 夜雨聆风
夜雨聆风





Claude Code 源码泄漏之后,真正让人后背发凉的,是后面的连锁反应
这件事表面上像一次尴尬的工程失误,但真正值得警惕的,可能不是代码本身,而是它正在把整个 AI 编程工具行业往更快、更卷、更黑盒的方向推。
如果你这两天刷到 Claude Code 源码泄漏的消息,第一反应大概率会是:这也太尴尬了。
一个天天被外界贴着“安全、谨慎、克制”标签的 AI 公司,结果把自家核心产品的一大段内部代码,因为一次发布打包失误,直接暴露给了外界。不是黑客攻进去了,不是员工把代码打包带走了,也不是电影里那种惊心动魄的内鬼戏码,就是一个很朴素、也很不体面的工程事故。
从目前公开信息看,事情是在 2026年3月31日 左右集中发酵的。多家媒体和社区讨论都提到,Anthropic 在发布 @anthropic-ai/claude-code 某个版本时,把 source map 一起带了出去,结果有人据此还原出大量内部 TypeScript 代码。Anthropic 对外的口径也比较明确:这是发布过程中的打包错误,不是系统被攻破,也没有客户数据或密钥泄漏。
这话当然重要,因为它至少说明事情没有坏到“数据事故”那个级别。
但如果你只把这件事理解成“一个公司出糗了”,那其实有点低估它了。
因为 Claude Code 不是一个普通软件。它属于现在最敏感、最热、也最卷的那条赛道:AI 编程工具。
而这条赛道最有意思的地方就在于,大家竞争的从来不只是模型强不强,还包括产品怎么组织任务、怎么做多步执行、怎么让 AI 真正像一个“能干活的同事”。这些东西,很多时候比模型参数更值钱。因为模型大家可以买、可以接、可以切,但一套真正成熟的产品逻辑,不是那么容易短时间做出来的。
所以这次泄漏真正让人后背发凉的地方,不是“代码被看到了”,而是很多原本需要慢慢试错、慢慢摸索、慢慢交学费才能长出来的东西,突然一下被摊到了明面上。
这才是连锁反应开始的地方。
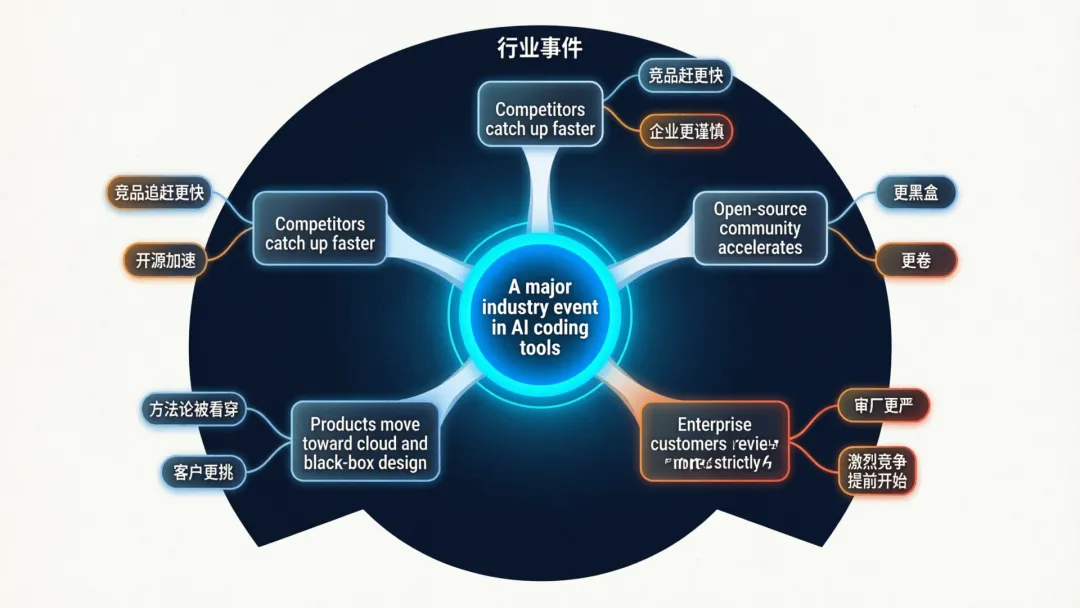
先来的,不是“崩盘”,而是同行追赶会更快
过去很多人用 Claude Code,会觉得它“就是顺”“就是像一个更会干活的 AI 工程师”,但到底为什么顺,很多人其实说不清。
现在一部分人开始能看清了。
源码这东西最可怕的一点,不是你能不能逐行看懂,而是你会突然知道:哦,原来它重点做的是这些地方;哦,原来它内部是这么组织任务的;哦,原来某些看起来很自然的体验,背后是这样拆出来的。
这意味着什么?
