 夜雨聆风
夜雨聆风





看Claude Code源码泄漏事件:比源码更重要的,是这次“谁来背锅”
Claude Code 源码泄露,本质上是一场再典型不过的工程事故。
权限控制不到位、上线链路存在手工步骤、流程设计有缺口,这些问题,哪家互联网大厂没有碰到过?几乎每一个做过复杂系统的团队,都踩过。
针对Claude Code源码的秘密和解读,网上已经太多了。
而我想从「事后复盘」的角度来谈谈这次的事情。
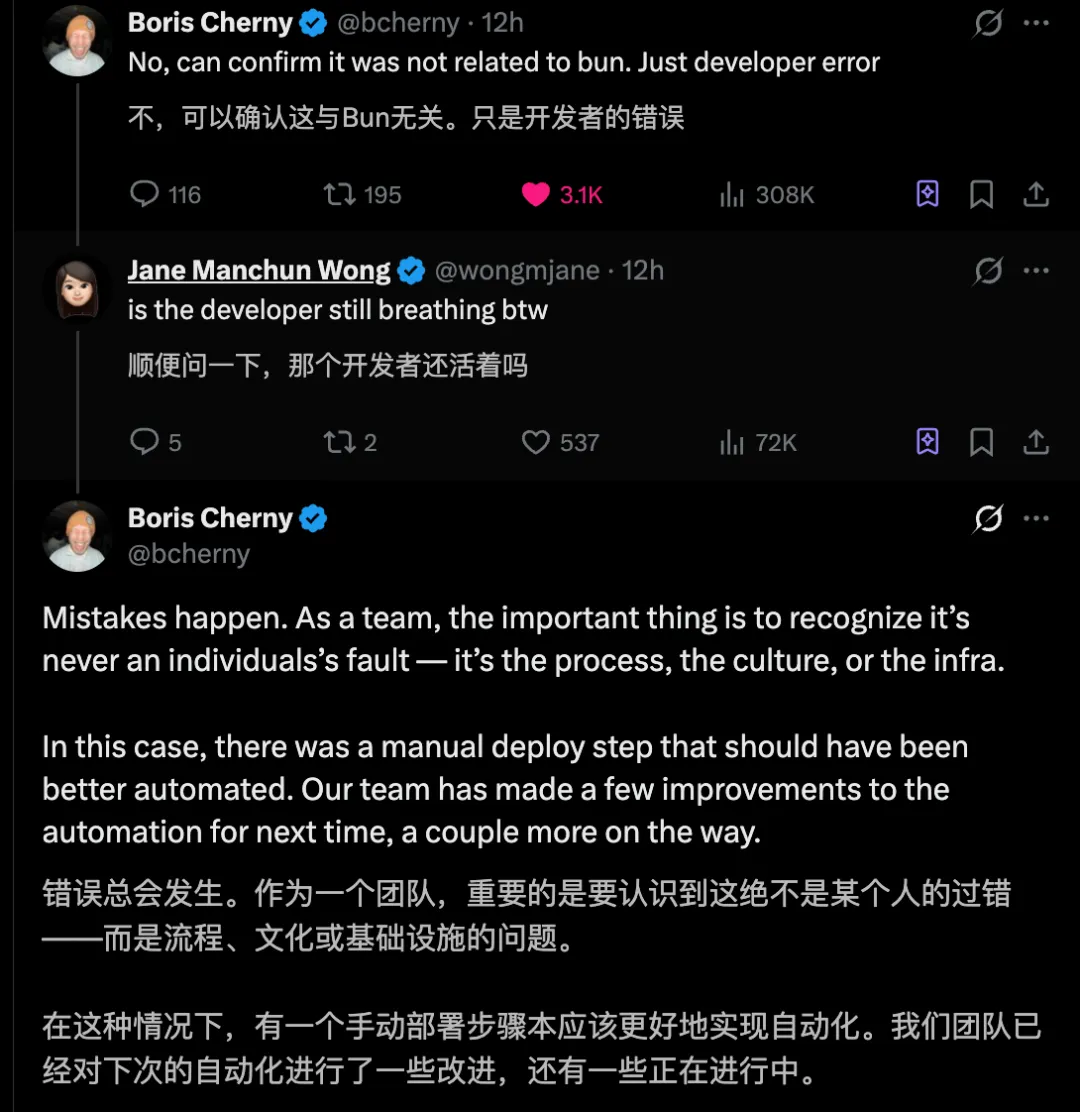
Anthropic Claude Code 的打造者、工程负责人 Boris Cherny,当被问到是Bun的错,还是开发者的错误时,他给了一个「半官方」的回应:
Mistakes happen. As a team, the important thing is to recognize it’s never an individuals’s fault — it’s the process, the culture, or the infra.
