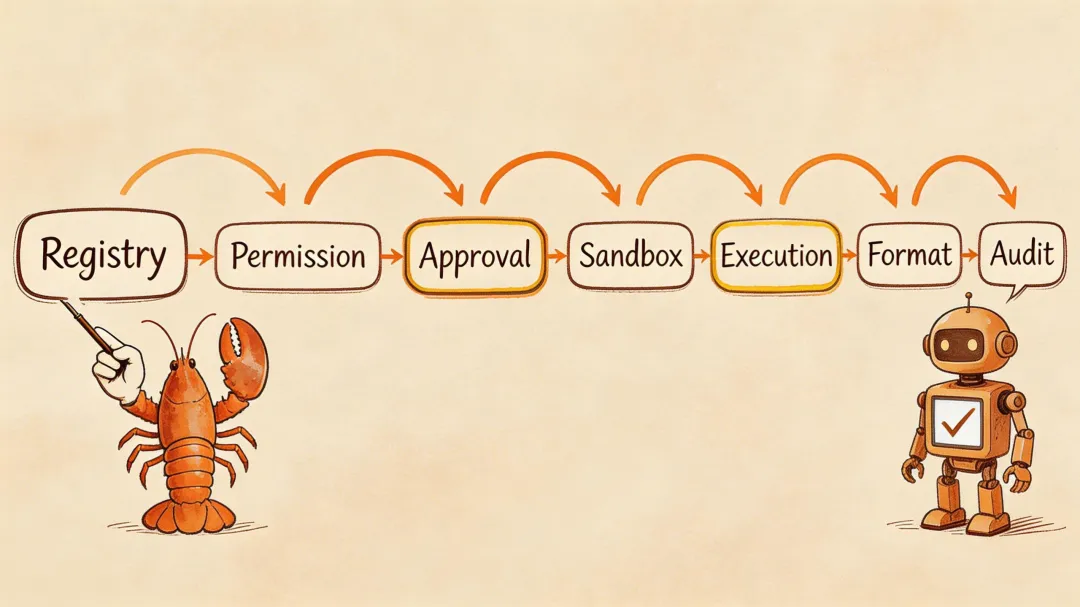
在深入细节之前,先看全局:当模型决定调用 exec ls -la 时,工具引擎到底做了什么?
七步流水线,每一步都是一道安全闸门。注册表确认工具存在,权限确认 Agent 有资格用,审批确认操作被允许,沙盒决定在哪跑。任何一步失败,都会返回结构化错误给模型——模型可以据此换方案,而不是直接崩掉。
二、三层工具体系:从内置到生态
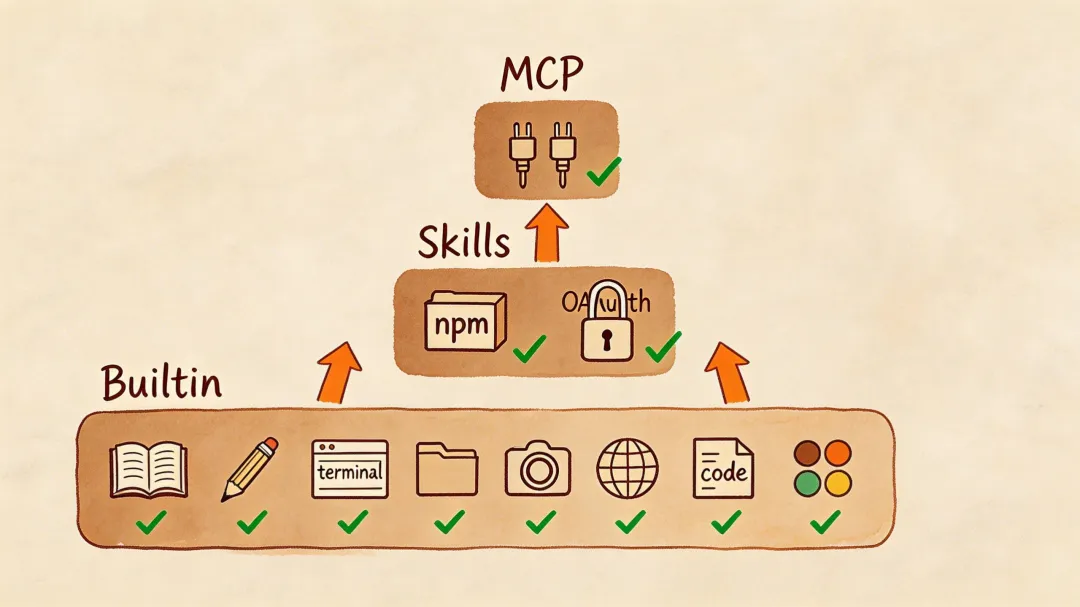
OpenClaw 的工具注册表(Tool Registry)分三层,越往上越灵活、越开放:
Layer 1 — 内置工具:八大金刚,硬编码在 Agent Runtime 里,开箱即用。这是 Agent 最基础的能力——读写文件、跑命令、搜代码、上网、操作浏览器。
Layer 2 — Skills 插件:通过 npm 包安装的能力扩展。Gmail、Calendar、GitHub 这些第三方集成都走这层。社区可以贡献新 Skill。
Layer 3 — MCP Server:标准协议(Model Context Protocol),动态发现工具。任何实现了 MCP 协议的服务器都能即插即用,不需要改 Agent 代码。
这种分层设计的好处是:核心能力稳定可靠(Layer 1),扩展能力丰富灵活(Layer 2),外部集成无限开放(Layer 3)。
三、内置工具详解:八大金刚

3.1 工具清单与参数
先看完整的接口定义:
// read - 读取文件interface ReadParams { path: string; // 文件绝对路径 offset?: number; // 起始行 (1-indexed, 负数从末尾) limit?: number; // 读取行数}// 返回: 行号标注的文件内容// write - 写入文件interface WriteParams { path: string; // 文件路径 (自动创建目录) contents: string; // 文件内容}// 原子写入: 写入 .tmp → rename (防止写一半崩溃)// edit - 精确替换interface EditParams { path: string; oldString: string; // 要替换的文本 (必须在文件中唯一) newString: string; replaceAll?: boolean; // 替换所有匹配 (默认 false)}// exec - 执行终端命令interface ExecParams { command: string; // shell 命令 cwd?: string; // 工作目录 (默认: Agent Workspace) timeout?: number; // 超时 ms (默认: 60000) env?: Record<string, string>; // 额外环境变量}// 返回: { stdout, stderr, exitCode, timedOut }// glob - 文件搜索interface GlobParams { pattern: string; // glob 模式 (自动加 **/ 前缀) cwd?: string; // 搜索起点}// grep - 内容搜索 (ripgrep 后端)interface GrepParams { pattern: string; // 正则表达式 path?: string; // 搜索路径 glob?: string; // 文件过滤 "*.ts" contextLines?: number; // 上下文行数}// browser - 浏览器自动化interface BrowserParams { action: "navigate" | "click" | "type" | "screenshot" | "extract" | "evaluate" | "wait" | "scroll"; url?: string; // navigate 用 selector?: string; // click/type 用 text?: string; // type 用 expression?: string; // evaluate 用}// web - 网页搜索interface WebParams { query: string; // 搜索关键词 maxResults?: number; // 结果数量 (默认 5)}// 返回: 摘要 + URL 列表几个值得注意的设计:
-
• write 是原子写入:先写 .tmp文件,再rename。这意味着不会出现”写了一半断电导致文件损坏”的情况。 -
• edit 要求唯一匹配: oldString必须在文件中唯一出现,否则报错。这避免了”改一处却改了十处”的事故。 -
• grep 底层是 ripgrep:所以搜索速度极快,万级文件目录也能在 1 秒内完成。
3.2 exec 工具:最危险也最强大
exec 是所有内置工具里权限最高的——它能执行任意 shell 命令。因此安全链条也最长:
匹配 deny 列表
匹配 requireApproval
匹配 autoApprove
sandbox=off
sandbox=non-main + 主会话
sandbox=non-main + 其他会话
sandbox=all
是
否
审批检查的优先级很关键:deny > requireApproval > autoApprove。也就是说,黑名单永远优先于白名单。超时处理也很讲究——先发 SIGTERM 给进程一个优雅退出的机会,等 5 秒还没退就 SIGKILL 强杀。
3.3 browser 工具:Playwright 驱动的浏览器自动化
底层用的是 Playwright(Chromium headless),生命周期管理如下:
安全方面限制得很死:
|
|
|
|---|---|
file://
|
|
127.0.0.1:18789 |
|
|
|
|
|
|
|
|
|
|
|
|
|
这些限制的核心思路是防止 Agent 通过浏览器攻击自身基础设施——比如访问 Gateway 的管理端口、读取本地文件等。
四、Skills 插件系统:npm 生态的力量
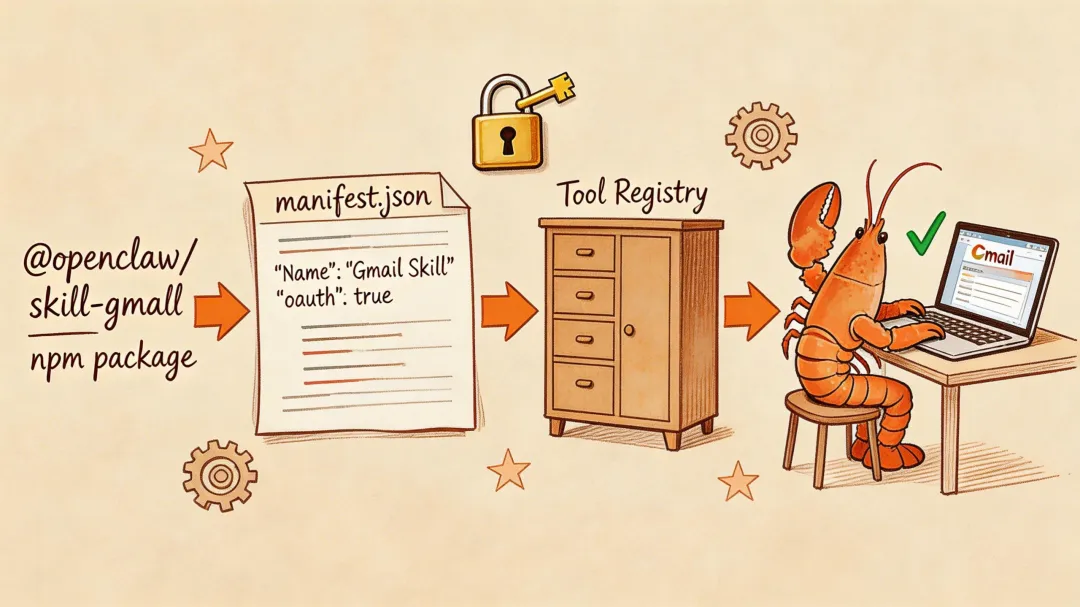
4.1 Skill 的目录结构
每个 Skill 就是一个标准 npm 包,结构清晰:
