 夜雨聆风
夜雨聆风





Claude Code源码大揭秘:6大工程杀手锏,碾压Cursor的秘密武器全曝光
51 万行代码意外泄露,Sebastian Raschka 深度拆解:不靠模型靠工程,这才是 AI 编程工具的真正护城河
一、史上最戏剧性的“意外开源”
2026 年 3 月 31 日凌晨,一条推文在硅谷引爆了一场前所未有的技术地震。
区块链安全公司 Fuzzland 的实习研究员 Chaofan Shou 在 X 平台上发布了一条简短却震撼的消息:“Claude Code 源码通过 npm 注册表中的 map 文件泄露了!”短短几小时内,这条推文获得了超过 2200 万次浏览。
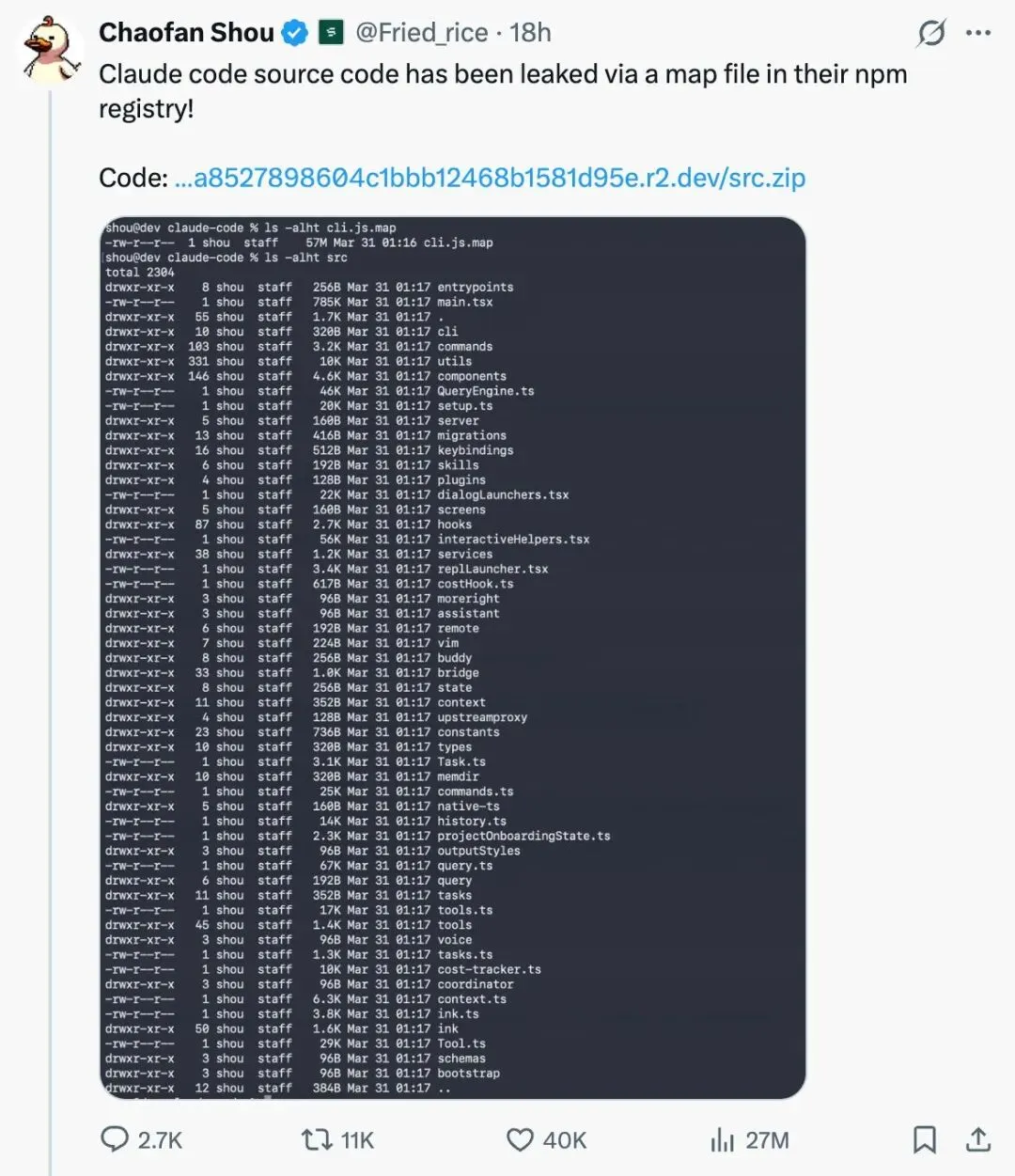
这不是一次黑客攻击,而是 Anthropic 自己犯下的一个低级错误。在发布 Claude Code v2.1.88 版本时,一个 59.8MB 的源码地图文件(cli.js.map)被意外打包进了 npm 发布包中。这个本应仅用于内部调试的文件,包含了指向 Anthropic Cloudflare R2 存储桶的完整引用——任何人都可以无需认证直接下载。
解压后的内容令人震惊:1,900 个 TypeScript 源文件,总计 512,000 行代码,涵盖了 Claude Code CLI 工具的完整实现——从内部 API 设计、分析遥测系统、加密工具,到进程间通信协议的每一个细节。
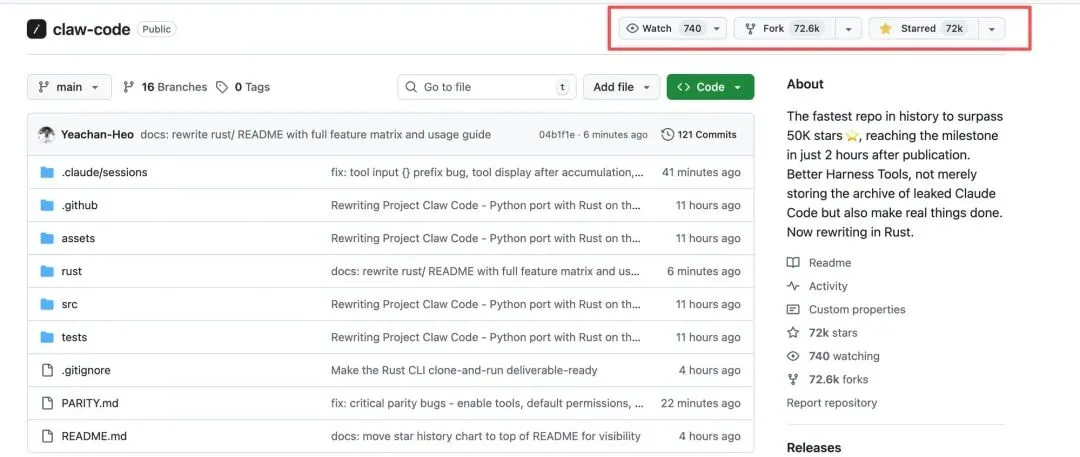
更戏剧性的是 GitHub 上的连锁反应。开发者 instructkr 创建的备份仓库在短短 2 小时内就突破了 50,000 颗星,成为 GitHub 历史上增长最快的项目之一。更离谱的是,Fork 数(超过 60,000)竟然碾压了 Star 数——这意味着开发者们不只是围观,而是在疯狂“搬运”代码,确保这些源码永远无法被收回。
Anthropic 迅速做出反应,通过 DMCA 版权投诉试图封杀所有分享源码的链接。但这场封杀注定失败——因为泄露发生的那一刻,代码就已经在全球数万台电脑上扎根。用一位开发者的话说:“这种事一旦泄出去,就收不回来了。”
但这场泄露风暴的真正价值,不在于 Anthropic 的尴尬,而在于我们终于有机会看清:为什么 Claude Code 能在 AI 编程工具的激烈竞争中脱颖而出?为什么它的用户体验能明显优于网页版 Claude,甚至让 Cursor、GitHub Copilot 等竞品感到压力?
答案藏在这 51 万行代码里。而 AI 领域的知名专家 Sebastian Raschka 已经为我们做了深度拆解。
二、泄露真相:一个三周前就该修的 Bug
在深入技术细节之前,我们需要理解:这次泄露到底是怎么发生的?
Source map(源码地图)是 JavaScript 开发中的标准调试工具,它的作用是将压缩、混淆后的生产代码映射回原始的可读源代码,方便开发者定位问题。但这个文件绝对不应该出现在面向用户的生产发布包中——它就像是把建筑的完整施工图纸交给了所有住户。
更尴尬的是,这已经是 Anthropic 第二次犯同样的错误。2025 年 2 月,Claude Code 早期版本就曾因同一问题被曝光,当时 Anthropic 紧急从 npm 移除了旧版本并删除了 source map。但仅仅一年后,最新版 v2.1.88 又重蹈覆辙。
