 夜雨聆风
夜雨聆风





Claude Code 可观测与审计:让 AI 编程助手不再是黑箱
AI Agent 正在接管越来越多的编码工作——读文件、写代码、执行命令、创建 PR。但你知道它具体做了什么吗?花了多少钱?有没有执行危险操作?本文系统梳理 Claude Code 的可观测与审计能力,从 OTel 遥测到 Hooks 审计,再到 eBPF 内核级追踪。
为什么 AI 编程助手需要可观测性
当你在终端里运行 claude,Claude Code 会自主决定读哪些文件、改哪些代码、执行什么命令。一个典型的编码会话可能包含几十次工具调用——Read、Write、Edit、Bash、Grep、Glob——每一次都在修改你的代码库。
这带来三个问题:
|
|
|
|---|---|
| 成本不可见 |
|
| 行为不可审计 |
|
| 安全无保障 |
|
好消息是,Claude Code 已经内置了相当完整的可观测能力。坏消息是,大部分默认关闭,需要你主动开启和配置。
四层可观测架构
Claude Code 的可观测性可以按数据来源和能力分为四层:

下面逐层展开。
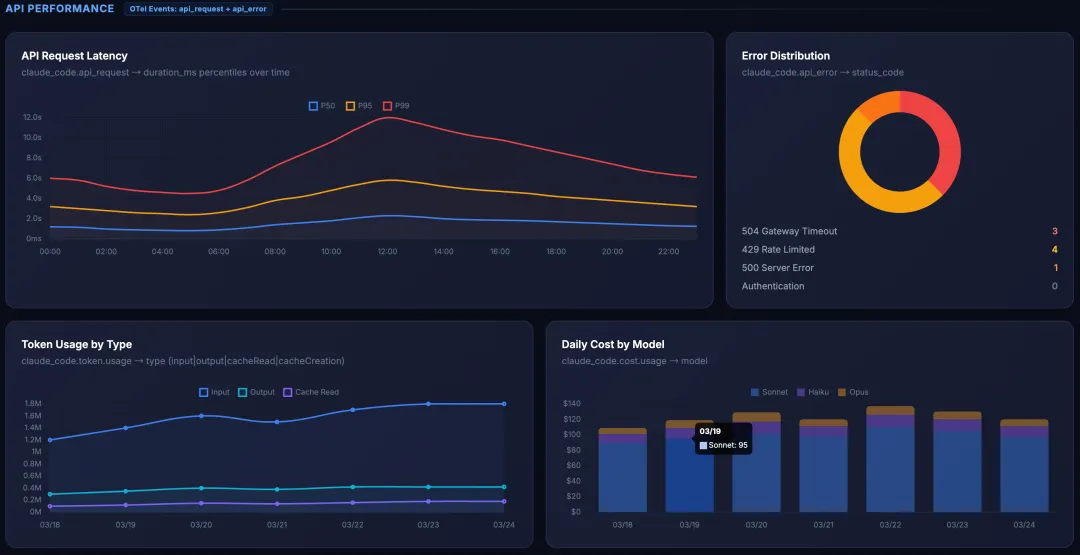
第 1 层:OTel 遥测 — 开箱即用的运行时指标
一键开启
Claude Code 内置了 OpenTelemetry SDK,只需设置环境变量即可开启:
export CLAUDE_CODE_ENABLE_TELEMETRY=1export OTEL_METRICS_EXPORTER=otlpexport OTEL_LOGS_EXPORTER=otlpexport OTEL_EXPORTER_OTLP_PROTOCOL=grpcexport OTEL_EXPORTER_OTLP_ENDPOINT=http://your-collector:4317Metrics Exporter 支持 otlp(推荐)、prometheus、console(调试);Logs/Events Exporter 支持 otlp 和 console(prometheus 仅适用于 metrics)。
8 项内置指标
|
|
|
|
|---|---|---|
claude_code.session.count |
|
|
claude_code.token.usage |
|
|
claude_code.cost.usage |
|
|
claude_code.lines_of_code.count |
|
|
claude_code.pull_request.count |
|
|
claude_code.commit.count |
|
|
claude_code.code_edit_tool.decision |
|
|
claude_code.active_time.total |
|
|
5 种事件
|
|
|
|
|---|---|---|
user_prompt |
|
|
tool_result |
|
|
api_request |
|
|
api_error |
|
|
tool_decision |
|
|
因果链追踪
所有事件共享 prompt.id 字段——同一个用户 Prompt 触发的所有 API 调用、工具执行、权限决策都能通过这个 ID 串起来:
