夜雨聆风
夜雨聆风





MinerU 3.0:从 PDF 到 Agent 可用知识

大家好,我是寂寞的熊猫。
上一篇聊 PaddleOCR 登顶OCR GitHub 全球第一:Agent 时代,文档才是最大数据瓶颈,Agent 时代,文档解析质量才是整条 AI 工作流的上限。 当时提到 MinerU 是文档转结构化 Markdown 最值得关注的工具之一。
MinerU 在 3 月 29 日直接放出了 3.0.0 大版本。这不是一次简单迭代——它从”一个好用的文档解析工具”,升级成了”一套企业级的文档解析基础设施”。
从一份 PDF 到 Agent 真能用的结构化知识,中间到底发生了什么?MinerU 的内部链路是怎样跑通的?
先说结论
- MinerU 做的不是 OCR,而是”版面理解 + 结构重建”。 传统 OCR 只搬运字符,MinerU 要还原文档的层级、表格、公式和阅读顺序——这些才是 Agent 能理解的东西
- 它有三套完全不同的解析后端,对应三种技术路线:Pipeline(分而治之)、VLM(端到端视觉理解)、Diffusion(并行扩散解码)。选哪个取决于你的硬件和场景
- 3.0.0 的核心变化是”从工具变基座”——原生 DOCX 解析、超长文档的滑动窗口、多卡 Router 编排,解决的都是真实生产环境的痛点
如果你只关心一句话:
MinerU 不是”把 PDF 变成文字”,而是”把非结构化文档变成 Agent 能理解的结构化知识”。它内部有一条完整的链路在做这件事。
它到底在解决什么问题?
很多人觉得文档解析就是 OCR——把图片里的字识别出来就行了。
不是。
一份典型的学术论文 PDF 里有什么?
- 双栏甚至三栏的复杂排版
- 跨页的大表格,带合并单元格
- 行内公式和行间公式混在一起
- 图表、图片说明、表格脚注
- 页眉、页脚、脚注、参考文献编号
传统 OCR 会怎么处理?它会自上而下机械地扫描所有像素,把能看到的字符全部抓出来,拼成一坨纯文本。结果就是:
- 双栏被读成交替混乱的文本流
- 表格变成一堆没有行列关系的字符
- 公式变成乱码或直接丢失
- 页眉页脚混进正文,把上下文搅得一团糟
- 图片直接消失
你拿这种东西喂给 Agent,模型再强也救不回来。
MinerU 要解决的不是”识别文字”,而是四个层层递进的问题:
- 版面理解:这页纸上,什么是标题、什么是正文、什么是表格、什么是公式、什么是图片?它们各自在什么位置?
- 结构重建:表格的行列关系是什么?合并单元格怎么还原?公式怎么从图像变成 LaTeX?
- 阅读顺序推断:双栏排版先读左还是先读上?跨页表格怎么拼接?脚注属于哪段正文?
- 噪声过滤:页眉、页脚、页码、脚注编号——哪些是正文,哪些是干扰项?
只有这四件事都做对了,输出的 Markdown 才是 Agent 真能”读懂”的格式。

内部链路拆解:一份 PDF 经过了什么
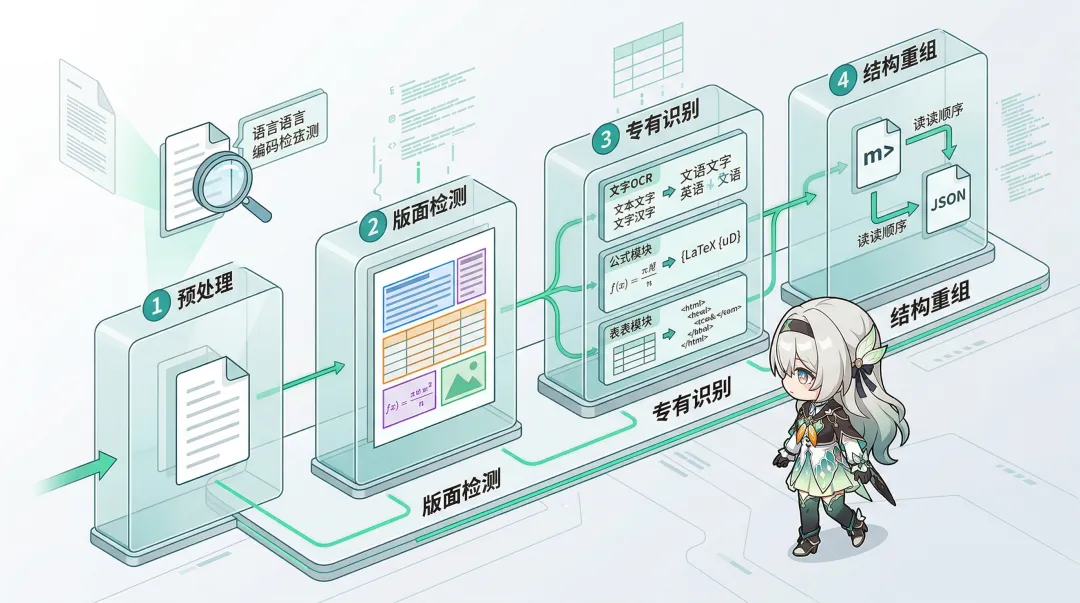
MinerU 最成熟的后端是 Pipeline,它把整个解析过程拆成了四步,每一步由专门的模型负责。
第一步:文档预处理
拿到 PDF 后,MinerU 先用 PyMuPDF 引擎做一遍”体检”:
- 这个文件加密了吗?