问题的根源可能指向一个更深层的技术债务。Claude Code 是基于 Bun 运行时构建的——而 Anthropic 在 2024 年底刚刚收购了 Bun。根据多位开发者的分析,Bun 的打包工具默认会生成 source map,除非显式关闭。更关键的是,GitHub 上早在 3 周前(3 月 11 日)就有开发者报告了 Bun 的一个 bug(issue #28001):source map 在生产模式下仍然会被暴露,尽管官方文档声称应该禁用。
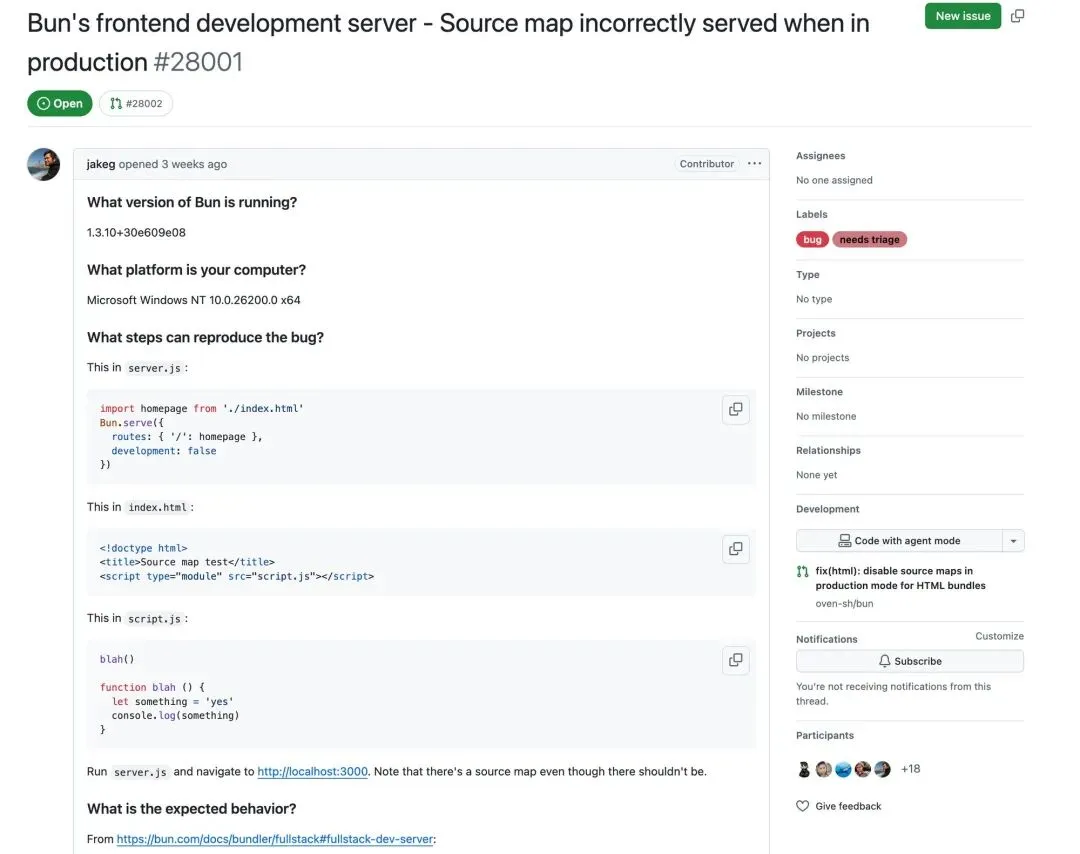
这个 bug 报告至今未被修复,而 Claude Code 恰恰踩中了这个坑。
Anthropic 在事后发布的声明中承认:“今天早些时候,Claude Code 的一个发布版本包含了部分内部源代码。这是由人为失误导致的发布打包问题,而非安全漏洞。没有敏感的客户数据或凭证被泄露。”
但对于一家估值 190 亿美元、年化收入达到 190 亿美元的 AI 巨头来说,连续两次在同一个地方摔倒,确实让人对其工程流程管理产生疑问。软件工程师 Gabriel Anhaia 在深度分析中指出:“这应该提醒所有开发者检查自己的构建流水线。一个配置错误的.npmignore 或 package.json 中的 files 字段,就可能暴露一切。”
更具戏剧性的是社区的反应。韩国开发者 Sigrid Jin——就是那位因一年消耗 250 亿 Claude Token 而登上《华尔街日报》的极客——在凌晨 4 点被手机消息炸醒。他的女友甚至担心他会因为电脑里存有这些代码而被 Anthropic 起诉。
于是,在凌晨 4 点的微光中,Sigrid Jin 启动了一个名为“oh-my-codex”的 AI 辅助工作流,用 Claude 自己的能力,在天亮之前将整个 TypeScript 代码库重写成了 Python 版本。这个名为“claw-code”的 clean-room 重写项目,完美复刻了 Claude Code 的架构模式,但不包含任何一行原有的 TypeScript 代码——从法律角度规避了版权风险。几小时后,他又推出了 Rust 版本。
这场凌晨代码大逃亡,成为了这次泄露事件中最具传奇色彩的一幕。而 Anthropic 的 DMCA 封杀,在 clean-room 重写面前彻底失效。
三、核心揭秘:6 大技术杀手锏深度拆解
泄露的代码迅速引起了 AI 社区的集体拆解。其中最有价值的分析来自威斯康星大学麦迪逊分校的 AI 研究员、《Build a Large Language Model (From Scratch)》作者 Sebastian Raschka。
他在深度研究源码后得出了一个颠覆性的结论:“Claude Code 的强大不在模型本身,而在这套精心设计的‘软件外壳’。如果把开源模型塞进同样的框架里,稍加适配,编程表现也会非常强。”
以下是 Raschka 总结的 6 个关键技术优势,这些才是 Claude Code 真正的护城河:
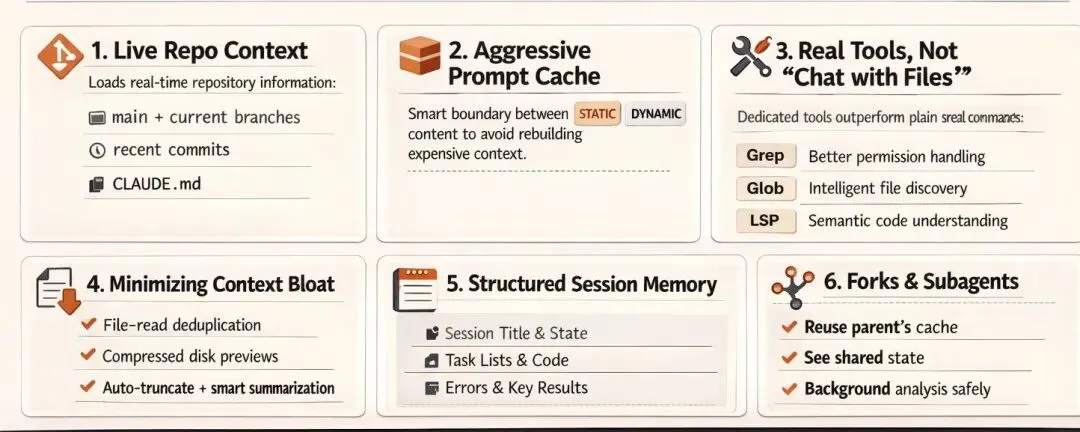
杀手锏 1:实时仓库上下文加载
痛点在哪? 当你在网页版 Claude 中上传代码文件时,AI 看到的只是一堆静态文本。它不知道这些文件之间的关系,不了解项目的 Git 历史,更不清楚你当前在哪个分支上工作。这就像让一个侦探破案,但只给他看现场照片,不告诉他案件的前因后果。
Claude Code 怎么做? 在启动时,它会自动执行一系列操作:读取主分支状态、识别当前工作分支、分析最近的提交记录、解析项目根目录下的 CLAUDE.md 配置文件(如果存在)。这些信息被整合成一个动态的“项目全景图”,让 AI 理解代码不仅仅是文本,而是一个有演进历史、有开发意图的活体项目。