意味着原来别人要花几个月、半年,甚至更久才能摸出来的一些产品方法,现在可能一两周就能学个七七八八。未必有人敢原封不动复制,但只要思路被看穿,模仿速度就一定会变快。
你可以把它理解成,一支原本领先的球队,突然把自己的训练录像和战术板丢出来了一部分。其他球队未必明天就能打赢它,但大家会更快知道该往哪练。
这对 Anthropic 来说,不是最致命的一刀,但绝对是很疼的一刀。
开源会更猛,头部产品的“神秘感”会变薄
这几天一个很明显的现象是,社区里讨论最热的,已经不只是“居然泄漏了”,而是“我从里面看到了什么”。
有人开始分析它的多代理编排,有人开始拆它的交互逻辑,有人甚至直接把里面的一些思路抽出来,往开源框架上架。你会发现,讨论重点已经迅速从新闻事件本身,转向了“这套东西到底值不值得学”。
这会带来一个很现实的变化:原本笼罩在头部 AI coding 产品身上的那层神秘感,会变薄。
以前很多用户心里会觉得,头部产品之所以领先,是不是因为它们背后藏着一整套别人根本学不会的黑科技。可一旦源码层面的一部分设计被看见,很多人就会开始重新判断:它的领先到底来自模型,来自体验,来自资源,还是来自某些其实并没有想象中那么不可复制的产品机制。
这会让开源社区更兴奋,也会让用户更挑剔。
兴奋,是因为“原来这部分也可以自己做”。
挑剔,是因为“你之前让我觉得很神,现在看起来也没有神到哪里去”。
一旦这种心理在开发者圈里扩散,整个赛道就会进入一种更透明、也更残酷的阶段。大家不再只比“谁最好用”,还会比“谁只是包装得更好”。
企业客户会更谨慎,不会再只听“模型很强”
我觉得这一层是最容易被普通讨论忽略的,但可能是中期影响最大的。
因为消费市场喜欢看热闹,企业市场更关心可控性。
很多大客户之所以愿意更信任某些 AI 厂商,不只是因为模型强,也因为它们看起来更像“流程成熟的大公司”。尤其像 Anthropic 这种长期把“安全”“责任”“边界”放在品牌叙事核心位置的公司,本来在企业客户那里是有额外分数的。
可这种事情一出,客户心里一定会多一个问号:
你们连最基础的发布打包都能出这种问题,那我为什么相信你们在更复杂的企业流程里不会出别的问题?
这不代表客户马上就会跑,也不代表这件事会立刻变成商业灾难。真正的变化是,以后企业客户会问得更细、更硬:
-
• 你们内部发布流程怎么审? -
• 调试产物怎么隔离? -
• 功能灰度怎么管? -
• 权限和工具调用怎么记录? -
• 一旦出错怎么追责、怎么回滚?
说白了,这次事情会让更多企业意识到:AI 工具公司到了今天这个阶段,不能只拿“模型很强”当护身符了。你得越来越像一家成熟的软件基础设施公司。
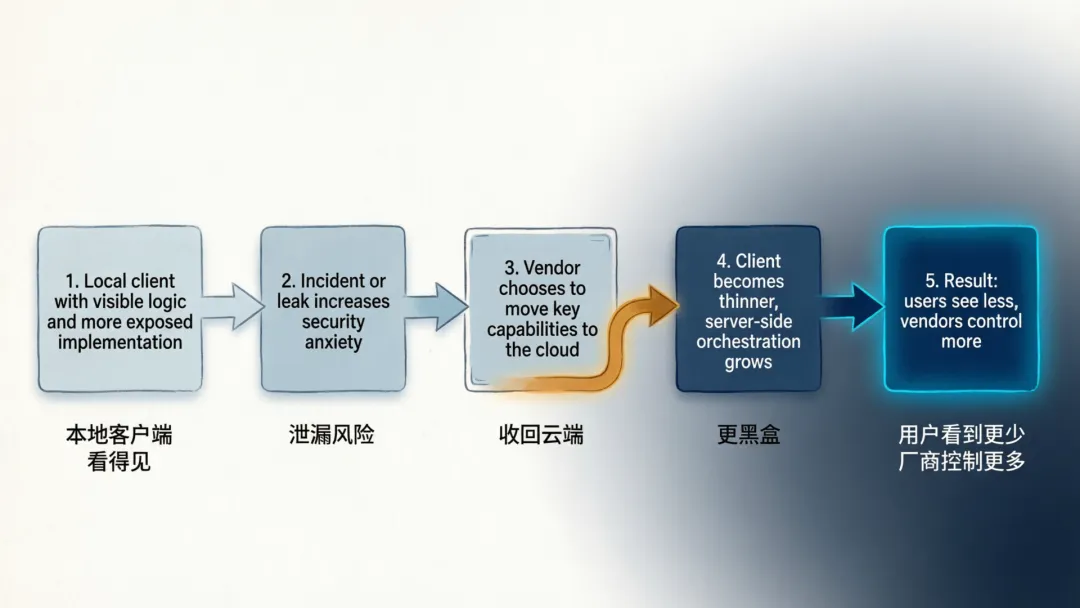
这件事还可能反过来推动产品更黑盒
这件事其实也很好理解。
如果一个本地 CLI 产品,只要某次打包没处理干净,就可能暴露太多内部实现,那厂商最自然的反应会是什么?