@openclaw/skill-gmail/├── package.json 标准 npm 包├── manifest.json Skill 元数据├── src/│ ├── index.ts 入口 (导出 SkillFactory)│ ├── tools/│ │ ├── list.ts gmail.list 实现│ │ ├── send.ts gmail.send 实现│ │ ├── archive.ts gmail.archive 实现│ │ └── search.ts gmail.search 实现│ └── auth/│ └── google-oauth.ts OAuth 2.0 流程└── README.md4.2 Skill Manifest:工具的”身份证”
manifest.json 声明了这个 Skill 提供哪些工具、每个工具的输入 Schema、以及所需的认证方式:
{ "name": "gmail", "version": "1.0.0", "displayName": "Gmail Integration", "description": "Read, send, and manage Gmail emails", "author": "@openclaw", "tools": [ { "name": "gmail.list", "description": "列出收件箱邮件。支持过滤标签、已读状态、日期范围。", "inputSchema": { "type": "object", "properties": { "query": { "type": "string", "description": "Gmail 搜索语法, 如 'is:unread from:boss'" }, "maxResults": { "type": "number", "default": 10 }, "labelIds": { "type": "array", "items": { "type": "string" } } } }, "auth": { "type": "oauth2", "provider": "google", "scopes": ["gmail.readonly"] } }, { "name": "gmail.send", "description": "发送邮件。", "inputSchema": { "type": "object", "required": ["to", "subject", "body"], "properties": { "to": { "type": "string" }, "subject": { "type": "string" }, "body": { "type": "string" }, "cc": { "type": "string" }, "attachments": { "type": "array" } } }, "auth": { "type": "oauth2", "provider": "google", "scopes": ["gmail.send"] } } ]}注意 auth 字段:每个工具可以声明自己需要的 OAuth scope,安装时引导用户授权,运行时自动管理 Token 刷新。