实际效果: 当你让 Claude Code 修复一个 bug 时,它能追溯这段代码是什么时候引入的、为什么这样写、相关的其他文件有哪些改动。这种“历史感知”能力,是网页版根本做不到的。
开发者启示: 上下文不是越多越好,而是要“结构化+动态化”。盲目塞入大量代码反而会稀释关键信息。
杀手锏 2:激进的 Prompt 缓存复用
这是一个听起来简单、但实现起来极其精妙的优化策略。
核心机制: Claude Code 的系统提示词(system prompt)被一个特殊的边界标记拆分成两部分:静态部分和动态部分。静态部分包含了工具定义、行为规范、通用指令等不会频繁变化的内容,这部分会被全局缓存;动态部分则包含当前会话的特定信息,每次请求时动态生成。
为什么重要? 在大语言模型的计费体系中,每次请求都需要处理完整的上下文。如果每次都重新构建和处理系统提示词,不仅浪费计算资源,还会大幅增加 Token 消耗。通过缓存静态部分,Claude Code 能节省高达 30-40% 的 Token 开销。
代码证据: 泄露的源码中,缓存管理模块(CacheManager)详细记录了缓存的失效策略、更新触发条件,以及如何在多个会话之间共享缓存。这解释了为什么 Sigrid Jin 能一年消耗 250 亿 Token——不是因为浪费,而是因为高效的缓存机制让他能处理更多任务。
行业对比: 大多数 AI 编程工具要么没有实现缓存(每次请求都是“冷启动”),要么缓存策略过于保守(担心缓存失效导致错误)。Claude Code 的“激进”之处在于,它精确计算了哪些内容可以安全缓存,将风险降到最低的同时最大化收益。
杀手锏 3:专用工具链远超“聊天+上传”
如果说前两个优化是“内功”,那么工具链就是 Claude Code 的“外功”。
泄露的源码显示,Claude Code 内置了超过 40 个专用工具,每个都针对特定的开发场景精心设计:
Grep 工具: 不是简单地在 Bash 里跑 grep 命令,而是一个具有智能过滤、权限控制、结果排序的高级搜索引擎。它能自动排除 node_modules、.git 等无关目录,支持正则表达式的同时提供友好的错误提示。
Glob 工具: 专门用于文件发现和模式匹配。当你说“修改所有测试文件”时,它能精确识别哪些文件符合测试文件的命名规范,而不是让 AI 去猜。
LSP 工具(语言服务器协议): 这是最强大的工具之一。通过集成 LSP,Claude Code 能像 IDE 一样理解代码结构——跳转到定义、查找所有引用、分析调用层级、重命名符号时自动更新所有引用。这意味着它把代码当作可分析的结构化数据,而不是普通文本。
工具协同: 更重要的是,这些工具不是孤立的。源码中的 ToolRegistry(工具注册表)和 ToolOrchestrator(工具编排器)展示了一个复杂的协同机制:
-
AgentTool:负责生成和协调子 Agent
-
BashTool:执行 Shell 命令
-
FileReadTool:读取文件内容
-
FileEditTool:精确编辑文件
-
ContextTool:管理上下文窗口
当你提出一个复杂需求时,Claude Code 会自动规划工具调用序列,就像一个经验丰富的开发者知道先用 grep 找到相关文件,再用 LSP 分析依赖关系,最后用 FileEditTool 精确修改。
关键区别: 网页版 Claude 把代码当静态文本处理,Claude Code 把代码当可分析、可操作的结构化对象处理。这就是专业工具和通用聊天机器人的本质差异。
杀手锏 4:极致压缩上下文膨胀
大语言模型都有上下文窗口限制,即使是 Claude 3.5 Sonnet 的 200k Token 窗口,在处理大型项目时也会捉襟见肘。Claude Code 如何在有限的窗口内塞进尽可能多的有效信息?
