 夜雨聆风
夜雨聆风





Claude Code 源码拆解第二篇:工具越多不一定越强,上下文越脏 agent 越笨
不是教你减少工具数量,而是教你怎么不让上下文变成垃圾场。
前几天,一个读者给我发了一段他和 Claude Code 的对话记录。
他接入了 15 个 MCP 工具,每个工具都有详细描述和参数 schema。他觉得很稳——工具多了,agent 能干的事也多了。
结果跑了一个小时后,他发现一个奇怪的现象:
同样的任务,刚开始跑得很顺,越往后越慢,越往后越”飘”。
他问我:”是不是模型累了?”
我说:”不是模型累了,是你的上下文脏了。”
如果你最近也有这些感受,这篇大概率对你有用:
-
工具接了不少,但越跑越感觉 agent “变笨了”。 -
同样的任务,刚开 session 时很快,后面越来越慢。 -
明明没做什么复杂的事,上下文却莫名其妙膨胀。
一、上下文污染:一个被忽视的隐性成本
很多人会把 agent “变笨”归因于模型能力、prompt 写法或者工具数量。
但 Claude Code 源码里有一个更底层的答案:上下文污染。
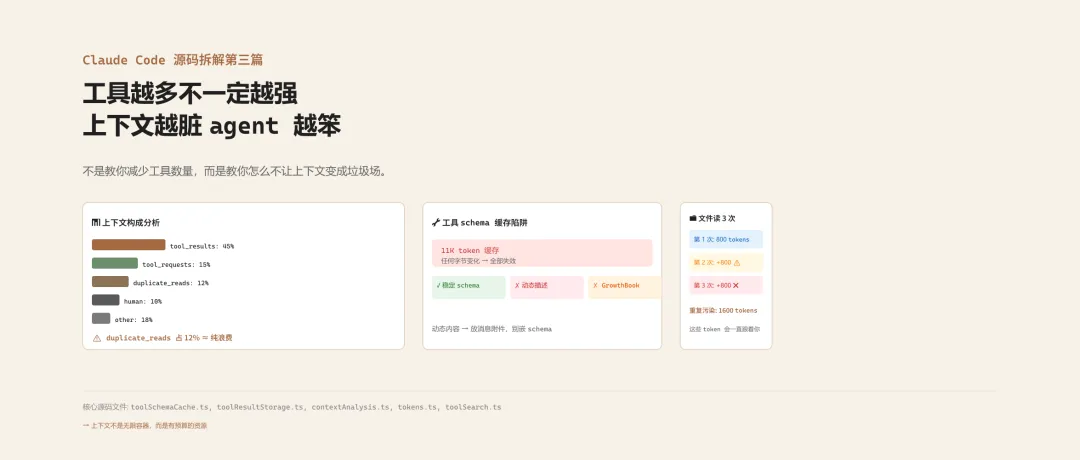
在 src/utils/contextAnalysis.ts 里,系统会持续分析你的上下文构成,统计这些指标:
toolRequests
:工具请求的 token 占比 toolResults
:工具结果的 token 占比 duplicateFileReads
:重复读文件的 token 占比 humanMessages
:用户消息的 token 占比 assistantMessages
:agent 回复的 token 占比 localCommandOutputs
:本地命令输出的 token 占比
这些数据不会直接展示给你,但它们决定了一件事:你的上下文里有多少是真正有用的信息,有多少是历史遗留的噪声。
为什么重复读文件是上下文杀手
源码里有一段专门统计 duplicateFileReads 的逻辑:
// Calculate duplicate file readsfileReadStats.forEach((data, path) => { if (data.count > 1) { const averageTokensPerRead = Math.floor(data.totalTokens / data.count) const duplicateTokens = averageTokensPerRead * (data.count - 1) stats.duplicateFileReads.set(path, { count: data.count, tokens: duplicateTokens, }) }})这段代码的意思是:如果你读同一个文件 3 次,第 2 次和第 3 次就是”重复污染”,它们的 token 数会被单独统计。
为什么这很重要?
因为上下文窗口不是无限容器,而是有预算的资源。每次重复读文件,都是在用你的 token 预算买一份已经买过的信息。
更残酷的是:Claude 的上下文是按 token 计费的,不是按”文件数”或”消息数”。
你以为只是多读了一个文件,实际上是多烧了几千 token。这些 token 会一直跟着你,直到 compact 清理掉。

二、工具 schema 的 11K token 缓存陷阱
如果你关心成本,还有一个更隐蔽的陷阱值得知道。
在 src/utils/toolSchemaCache.ts 里,有一句很重的注释:
Tool schemas render at server position 2 (before system prompt), so any byte-level change busts the entire ~11K-token tool block AND everything downstream.