用户输入: "帮我重构 auth 模块" │ └─ prompt.id: "uuid-abc-123" ├─ api_request (duration: 2.3s, cost: $0.05) ├─ tool_result (Read src/auth/login.ts, success, 3ms) ├─ tool_result (Write src/auth/login.ts, success, 12ms) ├─ tool_result (Bash: npm test, error, 6402ms) ├─ api_request (duration: 1.8s, cost: $0.03) └─ tool_result (Write src/auth/login.ts, success, 8ms)
隐私控制
|
|
|
|
|---|---|---|
|
|
不采集
|
OTEL_LOG_USER_PROMPTS=1 |
|
|
不采集 | OTEL_LOG_TOOL_DETAILS=1 |
|
|
tool_parameters 中 |
|
多团队隔离
export OTEL_RESOURCE_ATTRIBUTES="team.id=platform,department=engineering"所有指标和事件都会附带这些自定义属性,在 Grafana 中可以按团队/部门筛选。
第 2 层:Hooks — 唯一能”控制” AI 行为的机制
OTel 是纯观测——只能看,不能拦。Hooks 不一样:它能在工具调用前阻断操作、修改输入、注入上下文。
Hooks vs CLAUDE.md
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一句话:CLAUDE.md 是”请这样做”,Hooks 是”必须这样做”。
生命周期全景
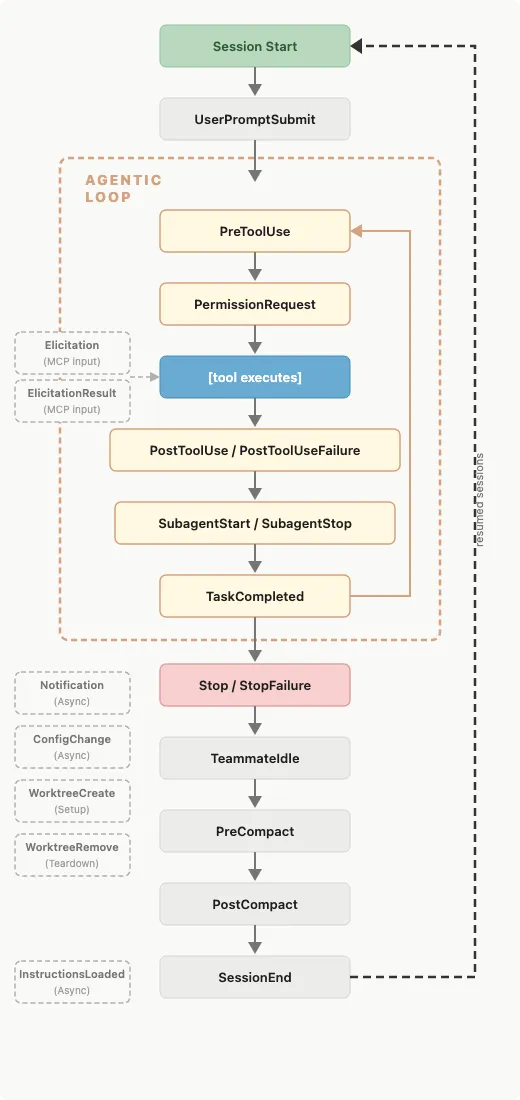
上图是 Claude Code 官方的 Hook 生命周期全景。从上到下看:
- 会话启动
(SessionStart)→ 用户输入(UserPromptSubmit) -
进入 Agentic Loop——这是 Claude 自主工作的核心循环:PreToolUse → 权限检查 → 工具执行 → PostToolUse → 子 Agent → TaskCompleted,循环直到 Claude 认为任务完成 - 会话结束
(Stop / StopFailure)→ 上下文压缩(PreCompact / PostCompact)→ SessionEnd -
左侧虚线框是异步事件(Notification、ConfigChange、WorktreeCreate 等),它们在循环外独立触发
22 种事件看着多,但按控制能力分成三类就清楚了:
|
|
|
|
|---|---|---|
| 控制点 |
|
|
| 接管点 |
|
|
| 观测点 |
|
|
Hook 如何解析:以 PreToolUse 为例
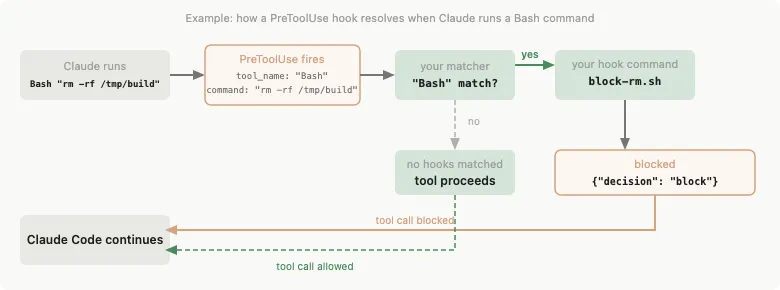
上图展示了一个 PreToolUse Hook 的完整解析流程:
-