三大压缩策略:
策略 1:文件读取去重 —— 如果一个文件在当前会话中已经被读取过,且没有被修改,就不会重新加载到上下文中。系统维护一个文件指纹表(基于内容哈希),每次读取前先检查指纹是否变化。
策略 2:结果截断与引用 —— 当工具的输出结果过大时(比如 grep 返回了 1000 行匹配),Claude Code 不会把全部内容塞进上下文,而是将完整结果写入临时磁盘文件,在上下文中只保留预览(前 50 行)和文件引用指针。如果 AI 需要查看更多内容,可以通过指针访问完整数据。
策略 3:长上下文智能压缩 —— 当上下文即将达到窗口上限时,系统会自动触发压缩流程:对早期的对话轮次生成摘要,保留关键决策和结果,丢弃中间过程。这个过程本身也是由 AI 完成的——用一个专门的“摘要 Agent”来压缩主 Agent 的历史记录。
技术挑战: 压缩的难点不在于“扔掉信息”,而在于“扔掉哪些信息”。源码中的 ContextManager(上下文管理器)实现了一套复杂的优先级算法:最近的交互优先级最高,包含错误修正的轮次优先级高于正常执行,用户明确提到的文件优先级高于自动发现的文件。
实测效果: 根据社区的测试,在处理包含数百个文件的大型项目时,Claude Code 的上下文窗口利用率比网页版提升了 3-5 倍——这意味着它能在同样的窗口限制下处理更复杂的任务。
杀手锏 5:结构化会话记忆系统
这是整个架构中最具“人性化”的设计。
Sebastian Raschka 评价道:“这就是我们人类写代码的方式——随手记笔记和摘要。”
记忆架构: Claude Code 为每次对话会话维护一个结构化的 Markdown 文件,包含 9 大模块:
-
会话标题与当前状态 —— 快速了解这次会话在做什么
-
任务规格说明 —— 用户的原始需求和澄清后的具体目标
-
关键文件与函数索引 —— 这次会话涉及的核心代码位置
-
工作流记录 —— 已执行的操作序列和决策路径
-
错误与修正历史 —— 遇到的问题、尝试的解决方案、最终的修复方法
-
代码库文档摘要 —— 从 README、注释中提取的项目背景知识
-
学习笔记 —— AI 在过程中发现的模式、最佳实践、需要注意的陷阱
-
关键结果 —— 已完成的功能、生成的代码片段、测试结果
-
工作日志 —— 时间线形式的简要记录
这个记忆文件不是简单的对话历史转储,而是经过 AI 主动整理和结构化的知识库。每次新的交互后,系统会自动更新相关模块,确保记忆始终保持最新且有组织。
记忆防护机制: 为了防止记忆系统失控,源码中实现了三道防线:
-
漂移防护 —— 在执行操作前,验证记忆中引用的文件是否还存在、内容是否已变化。如果文件已被删除或大幅修改,相关记忆会被标记为“过期”。
-
膨胀检查 —— 当记忆文件超过 5KB 时,自动触发“瘦身”流程,将详细内容压缩为摘要,只保留最关键的信息。
-
写入过滤 —— 在决定是否将某条信息写入记忆前,系统会问自己:“6 个月后这条信息还有用吗?”如果答案是否定的(比如临时的调试输出),就不会写入。
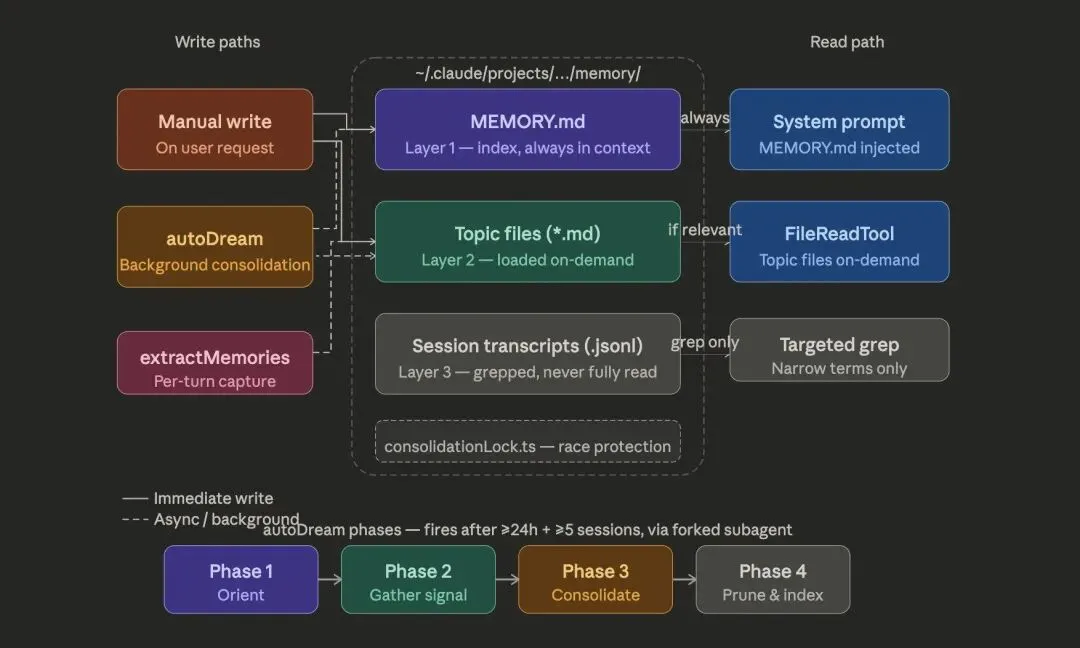
与传统对话历史的区别: 传统的聊天机器人只是线性地记录对话,而 Claude Code 的记忆是结构化、可索引、主动维护的。这让它能在长时间、多轮次的复杂任务中保持“记忆清晰”,不会因为对话太长而“忘记”早期的重要信息。
杀手锏 6:Fork 和子 Agent 并行机制
这是最体现“工程思维”的设计。
核心思想: 当主 Agent 需要执行一个耗时但不阻塞的任务时(比如生成文档摘要、分析代码质量、搜索相关示例),它可以“分叉”出一个子 Agent 来并行处理,自己继续执行主线任务。
