 夜雨聆风
夜雨聆风





[Dify]Dify Word 文档批注功能探索:让大模型生成审阅意见并写回
在使用 Dify 搭建工作流时,发现一个好用的插件 Word 文档操作工具插件 ,上一次研究了插件中pdf转word,今天研究一下插件中的文档批注 功能。
测试这样一个场景:让大模型先阅读 Word 文档,再把生成的审阅意见直接写回原始文档批注中,输出一份可继续修改和流转的审阅版 Word。
一、Word 文档操作工具插件
在插件市场中搜索 Word,比较容易找到这个插件。 根据插件说明,文档批注功能接收两个核心输入:
一个是原始 Word 文档,也就是需要被添加批注的 .docx 文件; 另一个是批注映射 JSON,其中键是文档中要查找的摘要文本,值是对应要添加的批注内容。
这个 JSON 支持两种格式:
一种是对象格式,也就是“原文摘要 : 批注内容”的直接映射;
一种是数组格式,本质上也是多组同样的映射,只是包在数组里。
从结构上看,这个插件本质上是在做一件事:
根据“原文片段—批注意见”的映射关系,把批注挂回 Word 对应位置。
二、文档批注场景
这个能力非常适合“文档审阅类”应用。
例如:
-
通知、方案、制度文件审阅 -
合同初稿风险提示 -
汇报材料优化建议 -
招标采购文件表述检查 -
项目申报材料规范性审阅
这些场景有一个共同点:
文档已经有了,但还需要审阅意见,而且最好直接体现在原文里。
相比单独输出一份“问题清单”,直接把批注写回 Word 的优势更明显:
-
审阅意见和原文位置对应更直观 -
使用者不用来回对照 -
更接近真实办公习惯 -
更适合作为修改底稿流转
三、工作流测试目标
这次我做的是一个最小功能版流程,目标比较明确:
-
上传一份 Word 文档 -
提取文档正文 -
让大模型生成批注映射 JSON -
对 JSON 做校验和清洗 -
调用 Word 文档批注插件 -
输出带批注的 Word 文件
整个流程并不复杂,但比较完整,已经能把“大模型审阅 + Word 落批注”这条链路跑通。
四、工作流整体思路
本次测试工作流整体结构如下:

从结构上看,主要分成三部分。
第一部分:文档内容抽取
先把上传的 Word 文档提取成文本,供后续大模型阅读。
第二部分:大模型生成批注 JSON
让模型基于文档内容和审阅要求,输出符合插件格式要求的 JSON。
第三部分:插件回写 Word 批注
将清洗后的 JSON 和原始 Word 一起传给插件,输出带批注的 Word 文件。
五、工作流搭建
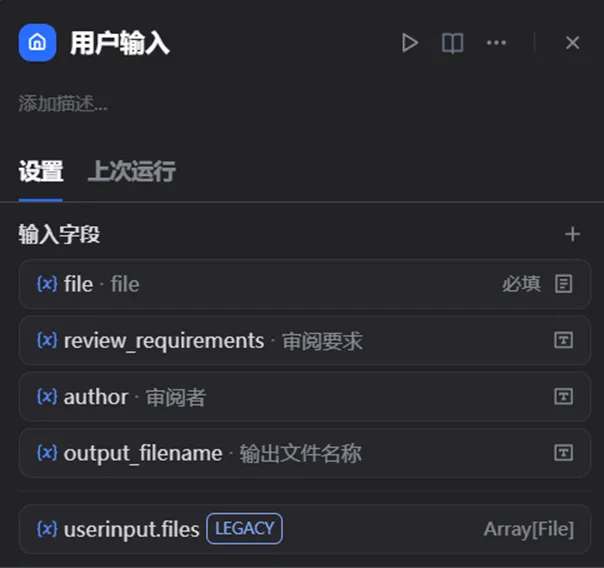
在开始节点中,除了上传文件,增加了几个可选输入项,并设置了默认值。
1. 审阅要求
用于告诉模型,这次审阅重点关注什么。
例如默认值可以设置为: 从错别字、语法错误、逻辑不通、表述不规范、专业错误、风险提示等方面进行审阅,并仅输出最值得批注的 5—10 处内容。
这样,可以直接使用默认要求,也可以根据具体文档自行调整审阅重点。
2. 审阅者
用于传给插件,作为批注作者名称。 例如默认设置为“AI审阅”。
3. 输出文件名称
用于设置最终生成文件的名称。 例如默认设置为“审阅批注版”。
这样配置的好处是:
不填写也能直接运行,想个性化时也可以自行调整。
六、LLM 节点
整个批注效果好不好,很大程度取决于大模型输出的 JSON 是否稳定、是否便于后续匹配原文。
因此,在提示词设计上,我重点约束了几个方面:
-
只输出合法 JSON -
key 必须尽量取自原文 -
value 要简明、明确、可操作 -
仅输出最值得批注的少量内容 -
不输出解释、前言、后缀或 Markdown 代码块
同时,为了提升稳定性,我还在提示词中加入了:
-
插件支持的 JSON 格式说明 -
正确示例 -
错误示例
