 夜雨聆风
夜雨聆风





Kafka副本同步机制深度剖析:源码级解密数据一致性保障

在分布式系统中,数据一致性是永恒的话题。作为高性能消息队列的代表,Kafka通过副本机制保障数据可靠性,但很多开发者对其副本同步的核心原理一知半解。本文将深入Kafka源码,从Leader与Follower的交互流程、日志复制确认机制等方面,全方位解析副本同步的实现细节,帮助你彻底理解Kafka如何在高吞吐下保证数据零丢失。
一、Kafka副本同步的基本概念
Kafka的副本机制是实现数据高可用性的核心,每个主题分区可以配置多个副本,其中一个作为Leader副本负责处理读写请求,其他为Follower副本仅负责从Leader同步数据。当Leader故障时,Kafka会从ISR(In-Sync Replicas)列表中选举新的Leader,确保数据不丢失。
ISR列表包含所有与Leader保持同步的副本,Follower必须在指定时间内(replica.lag.time.max.ms)向Leader发送心跳请求并同步日志,否则会被移出ISR。这种动态调整机制平衡了数据一致性和系统可用性。
二、副本同步核心流程源码分析
Kafka副本同步的核心流程分为生产请求处理、日志复制、ACK确认和HW更新四个阶段。我们从Kafka 2.8版本的ReplicaManager和FollowerFetchRequestHandler类入手,深入解析每个阶段的实现逻辑。
1. 生产请求处理
当Producer发送消息到Leader时,Leader首先验证请求合法性,然后将消息写入本地日志。核心代码如下:
// Leader处理生产请求核心逻辑
public AppendRecordsResponse appendMessages(AppendRecordsRequest request) {
// 1. 验证请求参数和权限
validateRequest(request);
// 2. 获取目标分区的日志实例
Log log = logManager.getLog(request.topicPartition());
// 3. 写入消息到本地日志
LogAppendInfo appendInfo = log.append(request.records(), request.isFromClient());
// 4. 记录日志偏移量
long baseOffset = appendInfo.firstOffset();
// 5. 处理Follower副本同步
handleFollowerSync(request, appendInfo);
// 6. 等待ISR副本确认
if (request.requiredAcks() != Acks.NONE) {
waitForReplicaAcks(request.topicPartition(), baseOffset, request.requiredAcks());
}
// 7. 更新High Watermark
updateHighWatermark(request.topicPartition());
// 8. 返回响应给Producer
return new AppendRecordsResponse(baseOffset);
}
2. 日志复制机制
Follower通过定期发送FetchRequest从Leader拉取最新日志。Leader在处理FetchRequest时,会将本地日志中Follower缺失的部分返回给Follower。核心代码如下:
// Follower拉取日志核心逻辑
public FetchResponse fetchMessages(FetchRequest request) {
// 1. 获取请求的分区和偏移量
TopicPartition partition = request.topicPartition();
long fetchOffset = request.fetchOffset();
// 2. 获取Leader端的日志实例
Log log = logManager.getLog(partition);
// 3. 检查偏移量合法性
if (!log.isValidOffset(fetchOffset)) {
return new FetchResponse(Errors.OFFSET_OUT_OF_RANGE);
}
// 4. 读取从fetchOffset开始的日志片段
LogSegment segment = log.read(fetchOffset, request.maxBytes());
// 5. 返回日志片段给Follower
return new FetchResponse(segment.records(), log.highWatermark());
}
3. ACK确认与ISR管理
当Follower成功同步日志后,会向Leader发送ACK确认。Leader维护每个Follower的同步状态,当Follower的LEO(Log End Offset)追上Leader时,将其加入ISR列表;如果Follower长时间未同步,则移出ISR。核心代码如下:
// 处理Follower ACK确认
public void handleFollowerAck(TopicPartition partition, long followerOffset, String brokerId) {
// 1. 更新Follower的LEO
updateFollowerLEO(partition, brokerId, followerOffset);
// 2. 检查是否需要将Follower加入ISR
if (shouldAddToISR(partition, brokerId)) {
addReplicaToISR(partition, brokerId);
}
// 3. 检查是否需要将Follower移出ISR
if (shouldRemoveFromISR(partition, brokerId)) {
removeReplicaFromISR(partition, brokerId);
}
// 4. 触发HW更新
maybeUpdateHighWatermark(partition);
}
三、副本同步UML流程图解读
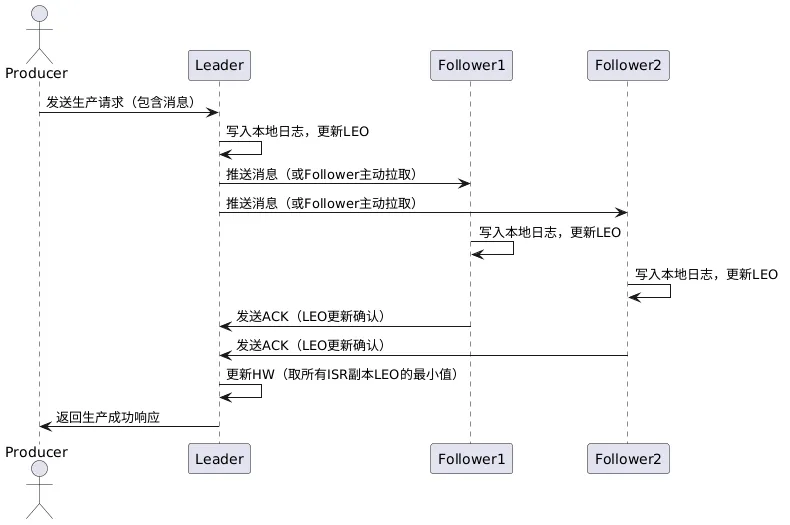
上图完整展示了Kafka副本同步的核心流程:
1. Producer发送生产请求到Leader副本
2. Leader验证请求并写入本地日志
3. Follower定期发送FetchRequest拉取日志
4. Leader返回缺失的日志片段给Follower
5. Follower写入日志并更新LEO
6. Follower发送ACK确认给Leader
7. Leader更新ISR列表和HW
8. Leader返回生产成功响应给Producer
四、常见问题与优化建议
1. 副本同步延迟排查
当出现副本同步延迟时,可以通过以下方式排查:
– 监控kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions指标
– 查看replica.lag.time.max.ms和replica.fetch.max.bytes配置
– 检查网络带宽和磁盘IO性能
2. 性能优化策略
- 合理设置
min.insync.replicas参数,平衡一致性和可用性 - 调整
replica.fetch.wait.max.ms减少Follower拉取延迟 - 开启
unclean.leader.election.enable(谨慎使用)允许非ISR副本成为Leader - 增加Follower副本数量提升系统容错能力
本文深入剖析了Kafka副本同步机制的源码实现,从生产请求处理到日志复制确认,全方位解析了数据一致性的保障原理。掌握这些核心知识,能帮助你在生产环境中更好地配置和优化Kafka集群。有任何疑问或实战经验,欢迎在评论区留言交流,咱们一起进步!