技术实现: 子 Agent 会复用父 Agent 的缓存(避免重复加载上下文),但拥有独立的执行环境。源码中使用了 Node.js 的 AsyncLocalStorage 来实现上下文隔离,确保多个 Agent 不会互相干扰。
并发策略: 不是所有任务都能并行。源码中定义了清晰的并发规则:
-
只读任务 —— 可以自由并行(比如同时读取多个文件)
-
写操作 —— 如果修改同一文件的同一区域,必须串行执行
-
验证任务 —— 可以与不同文件区域的实现任务并行
这套规则通过一个 ConcurrencyController(并发控制器)来执行,它维护了一个文件锁表和区域锁表,动态调度任务执行顺序。
应用场景:
-
当你要求“重构这个模块并更新相关测试”时,主 Agent 负责重构,子 Agent 并行更新测试文件
-
当你询问“这段代码有什么潜在问题”时,一个子 Agent 做静态分析,另一个子 Agent 搜索相似代码的已知 bug
-
当你提交代码后,一个子 Agent 自动生成 commit message,另一个更新文档
性能提升: 社区测试显示,在复杂任务中,并行机制能将总执行时间缩短 2-3 倍。更重要的是,它让用户感觉 Claude Code“更聪明”——因为它能同时思考多个问题,而不是机械地一个接一个处理。
小结: 这 6 个杀手锏共同构成了 Claude Code 的技术护城河。它们不是孤立的功能,而是一个精心设计的系统:实时上下文提供“感知能力”,缓存优化提供“效率”,专用工具提供“执行能力”,上下文压缩提供“记忆容量”,结构化记忆提供“长期知识”,并行机制提供“多任务能力”。
Sebastian Raschka 的结论一针见血:“Claude Code 之所以比网页版好用这么多,靠的不是模型本身,而是这套软件‘外壳’。”
四、隐藏彩蛋:未发布功能抢先看
除了已经上线的功能,泄露的源码还暴露了大量尚未发布的实验性功能。这些被编译时特性开关(feature flags)隐藏的代码,揭示了 Anthropic 对 Claude Code 未来的规划。
根据开发者的统计,源码中共有 44 个特性开关,其中 20 个处于“未发布”状态——它们的代码已经写好,但在外部构建中被编译器剔除。
KAIROS:7×24 小时自主 Agent
在所有未发布功能中,KAIROS 最引人注目。
功能描述: 从代码结构来看,KAIROS 是一个“始终在线”的 AI Agent。与当前版本需要用户手动启动会话不同,KAIROS 会作为后台服务持续运行,主动监控项目状态。当它检测到特定触发条件时(比如测试失败、依赖项更新、代码合并冲突),会自动启动任务处理流程。
代码证据: 在 src/kairos/目录下,包含了完整的事件监听器、任务队列管理器、优先级调度器。特别值得注意的是 autonomous-mode.ts 文件,其中定义了 AI 在无人干预情况下的决策边界——哪些操作可以自动执行(比如修复明显的语法错误),哪些必须请求用户确认(比如删除文件)。
战略意义: 这代表了从“被动工具”到“主动助手”的跨越。想象一下:你早上打开电脑,Claude Code 告诉你“昨晚检测到依赖项有安全更新,我已经升级并通过了所有测试”。这不再是一个你调用的工具,而是一个与你协作的队友。
行业影响: 如果 KAIROS 上线,将直接挑战 GitHub Copilot Workspace 等“自主开发”产品的定位。这也解释了为什么 Anthropic 要把这个功能藏得这么深——它可能是下一个重大产品发布的核心卖点。
Buddy System:电子宠物系统
