 夜雨聆风
夜雨聆风





盘完Cloude Code的源码,我发现了4个隐藏的高级RAG技巧~
昨天,Claude Code被动开源了,大家估计都刷到了,github已经76k star了
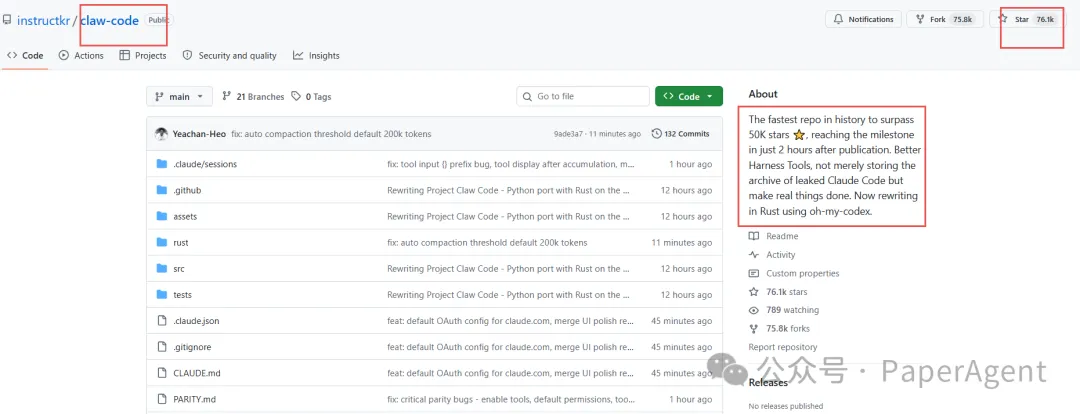
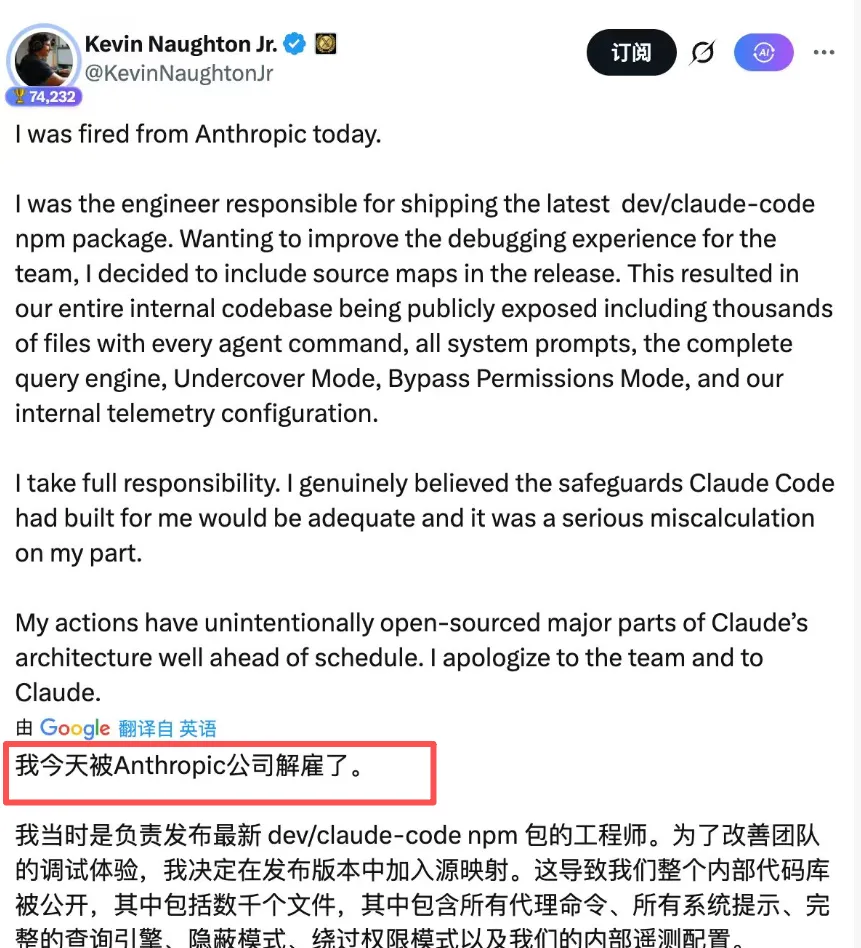
今天有人来认锅了:我被Anthropic开除了
然后,我把 Claude Code 的源码(准确说是从 npm 包的 cli.js.map 还原出来的 4756 个文件)翻了个底朝天。
说实话,翻完之后我最大的感受是:市面上那些“手搓 RAG”的教程,大多还停留在“把文档切一切、塞进向量库、查出来拼给模型”的初级阶段。