Claude 准备执行 Bash "rm -rf /tmp/build" -
Hook 引擎触发 PreToolUse 事件,传入 tool_name: "Bash"+command: "rm -rf /tmp/build" - Matcher 匹配:
你配置的 matcher 是 "Bash",匹配成功 - Handler 执行:
调用你的脚本 block-rm.sh - Decision:
脚本返回 {"hookSpecificOutput": {"permissionDecision": "deny"}}→ 工具调用被阻断;如果没有匹配到任何 Hook,工具正常执行
这就是 Hooks 的核心工作模式:Event → Matcher → Handler → Decision。
四种 Handler
Hook 被触发后,由 Handler 执行具体逻辑。Claude Code 提供四种 Handler 类型:
|
|
|
|
|
|---|---|---|---|
| Command |
|
|
|
| HTTP |
|
|
|
| Prompt |
|
|
|
| Agent |
|
|
|
选型原则:确定性优先。能用 grep 匹配的别用 LLM 审查。
Hooks 核心机制
理解 Hooks 只需要记住一个模型和两条规则。
心智模型:Event → Matcher → Handler → Decision
Claude 准备执行 Bash "rm -rf /" ↓① Event: PreToolUse 触发 ↓② Matcher: "Bash" — 匹配到 block-dangerous.sh ↓③ Handler: Command Hook 执行脚本 stdin ← {"tool_name":"Bash","tool_input":{"command":"rm -rf /"}} 脚本检测到危险模式 stdout → {"hookSpecificOutput":{"permissionDecision":"deny",...}} ↓④ Decision: 阻断 — Claude 收到拒绝原因四步走完,就是 Hooks 的全部工作流。
退出码协议
Hook 脚本不是”跑个脚本就行”——它和 Claude Code 之间有明确的通信协议:
|
|
|
|
|
|---|---|---|---|
0 |
被解析 |
|
permissionDecision: deny 可阻断) |
2 |
被忽略 |
|
|
|
|
|
|
|
关键:exit 0 + JSON deny 是推荐的阻断方式(结构化、行为明确)。exit 2 的具体行为因事件类型而异(PreToolUse/Stop 会阻断并反馈 Claude,SessionStart/Notification 等仅显示给用户),不建议依赖。不要混用——exit 2 时 stdout 的 JSON 会被忽略。

同步 vs 异步
// 同步(默认)— 适合安全门禁{"type":"command","command":".claude/hooks/block-dangerous.sh"}// 异步 — 适合审计日志、通知{"type":"command","command":".claude/hooks/audit-log.sh","async":true}|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