翻译成一句话:工具 schema 任何字节级变化,会打爆约 11K token 的缓存,以及它下游的所有缓存。
这意味着什么?
工具描述动态化的代价
如果你的工具描述里有动态内容(比如当前时间、在线 agent 数量、MCP 连接状态),每次这些内容变化,都会导致:
-
工具 schema 的字节发生变化。 -
约 11K token 的缓存失效。 -
系统必须重新发送完整的工具定义。 -
你之前的缓存投入,全部白费。
这就是为什么源码要用 TOOL_SCHEMA_CACHE 来锁定 schema 字节:
const TOOL_SCHEMA_CACHE = new Map<string, CachedSchema>()export function getToolSchemaCache(): Map<string, CachedSchema> { return TOOL_SCHEMA_CACHE}export function clearToolSchemaCache(): void { TOOL_SCHEMA_CACHE.clear()}锁定 schema 字节,就是锁定缓存稳定性。任何动态内容,都应该放到消息附件里,而不是嵌入工具描述。
为什么 GrowthBook gate flips 会打爆缓存
源码注释里还提到了一个具体场景:
GrowthBook gate flips (tengu_tool_pear, tengu_fgts), MCP reconnects, or dynamic content in tool.prompt() all cause this churn.
意思是:功能开关切换、MCP 重连、工具描述里的动态内容,都会导致 schema 变化,进而打爆缓存。
这也是为什么 Claude Code 会把 agent 列表放到 deferred_tools_delta 附件里,而不是嵌入工具描述:
为了保持 schema 稳定,为了保护你的 11K token 缓存。
三、长工具输出的上下文爆炸
还有一类污染,很多人不会意识到,但源码里做了完整防御。
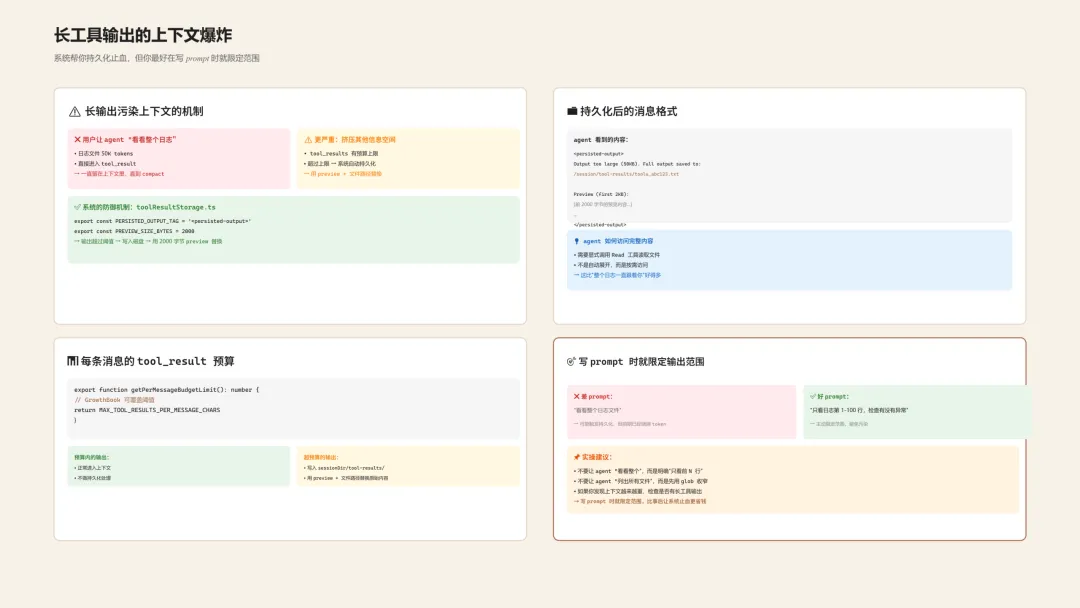
在 src/utils/toolResultStorage.ts 里,系统会对超长的工具输出做持久化处理:
export const PERSISTED_OUTPUT_TAG = '<persisted-output>'export const PERSISTED_OUTPUT_CLOSING_TAG = '</persisted-output>'export const TOOL_RESULT_CLEARED_MESSAGE = '[Old tool result content cleared]'export const PREVIEW_SIZE_BYTES = 2000核心机制是这样的:
-
当工具输出超过阈值( MAX_TOOL_RESULT_BYTES或工具自定的maxResultSizeChars)。 -
系统会把完整输出写入磁盘( sessionDir/tool-results/)。 -
用 2000 字节的 preview + 文件路径,替换原始内容。 -
agent 想看完整内容,需要显式调用 Read 工具。
为什么长输出会污染上下文
每条消息的 tool_result 都会进入上下文。如果你让 agent “看看整个日志”,这个日志会一直跟着你,直到 compact 清理掉。
更糟糕的是:长输出会挤压其他信息的空间。
在 toolResultStorage.ts 里,还有一个更精细的预算机制:
export function getPerMessageBudgetLimit(): number { const override = getFeatureValue_CACHED_MAY_BE_STALE<number | null>( 'tengu_hawthorn_window', null, ) if (typeof override === 'number' && Number.isFinite(override) && override > 0) { return override } return MAX_TOOL_RESULTS_PER_MESSAGE_CHARS}这段代码的意思是:每条消息里的 tool_result 总量,也有预算上限。
超过预算的输出会被系统自动持久化,用 preview 替换。这不是”帮你省钱”,而是”保护上下文不会爆炸”。
实操建议:写 prompt 时就限定范围
✅ 正确做法
-
不要让 agent “看看整个日志”,而是指定行号范围。 -
不要让 agent “列出所有文件”,而是先用 glob 收窄。 -