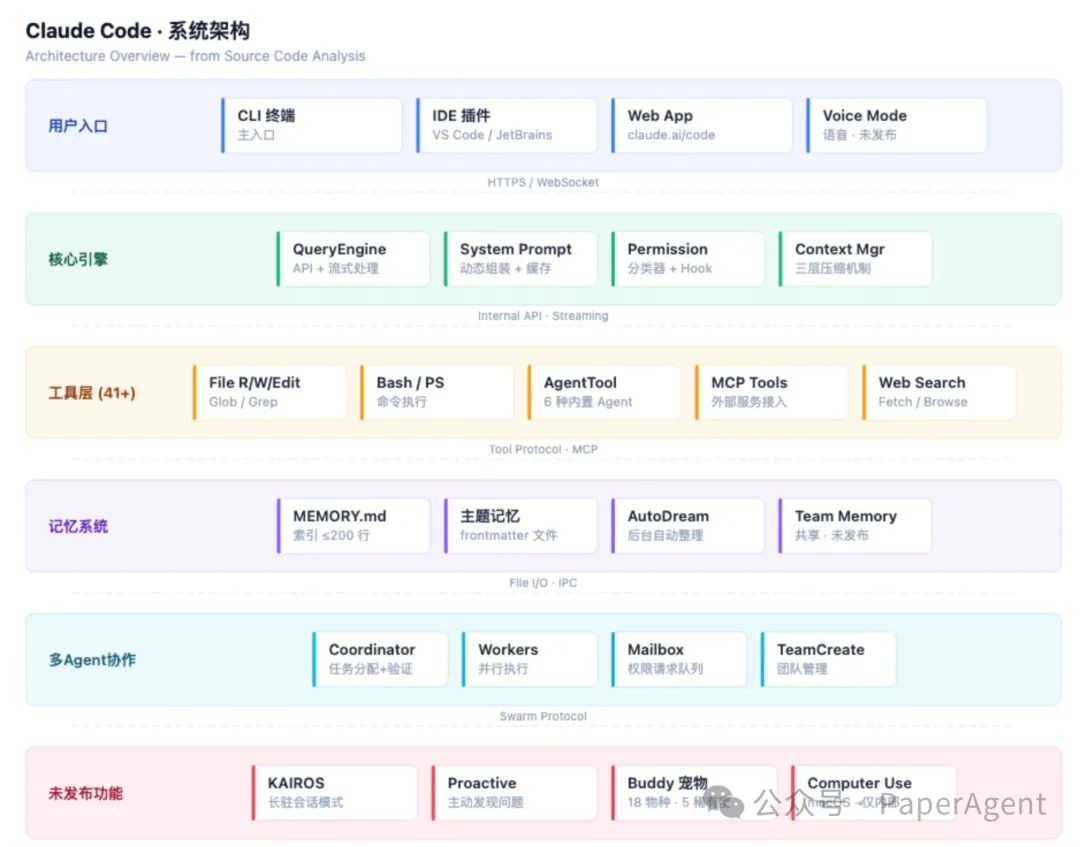
但 Claude Code 这套东西,完全不是这个玩法。
它把 RAG 从“外挂知识库”升级成了“操作系统级的内存管理”。它不是去外部找知识,而是在 Agent 执行过程中,动态决定什么时候搜索、搜索什么、保留什么、扔掉什么。
我把它拆解了一下,发现有四个技巧特别“反常识”,但非常值钱。
01 不用向量库的“即时检索”
很多人在做 RAG 时,第一反应就是:我得建个向量库。
先 Embedding,存进去,查的时候再召回。这一套流程跑下来,延迟、成本、准确率,处处是坑。
但 Claude Code 里的 Explore Agent,完全不用向量库。