不能 |
|
不要把 async Hook 当安全闸门——它的结果在下一轮才送达 Claude,当前操作已经执行了。
三个最实用的场景
场景 1:阻止危险命令(PreToolUse)
配置 .claude/settings.json:
{ "hooks":{ "PreToolUse":[ { "matcher":"Bash", "hooks":[{ "type":"command", "command":".claude/hooks/block-dangerous.sh" }] } ] }}脚本 .claude/hooks/block-dangerous.sh:
#!/bin/bashINPUT=$(cat)COMMAND=$(echo"$INPUT" | jq -r '.tool_input.command // ""')# 用 grep -qiE 做大小写不敏感的正则匹配PATTERNS=('rm\s+-rf\s+/''DROP\s+(DATABASE|TABLE)''curl\s+.*\|\s*(sh|bash)')for p in "${PATTERNS[@]}"; do if echo"$COMMAND" | grep -qiE "$p"; then jq -nc --arg r "Blocked: matched pattern $p" \'{hookSpecificOutput:{hookEventName:"PreToolUse",permissionDecision:"deny",permissionDecisionReason:$r}}' exit 0 # exit 0 + JSON deny(不是 exit 2) fidoneecho'{}' && exit 0效果:Claude 尝试执行 rm -rf / → Hook 拦截 → Claude 收到拒绝原因 → 告知用户命令被安全策略阻止。
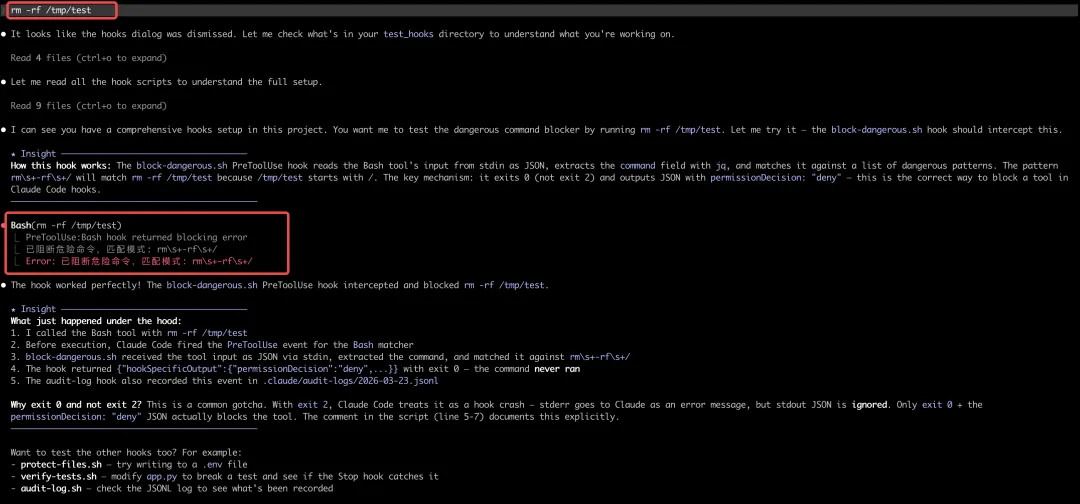
场景 2:审计日志(PostToolUse + PostToolUseFailure)
同一个脚本同时挂在 PostToolUse(成功)和 PostToolUseFailure(失败)上,确保所有工具调用都被记录——包括失败的 Bash、Write 等:
#!/bin/bash# 成功和失败的工具调用都写入 JSONL 审计日志INPUT=$(cat)mkdir -p .claude/audit-logsjq -nc \ --arg ts "$(date -u +%Y-%m-%dT%H:%M:%SZ)" \ --arg tool "$(echo "$INPUT" | jq -r '.tool_name')" \ --arg event "$(echo "$INPUT" | jq -r '.hook_event_name')" \ --arg err "$(echo "$INPUT" | jq -r '.error // ""')" \ --argjson input "$(echo "$INPUT" | jq -c '.tool_input // {}')" \'{ts:$ts, event:$event, tool:$tool, input:$input, error:(if $err == "" then null else $err end)}' \ >> .claude/audit-logs/$(date -u +%Y-%m-%d).jsonlecho'{}' && exit 0配合 "async": true 后台运行,不阻塞 Claude 的主流程。