不要让 agent “分析整个项目”,而是限定目录或模块。
你少写一句”整个”,就能少烧几千 token。
四、deferred tools:工具延迟加载的省钱策略
如果你接入了很多 MCP 工具,还有一个更聪明的做法值得知道。
在 src/tools/ToolSearchTool/prompt.ts 里,Claude Code 引入了一个机制:deferred tools(延迟加载工具)。
核心思路是:
MCP 工具不一开始就塞进 prompt,而是只在工具名列表里占位。agent 需要调用时,先用 ToolSearch 工具加载完整 schema。
export function isDeferredTool(tool: Tool): boolean { // Explicit opt-out via _meta['anthropic/alwaysLoad'] if (tool.alwaysLoad === true) return false // MCP tools are always deferred (workflow-specific) if (tool.isMcp === true) return true // Never defer ToolSearch itself if (tool.name === TOOL_SEARCH_TOOL_NAME) return false return tool.shouldDefer === true}这意味着:
-
MCP 工具默认不占初始上下文。 -
只在需要时才加载,用完就留在历史里。 -
你可以接入很多 MCP 工具,而不必担心初始 token 爆炸。
工具延迟加载的三种触发方式
在 src/utils/toolSearch.ts 里,延迟加载可以通过三种方式触发:
export type ToolSearchMode = 'tst' | 'tst-auto' | 'standard'export function getToolSearchMode(): ToolSearchMode { // auto: N% threshold check // true: always defer // false: always load upfront}tst
:所有 MCP 工具都延迟加载。 tst-auto
:当 MCP 工具描述超过 N% 上下文阈值时,才延迟加载。 standard
:所有工具 upfront 加载(传统模式)。
你可以通过环境变量控制:
ENABLE_TOOL_SEARCH=true # 延迟加载所有 MCP 工具ENABLE_TOOL_SEARCH=auto # 自动判断(默认 10% 阈值)ENABLE_TOOL_SEARCH=auto:5 # 5% 阈值ENABLE_TOOL_SEARCH=false # 禁用延迟加载
为什么延迟加载能省钱
延迟加载的本质是:把工具 schema 的 token 成本,从”一次性预付”变成”按需付费”。
假设你有 20 个 MCP 工具,每个工具的 schema 平均 500 token:
-
upfront 加载:一开始就烧掉 10K token。 -
延迟加载:只在需要时加载,可能一次任务只用到 3 个工具,烧掉 1.5K token。
更重要的是:延迟加载能让 agent 的初始上下文更干净。
agent 不必在一堆可能用不到的工具描述里”寻找”任务线索,而是直接看到你的任务,快速进入状态。

五、上下文预算的精细管理
Claude Code 对上下文预算的管理,比很多人想象的精细得多。
在 src/utils/tokens.ts 里,有一个核心函数:
export function tokenCountWithEstimation(messages: readonly Message[]): number { // 使用最后一次 API 响应的 token 计数 // 加上新增消息的估算}这个函数会:
-
从最后一次 API 响应里,读取真实的 token 计数(input + output + cache)。 -
估算新增消息的 token 数。 -
返回当前上下文的准确 token 数。
为什么不能用累计 token 计数
源码注释里有一句很关键的提醒:
This is the CANONICAL function for measuring context size when checking thresholds (autocompact, session memory init, etc.). Uses the last API response’s token count (input + output + cache) plus estimates for any messages added since.