它是一个纯读模式的代码探索专家。当主 Agent 需要了解某个模块、查找某个函数、搞清楚某段逻辑时,它不会去向量库里“搜相似”,而是直接调用 Glob 和 Grep 去实时搜索。
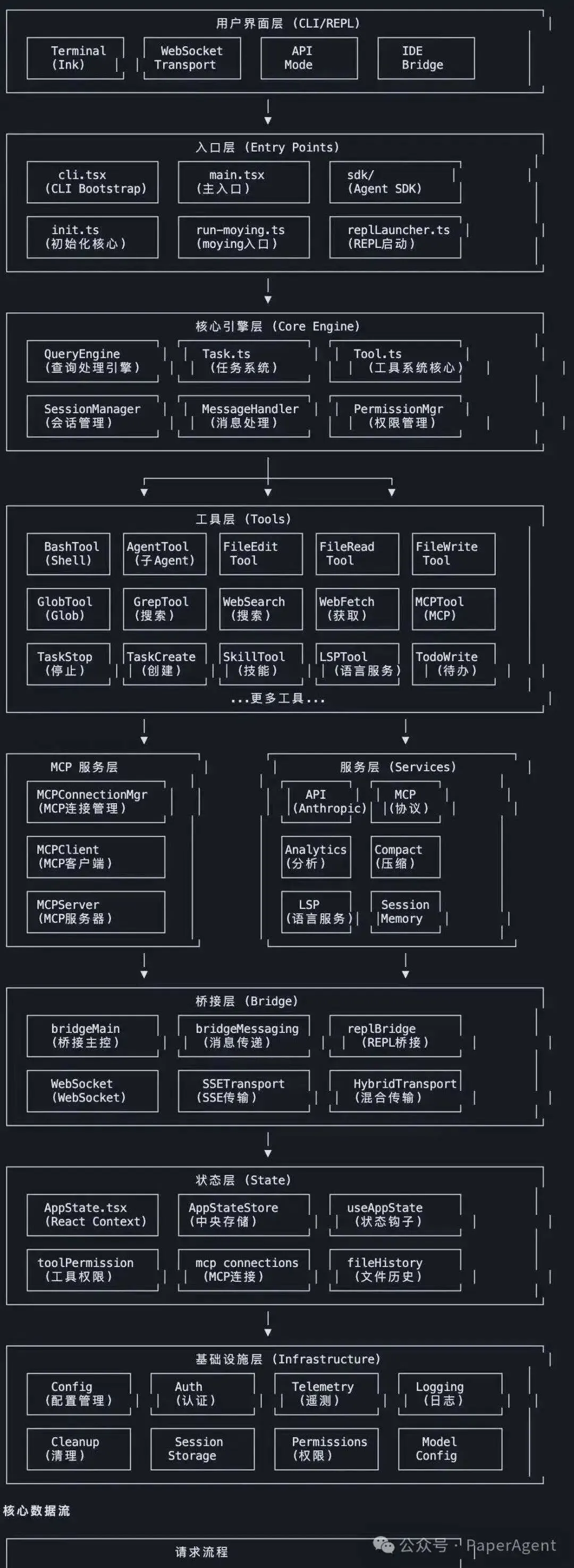
这有什么区别?
向量库搜的是“语义相似”。在代码场景里,“语义相似”经常是坑——两个完全不同的函数可能因为注释相似而被召回,而真正要查的那个精确符号反而排在后头。
但 Glob 和 Grep 搜的是“精确存在”。我要找某个接口的定义,就直接 Grep 它的签名;我要找某个模块的所有文件,就直接 Glob 它的路径。
更关键的是,这个检索不是“提前做好的”,而是在 Agent 思考的过程中动态触发的。模型看到任务后,自己决定:我该搜什么?用什么工具搜?搜到后读哪个文件?
