夜雨聆风
夜雨聆风





Claude Code源码泄露:媒体没说清楚的那件事,才是真正危险的
这次源码泄露事件对 Anthropic 的实际伤害,没有媒体宣扬的那么大,因为核心的模型权重并未泄露,这才是 Anthropic 的最核心的竞争力;
但暴露出来的问题,比官方”人为失误”四个字交代的要值得深思,这个是一个顶级的 AI 公司工程/流程上的失误,也说明了一个核心问题:对于任何系统工程来讲,没有完美的系统,而人总会容易犯错。
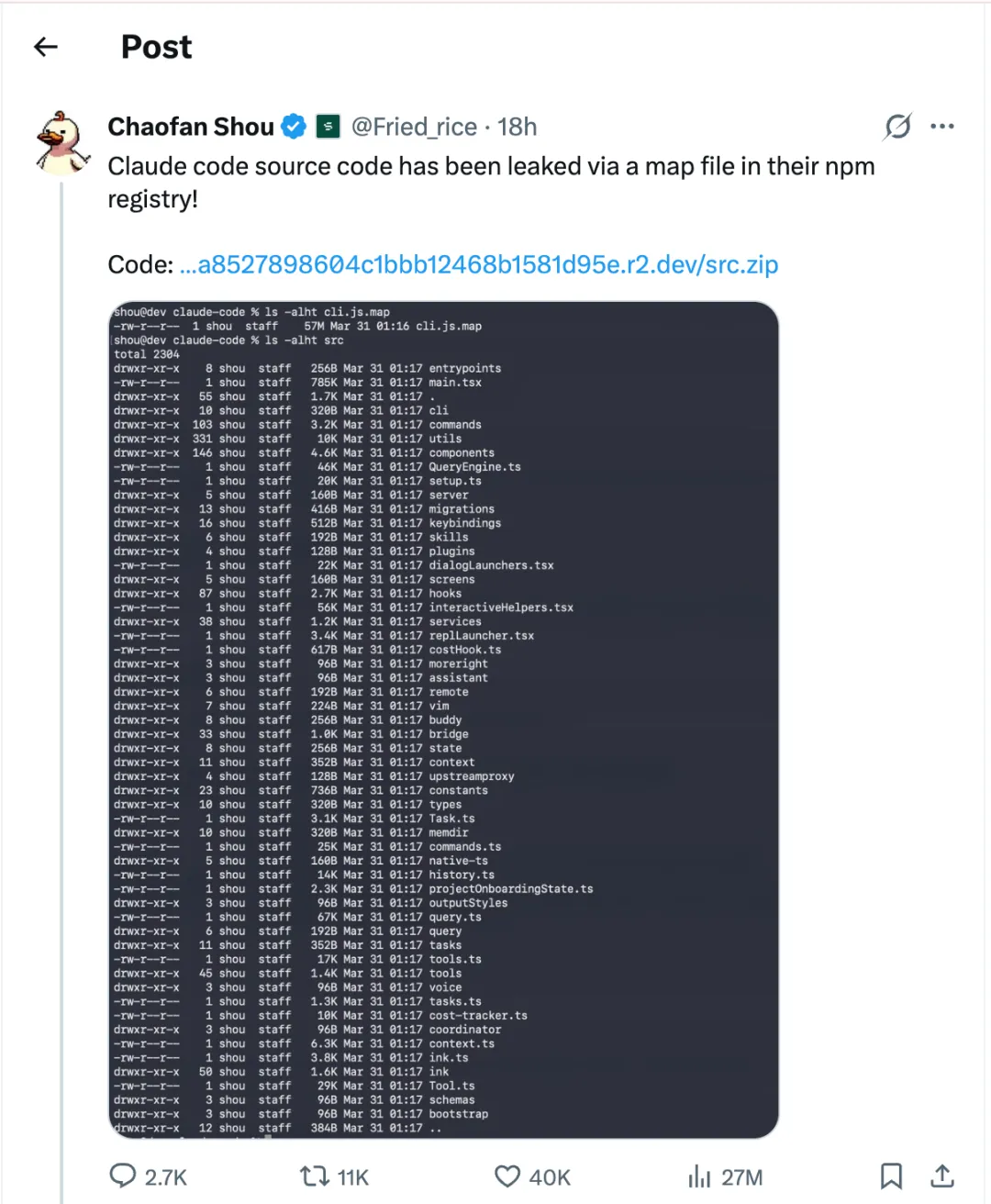
这次的泄露事件泄露了什么,没泄露什么?
泄露的是 Claude Code 的工程实现:工具调用架构和流程、prompt 拼接策略、上下文压缩的逻辑和方案,还有个可能是更重要的泄露——Anthropic 的产品路线图。
没泄露的是 Claude 的模型权重。
做过 AI 基础设施的人都清楚这个区别:Claude Code 的竞争力来自 Claude 模型本身的能力,不是那 40 个工具的实现方式。任何团队拿着这 51 万行代码,可能可以复刻 Claude Code 这个命令行工具,但是照样造不出 Claude 模型。
但有对于产品路线图的泄露是对于这个公司商业化上的一个更大的挑战。代码里出现了内部代号 Capybara(定位在 Opus 之上的下一代旗舰模型)、Capybara-v2-fast 支持 1M 上下文,还有一个叫 Numbat 的未知模型。竞争对手现在知道 Anthropic 下一步要打什么牌了,这才是真正敏感的信息,就是告诉别人我接下来要做什么。
这次泄露还有什么值得重点关注的?
有人读了源码后发现了一个细节:Claude Code 内部有一套叫 ABLATION_BASELINE 的机制,可以一键关掉思维链、上下文压缩、自动记忆等核心功能,专门用来跑消融实验——也就是逐个关掉功能,量化每个组件对最终效果的实际贡献。
把科研里的消融实验方法论搬进工程代码,我做了这么多年产品,在工业代码里还是很少见。这意味着 Anthropic 每上线一个功能,背后都有对照组做数据支撑,依赖数据进行决策,这是典型的逻辑思维、系统思维指导下搭建出来的系统,这套系统不是”感觉有用就上”,而是基于数据的指标做决策。
这种工程文化和严谨性可能也是 Anthropic 从默默无闻到现在成为 Code 领域、企业领域 AI 霸主的关键。
但同一份代码也暴露了 Anthropic 系统工程的另一面:64000 多行生产代码,零测试覆盖。
安全是乘法,不是加法。99 个环节做对,1 个漏了,等于 0。
对开发者的实际风险:有一件事被混淆了
Source map 泄露源代码本身对使用者几乎没有直接风险:Anthropic 已确认无用户数据、无 API 密钥泄露,所以没有任何用户的隐私被泄露,也没有任何直接的安全风险。
但同一天还有一件独立事件被混入报道:npm 的 axios 包被注入了远控木马。如果你在北京时间 3 月 31 日上午 8 点到 11 点半之间通过 npm 更新过 Claude Code,需要检查 lockfile 里有没有 axios 1.14.1 或 0.30.4 版本。两件事时间窗口重叠,很多人没分清哪个才是真正危险的。
总结下来,这个泄露对于 Anthropic 最大的影响第一是产品路线图的泄露,会让竞争对手知道他们的底牌,进而考虑对应的应对策略;第二个是 Claude Code 本身源码的泄露可能对 Cursor 等工具也有不小的影响,因为后来者可以基于这份源码在大幅降低试错成本的基础上打造另外一个 Code Agent;而这个事件背后反映出的 Anthropic 的严谨性和代码安全方面的人为错误的不可避免性,也是每个计算机开发相关的人需要重点借鉴和学习的。