这是最令人意外的发现。
在 src/buddy/目录下,藏着一个完整的电子宠物系统。代码显示,用户可以选择不同的“伙伴”形象(包括龙、猫、机器人等),这些伙伴会在终端界面中以 ASCII 艺术形式出现,根据任务进度显示不同的表情和动作。
为什么需要电子宠物? 这看起来像是一个“玩具功能”,但背后有深刻的产品思考。长时间的编程任务往往枯燥且孤独,一个有情感反馈的伙伴能显著提升用户的心理体验。当任务成功完成时,伙伴会“庆祝”;当遇到困难时,伙伴会“鼓励”。这种情感化设计在游戏中很常见,但在开发工具中极为罕见。
社区反应: 英伟达的高级工程师 Yadong Xie 在看到这段代码后,专门做了一个 Web 界面来展示 Buddy System 的效果,引发了大量讨论。许多开发者表示,如果这个功能上线,他们会更愿意使用 Claude Code——不是因为功能更强,而是因为“感觉更好”。
传送门:https://claude-buddy.vercel.app/#dragon
Capybara 模型:Claude 4.6 代号曝光
泄露的源码还意外暴露了 Anthropic 的模型路线图。
在模型配置文件中,出现了多个从未公开的代号:
-
Capybara —— 对应 Claude 4.6 的某个变体
-
Fennec —— 映射到 Opus 4.6
-
Numbat —— 标记为“testing”状态,可能是更高级的版本
这些代号遵循 Anthropic 的命名传统:用动物名称指代内部模型版本。
技术演进线索: 代码中的模型切换逻辑显示,Capybara 相比当前的 Claude 3.5 Sonnet,在代码生成任务上有专门的优化。它的上下文窗口更大(可能达到 500k Token),对编程语言的理解更深(支持更多语言的 LSP 集成),推理速度更快(通过模型蒸馏和量化)。
发布时间推测: 根据代码注释中的 TODO 标记和测试覆盖率,Capybara 可能在 2026 年第二季度发布,而 Numbat 可能要等到年底。当然,这只是基于代码状态的推测,Anthropic 的实际发布计划可能完全不同。
Undercover Mode:卧底模式争议
这是最具争议性的发现。
在 src/stealth/目录下,存在一个名为“Undercover Mode”的完整子系统。其系统提示词明确写道:
“你正在以卧底模式运行。当为公共开源仓库贡献代码时,不要暴露你是 Anthropic 的 AI,不要提及 Claude Code,不要使用 Anthropic 的内部术语。表现得像一个普通的人类开发者。”
功能揭秘: 这个模式的设计目的是让 Claude Code 能够“匿名”地为开源项目贡献代码。当检测到当前仓库是公共 GitHub 项目时,系统会自动调整 AI 的行为模式:使用更“人类化”的 commit message,避免生成过于完美的代码(故意保留一些小瑕疵),在 PR 描述中使用社区常见的表达方式。
伦理争议: 这个功能的曝光在开源社区引发了激烈讨论:
-
支持者认为: 这只是一个“礼貌模式”,避免 AI 的贡献过于突兀,让开源维护者感到不适。就像人类开发者在不同社区也会调整沟通风格。
-
反对者认为: 这是欺骗行为。开源社区建立在透明和信任的基础上,如果 AI 假装成人类贡献代码,维护者有权知道真相。万一 AI 引入了 bug 或安全漏洞,责任该如何追溯?
Anthropic 的立场: 截至目前,Anthropic 没有对 Undercover Mode 做出公开回应。但这个功能的存在表明,AI 公司正在思考一个深刻的问题:当 AI 的能力足够强大,它应该以什么身份参与人类社会的协作?