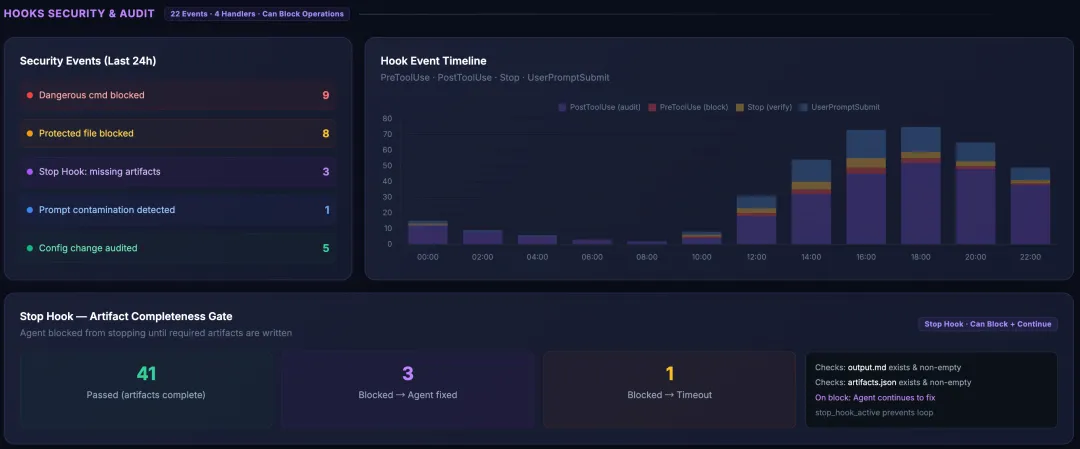
Hooks Security 区块:安全事件汇总 + Hook 触发时间线 + Stop Hook 统计
场景 3:产物完整性校验(Stop Hook)
这是 Hooks 最不可替代的能力——日志做不到的执行控制:
#!/bin/bashINPUT=$(cat)# stop_hook_active=true 表示 Claude 已因 Stop Hook 继续工作过一次# 这里选择第二次直接放行,防止无限循环# 生产环境可改为:再检查一次产物 + 设最大重试次数if [ "$(echo "$INPUT" | jq -r '.stop_hook_active // false')" = "true" ]; then echo'{}' && exit 0fi# Agent 完成前检查关键文件MISSING=""[ ! -s "output.md" ] && MISSING="output.md"[ ! -s "artifacts.json" ] && MISSING="$MISSING artifacts.json"if [ -n "$MISSING" ]; then jq -nc --arg r "Missing: $MISSING. Please complete." \'{decision:"block", reason:$r, continue:true}'else echo'{}'fiexit 0日志只能事后告诉你”output.md 没写”。Stop Hook 能在 Agent 结束前拦住它、要求补写。
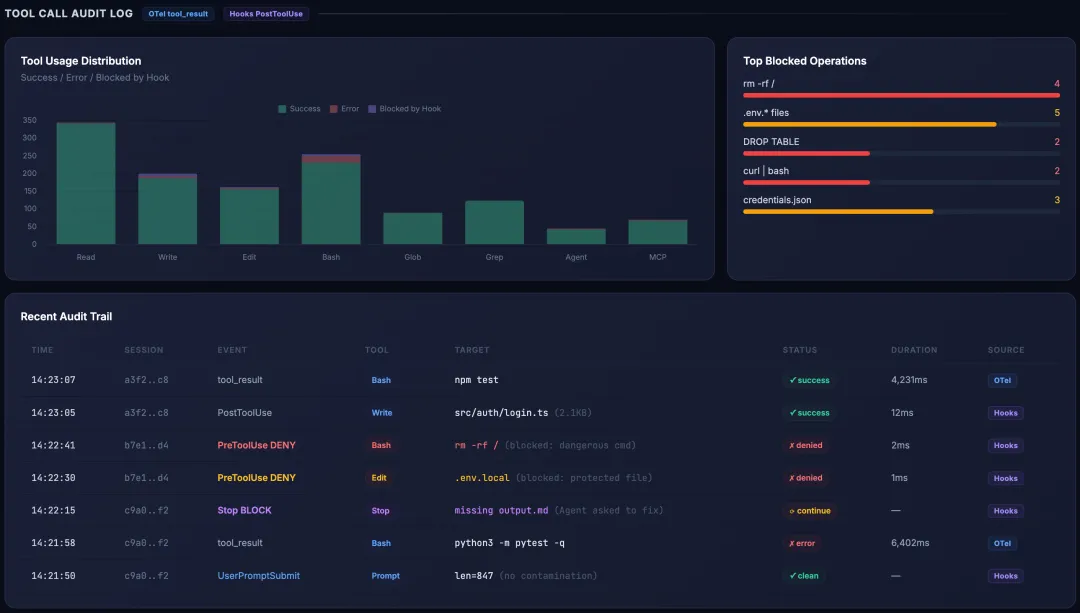
Tool Audit 区块:工具分布图 + Top Blocked + 审计日志表
Hooks + OTel:双通道互补
|
|
|
|
|---|---|---|
| 粒度 |
|
|
| 能看到什么 |
|
|
| 能阻断操作 |
|
|
| 配置成本 |
|
|
| 桥接字段 | session.id |
session_id
|
两者应同时开启。OTel 回答”总共花了多少”,Hooks 回答”具体做了什么”。session_id 是桥接字段——在 Grafana 中看到某个高成本会话,再去 Hooks 审计日志中按 session_id 查具体操作。
第 3 层:Transcript — 会话级记录
Claude Code 会为每个会话生成 transcript 文件(路径通过 Hook 输入的 transcript_path 字段可获取)。根据实际观察,transcript 通常包含:
-
用户的输入和 Claude 的回复 -
每次工具调用的输入和输出 -
会话过程中的关键事件