- 里面的文字是原生文本还是扫描图片?
- 有没有乱码?
- 文档是什么语言?
如果检测到是扫描版 PDF 或者文字复制出来是乱码,系统会自动触发全链路 OCR。这一步的关键是判断走哪条路——不是所有 PDF 都需要 OCR,原生文本 PDF 可以直接提取,速度快得多。
第二步:版面检测
这是整条链路的基石。
系统用专门的版面检测模型(基于 DocLayout-YOLO),对页面的每个像素进行空间分析。它会在页面上画出一个个边界框(Bounding Box),把每个区域分类为:
- 正文文本
- 标题(H1、H2、H3)
- 表格
- 图片
- 行内公式 / 行间公式
- 页眉 / 页脚 / 页码
说白了,这一步在做”这张纸上每个区域是什么东西“的判断。如果这一步出了偏差——比如把一个表格误判成了图片——后面的所有处理都会跟着错。
第三步:专有内容识别
版面检测把页面切成了一块块区域,接下来每个区域交给最擅长处理它的专家模型:
- 纯文本:交给 PaddleOCR,支持 109 种语言识别
- 数学公式:先用 YOLOv8 精准定位行内公式和行间公式的位置,再用 UniMERNet 把公式图像逆向编译成 LaTeX 源码
- 表格:用结构化重建技术,把表格图像还原成 HTML 格式——注意,不是简单的 Markdown 表格,而是 HTML。为什么?因为只有 HTML 才能准确表达跨行跨列的合并单元格
- 图片:提取图像文件,关联图片标题和脚注
这一步是 MinerU 相比竞品的真正优势所在。很多工具在表格和公式上要么丢失结构、要么精度不够,MinerU 用专家模型分别攻坚,每个子任务都能定向优化。
第四步:后处理与结构重组
识别完成后还有关键的一步:
- 剔除噪声:自动删除页眉、页脚、页码等干扰元素
- 推断阅读顺序:基于空间分布的拓扑排序算法,确保双栏、多栏排版下文本输出符合人类阅读逻辑
- 组装输出:把所有内容组装成 Markdown(保留层级结构)和 JSON(层级化数据,从文档区块→功能区块→行→字符跨度)
输出的 JSON 结构非常精细——不是简单的文本平铺,而是一个四层嵌套结构:顶级文档区块→功能区块(图片注释、表格脚注、行间公式)→单行→具体字符跨度(包含内联公式标记)。这种结构对下游 RAG 的 Chunking 分块特别友好,能保持语义边界不被破坏。
三套后端
Pipeline 只是 MinerU 三套后端之一。每套后端本质上是同一种问题的不同解法。
Pipeline:分而治之,确定性优先
前面拆解的四步链路就是 Pipeline。它的核心思路是把复杂问题拆成子任务,每个子任务交给最擅长的专家。
优势:
- 资源门槛极低——最低 4GB 显存,甚至能在纯 CPU 上全功能运行
- 确定性高——每个模块的输入输出明确,出了问题可以定位到具体环节
- OmniDocBench 86.2 分,已经超过上一代主流 VLM
劣势:
- 级联误差风险——版面检测要是漏检了一个表格,下游的表格识别就完全不会触发
- 串行处理,速度受限于最慢的环节