比如,在提示词里会明确告诉模型:
对象格式就是“原文摘要:批注内容”的直接映射; 数组格式则是多组这样的映射集合。 同时还会专门提醒模型,不能输出“以下是审阅结果”之类的说明文字,也不能把 key 写成“这段话主要讲的是……”这种概括句,而应该尽量直接取自原文。
这样做的目的,就是尽可能提高模型输出的稳定性,减少后续匹配失败的概率。
你是专业文档审阅助手。请对上传的 Word 文档内容进行审阅,并生成用于 Word 批注插件的 JSON 数据。审阅重点:{{#1774257312397.review_requirements#}}插件要求:- 输出内容必须是合法 JSON- 支持两种格式:1. 对象格式:{"摘要1":"批注1","摘要2":"批注2"}2. 数组格式:[{"摘要1":"批注1","摘要2":"批注2"},{"摘要3":"批注3"}]- 键为文档中要查找的摘要文本,尽量是一句话或者一个较短段落,必须尽量与原文保持一致,便于后续定位和匹配- 值为要添加的对应批注输出要求:1. 只输出合法 JSON,不要输出任何解释、前言、后缀、说明文字或 Markdown 代码块。2. 优先输出“对象格式”JSON,除非确有必要再使用“数组格式”。3. key 必须尽量直接取自原文,不能随意改写,不能概括替代,不能写成“第一段内容”“这句话”等模糊表述。4. key 尽量为一句完整原文,或一个较短自然段,不要选择标题,不要选择过长段落。5. value 为对应批注意见,语言简明、明确、可操作,适合直接作为 Word 批注内容。6. 仅输出最值得批注的 5-10 处内容,不要覆盖全文每一句。7. 批注重点可包括:表述不规范、逻辑不清、信息不完整、风险提示、专业表述不准确等。8. 如果文档整体质量较高,也应尽量找出少量确有价值的批注点,但不要为了凑数量强行批注。正确示例1(对象格式):{"请各部门及时报送相关材料。": "建议补充明确的报送截止时间和报送方式,便于执行。","请认真贯彻落实。": "表述较为原则,建议结合本文主题补充更具体的落实要求。"}正确示例2(数组格式):[{"为进一步做好相关工作,现将有关事项通知如下。": "如后文事项较多,建议采用分条编号方式,增强层次性。","请各部门及时报送相关材料。": "建议补充明确的报送截止时间和报送方式。"},{"请认真贯彻落实。": "表述较为原则,建议补充更具体的执行要求。"}]错误示例1(不要这样输出):以下是审阅结果:{"某句话": "某批注"}错误原因:包含了多余说明文字,不是纯 JSON。错误示例2(不要这样输出):{"这段话主要讲的是报送要求": "建议更明确"}错误原因:key 不是原文片段,后续可能无法匹配到文档位置。错误示例3(不要这样输出):```json{"请各部门及时报送相关材料。": "建议补充时间。"}
七、JSON 清洗代码节点
虽然在 LLM 提示词中已经明确要求“只输出 JSON”,但在实际运行时,大模型仍然可能出现以下情况:
-
前面多输出一句说明文字 -
自动加上代码块标记 -
JSON 结构不完整 -
键值类型不符合要求
如果把这类原始结果直接传给插件,就容易导致执行失败,而且问题不容易定位。
因此,我在 LLM 节点后面增加了一个 JSON 清洗代码节点,主要用于:
-
去掉多余的代码块包裹 -
校验输出是否为合法 JSON -
校验 JSON 是否符合插件支持的格式 -
输出标准化后的 JSON 字符串
如果校验失败,则直接提示:
LLM 输出不是合法 JSON,请检查提示词或模型输出。
这样可以把格式问题拦在插件前面,减少后续报错,也更方便排查问题。