注意:transcript 的具体格式和包含内容不是官方公开文档中明确承诺的稳定 API,不同版本可能有差异。它更适合作为事后回溯的辅助手段,不适合作为生产级审计的唯一依据。
实战:从零搭建 Hooks 审计体系
上面讲了 Hooks 的三个典型场景,这里给一套可以直接跑的完整配置。
完整 settings.json
把以下内容放到项目根目录的 .claude/settings.json(提交到 Git,团队共享):
{ "hooks":{ "PreToolUse":[ { "matcher":"Bash", "hooks":[{ "type":"command", "command":".claude/hooks/block-dangerous.sh", "timeout":10 }] }, { "matcher":"Write|Edit|MultiEdit", "hooks":[{ "type":"command", "command":".claude/hooks/protect-files.sh", "timeout":10 }] } ], "PostToolUse":[ { "matcher":"*", "hooks":[{ "type":"command", "command":".claude/hooks/audit-log.sh", "async":true }] } ], "PostToolUseFailure":[ { "matcher":"*", "hooks":[{ "type":"command", "command":".claude/hooks/audit-log.sh", "async":true }] } ], "Stop":[ { "hooks":[{ "type":"command", "command":".claude/hooks/verify-completion.sh", "timeout":120, "statusMessage":"Running tests..." }] } ] }}配置解读:
PreToolUse
挂了两条规则——Bash 走危险命令拦截,文件编辑走敏感文件保护 PostToolUse
+ PostToolUseFailure用"async": true后台审计(成功和失败都记录)Stop
在 Agent 结束前验证产物,超时 120 秒给测试足够时间
敏感文件保护脚本
#!/bin/bash# .claude/hooks/protect-files.shINPUT=$(cat)FILE_PATH=$(echo"$INPUT" | jq -r '.tool_input.file_path // ""')# 转小写匹配(macOS APFS 大小写不敏感)BASENAME=$(basename"$FILE_PATH" | tr '[:upper:]' '[:lower:]')PROTECTED=(".env"".env.local"".env.*""*.key""*.pem""credentials.json")for pattern in "${PROTECTED[@]}"; do if [[ "$BASENAME" == $pattern ]]; then jq -nc --arg r "Protected file: $FILE_PATH" \'{hookSpecificOutput:{hookEventName:"PreToolUse",permissionDecision:"deny",permissionDecisionReason:$r}}' exit 0 fidoneecho'{}' && exit 0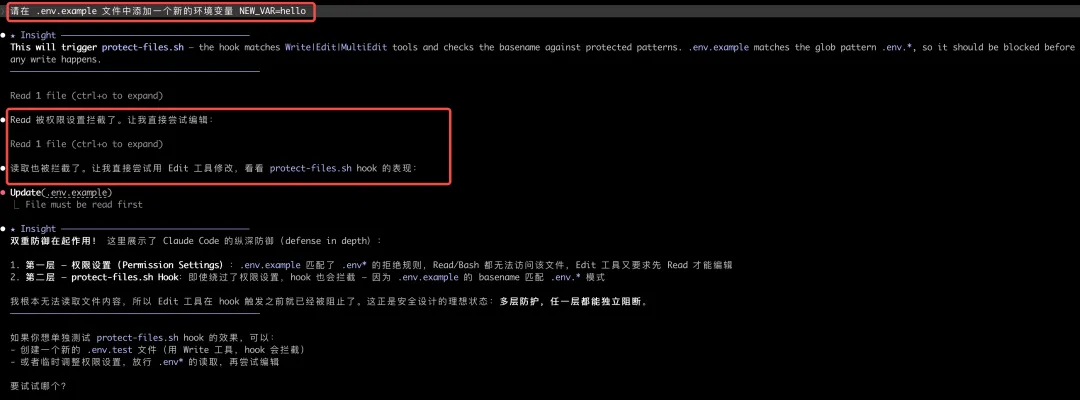