适合谁:没有高端 GPU、需要稳定可用、文档类型多样的场景。这也是我推荐大多数人先试的后端。
VLM:端到端,全局理解
VLM(视觉语言模型)后端的思路完全不同。它不分步,而是用一个大型视觉语言模型直接看整页图像,然后生成结构化文本。
你可以把它理解成一个”读过几百万份文档的 AI”——它不只看像素,还带着”文档一般长什么样”的先验知识来判断。
优势:
- 全局语义理解——不会因为某个边界框画歪了就出错
- 精度最高——OmniDocBench 90+ 分,是目前 MinerU 内部的精度天花板
劣势:
- 硬件门槛高——至少 8GB 显存,要求 Volta 架构以上 GPU 或 Apple Silicon
- 无法纯 CPU 运行
- 端到端模型出了问题,很难定位是哪个环节
适合谁:有 GPU 服务器、追求最高精度、文档排版特别复杂的场景。
Diffusion:并行解码,速度优先
这是 MinerU 最新探索的方向(MinerU-Diffusion-V1),思路更大胆——它不再逐字生成,而是并行扩散解码。
传统的自回归模型(包括 VLM)是从左到右一个字一个字预测,这在文档 OCR 里有两个致命问题:一是慢,逐字生成无法利用 GPU 的并行能力;二是容易”幻觉”,模型太依赖语言先验,遇到财务报表里的数字串、化学式这些”不像人话”的内容,容易脱离视觉证据瞎猜。
Diffusion 的做法是:把整个 Token 序列当成一幅”噪声图”,通过并行去噪,让所有位置同时收敛到正确结果。 配合结构化块注意力掩码,复杂度从二次方降到接近线性。
结果是什么?在保持 99.9% 相对准确率的条件下,推理速度是自回归模型的 2.12 倍;放宽到 98.8%,速度飙到 3 倍以上。
适合谁:大规模语料生产、数据工厂、对吞吐量有极致要求的场景。目前还在早期阶段,但方向非常有想象力。
一张表看清怎么选
| Pipeline | VLM | Diffusion | |
|---|---|---|---|
| 核心思路 | 分步专家协作 | 端到端视觉理解 | 并行扩散解码 |
| 精度 | 86.2 | 90+ | 略低但极快 |
| GPU 要求 | 4GB / 纯 CPU | 8GB+ | 8GB+ |
| 速度 | 中等 | 慢 | 最快(3x) |
| 适合场景 | 通用、入门首选 | 高精度需求 | 大规模生产 |
我的建议:先跑 Pipeline。一行命令就能用,不需要 GPU。等你发现 Pipeline 在你的文档上确实有瓶颈了,再考虑 VLM 或 Diffusion。
3.0.0 到底变了什么
上面讲的是 MinerU 的核心链路和架构。3.0.0 的更新,本质上是让这套架构从”能跑”变成”能在生产环境大规模跑”。
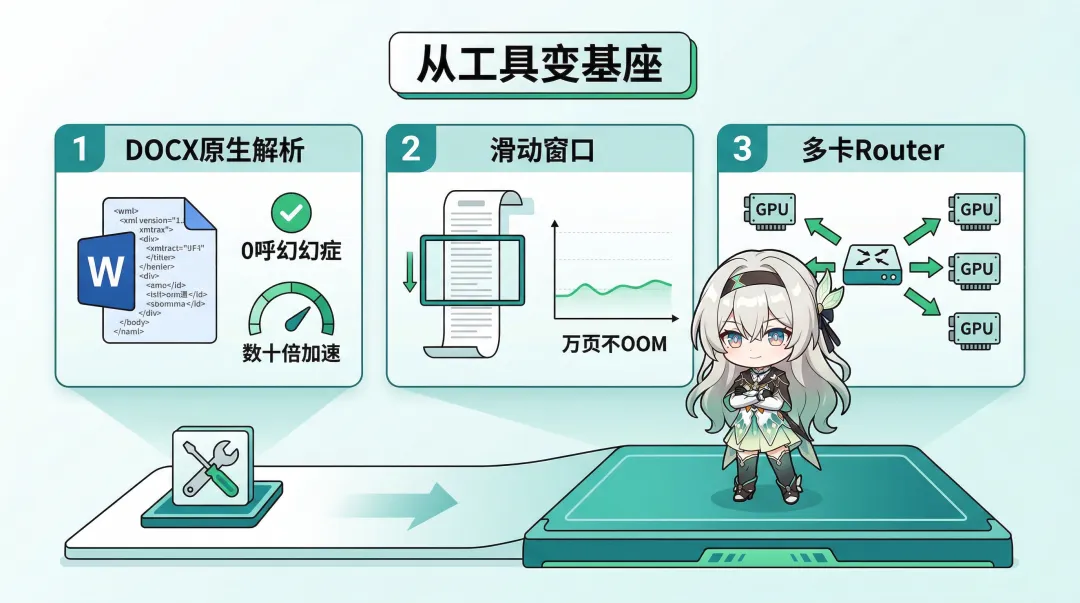
DOCX 原生解析
之前的做法是把 DOCX 先转成 PDF,再用视觉模型解析 PDF。这个路径有个根本问题:DOCX 的底层是 XML,里面明确定义了文档结构,但转成 PDF 后这些确定性信息全丢了,视觉模型只能”猜”原来的结构是什么。