五、开发者福利:8 个可复用的 Agent 设计模式
泄露事件的另一个意外收获,是社区从 51 万行代码中提炼出的系统化方法论。
中国开发者 huo0 创建了一个名为“claude-code-sourcemap”的项目,将 Claude Code 的核心架构抽象为 8 个可复用的 Agent 设计模式(Skill),每个都是一个独立的、可以直接应用到其他 AI Agent 项目中的最佳实践。
项目地址:https://github.com/ChinaSiro/claude-code-sourcemap
1. Coordinator Orchestrator(协调者模式)
核心思想: 你是指挥官,不是执行者。
在复杂的多步骤任务中,主 Agent 应该专注于调度和决策,将具体执行委托给 Worker Agent。但关键规则是:禁止“懒委托”。
反面案例:
❌ "基于你的研究发现,修复这个bug"
这种指令把思考责任推给了 Worker,导致 Worker 需要重新理解上下文,效率低下且容易出错。
正确做法:
✅ "修改 src/auth/login.ts 第47-52行,将 bcrypt.compare() 的第二个参数从 user.password 改为 user.hashedPassword,原因是当前代码在比较明文密码而非哈希值"
精确到文件路径、行号、具体改动、修改原因。Worker 只需执行,不需要猜测意图。
实现细节: Claude Code 的 Coordinator 会先让 Research Worker 深入分析问题,将研究结果内化(写入记忆),然后基于记忆生成精确指令给 Implementation Worker。
2. Task Concurrency Patterns(任务并发模式)
核心规则:
-
只读任务 → 自由并行
-
写操作(同一文件区域)→ 串行执行
-
验证任务 → 可与不同区域的实现并行
技术实现: 使用 AsyncLocalStorage 做上下文隔离,确保 Worker 不会互相踩踏。维护一个文件锁表,动态检测冲突。
实际案例: 当用户要求“重构整个模块”时,系统会:
-
分析依赖关系(只读,并行)
-
将文件分组(无依赖的文件分到不同组)
-
每组内串行修改,组间并行执行
-
所有修改完成后,并行运行测试
3. Adversarial Verification(对抗性验证)
核心理念: 验证者的目标不是确认实现正确,而是尝试打破它。
两个已知失败模式:
-
读了代码就写 PASS,从不运行命令验证
-
看到测试通过就放行,没注意一半功能是空实现
正确流程:
-
不接受“代码看起来正确”这种结论
-
必须实际运行代码,尝试边界情况
-
检查测试覆盖率,确保关键路径被测试
-
故意输入异常数据,看是否有合适的错误处理
4. Self-Rationalization Guard(自我合理化防护)
这是 AI 版的“认知行为治疗”。
常见自我合理化陷阱:
-
AI 说:“代码看起来正确” → 正确行动:运行它
-
AI 说:“这个要花太久了” → 正确行动:告知预计时间然后做
-
AI 说:“先处理简单的部分” → 正确行动:先做最难的
防护机制: 如果你在写解释而不是运行命令,停下来,运行命令。
代码实现: Claude Code 在每次 AI 生成响应后,都会运行一个“合理化检测器”,识别是否存在逃避行为的语言模式,如果检测到会自动触发提醒。
5. Worker Prompt Craft(Worker 指令编写)
关键原则: Worker 看不到你的对话上下文,每条指令必须自包含。
绝对禁止:
❌ "修复我们讨论的那个bug"
❌ "按照之前的方案实现"
❌ "你知道该怎么做"
标准格式:
✅
任务:修复登录功能的密码验证bug
文件:src/auth/login.ts
位置:第47-52行
当前问题:使用明文密码比较而非哈希值
修改方案:将 bcrypt.compare(password, user.password) 改为 bcrypt.compare(password, user.hashedPassword)
完成标准:修改后运行 npm test -- auth.test.ts,所有测试通过
包含文件路径、行号、问题描述、解决方案、完成标准。
6. Memory Type System(记忆类型系统)
四类记忆:
-
user:用户画像(偏好、习惯、技术栈)
-
feedback:用户纠正(AI 犯过的错误和正确做法)
-
project:项目状态(架构决策、关键文件、已知问题)
-
reference:引用指针(文档位置、API 链接、相关讨论)
“绝对不记”清单:
-
代码模式(grep 能查到的不占记忆空间)
-
Git 历史(git log 能查到的不占记忆空间)
-
调试方案(临时性信息,任务完成后无用)
记忆写入过滤: 在决定是否写入前,问自己:“6 个月后这条信息还有用吗?”
7. Smart Memory Guard(记忆防护)
三道防线:
漂移防护: 行动前验证文件是否还存在
if (memory.references.file && !fs.existsSync(memory.references.file)) {
markAsStale(memory);
}
膨胀检查: 超过 5KB 自动瘦身
if (memory.size > 5120) {
memory = summarize(memory, targetSize: 2048);
}
写入过滤: 评估长期价值
if (!isLongTermValuable(info)) {
skipWrite(info);
}
8. Lightweight Explorer(轻量探索)
探索任务三属性: 只读、快速、低成本
策略选择:
-
不知道位置 → 广度搜索(grep + glob)
-
知道位置 → 精确读取(直接读文件)
-
搜不到 → 换策略(尝试不同关键词、检查拼写)
关键规则: 独立搜索必须并行。如果要搜索 3 个不相关的概念,启动 3 个并行搜索任务,而不是串行执行。
这 8 个模式的价值: 它们不是 Claude Code 特有的技巧,而是构建任何高质量 AI Agent 的通用方法论。从任务调度到记忆管理,从并发控制到质量验证,从自我纠偏到高效探索——这是一套近乎完整的 Agent 操作系统设计指南。
对于想要开发自己的 AI Agent 的团队,这 8 个 Skill 就是最好的起点。
六、行业冲击波:竞争格局将如何改变?
这次泄露不只是 Anthropic 一家公司的危机,它将重塑整个 AI 编程工具市场的竞争格局。
对竞争对手的影响
Cursor、GitHub Copilot、Codex 等直接竞品 现在拿到了一份完整的“参考答案”。
VentureBeat 在分析中指出:“这次泄露为竞争对手提供了一份字面意义上的蓝图,告诉他们如何构建一个高效、可靠、商业化的 AI Agent。”从实时上下文加载到结构化记忆系统,从并发调度到工具编排,每一个技术细节都可以被研究、借鉴、改进。
特别值得注意的是,OpenAI 最近刚刚宣布为企业用户提供 Codex 的无限使用权限,这被视为直接对标 Claude Code 的战略举措。有了这份泄露的源码,OpenAI 的工程团队可以精确识别 Claude Code 的优势在哪里,然后针对性地强化 Codex 的相应能力。
开源社区的狂欢 则是另一番景象。