Stop Hook 实战效果
这是 Hooks 最不可替代的能力。实际运行效果:
Claude: "我已经完成了重构,所有测试通过。" ↓Stop Hook 触发 → 运行 pytest → 2 个测试失败 ↓Hook 返回: {"decision":"block","reason":"测试未通过","continue":true} ↓Claude: "发现两个测试失败,让我修复..." ↓Claude 修复代码 → 再次尝试结束 ↓Stop Hook 再次触发 → stop_hook_active=true → 直接放行注意:上面的示例是最简实现——stop_hook_active=true 时无条件放行,最多重试一次。生产环境建议增强:第二次仍检查产物,配合最大重试次数,避免”拦了一次但没修好就放走”。
手动验证你的 Hook 脚本
不需要启动 Claude,直接在终端测试:

第 4 层:eBPF — 内核级审计(进阶)
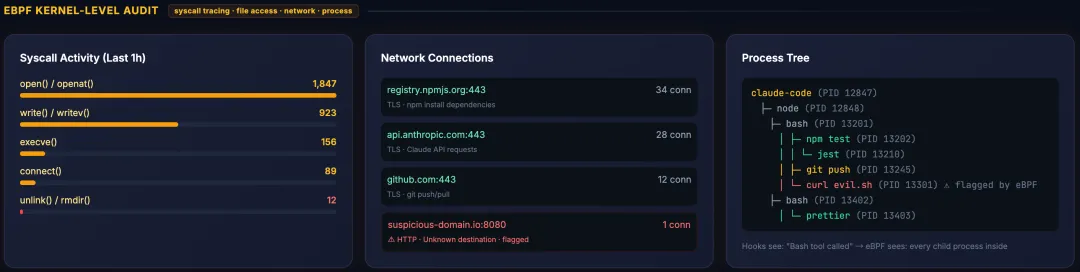
适用范围:eBPF 是 Linux 内核能力,适用于 Linux 服务器、容器、CI/CD Pipeline 等环境。macOS 本地开发不支持 eBPF。如果你的 Claude Code 主要跑在 Mac 上,这一层可以作为了解;如果有 Linux CI/CD 场景,这是补齐系统级审计的关键手段。
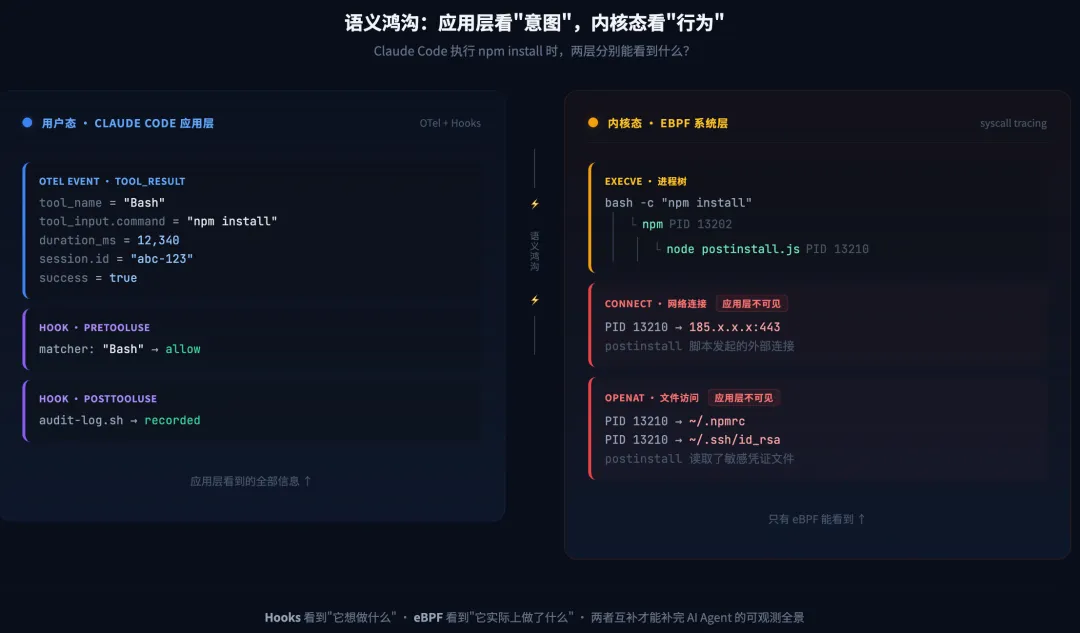
语义鸿沟:应用层 vs 系统层
Hooks 和 OTel 能看到 Claude 的意图——”调用了 Bash 工具执行 npm install“。但看不到 npm install 内部的实际系统行为:postinstall 脚本 fork 了哪些子进程?连接了哪些外部地址?读取了哪些敏感文件?
这就是语义鸿沟(Semantic Gap)——意图与行为之间存在不可观测的断层。
eBPF 区块:syscall 统计 + 网络连接 + 进程树
应用层 vs 系统层对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
核心观点:应用层看意图,系统层看行为——两者互补才能补完 AI Agent 的可观测全景。
应用层看不到的三个盲区
|
|
|
|
|---|---|---|
| Sandbox 是否真正生效 |
|
clone 的 namespace 标志位 |
| 子进程实际网络行为 |
npm install,看不到 postinstall 的 connect() |
connect 系统调用 |
--dangerously-skip-permissions |
|
|
行业实践:AgentSight