3.0.0 直接在 XML 层面解析 DOCX,完全绕过视觉渲染。结果:零幻觉,速度提升数十倍。
这对金融、法律这种 Word 文档为主的场景是杀手级更新。
滑动窗口:万页文档不再 OOM
以前解析几万页的招股说明书,内存会爆掉,只能手动拆文件。
3.0.0 引入了动态滑动窗口机制,限制活跃计算的上下文窗口大小。配合流式落盘(解析完一部分就写入磁盘),无论文档多长,内存占用峰值始终稳定在低位。
mineru-router:一键多卡部署
新增的路由器组件,对外接口和 mineru-api 完全兼容,但能在后端自动做多服务、多 GPU 的任务路由和负载均衡。
配合线程安全优化,现在可以实现:一条命令启动多卡部署。
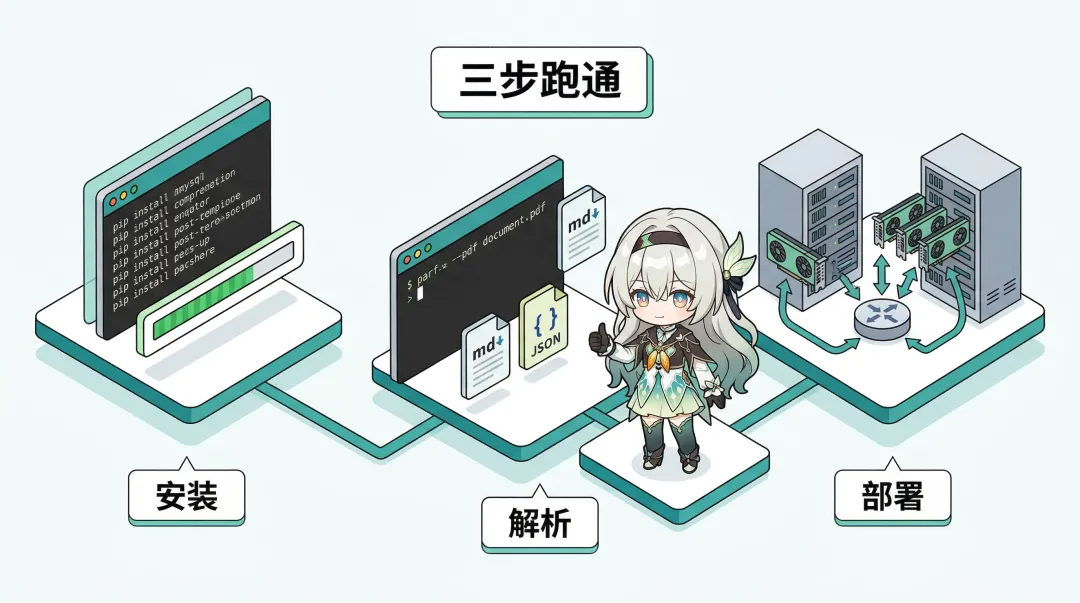
怎么跑起来
最小化上手,三步搞定。
安装:
pip install --upgrade pippip install uvuv pip install -U "mineru[all]"如果网络访问不了 HuggingFace,先切换模型源:
export MINERU_MODEL_SOURCE=modelscope解析单个文档(不需要 GPU):
mineru -p 你的文档.pdf -o 输出目录 -b pipeline启动 API 服务:
mineru-api --host 0.0.0.0 --port 8000然后用 HTTP 调用:
curl -X POST http://127.0.0.1:8000/file_parse \ -F "files=@demo.pdf" \ -F "return_md=true"多卡部署(如果你有多张 GPU):
mineru-router --host 0.0.0.0 --port 8002 --local-gpus auto一条命令,Router 自动拉起多个 worker,对外统一入口,内部自动负载均衡。
Gradio WebUI(可视化):
mineru-gradio --server-name 0.0.0.0 --server-port 7860浏览器打开 http://127.0.0.1:7860,拖文件进去就能看效果。
写在最后
MinerU 3.0.0 的真正意义不是”又加了几个功能”,而是它完成了从工具到基础设施的跃迁:
- Pipeline 后端解决了”谁能用”的问题——4GB 显存甚至纯 CPU 就能跑,门槛压到了最低
- VLM 后端解决了”准不准”的问题——端到端视觉理解,精度天花板
- Diffusion 探索了”快不快”的问题——并行解码,3 倍加速,面向未来的大规模语料生产
- 滑动窗口和 Router 解决了”能不能上生产”的问题——万页文档不爆内存,多卡一键编排
如果对AI个人提效,以及副业感兴趣,而不只是围观,也推荐加入 IDO 老徐 的知识星球:AI 落地实战 · DeepSeek · OpenClaw。
里面会持续分享 OpenClaw 相关内容、AI 工作流搭建、商业化落地和各种实战避坑经验。