4.3 Skill 的安装与运行时
安装流程——从 npm install 到热生效,无需重启:
是
否
运行时执行——模型调用 gmail.list 时的完整链路:
有效
过期
无 Token
Skill 的代码接口也非常简洁:
interface SkillFactory { name: string; manifest: SkillManifest; createTools(context: SkillContext): ToolImplementation[];}interface SkillContext { auth: AuthManager; // OAuth Token 管理 config: Record<string, any>; // Skill 配置 logger: Logger; storage: SkillStorage; // Skill 持久化存储}一个 createTools 方法返回所有工具实现,SkillContext 提供了 Auth、Config、Storage 等基础设施。开发一个新 Skill 的心智负担很低。
五、MCP Server 集成:标准协议的威力
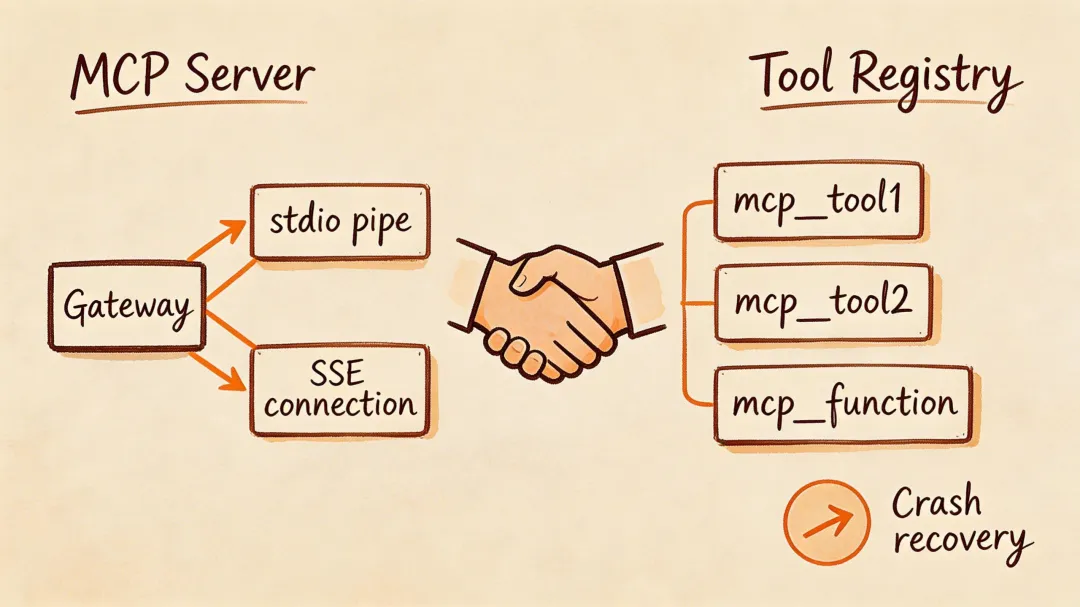
5.1 MCP 的完整生命周期
MCP(Model Context Protocol)是一个开放标准,让任何外部服务都能以统一方式为 Agent 提供工具。OpenClaw 对 MCP Server 的管理非常完善:
stdio
sse
MCP Server 崩溃
重启成功
几个设计亮点:
-
1. 双传输协议:stdio(本地进程)和 SSE(远程服务)都支持。本地工具用 stdio 低延迟通信,远程服务用 SSE 走 HTTP。 -
2. 工具名前缀: read_file变成mcp__filesystem__read_file,彻底避免不同 MCP Server 之间的命名冲突。 -
3. 崩溃自愈:MCP Server 挂了不会影响其他工具,后台指数退避重启,恢复后自动重新注册。
5.2 MCP 配置示例
{ "mcpServers": { "filesystem": { "command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", "/home/user"], "env": {} }, "database": { "command": "npx", "args": ["-y", "@openclaw/mcp-sqlite", "--db", "/path/to/db.sqlite"], "env": {} }, "custom-rag": { "url": "http://localhost:8080/mcp", "transport": "sse" } }}配置非常直白:command + args 是 stdio 模式,url + transport 是 SSE 模式。
5.3 Skills vs MCP:什么时候用哪个?
有了 Skills 和 MCP 两种扩展机制,一个自然的问题是:做一个新集成,该选哪个?
