 夜雨聆风
夜雨聆风





DeepSeek-OCR解析PDF文件
目标:将PDF文件转成可编辑的MD文件
实现思路:先将整体的PDF文件按照页码分割成一个个图片,然后调用DeepSeek-OCR解析图片,将解析的内容存储成MD格式。
只保留核心代码,不包含提升美观和兼容性的代码,不然很不适合初学者。如果不想看过程,可以直接跳至文末,获取代码
使用工具:Python3.13,使用到的库
import osimport requestsimport base64import fitz#如果没有这个库,安装的时候是安装pymupdfimport re
DeepSeek-OCR使用硅基流动的,目前免费,速度也快,如果没有硅基流动的密钥,需要先申请一个。
代码实现
import os#负责打开或者删除文件import requests#调用大模型import base64#将图片转成字符串,方便传输import fitz#将PDF分割成图片import re#提取内容def pdf_to_image(pdf_path, total_pages):"""用PyMuPDF将PDF转为图片"""doc = fitz.open(pdf_path)for page_num in range(total_pages):page = doc[page_num]pix = page.get_pixmap(dpi=300)# 渲染图片(dpi=300保证清晰度)temp_img = f"temp_{page_num}.png"pix.save(temp_img)doc.close()def ocr_image_to_md(image_path):"""单张图片调用DeepSeek-OCR转MD"""#将图片转成字符串with open(image_path, "rb") as f:b64 = base64.b64encode(f.read()).decode("utf-8")#调用DeepSeek-OCRresp = requests.post("https://api.siliconflow.cn/v1/chat/completions",headers={"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"},json={"model": "deepseek-ai/DeepSeek-OCR","messages": [{"role": "user", "content": [{"type": "text", "text": "解析内容为markdown格式,原版输出"},{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{b64}"}}]}],"temperature": 0.0,"max_tokens": 4092,"stream": False # 显式关闭流式输出},timeout=60)#提取转化内容raw_content=resp.json()["choices"][0]["message"]["content"]#提取的内容有“}^tokens”这个字符串,不知道为什么,为了内容的干净,把这个字符剔掉clean_text = re.sub(r"\}\^tokens\s*", '', raw_content).strip()return clean_text# 核心流程:PDF转图片(无poppler)→ 逐页OCR → 合并MDif __name__ == "__main__":# 核心配置(替换为你的信息)API_KEY = "sk-替换为你自己的密钥"PDF_PATH = r"D:\测试.pdf" # 待解析PDFOUTPUT_MD = "output.md" # 输出MD文件#获取PDF总页数doc = fitz.open(PDF_PATH)total_pages = len(doc)doc.close()pdf_to_image(PDF_PATH, total_pages)print("完成PDF转图片")# 2. 逐页解析md_content = ''for page_idx in range(total_pages):# 转图片(无poppler)img_path = f"temp_{page_idx}.png"# 调用OCRpage_md = ocr_image_to_md(img_path)md_content +='\n' + page_mdprint(f"解析完第{page_idx+1}页")# 删除临时图片os.remove(img_path)# 3. 保存结果,MD文件存在这个py文件的位置with open(OUTPUT_MD, "w", encoding="utf-8") as f:f.write(md_content)print(f"解析完成!结果已保存至 {OUTPUT_MD}")
实现效果
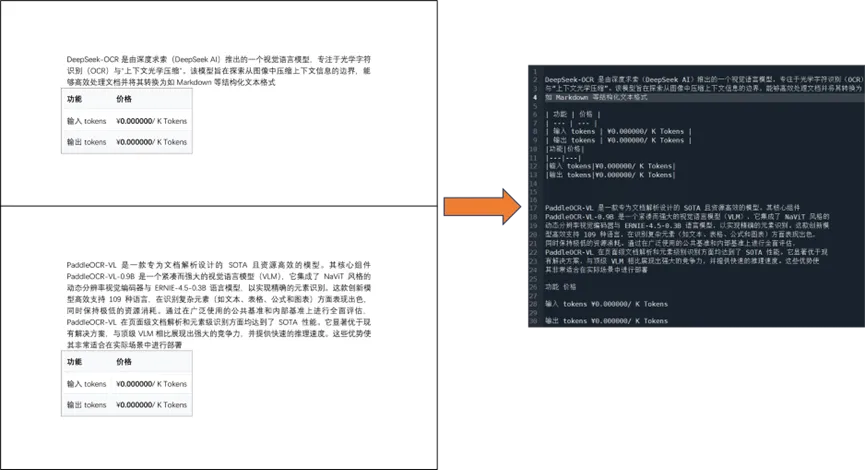
写在最后
我以为这是一个很简单的活,但是AI给的代码总是很冗长,写了很多兼容性的代码,而且也不能直接用,需要一遍遍的改,实现思路也不清晰。写下这篇文章,希望可以让初学者少走一些坑。