不是“以后再也不做客户端了”,而是“以后能不下发到本地的东西,就尽量别下发”。
这意味着,接下来你可能会看到更多 AI 编程工具往一个方向走:本地端越来越轻,真正关键的能力、策略、调度、判断和实验功能,尽量收回到服务端。
从公司角度讲,这当然更安全,也更方便灰度控制。
但从用户角度讲,事情就没那么单纯了。因为这意味着产品会更黑盒,你能看到的更少,能掌控的也可能更少。
很多人以为源码泄漏会推动行业更开放,某种程度上确实如此;但它也可能刺激头部公司把真正最值钱的部分藏得更深。
你会得到更稳定的服务,也可能得到一个更不透明的系统。
这是一种很现实的交换。
真正更难受的,可能是中间层玩家
很多人遇到这种新闻,天然会把关注点放在头部公司身上:它会不会掉粉,会不会丢客户,会不会被对手围攻。
这些当然都重要。
但从行业格局上看,真正会更难受的,往往是中间层产品。
因为头部厂商即便翻一次车,仍然有品牌、模型、资源、分发和用户基盘托着;开源社区则会因为这种事情迎来一次“集体提速”;最尴尬的,是夹在中间的那些产品。
它们没有最强模型,也没有最强品牌,还没形成足够强的开源生态。原本还能靠“更懂开发者”“体验更轻”“某个细节更顺手”去打差异化。可一旦头部产品的很多方法论被更快吸收,整个行业的平均水平一起抬高,中间层就会很容易变成两头受压。
上面的大厂更快补洞,下面的开源更快追赶。
到最后,中间层最容易进入一种很难受的状态:没有绝对领先点,但处处都要被拿来对比。
很多行业不是被一次事故直接改写的,而是被事故之后的“加速竞争”慢慢改写的。我觉得 AI coding 这个赛道,现在就有点这个味道了。

品牌滤镜也会被削弱
Anthropic 在很多人心里,代表的已经不只是一个模型厂商,而是一种价值观叙事:更谨慎、更守规则、更重边界。
可问题在于,品牌叙事越往这个方向走,一旦发生这种事情,反噬就越强。
因为外界很容易本能地产生一种情绪:
你天天提醒别人注意风险,结果自己先在最基础的工程环节上翻了车。
哪怕理性地说,“模型安全”和“软件打包失误”不是一回事;哪怕严格讲,这次也不是数据安全事故;但公众情绪不会分得那么细。很多人只会留下一个印象:原来你也会犯这种低级错误。
这对品牌来说,不是毁灭性的,但一定是掉分的。更麻烦的是,这种掉分不像服务器挂了一次那样容易恢复,因为它动摇的是一种更深的东西:你到底值不值得被默认信任。
最后真正值得警惕的是什么
不是 Claude Code 里到底藏了多少彩蛋,不是它到底有多少行代码,也不是某个内部功能是不是很酷。
而是这件事在提醒我们,AI 编程工具行业已经不再只是“谁更会聊天”的竞争了。它正在进入一个更像基础设施竞争的阶段。
在这个阶段里,大家比的是:
-
• 谁更会做工作流 -
• 谁更会做工具调用 -
• 谁更会做权限边界 -
• 谁更会做多模型协作 -
• 谁更像一家成熟的软件公司
而一旦你在这个阶段把自己的方法论暴露出来,哪怕只是一部分,行业整体都会被往前推一截。
它不一定会立刻改变第一名是谁,但它会让后来者更快,让开源更猛,让客户更谨慎,让头部更封闭,让中间层更难受。
说得再直白一点:
这次源码泄漏,真正让人后背发凉的,不是“Claude Code 被看光了”,而是“AI 编程工具的下一轮贴身肉搏,可能会因此提前开始”。
今天大家看到的是热搜,接下来几个月,大家看到的很可能是:产品越来越像,竞争越来越狠,用户越来越挑,厂商越来越不愿意把真正值钱的东西留在客户端。
如果真走到那一步,那这次事故最大的后果,就不是一次公关危机,而是它悄悄把整个行业推快了。
这才是最值得害怕的连锁反应。