|
|
|
|
|---|---|---|
| 开发语言 |
|
|
| 安装方式 | npm install
|
|
| Auth 管理 |
|
|
| 状态管理 |
|
|
| 适合场景 |
|
|
| 生态壁垒 |
|
|
简单来说:如果你在做一个 Gmail/GitHub 级别的深度集成,选 Skills;如果你已有一个 Python 服务想快速暴露给 Agent,选 MCP。
六、Tool Router:工具分发的中枢大脑
前面三节讲的是”有哪些工具”,这一节开始讲”怎么调度它们”。Tool Router 是整个执行链路的入口——它接收模型的 tool_call,决定交给谁执行、是否需要审批、要不要进沙盒。
先看核心代码(约 50 行,逻辑非常清晰):
class ToolRouter { async execute(toolCall: ToolCall, context: ExecutionContext): Promise<ToolResult> { const { name, arguments: args } = toolCall; // [1] 权限检查 if (!this.policy.isAllowed(name, context.agent)) { return { toolCallId: toolCall.id, content: `Permission denied: ${name}`, isError: true }; } // [2] 路由分发 let executor: ToolExecutor; if (name.startsWith("mcp__")) { executor = this.mcpManager.getExecutor(name); } else if (this.builtinTools.has(name)) { executor = this.builtinTools.get(name)!; } else if (this.skillsManager.match(name)) { executor = this.skillsManager.getExecutor(name); } else { return { toolCallId: toolCall.id, content: `Unknown tool: ${name}`, isError: true }; } // [3] 审批检查 (仅 exec 类) if (name === "exec") { const approval = await this.approvals.check(args.command, context); if (approval === "deny") { return { toolCallId: toolCall.id, content: "Command denied by policy", isError: true }; } if (approval === "require") { const result = await this.approvals.requestApproval(args.command, context); if (!result.approved) { return { toolCallId: toolCall.id, content: `User ${result.action}: ${args.command}`, isError: true }; } } } // [4] 沙盒决策 const sandboxed = this.sandbox.shouldSandbox(name, context); // [5] 执行 + 超时 const result = await withTimeout( sandboxed ? this.sandbox.execute(executor, args) : executor.execute(args), context.agent.config.limits.toolTimeout ); // [6] 审计记录 this.audit.logToolExecution({ toolCall, result, sandboxed, context }); return result; }}路由的判定顺序是:mcp__ 前缀 → 内置工具表 → Skills 模式匹配 → 未知工具报错。先做前缀检查是因为 MCP 工具天然带有 mcp__ 前缀(见第五节),字符串前缀匹配 O(1) 最快,可以第一时间分流;而内置工具数量固定(Map 查找),也优先于 Skills 的模式匹配。这个顺序本质上是按匹配成本从低到高排列。
还有一个设计选择值得注意:审批检查只针对 exec(代码第 [3] 步)。为什么 write 不需要审批?因为 write 的破坏力有限——它只能写入 Agent Workspace 目录下的文件,而 exec 能执行任意 shell 命令(rm -rf /、curl 外泄数据、安装恶意包……)。审批的粒度精确对准了风险最高的那个入口。
七、工具定义如何传递给模型
工具引擎面临一个容易被忽视的问题:模型怎么知道有哪些工具可用? 答案是——每次调用模型时,都要把所有工具的 Schema 塞进 tools 参数。这不是免费的,每个 Schema 都会消耗上下文窗口的 Token。
≤ toolTokenBudget
> toolTokenBudget (默认 5000)
Token 预算控制是个很务实的设计。算一笔账:16 个工具 ≈ 2500 tokens,占 Claude 200K 上下文的 1.25%,看起来不多。但如果 Skill + MCP 扩展到 50 个工具,就是 ~8000 tokens——而且这个成本是每轮对话都要付的固定税,一个 10 轮对话就是 80K tokens 花在了工具 Schema 上。