Always use this instead of:
Cumulative token counting (which double-counts as context grows) messageTokenCountFromLastAPIResponse (which only counts output_tokens) tokenCountFromLastAPIResponse (which doesn’t estimate new messages)
意思是:上下文不是”所有消息的 token 简单相加”,而是”最后 API 响应的完整上下文 + 新增估算”。
因为:
-
API 响应里的 input_tokens已经包含了历史消息。 -
如果你再把历史消息的 token 累加,就会 double-counting(重复计数)。
这也是为什么很多人觉得”明明没做什么,token 却莫名其妙很高”——他们用的是错误的计数方式。
compact 的触发阈值
在 src/utils/tokens.ts 里,还有一个阈值检查:
export function doesMostRecentAssistantMessageExceed200k( messages: Message[],): boolean { const THRESHOLD = 200_000 const lastAsst = messages.findLast(m => m.type === 'assistant') if (!lastAsst) return false const usage = getTokenUsage(lastAsst) return usage ? getTokenCountFromUsage(usage) > THRESHOLD : false}当上下文超过 200K token 时,系统会触发 compact(压缩)。compact 会清理掉旧消息,保留关键摘要。
但 compact 的代价是:你会丢失详细的历史上下文。
更好的做法是:在 compact 触发之前,就主动管理上下文,不让它膨胀到需要压缩的程度。
六、一个够用的上下文健康检查清单
每次跑完一个复杂任务,可以用这份清单检查:
检查一:有没有重复读文件
stats.duplicateFileReads.forEach((path, data) => { console.log(`${path}: ${data.count} reads, ${data.tokens} duplicate tokens`)})如果你发现某个文件被读了 5 次,第 4 次和第 5 次就是纯浪费。下次写 prompt 时,记得明确”只读一次,不要重复”。
检查二:有没有长工具输出没被持久化
检查消息里有没有超长的 tool_result。如果有,系统应该已经用 <persisted-output> 替换了。如果没有,可能是阈值设置有问题。
检查三:工具 schema 有没有被动态内容打爆
检查 TOOL_SCHEMA_CACHE 是否频繁被清空。如果清空次数很多,说明你的工具描述里有不稳定内容。
检查四:MCP 工具是不是全部 upfront 加载
如果你接了很多 MCP 工具,但没启用延迟加载,初始上下文可能已经被工具 schema 塞满了。
ENABLE_TOOL_SEARCH=auto
七、源码真正推荐的上下文管理策略
源码里没有写”操作手册”,但通过这些机制的设计,你能读出一个明确的策略:
策略一:把工具延迟加载当成默认选项
如果你有 5 个以上 MCP 工具,建议启用延迟加载:
ENABLE_TOOL_SEARCH=auto
这样 agent 初始上下文更干净,响应更快,成本更低。
策略二:写 prompt 时就限定输出范围
不要让 agent “看看整个”,而是明确”只看前 100 行”、”只看这个模块”、”只看这个文件”。
这比事后让系统帮你持久化,更主动,更省钱。
策略三:避免重复读文件
同一个文件,不要让 agent 读两次。如果需要多次引用,可以在第一次读完后,让 agent 在后续回复里复用已经看到的内容。
策略四:保持工具 schema 稳定
工具描述里不要放动态内容。时间、状态、数量这类信息,应该放到消息附件里,而不是嵌入 schema。
策略五:主动 compact,不要等系统触发
当你觉得任务已经进入新阶段,可以主动触发 compact,清理掉旧阶段的历史。这比等系统在 200K 阈值触发,更可控。
最后总结
工具数量不是能力指标,上下文健康才是。
如果你只记住一句话,我建议记这个:
上下文不是无限容器,而是有预算的资源。每一次重复读文件、每一个长输出、每一个动态工具描述,都是在烧你的预算。
本文提到的源码位置
src/utils/contextAnalysis.ts:27-97
(上下文污染分析和 duplicate file reads) src/utils/toolSchemaCache.ts:3-8
(schema 稳定性和 11K token 缓存) src/utils/toolResultStorage.ts:55-78, 272-334
(长工具输出持久化和预算管理) src/utils/tokens.ts:226-260
(上下文 token 估算和避免 double-counting) src/tools/ToolSearchTool/prompt.ts:62-108
(deferred tools 判断逻辑) src/utils/toolSearch.ts:172-198, 385-473
(tool search 模式和阈值检查)
下一篇,我会继续拆一个更实用的话题:compact 的触发时机和压缩策略,什么时候该主动压缩,什么时候该保留历史。