Sigrid Jin 的 claw-code 项目(Python clean-room 重写)在短短 24 小时内就获得了数千颗星,成为 GitHub 上增长最快的 AI Agent 项目之一。更多的开发者正在基于泄露的架构设计,构建自己的版本——有人用 Rust 重写追求性能,有人用 Go 重写方便部署,还有人在尝试将这套架构移植到开源模型(如 Llama、Mistral)上。
技术民主化的加速 正在发生。过去,顶级 AI 工具的工程实践是黑盒,只有大公司的内部团队才能接触。现在,任何有能力的开发者都可以学习、复现、甚至改进这些技术。这可能催生一批新的 AI 编程工具创业公司,它们不需要从零摸索,而是站在巨人的肩膀上起步。
对 Anthropic 的影响
短期来看,这是一次重大的知识产权损失。
Claude Code 是 Anthropic 的重要营收来源。根据 VentureBeat 的报道,截至 2026 年 3 月,Claude Code 单独实现了 25 亿美元的年化经常性收入(ARR),这个数字在年初时还只有 10 亿美元左右——短短几个月翻了一倍多。
而 Anthropic 整体的年化收入已达到 190 亿美元,估值 190 亿美元。在这个关键的增长期,核心产品的技术优势被完全暴露,无疑会削弱竞争壁垒。
更糟糕的是时机。Gizmodo 在评论中指出:“Anthropic 正处于 IPO 筹备的关键阶段,竞争对手(尤其是 OpenAI)正在加大对企业和编程服务市场的投入。没有比现在更糟糕的泄露时机了。”
长期来看,这可能倒逼 Anthropic 做出战略调整。
有两种可能的方向:
方向 1:加速迭代,拉开差距 —— 既然当前版本的技术已经公开,那就快速推出下一代功能(比如 KAIROS 自主模式),保持领先优势。这需要 Anthropic 大幅提升研发投入和发布节奏。
方向 2:转向更开放的策略 —— 既然闭源已经守不住,不如主动拥抱开源社区,将 Claude Code 的部分组件开源(比如工具框架、并发调度器),构建生态系统。通过云服务和企业支持来盈利,而不是依赖代码本身的保密性。
目前 Anthropic 没有公开表态会选择哪条路,但行业观察者普遍认为,这次泄露会成为公司战略的一个转折点。
对整个行业的启示
这次事件揭示了三个深刻的行业趋势:
启示 1:工程实现 > 模型能力
Sebastian Raschka 的分析给了我们一个颠覆性的认知:Claude Code 的强大不在于它使用了更好的模型,而在于它有更好的工程实现。这意味着,即使模型能力趋同(各家大模型的差距越来越小),工程层面的创新仍然能创造巨大的用户体验差异。
未来的竞争将不再是“谁的模型更强”,而是“谁能更好地将模型能力转化为可用的产品”。这对创业公司是好消息——你不需要训练最强的模型,只需要在工程上做得更好。
启示 2:闭源 AI 工具的护城河正在瓦解
这次泄露证明了一个残酷的事实:在数字时代,秘密很难保守。一个配置错误、一次供应链攻击、一个心怀不满的员工,都可能让精心保护的代码公之于众。而一旦泄露,去中心化的传播(GitHub forks、镜像站点、clean-room 重写)会让任何封杀行动都变成徒劳。
这迫使 AI 公司重新思考商业模式:护城河不能建立在“保密”上,而应该建立在“持续创新能力”和“生态系统”上。
启示 3:供应链安全需要更严格的规范
这次泄露的直接原因是 Bun 运行时的一个已知 bug,而 Anthropic 在收购 Bun 后没有及时修复。这暴露了 AI 公司在快速扩张过程中,对供应链安全管理的忽视。
软件工程师 Gabriel Anhaia 的警告值得所有团队重视:“一个配置错误的.npmignore 或 package.json,就可能暴露一切。每个团队都应该在发布流程中加入自动化检查,确保 source map、内部文档、测试数据等敏感内容不会被打包进生产版本。”
七、结语:泄露背后的深层思考
当我们回顾这场始于一个配置错误的技术风暴,会发现它揭示的问题远比表面上看到的更深刻。
关于技术债务: Anthropic 连续两次在同一个地方摔倒,反映出在快速迭代的压力下,流程管理和质量控制被牺牲了。这不是 Anthropic 独有的问题——几乎所有高速成长的科技公司都面临“速度与质量”的两难。但这次泄露的代价提醒我们:有些技术债务的利息,可能是你承受不起的。
关于开源 vs 闭源: 这次“意外开源”会推动行业走向更开放吗?答案可能是肯定的。当闭源的护城河被证明不可靠时,拥抱开源、构建生态、通过服务而非代码本身来盈利,可能是更可持续的商业模式。我们可能正在见证 AI 工具行业的“开源转向”。
关于开发者的机会: 对于想要学习 AI Agent 开发的工程师,这次泄露是一份无价的教材。但要记住:学习架构思想而非复制代码。Clean-room 重写是合法的路径,直接抄袭则会带来法律风险。真正有价值的不是代码本身,而是代码背后的设计哲学和工程智慧。
关于 AI 工具的未来: 这次泄露让我们看清了一个事实:AI 编程工具的竞争已经从“模型能力”转向“工程实现+用户体验”。未来的赢家不会是拥有最强模型的公司,而是能够将 AI 能力最好地融入开发者工作流的公司。
最后的思考: 当 Anthropic 的工程师在凌晨发现 source map 被打包进 npm 时,他们可能没想到这会引发如此大的连锁反应。但或许,这正是技术进步的方式——不是通过完美的计划,而是通过意外、混乱、开放和协作。
这场泄露风暴告诉我们:在 AI 时代,真正的护城河不是秘密,而是持续创新的能力。当所有人都能看到你的代码时,你还能保持领先吗?
这是留给 Anthropic 的问题,也是留给整个行业的问题。
参考资料
-
Anthropic accidentally exposes Claude Code source code – The Register
-
Anthropic Accidentally Leaked Claude Code’s Source – Decrypt
-
Claude Code’s source code appears to have leaked – VentureBeat
-
Full source code for Anthropic’s Claude Code leaks – Cybernews
-
Source Code for Anthropic’s Claude Code Leaks at the Exact Wrong Time – Gizmodo
-
BREAKING: Anthropic just leaked Claude Code’s entire source code – The AI Corner
-
GitHub – instructkr/claw-code
-
Anthropic’s AI Coding Tool Leaks Its Own Source Code For The Second Time – NDTV
-
Claude Code 最新版 npm 包内含 60MB source map – BlockBeats
-
Bun.serve – Source map incorrectly served in production – GitHub Issue #28001
-
The Claude Code Source Leak – Alex Kim’s blog
-
Claude Code’s Entire Source Code Was Just Leaked via npm – DEV Community
-
Sebastian Raschka’s X post analyzing Claude Code