按使用频率裁剪是个聪明的策略:Agent 的工具使用有明显的幂律分布(read/write/exec/edit 四大天王占 80%+ 调用),低频工具被移除后 Agent 大概率不会用到。即使偶尔需要,模型收到 “Tool not available” 后也能调整策略。
另一个被低估的设计:Anthropic 和 OpenAI 的工具 Schema 格式不同。OpenClaw 在这一步做了适配,意味着同一套工具定义可以无缝对接不同的模型提供商——这对于需要 multi-model fallback 的生产环境至关重要。
八、并行工具执行:一次请求,多工具齐发
当模型在一次回复中返回多个 tool_call 时,OpenClaw 默认并行执行:
[ tool_call("read", {"path": "a.txt"}), tool_call("read", {"path": "b.txt"}), tool_call("web", {"query": "latest news"})]执行策略是 Promise.allSettled()(注意不是 Promise.all())——所有工具同时启动,互不阻塞。选 allSettled 而非 all 是关键决策:all 在任一工具失败时会立即终止所有工具并抛错,而 allSettled 保证即使某个工具失败,其他工具的结果也能正常返回。在 Agent 场景下,部分结果远好于没有结果。
异常隔离是核心原则:单个工具失败只影响自己,返回错误信息,其他工具正常完成。每个工具有独立的 timeout 计时器。
边界情况处理(这些 edge case 的处理方式反映了设计哲学):
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
九、工具结果格式化:给模型的”翻译层”
工具执行完的原始输出五花八门——可能是 200KB 的 npm test 日志、一张 Base64 截图、或者一个 JSON 对象。模型不需要(也处理不了)这些原始数据。ToolResult 就是这个翻译层:
interface ToolResult { toolCallId: string; content: string; // 给模型看的文本 isError: boolean; metadata: { executionTimeMs: number; sandbox: boolean; approved?: boolean; truncated?: boolean; // 输出是否被截断 };}截断策略防止大输出撑爆上下文窗口。注意每种工具的阈值不同——这不是随意设定的,而是反映了各类输出的信息密度:
-
• exec输出 > 100KB → 截断。构建日志大量重复,截断损失小 -
• read文件 > 200KB → 截断 + 建议使用offset/limit。源码文件通常有结构,可以分段读取 -
• web搜索结果 → 每条最多 500 字摘要。搜索引擎已经做了初步摘要 -
• browser截图 → Base64(给视觉模型)或文字描述。视觉信息无法文本化截断,所以提供两种模式
传递给不同模型时的格式适配:
Anthropic: { type:"tool_result", tool_use_id, content, is_error }OpenAI: { role:"tool", tool_call_id, content }这个看似简单的格式差异,实际上是多模型 Agent 框架的一个常见痛点。OpenClaw 在 ToolResult 层统一抽象,在最后一步才做格式适配,避免了 Provider 特定逻辑污染整个工具链路。
十、自定义内置工具开发
理解了前面九节的执行链路,你会发现添加一个自定义工具只需要关心两件事:定义 Schema(告诉模型这个工具做什么、接受什么参数)和实现执行逻辑。路由、权限、审批、沙盒、结果格式化——这些全部由引擎处理。
import { ToolDefinition, ToolExecutor } from "../types/tool";export const myTool: ToolDefinition = { name: "my_tool", description: "简要说明这个工具做什么,模型根据此描述决定何时调用。", inputSchema: { type: "object", required: ["param1"], properties: { param1: { type: "string", description: "参数说明" }, param2: { type: "number", description: "可选参数", default: 10 }, }, },};export const myToolExecutor: ToolExecutor = { async execute(args: { param1: string; param2?: number }): Promise<string> { const result = await doSomething(args.param1, args.param2 ?? 10); return JSON.stringify(result); },};// 注册:// src/tools/builtin/index.ts// registry.register(myTool, myToolExecutor);两步:定义 Schema(ToolDefinition)+ 实现执行逻辑(ToolExecutor),然后在注册表里挂上。模型会根据 description 自动决定什么时候调用你的工具。
这里有个容易踩的坑:description 的质量直接决定了模型能否正确调用你的工具。写得太模糊,模型不知道什么时候该用;写得太具体,模型只在精确匹配时才用。好的 description 应该说明输入什么、做什么、输出什么,用一两句话。