In this case, there was a manual deploy step that should have been better automated. Our team has made a few improvements to the automation for next time, a couple more on the way.
错误总会发生。作为一个团队,重要的是要认识到这绝不是某个人的过错——而是流程、文化或基础设施的问题。在这种情况下,有一个手动部署步骤本应该更好地实现自动化。我们团队已经对下次的自动化进行了一些改进,还有一些正在进行中。
这句话的核心,其实只有一个:把责任,从“人”,转移到了“系统”和“流程”。
他甚至进一步给出了明确指向,这次问题的根因,是一个本该自动化的 deploy 步骤,仍然依赖人工。
换句话说,这不是“谁做错了”,而是:系统允许错误发生,这本身就是系统的问题
正是这句回应,让 Boris 获得了社区的广泛好评。
这套逻辑,在 SRE / DevOps 体系里并不新鲜:事故的价值,不是用来追责,而是用来修系统。
但问题在于真正做到这一点的企业和组织,实在太太太太少了。
如果把同样的事情放到国内大厂语境里,剧情往往会是另一种展开:
-
对外:统一口径,“复盘对事不对人” -
对内:开始排查链路,锁定关键节点 -
最后:总会有一个“责任人”被明确(哪怕不是公开的)
据我所知,某大厂内部还有一个专门为P2+事故做复盘引导的团队,最后一定要给故障定责,找到一个「背锅」的责任方。
每次故障复盘会都会重复类似的话术和流程,其实比事故发生时的处理和修复,更加的耗人心神。
就不说哪家大厂了,但应该多家互联网公司都会有类似的组织。但有时候又觉得,没有这种组织,似乎又说不过去。
因为IT部门的更高层领导们、主管们,肯定都期望能够在故障中吸取经验,来让事故减少发生,以对业务部门展现「精益求精」的commitment。
因此,你会看到一整套非常熟悉的闭环:
流程优化了、规范补充了、培训加强了、责任也落实了
问题是,这里的“责任落实”,往往仍然落在人身上。而这个人,可能是一名刚入职但又实际干活的「小兵」,抑或是一名某某外包厂的同事。
于是就出现一个结构性矛盾:一边说“问题在系统”,一边却需要“有人为系统的问题负责”。
久而久之,大的团队会形成一种隐性的行为模式:
-
避免踩雷,而不是暴露问题 -
避免出错,而不是推动系统优化 -
在复盘中“讲对的话”,而不是“讲真实的问题”
这也是为什么,很多团队的复盘会越来越像一种“话术工程”。
反过来看 Boris 的这次回应,其实做了两件不容易的事:
第一,把问题钉死在系统上,而不是人上
第二,公开承认流程设计本身存在缺陷
但评论区的一个问题,同样值得深思:
will team still trust this person?
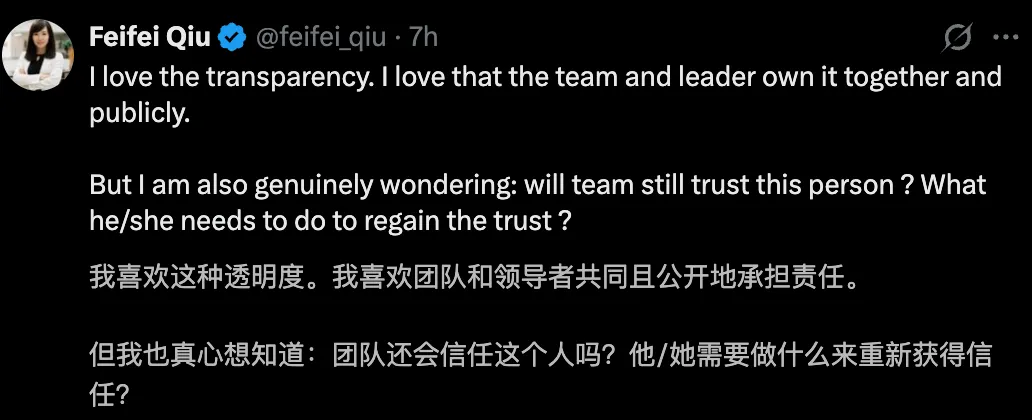
这揭示了更底层的一层:一个成熟的工程组织,信任从来不是建立在“谁不犯错”,而是建立在:错误是否能被安全地暴露 ➕ 暴露之后,是否真的推动系统改进
当你说“不是人的问题”之后,系统,真的被改了吗?