这不叫 RAG,这叫“带工具的实时检索”。它比 RAG 更准,也比 RAG 更轻。
02 Prompt 里藏着的“缓存经济学”
很多人写系统提示词,恨不得把所有的规则、规范、例子全塞进去。结果 prompt 越来越大,每次调用都烧掉一大堆 token。
Claude Code 的提示词,却是按“能不能缓存”来切的。
他们把 system prompt 分成了两部分:静态前缀和动态后缀。
静态前缀里放的是身份定位、行为哲学、工具使用规范——这些东西在整个会话过程中基本不变。这一部分可以被缓存,后面的调用几乎不花成本。
动态后缀里放的才是会话相关的信息,比如当前打开的 skill、MCP 工具的使用说明、session-specific 的临时指令。
这个设计的精妙之处在于:它不是把 prompt 当作文本,而是把它当作“可缓存的运行时资源”。
更狠的是,在 Agent 的 fork 机制里,他们甚至刻意让子 Agent 继承主 Agent 的 system prompt 和工具定义,只为了保持 API 请求的前缀字节完全相同,从而命中缓存。
这意味着什么?
意味着他们不是把 token 当“反正也不贵”的消耗品,而是当“每一分钱都得算”的预算来管理。一个会算账的 RAG 系统,才可能真正跑在生产环境里。
03 用“上下文压缩”替代“向量索引预筛选”
RAG 的标准流程里,检索出来的上下文经常太长,塞不进模型窗口。于是大家会做一步“预筛选”,用向量相似度或者别的规则,挑最相关的几条。
但 Claude Code 做了一件更绝的事:它不预筛选,而是让模型自己压缩。
源码里有明确的 Session-specific guidance 和 token 预算管理逻辑。当上下文逼近窗口上限时,系统不是粗暴地扔掉旧消息,而是让模型把之前的对话、工具结果、中间产出,压缩成一个“紧凑摘要”。
这个摘要是结构化的,保留了关键信息,但去掉了冗长的细节。压缩后,原来占 10000 token 的上下文可能只剩 2000 token,但核心内容没丢。
这相当于把 RAG 的“预筛选”从“检索阶段”挪到了“模型消费阶段”。
谁的判断更准?当然是模型自己的判断更准。向量相似度永远不知道“什么信息对当前任务重要”,但模型知道。
04 “MCP 不只是工具桥,还是行为说明注入通道”
最后一个技巧,藏得最深。
很多人用 MCP(Model Context Protocol)的时候,只把它当作“让模型能调用外部工具”的桥梁。给模型暴露几个 API,它能调就行了。
但 Claude Code 的 prompts.ts 里有一段很关键的逻辑:getMcpInstructionsSection()。
这段逻辑会遍历所有连接的 MCP Server,如果某个 Server 提供了 instructions 字段,就把这些 instructions 直接拼进系统提示词里。
这意味着什么?
意味着 MCP 不仅能注入工具,还能注入“如何使用这些工具的行为说明”。
比如一个数据库 MCP 工具,可以在 instructions 里写清楚:“查询时优先用索引字段,避免全表扫描;大批量数据要用分页,不要一次拉完。”
这些说明会变成系统提示词的一部分,直接影响模型的行为。
这不就是 RAG 吗?
RAG 的本质,是把“外部知识”注入到模型的上下文中。MCP instructions 做的,就是把“工具的使用知识”注入到模型的上下文中。
它不是检索文档,而是检索“工具的行为规范”。这个思路一旦打开,RAG 的边界就不再局限于“搜网页、搜文档”了,而是可以扩展到“搜工具怎么用、搜系统怎么玩”的层面。
最后
回过头看,Claude Code 的这 4 个技巧,其实都指向同一个核心:
RAG 的本质不是“外挂知识库”,而是“让模型在正确的时候,拿到正确的信息”。
向量库只是实现这个目标的手段之一,不是唯一,甚至不一定是最好的。
Explore Agent 的实时检索,比向量库更准。 Prompt 的缓存切分,比堆 token 更省。 上下文的动态压缩,比预筛选更聪明。 MCP 的行为说明注入,比单纯工具桥更“懂”。
这些技巧,任何一个单独拎出来,都值得深挖。而它们组合在一起,就成了 Claude Code 那个“手感特别好”的秘密。
如果你也在做 Agent 相关的系统,不妨想一想:你的 RAG,还停留在“向量库 + 召回”的阶段吗?还是已经在往“操作系统级内存管理”的方向走了?