十一、容错与监控:”把错误暴露给模型”
OpenClaw 的容错哲学可以用一句话概括:fail open to the model——出了问题,不要自己吞掉错误,而是把结构化的错误信息交给模型,让模型决定怎么处理。这比传统软件的”重试三次然后报错”要更适合 Agent 场景,因为模型有推理能力,能根据错误信息调整策略。
|
|
|
|---|---|
|
|
|
|
|
"Permission denied: {tool}"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这张表里藏着一个最精妙的设计决策:exec 退出码非零时不标记为 isError。
直觉上,命令执行失败 = 错误,应该标 isError: true。但 OpenClaw 刻意不这么做。原因是:npm test 失败时的 stderr 包含了具体哪个测试用例挂了、哪行代码有问题——这对模型来说不是”错误”,而是关键的上下文输入。如果标了 isError,某些模型可能会直接跳过 stderr 内容,反而失去了修复 bug 的线索。
这就是”fail open to the model”在实践中的体现:把原始信息原样交给模型,让它自己判断是”真错了”还是”有用的反馈”。
监控指标记录到 audit.jsonl + usage.jsonl:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
十二、性能特征:实测数据
最后附上各环节的实测性能数据,供架构选型参考:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 工具定义序列化(16 工具) | < 5ms |
| 工具定义 Token 开销(16 工具) | ~2500 tokens |
几个值得关注的规律:
-
1. 路由层几乎免费:Tool Router 分发 + 权限检查 < 2ms,工具定义序列化 < 5ms。引擎的设计正确地把优化资源放在了工具执行本身,而非调度层。 -
2. I/O 密集型工具是真正的瓶颈:browser navigate(1-10s)、web search(0.5-2s)、Skill/MCP 远程调用(0.5-2s)——这些都是网络 I/O 主导的操作,恰好是并行执行收益最大的场景。三个 read 串行需要 15-60ms,并行只需要 5-20ms(取最慢的一个);如果换成三个 web search,串行可能要 6 秒,并行只需 2 秒,差距更加显著。 -
3. Token 税不可忽视:16 个工具的 Schema 就要 ~2500 tokens,这是每轮对话都要”交”的固定成本。工具越多,留给实际任务的上下文窗口就越小。
总结与思考
设计精华
回顾整个工具引擎,有四个设计原则贯穿始终:
-
1. 分层解耦:内置工具保证基本功、Skills 扩展能力边界、MCP 连接无限生态。三层之间通过 Tool Registry 统一抽象,上层不感知下层差异。 -
2. 安全纵深:权限 → 审批 → 沙盒,三道防线层层递进。且安全粒度精确——审批只卡 exec,不给其他工具增加不必要的摩擦。 -
3. Fail Open to the Model:不吞掉错误,不过度重试,把结构化错误暴露给模型。模型有推理能力,比硬编码的重试逻辑更能做出正确判断。 -
4. 性能务实:并行执行、Token 预算控制、按信息密度分级截断。每一处都在权衡”好一点”和”贵多少”。
局限性与开放问题
不过,这套设计也有一些值得思考的地方:
-
• 工具间依赖缺失:当前的并行执行不做依赖分析。write + read 同一文件的竞态条件虽然”模型下一轮可以修正”,但在长链路任务中,这种”最终一致”可能导致不必要的多轮对话开销。未来是否需要引入轻量级的 DAG 调度? -
• 审批只覆盖 exec:随着 Skills 能力增强(比如 gmail.send可以发邮件、github.merge可以合并 PR),是否需要把审批机制泛化到高风险的 Skill 操作?目前这些都是”安装时授权,运行时放行”。 -
• Token 预算的冷启动问题:按使用频率裁剪工具需要历史数据。新 Agent / 新 Session 没有历史时,如何决定保留哪些工具? -
• MCP Server 的安全边界:MCP 协议本身不包含认证和授权。一个恶意 MCP Server 可以注册与内置工具同名(加 mcp__前缀后不同名)的工具,但可以注册看起来像合法工具的误导性名称。这个信任模型是否足够?
与同类方案的对比
如果你用过 LangChain 的 Tool 抽象或 AutoGen 的 Function Calling,会发现 OpenClaw 的差异化在于:
-
• LangChain 的工具是纯函数式的,没有内置的权限/审批/沙盒链路——这些都需要开发者自行实现 -
• AutoGen 的 Function Calling 直接暴露给模型,缺少 MCP 这样的标准化扩展协议 -
• OpenClaw 在工具安全和生态扩展性上走得更远,代价是引入了更多概念(三层体系、审批策略、沙盒模式)
没有哪个方案是银弹。如果你的场景是受控环境下的简单工具调用,LangChain 的轻量方案就够了。如果你需要在生产环境运行、给不信任的用户暴露 Agent 能力,OpenClaw 的安全纵深才值得引入。
如果你正在构建自己的 AI Agent 框架,建议优先借鉴的是这三个模式:Tool Router 的分层路由(简单但高效)、exec 的审批-沙盒链路(安全设计的最小可行方案)、以及 “fail open to the model” 的容错哲学(比硬编码重试好得多)。
项目地址:github.com/openclaw/openclaw — 工具引擎相关代码主要在 src/tools/ 和 src/gateway/ 目录下。