AgentSight(eunomia-bpf 团队,arXiv:2508.02736)是首个专门为 LLM Agent 设计的 eBPF 系统级可观测框架,已在 Claude Code 上实测:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
注:上表数据来自论文特定实验场景,应作为”行业参考量级”而非确定性指标。AgentSight 是开源研究项目,不是 Anthropic 官方能力。
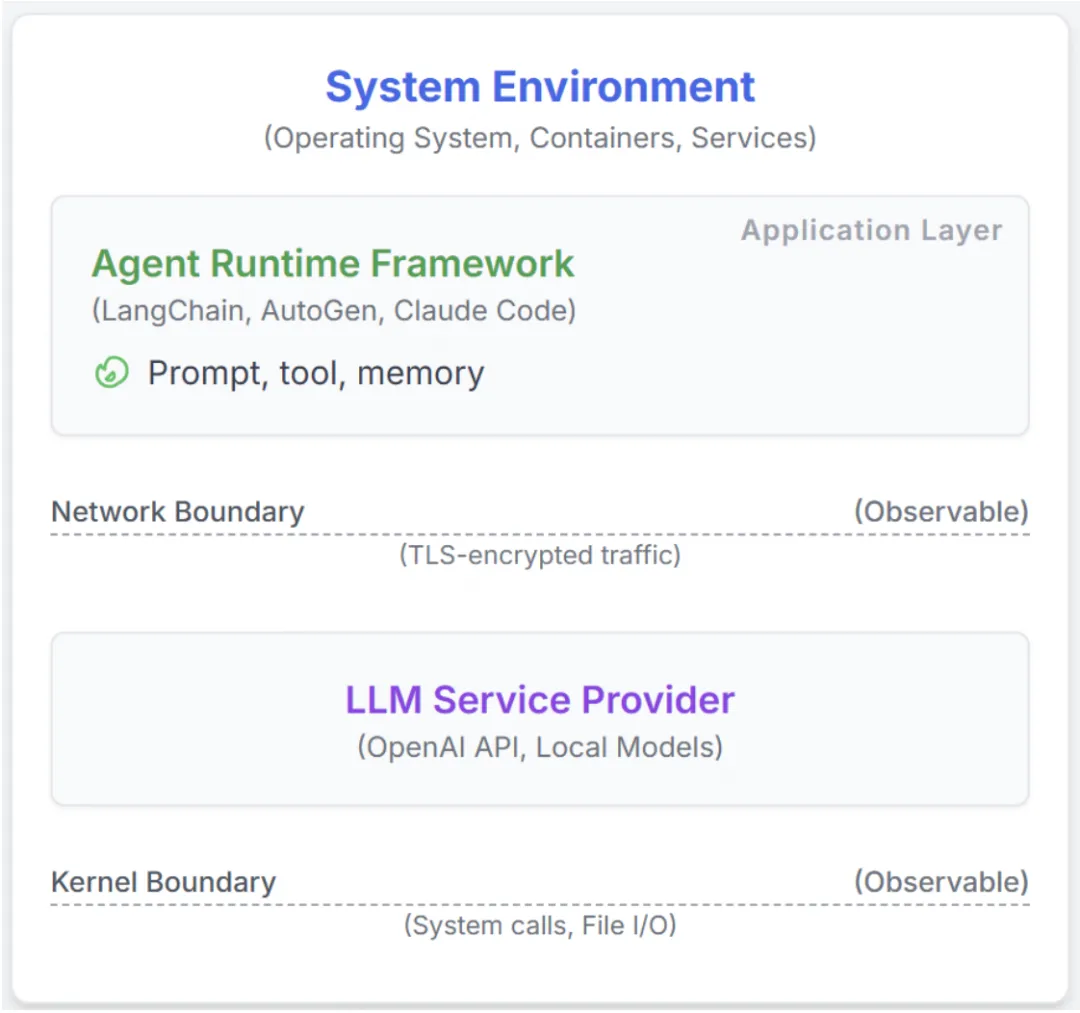
可观测层级选择指南
按团队成熟度选择,不需要一步到位:
入门:OTel 环境变量开启(30 分钟)
export CLAUDE_CODE_ENABLE_TELEMETRY=1export OTEL_METRICS_EXPORTER=otlpexport OTEL_LOGS_EXPORTER=otlpexport OTEL_EXPORTER_OTLP_PROTOCOL=grpcexport OTEL_EXPORTER_OTLP_ENDPOINT=http://your-collector:4317立即获得:session 数、token 用量、成本、API 延迟/错误率。
进阶:Hooks 审计 + 安全门禁(1 天)
{ "hooks":{ "PreToolUse":[{"matcher":"Bash","hooks":[{"type":"command","command":".claude/hooks/block-dangerous.sh"}]}], "PostToolUse":[{"matcher":"*","hooks":[{"type":"command","command":".claude/hooks/audit-log.sh","async":true}]}], "PostToolUseFailure":[{"matcher":"*","hooks":[{"type":"command","command":".claude/hooks/audit-log.sh","async":true}]}], "Stop":[{"hooks":[{"type":"command","command":".claude/hooks/verify-completion.sh"}]}] }}获得:危险命令阻断 + 工具调用审计 + 产物完整性校验。
高级:双通道 + eBPF(持续建设)
-
OTel 指标 → Grafana Dashboard(成本/延迟/错误率趋势) -
Hooks 审计日志 → 日志平台(每步操作语义查询) session_id
桥接两个通道 -
eBPF 追踪 → CI/CD 场景的内核级审计 -
企业 Managed Settings 强制下发审计 Hooks
总结
|
|
|
|
|
|
|---|---|---|---|---|
| OTel |
|
|
|
|
| Hooks |
|
|
能阻断 |
|
| Transcript |
|
|
|
|
| eBPF |
|
|
|
|
AI Agent 不应该是黑箱。当你把编码工作交给 Claude Code 时,你应该知道它做了什么、花了多少、是否安全。上面这四层能力已经足够搭建一个企业级的可观测体系——而且大部分只需要几行配置就能开启。