import jsonimport redef main(llm_text: str) -> dict:if llm_text is None:raise ValueError("格式错误:LLM 未返回内容")text = llm_text.strip()# 去掉 Markdown 代码块包裹text = re.sub(r"^```json\s*", "", text, flags=re.IGNORECASE)text = re.sub(r"^```\s*", "", text)text = re.sub(r"\s*```$", "", text)if not text:raise ValueError("格式错误:LLM 返回内容为空")# 尝试解析 JSONtry:data = json.loads(text)except Exception:raise ValueError("格式错误:LLM 输出不是合法 JSON,请检查提示词或模型输出")# 只允许两种格式:# 1. 对象格式:{"摘要1":"批注1"}# 2. 数组格式:[{"摘要1":"批注1"}, {"摘要2":"批注2"}]if isinstance(data, dict):for k, v in data.items():if not isinstance(k, str) or not isinstance(v, str):raise ValueError("格式错误:对象格式中,键和值都必须是字符串")elif isinstance(data, list):for item in data:if not isinstance(item, dict):raise ValueError("格式错误:数组格式中,每个元素都必须是对象")for k, v in item.items():if not isinstance(k, str) or not isinstance(v, str):raise ValueError("格式错误:数组格式中,键和值都必须是字符串")else:raise ValueError("格式错误:仅支持对象格式或对象数组格式")# 返回清洗后的标准 JSON 字符串,供插件直接使用return {"clean_comments_json": json.dumps(data, ensure_ascii=False)}
八、Word 文档批注插件
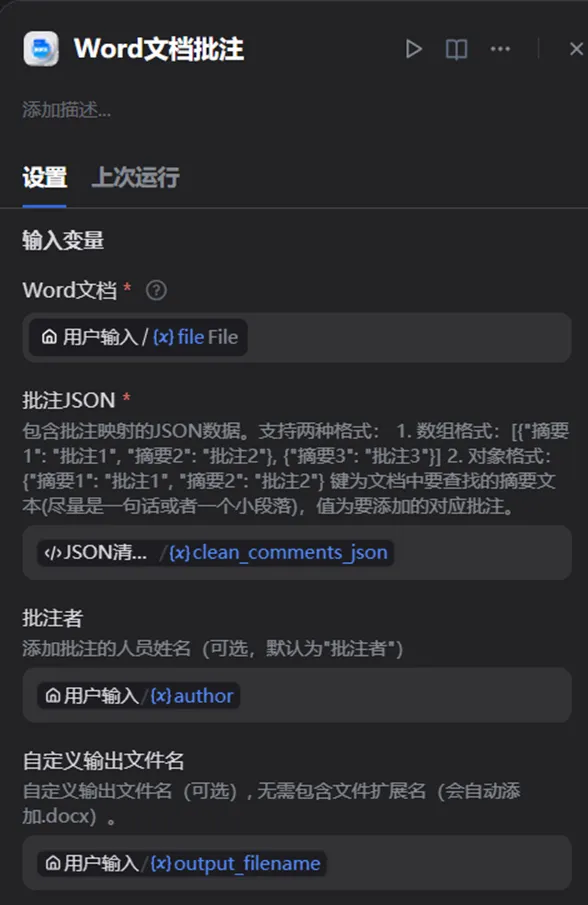
在插件节点中,主要传入了以下参数:
1. 原始 Word 文档
直接引用开始节点上传的文件。
2. 批注 JSON
引用 JSON 清洗节点输出的标准 JSON 字符串。
3. 批注者
引用开始节点中的 author。
4. 输出文件名称
引用开始节点中的 output_filename。
5. 相似度阈值
这里固定设置为 0.8。
这个参数决定了插件对文本匹配的严格程度: 值越高,要求匹配越精确;值越低,则允许更模糊的匹配。 在当前测试中,0.8 是一个相对平衡的值。
九、工作流运行效果
流程跑通后,最终可以输出一份带批注的 Word 文件。
这份文件会保留原始文档结构,同时在对应句子或段落位置添加批注。使用者打开 Word 后,可以直接看到模型给出的审阅意见。
从结果来看,这种方式的几个优势比较明显。
1. 审阅意见直接回到原文
不需要再单独对照一份问题清单,阅读和修改都更方便。
2. 更贴近实际办公场景
比起只输出一段结果文本,带批注的 Word 更像真实工作中的审阅稿。
3. 整个流程形成闭环
从“读文档”到“出批注版文件”,整个过程可以在一个工作流中完成。
从这次测试结果看,Word 文档批注功能已经能够较好支持“文档解析—批注生成—结果写回”的完整链路,作为文档智能审阅场景的基础能力,已经具备较强的实用价值。
如果这篇文章对你有帮助,欢迎点个赞、点个在看,也欢迎转发给有需要的朋友。 想第一时间收到更新,也可以给我加个星标。 感谢你的阅读,我们下次再见。